优化 | AlphaOPT:用大模型为优化建模构建可进化的“经验知识库”
本文提出了一种全新的、自我改进式经验库学习框架AlphaOPT,用于自动构建优化模型。AlphaOPT 能够仅依赖最优解进行学习,并在分布外泛化方面显著优于微调类方法。同时,它生成的知识结构化、可解释、可审计,适用于真实工业场景中的人工干预与验证需求。展望未来,有三个方向值得进一步探索:(1)面向推理的测试时规模扩展:优化任务具有天然的可验证性,因此在推理层面的扩展潜力更大;(2)构建更大规模、覆

原文信息:(包括题目、发表期刊、原文链接等):AlphaOPT: Formulating Optimization Programs with Self-Improving LLM Experience Library (https://arxiv.org/abs/2510.18428)
原文作者:Minwei Kong, Ao Qu, Xiaotong Guo, Wenbin Ouyang, Chonghe Jiang, Han Zheng, Yining Ma, Dingyi Zhuang, Yuhan Tang, Junyi Li, Shenhao Wang, Haris Koutsopoulos, Hai Wang, Cathy Wu, Jinhua Zhao
开源代码:https://github.com/Minw913/AlphaOPT
1. 模型与方法
尽管优化任务以多样的自然语言描述出现,但它们共享一些在特定条件下触发的可复用的建模经验知识。AlphaOPT 通过持续的两个阶段循环不断提取优化这些经验知识,直到模型无法再取得显著性能提升为止 (如图1所示):
- 经验库学习阶段(Library Learning Phase):从失败任务中提取经过自验证的结构化经验知识(分类、适用条件、解释、示例),并通过动态合并冗余条目以控制经验库的规模增长。
- 经验库进化阶段(Library Evolution Phase):通过分析新任务中的经验知识的误检与漏检情况,系统持续修正经验知识的适用条件,从而增强其跨任务迁移能力。
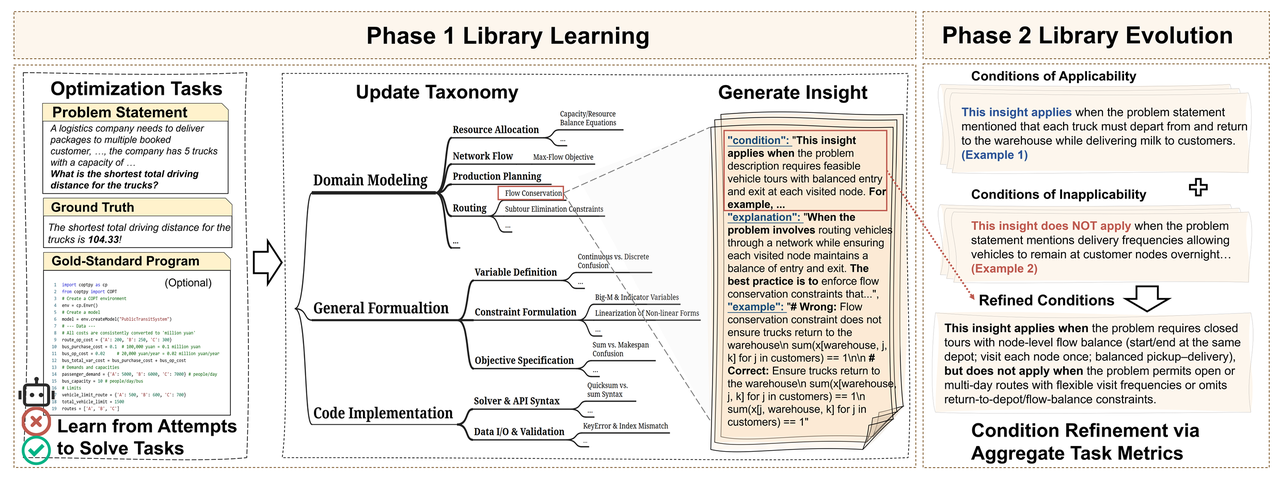
图1 AlphaOPT的方法框架
1.1 经验库学习
经验提取与表示
对于每个优化任务,系统会先根据自然语言描述构建数学模型,再生成可执行的求解器程序求得相应解。若经验库非空且任务检索到相关的经验知识,这两个步骤将由检索到的知识进行引导。当求解器返回的解未达到最优时,系统会根据可用的监督信息通过两种方式提取新的经验知识:
- 若存在标准程序:系统会将 LLM 生成的程序与标准程序进行比对,诊断错误原因(如变量缺失、约束错误、目标项不正确等),并将其归纳为经验知识,存入经验库。
- 若仅有最优解:系统通过自探索不断生成候选可执行程序,借助求解器反馈进行验证,并将失败信息作为上下文持续迭代,直到找到能得到正确目标值的程序。随后,该程序将作为参考基础,用于提取相应的经验知识。
每条经验知识由四部分构成:
- 分类(Taxonomy):用于组织与检索的分层标签体系;
- 条件(Condition):明确描述该经验知识的适用前提与触发信号;
- 解释(Explanation):阐述经验知识背后的理论依据或建模原理;
- 示例(Example):提供可操作的示例,如相应的数学表达式或求解器代码。
经验库存储与检索
新产生的经验知识将被组织并存入一个动态更新、按层级结构管理的经验库中,该经验库包含三大类别:
- 领域建模(Domain Modeling):涵盖与具体问题结构、业务逻辑及领域特性相关的建模原则与结构性假设;
- 通用建模(General Formulation):总结跨任务可复用的数学建模模式,包括变量定义、约束构造与目标函数结构等通用方法;
- 代码实现(Code Implementation):涉及求解器语法、API 使用规范与数据结构一致性等与程序生成和执行相关的技术要点。
在生成优化问题解法时,“领域建模”和“通用建模”经验用于引导数学建模,“代码实现”经验用于指导基于求解器的编程。三大类别下还细分为两级标签;当新经验无法归入现有标签时,系统将自动创建新标签。为避免冗余,经验入库前会进行重复性检查并在必要时合并,同时需通过“自验证”,即在源任务上重新应用一遍以确认其确实能够修复原始错误。
经验库的检索过程分为两步:(1)快速标签匹配:系统首先根据任务描述筛选出可能相关的标签,缩小候选范围。(2)条件匹配验证:严格评估每条经验知识的适用条件,仅保留最匹配、最相关的经验知识作为后续建模的参考。
1.2 经验库演化
在经验库学习阶段,系统会不断新增经验知识,但这些知识的适用条件在初期往往过于狭窄或过于宽泛。若不修正,可能导致本应触发的知识未被检索,或错误地在不相关任务中被调用。经验库演化阶段,系统通过“诊断–改善”循环解决这一问题:识别特定经验知识的适用条件的偏差,综合不同任务的证据,并在每轮迭代末对其适用条件进行更新,使其逐渐趋于准确。
经验诊断
在每轮训练结束后,系统会回溯所有失败任务,并分析它们与经验知识之间的适配情况。每条经验知识都会被划分为三类:
- 正例(Positive):经验知识被正确检索并引导任务得到最优解;
- 负例(Negative):经验知识被错误检索并误导了任务求解;
- 漏检(Unretrieved):若应用该经验知识可以修复任务错误,但系统未将其检索出来。
这些诊断信息使系统能够将问题定位在“检索条件不适配”上,从而避免重新生成冗余经验。
经验改善
基于诊断结果,系统结合关联任务改善经验知识的适用条件。具体而言,负例任务提供“不可适用条件”,用于指示在何种情境下不应触发该经验知识;而漏检任务提供缺失的适用信号,揭示应当触发但被系统忽略的条件。LLM为每条经验知识的适用条件生成多个候选改善方案,并从中选择在保持正例任务尽量不受影响的前提下,能最大程度减少负例和漏检任务的方案更新经验库。
1.3 优化机制
该框架提供了一种有原则的优化视角:在最大化任务成功率的同时,通过控制经验库规模提升检索效率并减少冗余;最终通过持续调整经验库的内容与结构,使其逐步向性能最优状态收敛。
设 LLL为候选经验库,TTT为系统需要解决的任务分布,其目标可表述为:
maxl∈LEt∼T[Success(t∣ℓ)]−λΩ(ℓ),\max\limits_{l \in \mathcal{L}} \mathbb{E}_{t \sim \mathcal{T}}\left[\text{Success}(t | \ell)\right] - \lambda \Omega(\ell),l∈LmaxEt∼T[Success(t∣ℓ)]−λΩ(ℓ),
其中,Success(t∣ℓ)\text{Success}(t | \ell)Success(t∣ℓ) 表示经验库ℓ\ellℓ是否能支持系统生成正确求解任务ttt的程序;Ω(ℓ)\Omega(\ell)Ω(ℓ) 则衡量经验库的复杂度(经验知识数量)。
在我们的设计中,Success(⋅)\text{Success}(\cdot)Success(⋅) 与 Ω(⋅)\Omega(\cdot)Ω(⋅) 都具有有界且连续的性质,再结合系统的充分探索以及冗余合并机制,使得这一“学习—改善”的动态过程能够逐步收敛到一个局部最优的经验库。鉴于自然语言固有的模糊性以及 LLM 输出的随机性,我们并未将这一视角视为严格意义上的定理,而是将其作为支持系统设计合理性的一种原则性论证。
2. 主要结果
实验基于 454 个运筹优化问题实例,来源于 NLP4LP、NL4OPT、IndustryOR 和 MAMO等数据集,覆盖多种建模类型,包含学术、教学及真实工业场景。我们对每个数据集进行分层抽样,按 70%/30% 划分训练与测试集,并严格保证二者不重叠。经验库仅由训练集构建,以避免信息泄露。此外,我们在 LogiOR 和 OptiBench 上进行额外评估,以检验分布外泛化能力。
2.1 整体性能
如表1,AlphaOPT 在分布外数据集上取得了整体最佳成绩:LogiOR 达到 51.1%,OptiBench 达到 91.8%。相比之下,AlphaOPT 在所有分布内数据集上都表现稳健,在 IndustryOR 和 MAMO(ComplexLP)上达到或超过现有基线,并在分布外泛化上保持显著领先。这些结果表明,经验库机制使 AlphaOPT 能够学习可迁移的建模原则,而非仅依赖特定数据集的表层模式,因此在分布变化时展现出更强的稳健性。
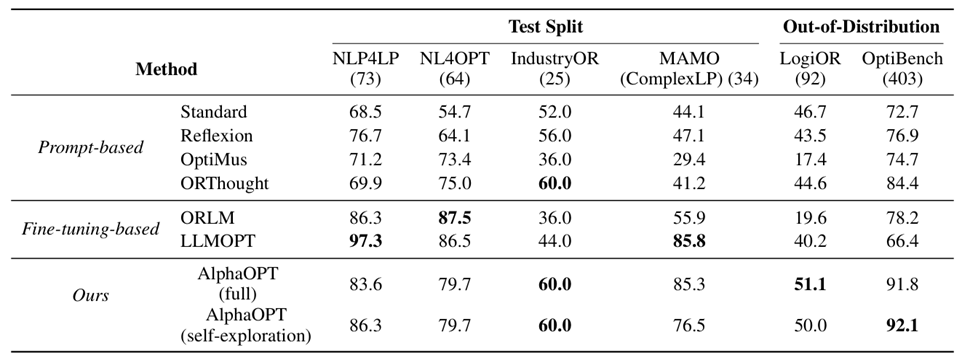
表1 AlphaOPT和其他基线方法在测试集和分布外数据集上的整体性能对比
2.2 有限监督下的学习能力
在多数实际 OR 场景中,由于专家标注稀缺且成本高,标准程序往往缺失。为检验 AlphaOPT 在缺少标准程序时的学习能力,我们移除所有训练数据的标准程序,让模型仅通过求解器反馈进行自探索式学习。表1中的 AlphaOPT(full)使用标准程序进行监督训练,而 AlphaOPT(self-exploration)则完全依赖最优解作为监督信号。实验结果显示,即使仅依赖最优解作为监督信号,AlphaOPT 的表现仍几乎与使用标准程序监督时相当,表明其并不依赖标准程序也能有效提升性能。
2.3 分布外泛化能力
我们在两个未参与训练的数据集(LogiOR 和 OptiBench)上评估了模型的分布外泛化能力(图 2)。结果表明,微调模型(如 ORLM、LLMOPT)虽在分布内表现优异,但在分布外显著退化:ORLM 在 LogiOR 和 OptiBench 上的准确率分别降至 19.6% 和 13.3%,LLMOPT 亦明显低于其分布内水平。相比之下,AlphaOPT 在所有分布外基准上均保持较高准确率,在 LogiOR 和 OptiBench 上分别达到 51.1% 和 91.8%。这表明,微调模型更易依赖学习表层模式,而 AlphaOPT 通过经验库学习可复用的建模知识,从而具备更强的分布外泛化能力。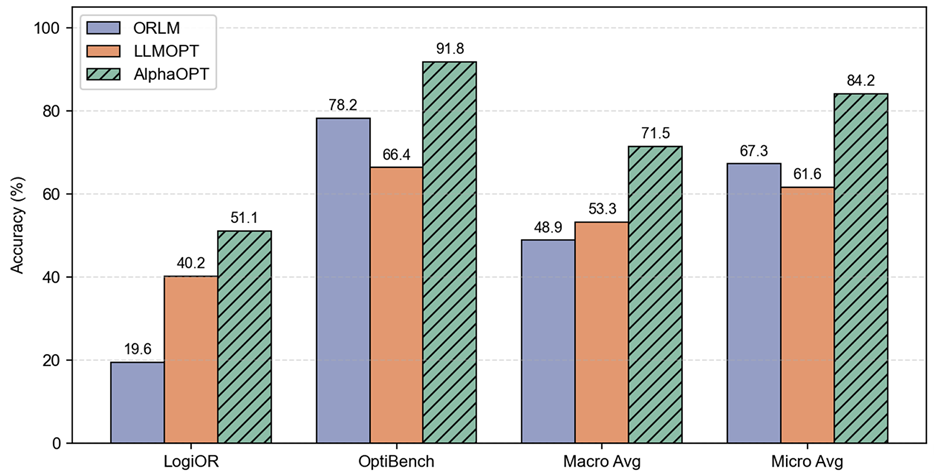
图2 AlphaOPT和微调模型在分布外数据集上的性能表现对比
2.4 随数据规模扩大的持续提升
我们进一步检验了 AlphaOPT 在数据规模增加时的性能持续提升能力。具体做法是分别从训练集中抽取100、200和300个样本,使用这三个不同规模的数据子集对 AlphaOPT 进行训练。实验结果(表2)表明,在分布外测试集(LogiOR、OptiBench)上,AlphaOPT 的性能会随着数据规模的增长而稳步提升,并且整个过程无需更新模型参数。
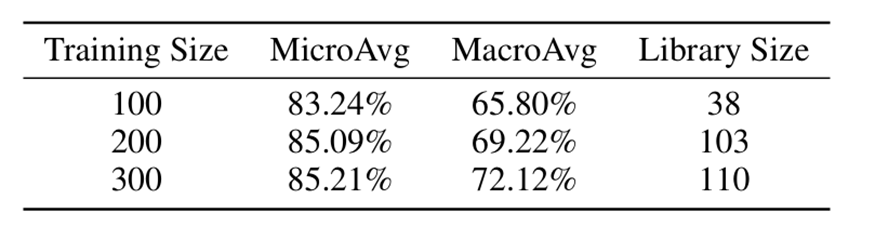
表2 AlphaOPT 随训练数据规模提升的性能变化
3. 经验库分析
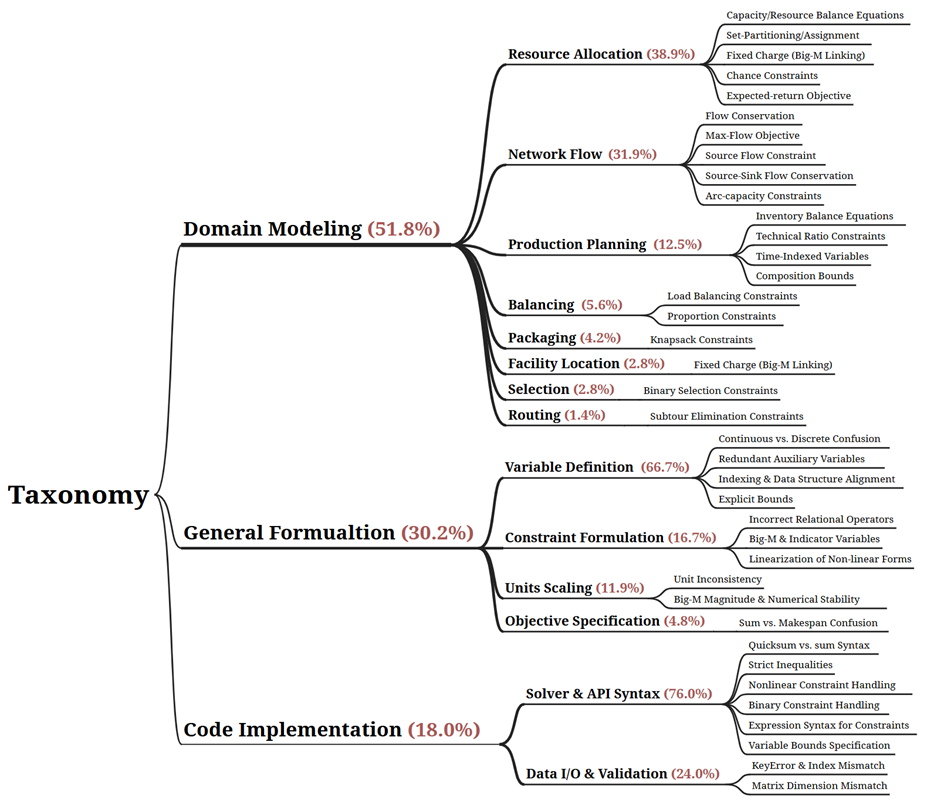
本文对最终经验库的层级化结构及不同类别的经验分布进行了可视化展示(图3),并从中归纳LLM在求解运筹优化问题时存在的常见难点.
- 领域建模(Domain Modeling)层面,LLM主要存在两类核心困难:一是难以刻画跨变量或跨阶段的结构耦合关系,二是难以维持系统资源或数量的整体约束平衡;这类问题在 Resource Allocation(38.9%)、Network Flow(31.9%)和 Production Planning(12.5%)等问题类型中尤为突出。
- 通用建模规则(General Formulation)层面, LLM 将直觉性描述转化为数学上严谨且与求解器一致时,困难主要存在于Variable Definition(66.7%)、Constraint Formulation(16.7%)和 Units Scaling(11.9%)三个方面。其中,Variable Definition 主要表现为变量域不清及连续—离散变量混淆;Constraint Formulation 常见错误包括关系运算符误用以及 Big-M 或指示变量处理不当;Units Scaling 则主要体现在单位不一致和 Big-M 取值不合理导致的数值不稳定。
- 代码执行(Code Implementation)层面,LLM 从符号化数学模型过渡到可执行求解器代码时仍面临关键瓶颈,主要问题集中于模型与求解器的交互阶段。其中,76% 的错误来源于 Solver & API Syntax(如非线性约束处理不当、quicksum 与 sum 使用混淆等),其余 24% 则来自 Data I/O & Validation(如 KeyError、索引不匹配及矩阵维度错误等)。
4. 总结
本文提出了一种全新的、自我改进式经验库学习框架AlphaOPT,用于自动构建优化模型。AlphaOPT 能够仅依赖最优解进行学习,并在分布外泛化方面显著优于微调类方法。同时,它生成的知识结构化、可解释、可审计,适用于真实工业场景中的人工干预与验证需求。
展望未来,有三个方向值得进一步探索:
(1)面向推理的测试时规模扩展:优化任务具有天然的可验证性,因此在推理层面的扩展潜力更大;
(2)构建更大规模、覆盖复杂工业场景的数据集:当前基准以玩具问题为主,限制了模型在大规模优化上的表现;
(3)从正确性走向效率优化:学习生成更高质量、更高效率的数学模型,将显著提升系统在实际部署中的价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)