YOLOv11 轻松上手!3分钟搞定手写数字识别
前言:AI入门,从简单实战开始
想入门AI识别,又怕流程繁琐、耗时过长?YOLOv11 上手便捷、效率在线,不用死磕理论,跟着实战就能快速上手!
今天就带大家入门,用 Python + YOLOv11,3分钟搭建「手写数字实时识别」网页应用,新手也能轻松跟上!
✅ 第一阶段:别想复杂的!先让代码跑起来
我把所有代码都准备好了,你只需要 2 步无脑操作:
-
下载完整代码包
我把能直接运行的 YOLOv11 手写数字识别系统整理好了,你只需要在软件内点击【一键运行】按钮,一键获取所有文件(包含模型、前端页面、训练脚本),不用自己写一行代码、加一句注释。
-
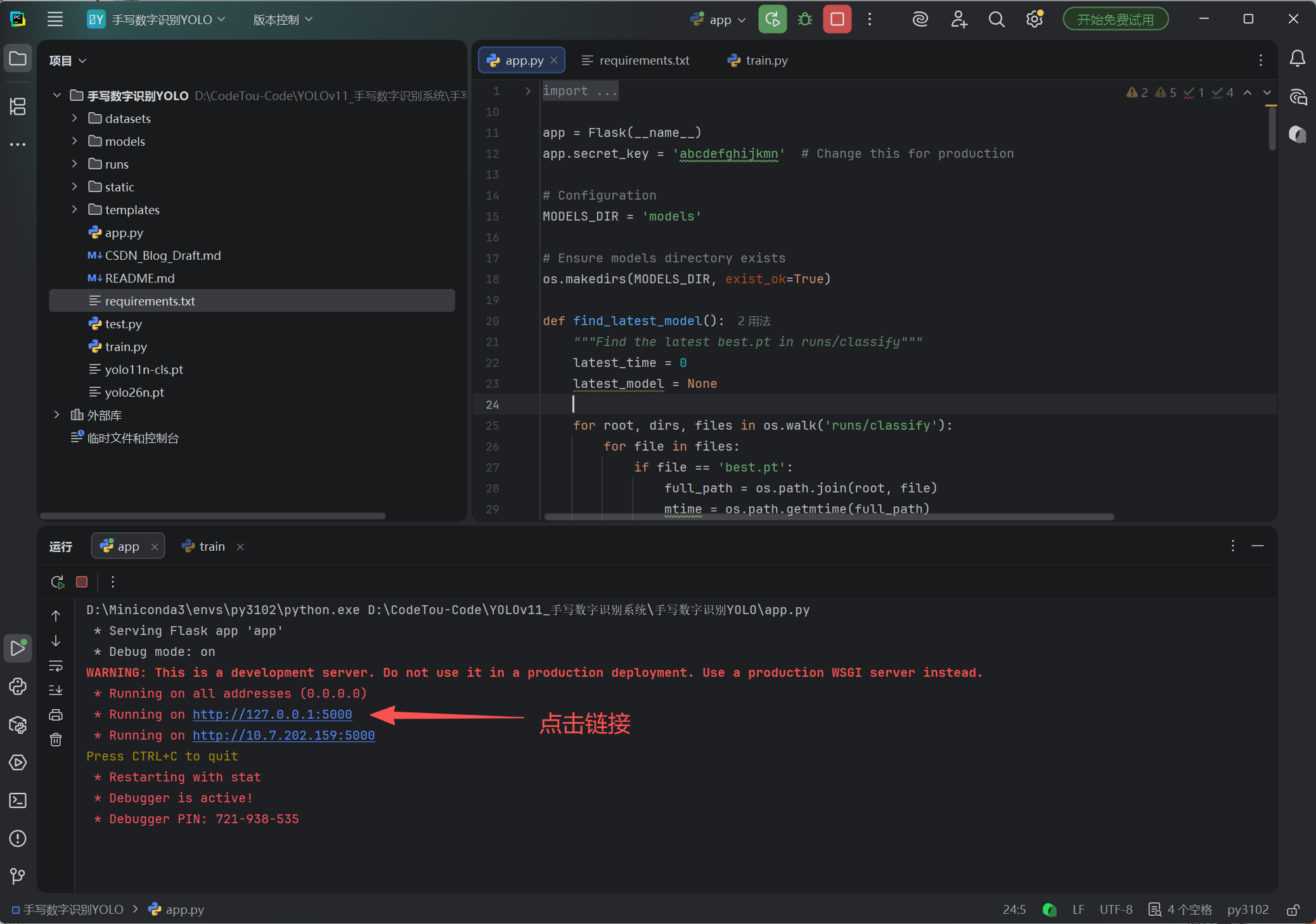
单击【一键运行 】→ 直接玩
稍等片刻打开浏览器访问
http://127.0.0.1:5000,在画板上随便写个数字,AI 瞬间就能认出来,全程不用调试、不用改模型,5分钟就能玩上你自己部署的 AI 系统!
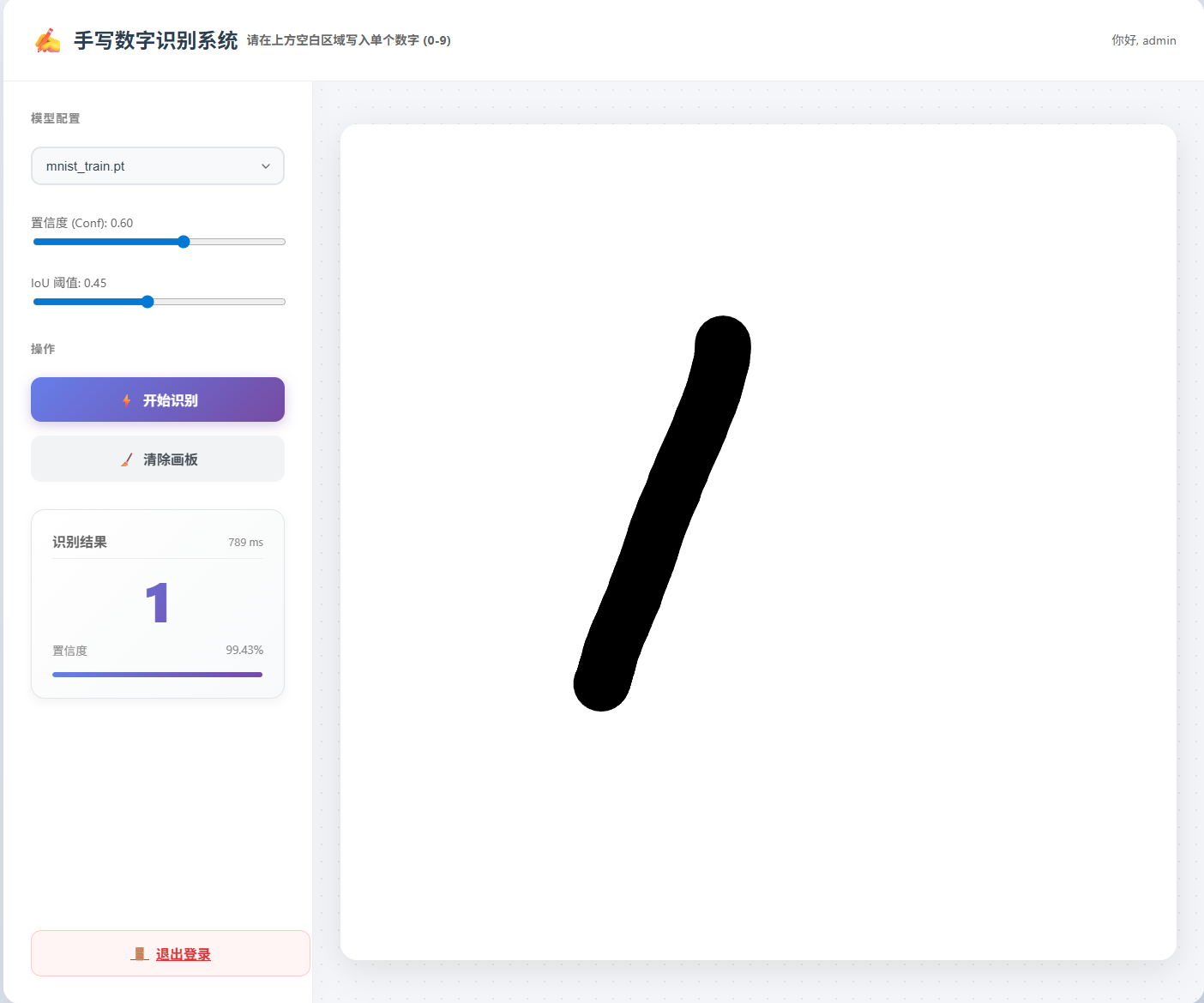
操作与玩法
- 登录:默认账号
admin,密码123456 - 手写:在左侧白色画板区域按住鼠标(或触摸屏幕)书写数字 0-9。
- 识别:系统会自动实时识别,或点击识别按钮。
- 调节:拖动右侧滑块调整“置信度阈值”,过滤掉不确定的结果。
源码目录
抠头助手:下载工具获取源码
安装与运行
1.在「代码社区」中选择「目标检测&图像处理」:
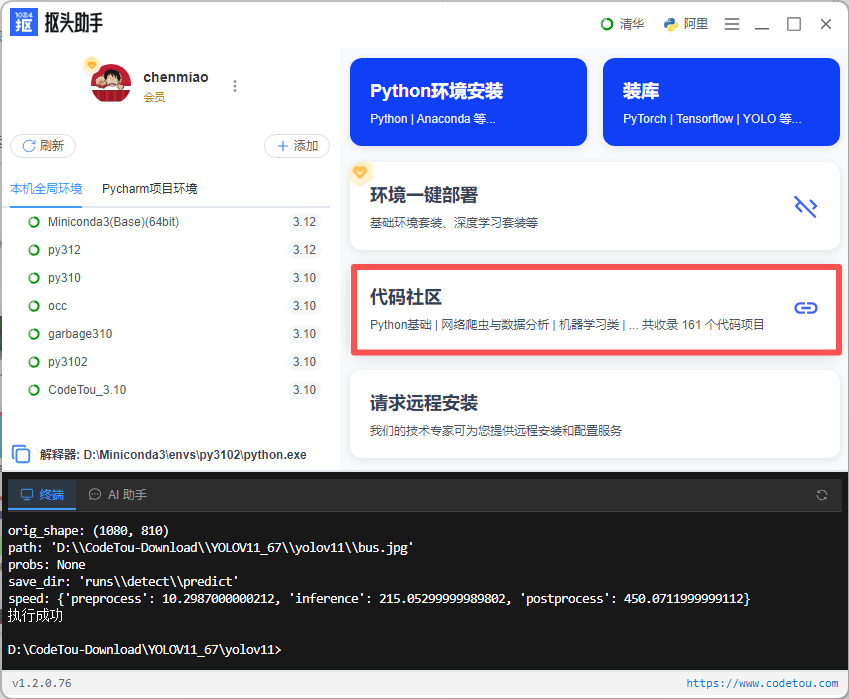
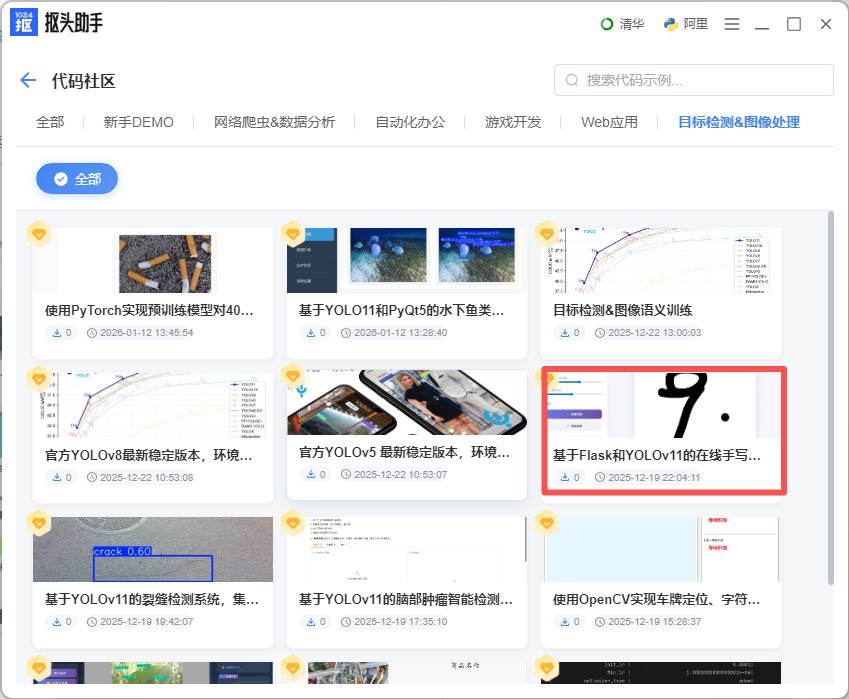
✅ 第二阶段:照猫画虎,训练你自己的模型
玩腻了数字识别?想识别字母?还是想识别自己画的简笔画?
其实,YOLOv11 最强大的地方在于它的通用性。你只需要准备好数据,剩下的交给代码。
1. 准备数据集
YOLOv11 分类模型的数据集结构非常简单。这里我们以本项目使用的 YOLO 官方 MNIST 数据集 为例:
datasets/
└── mnist/ # 数据集名称(可以改成你的,如 fruit)
├── train/ # 训练集
│ ├── 0/ # 类别 0 的图片(比如放几百张写着0的图)
│ ├── 1/ # 类别 1 的图片
│ └── ... # 其他类别
└── test/ # 测试集(结构同上)
- 小贴士:如果你想识别“苹果”和“香蕉”,就创建
apple和banana两个文件夹,往里面塞对应的照片就行!
2. 一键开始训练
打开 train.py,你几乎不需要改代码,直接运行即可。
from ultralytics import YOLO
def main():
# 1. 加载一个最小的模型(速度最快)
model = YOLO("yolo11n-cls.pt")
# 2. 告诉模型数据在哪,训练多少轮
results = model.train(
data="datasets/mnist", # 你的数据集路径
epochs=25, # 训练轮数(练得越久通常越准)
imgsz=32, # 图片大小(手写数字很小,32就够;如果是照片建议 224)
batch=128
)
if __name__ == "__main__":
main()
运行后,你会看到进度条进跑。等跑完后,系统会自动把训练好的模型文件(best.pt)保存在 runs/classify/train/weights/ 目录下。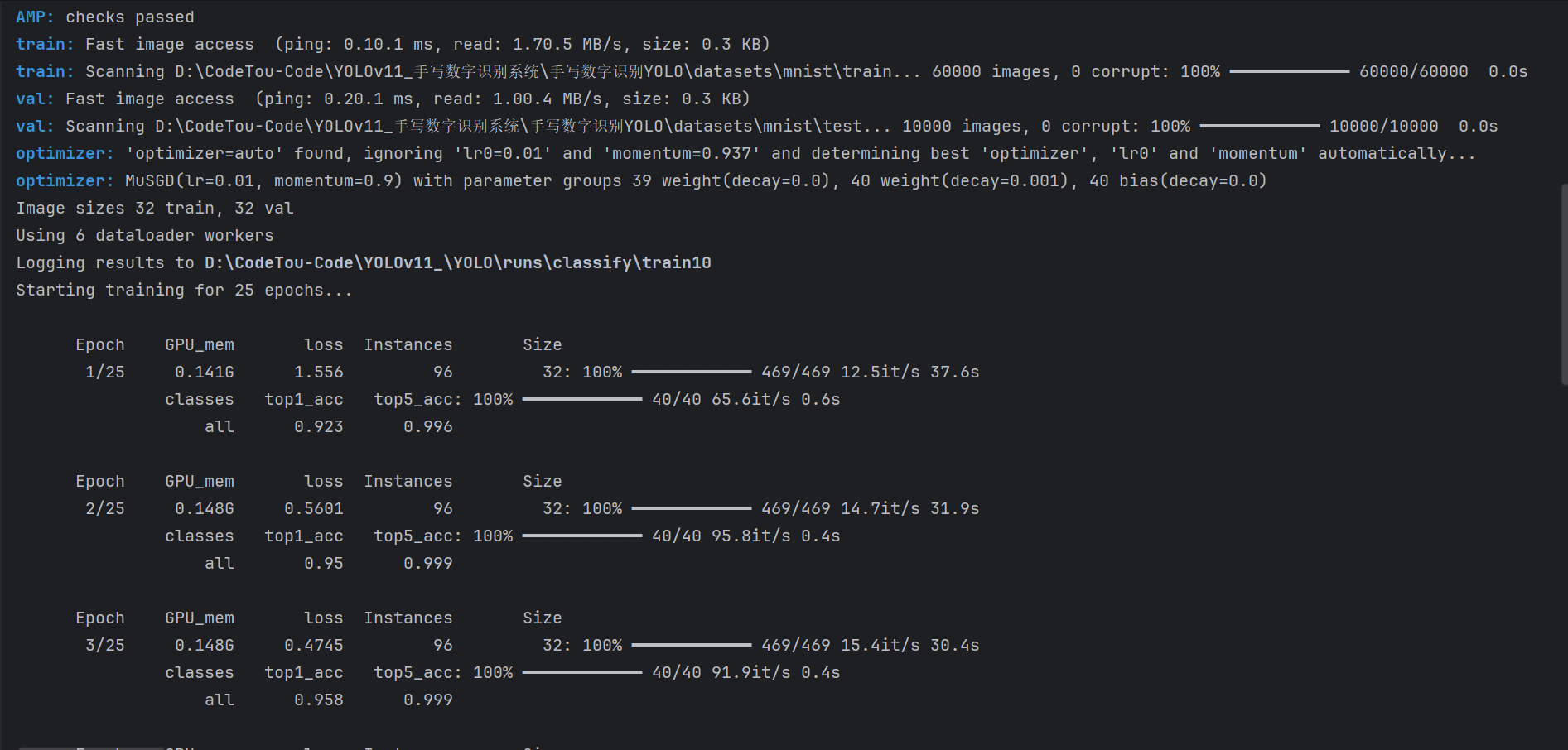
3. 自动部署新模型
最酷的地方来了!你不需要手动去改后端的代码。
我们的系统写了自动发现机制:它会自动扫描 runs 文件夹,找到你最新训练好的模型。你只需要刷新网页,就能在右上角的“模型选择”下拉框里看到你刚练好的模型了!
✅ 第三阶段:探究原理!AI 是怎么看懂你写的字的?
你可能会好奇,我在网页上随便画几笔,后台是怎么知道它是“3”还是“5”的?
关键步骤:图像“翻译” (Pre-processing)
这是很多新手容易翻车的地方。
- 人类视角:我们在白纸上用黑笔写字(白底黑字)。
- AI 视角:常用的 MNIST 数据集是黑底白字的。
如果直接把你的白底黑字丢给 AI,它会完全懵圈。所以我们在 app.py 里做了一个关键的“反色”处理:
# 1. 解码图片
image = Image.open(BytesIO(binary_data)).convert('L')
# 2. 【关键】颜色反转!把白底黑字变成黑底白字
image = ImageOps.invert(image)
# 3. 缩放!把图片缩小到 32x32 像素(和训练时一样大)
image = image.resize((32, 32), Image.Resampling.LANCZOS)
3. 最终判决:模型推理 (Inference)
处理好的小图片被喂给 YOLOv11 模型,模型会输出一个概率列表:
- 是 0 的概率:0.1%
- 是 3 的概率:99.5%
- 是 8 的概率:0.4%
…
我们取概率最大的那个(Top-1),就是最终结果。同时,我们还设计了一个**“置信度阈值”**:如果模型对第一名的信心都不足 60%(比如你画了个四不像),系统就会诚实地显示“?”,而不是瞎猜一个误导你。
这个项目就是一个微型的 AI 落地全流程。下载代码,试着把数据集换成你喜欢的(比如石头剪刀布的手势图),训练一个属于你自己的 AI 吧!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)