AI程序员翻车现场大揭秘!9种RAG架构让你的大模型不再“一本正经胡说八道“
文章详细解析RAG(检索增强生成)技术如何解决大模型"幻觉"问题,通过让模型在生成答案前先检索外部知识库,将输出锚定在可验证事实上。文章从基础到高级介绍了9种RAG架构:标准RAG、对话RAG、校正型RAG、自适应RAG、融合RAG、假设性文档嵌入、自省RAG、智能体RAG和图RAG,每种架构配有适用场景、优缺点及可直接运行的代码示例,帮助开发者根据实际需求构建可靠AI系统。
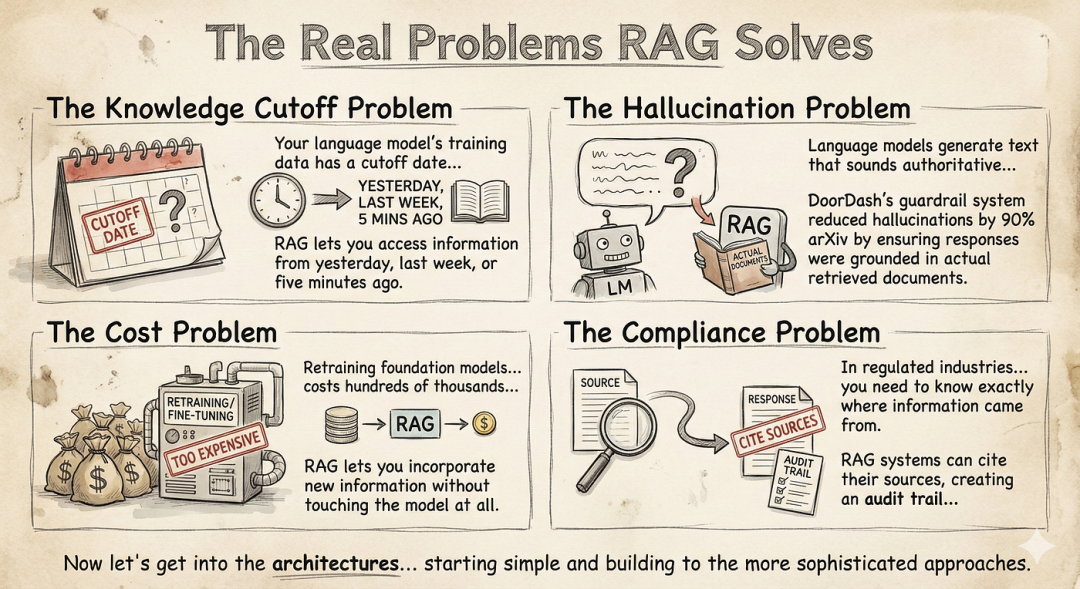
你是否也曾被大模型的“一本正经胡说八道”气到无语?
你精心部署的客服机器人,自信地告诉客户:“我们的退货政策是90天!”——而实际上,公司的规定是30天。
或者,它热情洋溢地介绍了一款“旗舰产品”的“革命性功能”,但问题是——你的公司根本就没这款产品。
这,就是那个令所有AI开发者头疼的“幻觉”问题。大模型明明在胡说八道,语气却无比坚定。在技术演示里,这或许是个小尴尬;但在生产环境中,这可能意味着流失客户、损失金钱,甚至承担法律风险。
今天,我们要聊的 RAG(检索增强生成),就是解决这个问题的“金钥匙”。但很多人不知道的是,RAG不是单一技术,而是一整个架构家族。选错了,你的项目可能从一开始就走在弯路上。
本文将以Python技术视角,为你深入解析9种必须掌握的RAG架构,并提供可直接运行的代码示例,带你从“会用”到“懂选”,构建真正可靠的AI系统。
一、RAG究竟是什么?给模型配个“档案管理员”
想象一下,你公司新来了一位极其聪明的员工,他博闻强记,口才一流。但有个致命缺点:他的知识停留在入职培训那天,对公司最新的项目、数据、政策一无所知。
RAG 就是给这位“聪明员工”配了一位专业的“档案管理员”。
当员工(大模型)需要回答问题时,他不再凭空回忆,而是先转头问档案管理员(检索系统):“嘿,关于XX政策,我们的文件里是怎么说的?” 管理员迅速从档案柜(知识库)中找出相关文件递给他。员工基于这些真实、最新的文件,组织语言给出回答。
技术定义: RAG通过让大模型在生成答案前,先从外部知识库(如文档、数据库、知识图谱)中检索相关信息,从而将生成过程锚定在可验证的事实上。
一、RAG是什么?为什么是刚需?
想象一下,你新招了一位天才员工,他博闻强识(预训练模型),但记忆力极差,且知识停留在去年(训练数据截止)。公司最新的产品手册、客户协议,他一概不知。
RAG就像是给这位天才配了一个随身文件柜(知识库)和一个高效秘书(检索系统)。每当员工需要回答问题时,秘书会迅速从文件柜中找出相关文件,员工结合这些最新资料,给出准确答复。
技术定义:RAG通过让大模型在生成答案前,检索并参考外部知识源,来优化其输出。它让模型不再仅仅依赖训练时学到的“旧知识”,而是能结合你提供的文档、数据库进行回答。
标准流程:
- 检索:将用户问题转化为向量,在你的知识库中寻找最相关的文档片段。
- 增强:将这些片段作为“上下文”与原始问题一起提交给大模型。
- 生成:模型基于给定的上下文,生成一个信息 grounded 的回答。
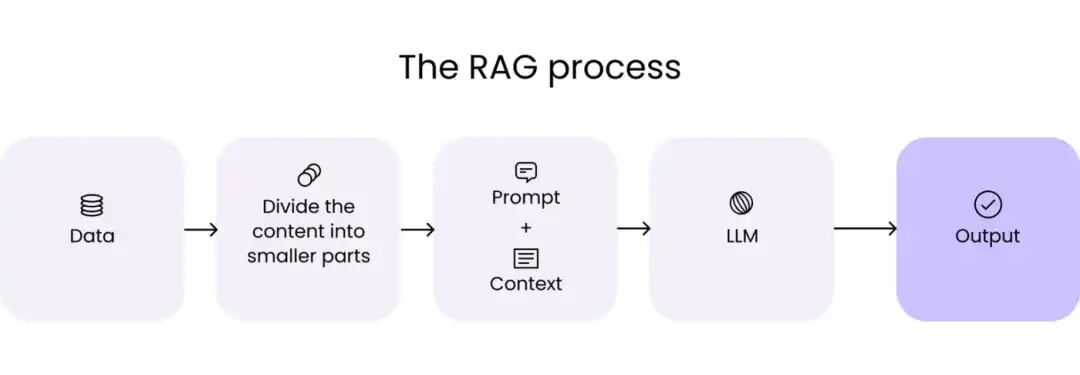
下面,我们从最简单、也是你必须掌握的“Hello World”版本开始。
二、基础篇:从“标准款”到“记忆增强款”
我们将用 langchain 和 chromadb 等主流库来演示核心思想。请先安装基础环境:pip install langchain langchain-openai chromadb tiktoken
img
架构1:标准RAG(Standard RAG)- 你的起点
定位:所有RAG的起点。简单、快速、开箱即用。假设你的检索系统是完美的,适合对速度要求高、容错率相对宽松的场景。
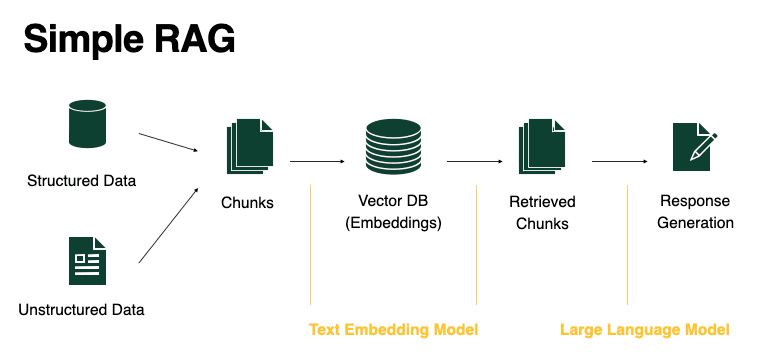
工作原理:
- **分块:**将文档拆解为可处理的文本片段。
- **嵌入:**每个片段转换为向量并存储于数据库(如Pinecone或Weaviate)。
- **检索:**用户查询经向量化处理,通过余弦相似度提取“Top-K”最匹配片段。
- **生成:**将这些片段作为“上下文”输入大型语言模型,生成符合语境的回应。
适用场景:问答机器人、内部知识库查询等简单、明确的单轮问答。
核心代码:让我们实现一个最简单的标准RAG流程。
# 安装必要库:pip install langchain langchain-community chromadb langchain-openai tiktokenfrom langchain_community.document_loaders import TextLoaderfrom langchain_text_splitters import RecursiveCharacterTextSplitterfrom langchain_openai import OpenAIEmbeddings, ChatOpenAIfrom langchain_chroma import Chromafrom langchain_core.prompts import ChatPromptTemplatefrom langchain.chains import RetrievalQA# 1. 加载与分块文档(模拟员工手册)loader = TextLoader("employee_handbook.txt") # 假设有此文件documents = loader.load()text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=50)chunks = text_splitter.split_documents(documents)print(f"文档被切分为 {len(chunks)} 个片段")# 2. 向量化并存入数据库embeddings = OpenAIEmbeddings(model="text-embedding-3-small") # 或使用开源embeddingvectorstore = Chroma.from_documents(documents=chunks, embedding=embeddings, persist_directory="./chroma_db")# 3. 构建RAG链llm = ChatOpenAI(model="gpt-3.5-turbo")retriever = vectorstore.as_retriever(search_kwargs={"k": 3}) # 检索Top-3相关片段prompt = ChatPromptTemplate.from_template("""请根据以下上下文信息回答问题。如果上下文没有提供相关信息,请直接说“根据现有资料,我无法回答这个问题”。上下文:{context}问题:{question}答案:""")rag_chain = RetrievalQA.from_chain_type( llm=llm, chain_type="stuff", # 最简单的一种链,将所有上下文塞入prompt retriever=retriever, chain_type_kwargs={"prompt": prompt})# 4. 提问测试query = "公司规定的年假有多少天?"result = rag_chain.invoke({"query": query})print(f"问题:{query}")print(f"答案:{result['result']}")
优点:
- 低于一秒的延迟。
- 计算成本极低。
- 调试和监控简单。
缺点:
- 极易受“噪声”影响(检索无关数据块)。
- 无法处理复杂的多部分问题。
- 检索数据错误时缺乏自我纠错能力。
重要原则:永远从这里开始。如果标准RAG效果不好,增加复杂度往往无济于事。
架构2:对话RAG(Conversational RAG)- 给AI加上“记忆”
定位:为标准RAG添加记忆(Memory)。解决用户连续提问时(如“它多少钱?”),AI不知道“它”指代什么的问题。
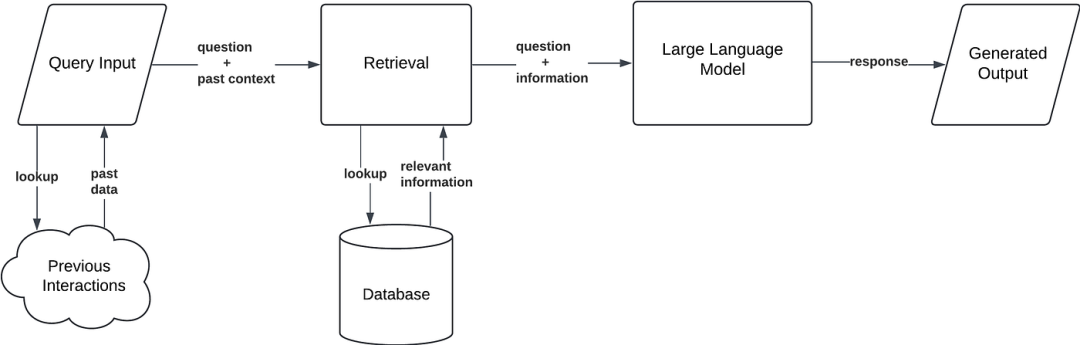
适用场景:客服聊天、多轮诊断、持续探索性对话。
核心:在检索前,用一个LLM先对当前查询进行重写,融入对话历史,使其成为一个独立、完整的查询。
from langchain.memory import ConversationBufferMemoryfrom langchain.chains import ConversationalRetrievalChain# 1. 在标准RAG的基础上,添加记忆模块memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)# 2. 构建对话式RAG链conversational_rag_chain = ConversationalRetrievalChain.from_llm( llm=llm, retriever=retriever, memory=memory, combine_docs_chain_kwargs={"prompt": prompt} # 可使用更复杂的prompt)# 3. 模拟多轮对话print("--- 第一轮对话 ---")result1 = conversational_rag_chain.invoke({"question": "我们公司有哪些福利?"})print(f"用户:我们公司有哪些福利?")print(f"AI:{result1['answer']}")print("\n--- 第二轮对话(依赖上下文) ---")result2 = conversational_rag_chain.invoke({"question": "其中,医疗保险覆盖家人吗?"})print(f"用户:其中,医疗保险覆盖家人吗?")# AI此时能理解“其中”指的是“福利”,并能从上下文中找到医疗保险的具体条款。print(f"AI:{result2['answer']}")
优点:对话体验自然,用户无需重复信息。
缺点:增加了Token消耗;历史信息可能干扰当前检索(“记忆漂移”)。
三、进阶篇:为了“更准”与“更高效”
架构3. 校正型RAG(Corrective RAG, CRAG)- 引入“质检员”
定位:为高准确性要求的场景设计(如金融、医疗)。它在检索后增加了一个**“质检门”,评估检索到的文档质量。如果质量太差,它会触发备用方案(如联网搜索)**。
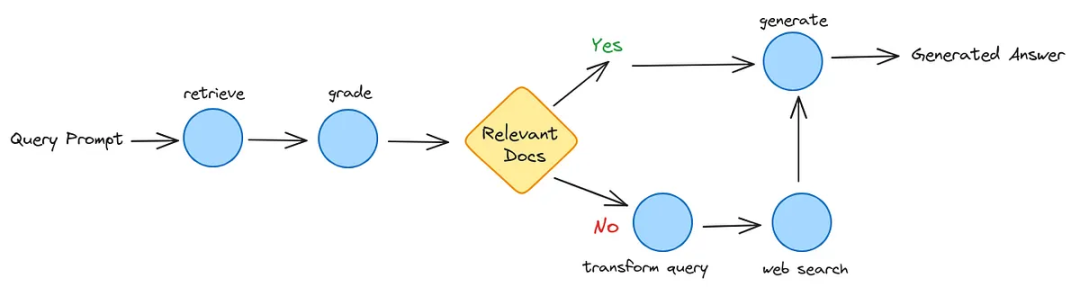
CRAG是一种专为高风险环境设计的架构。它引入了**“决策门”机制**,在检索到的文档进入生成器前对其质量进行评估。若内部检索质量不佳,则触发回退至实时网络的机制。
在部署CRAG式评估器的团队内部基准测试中,幻觉现象较原始基线显著降低。
工作原理:
- 检索阶段: 从内部向量存储库获取文档。
- 评估阶段: 轻量级“评分器”模型为每个文档片段赋予评分(正确/模糊/错误)。
- 决策门控:
- 正确: 直接进入生成器阶段
- 错误: 丢弃数据并触发外部API(如谷歌搜索或Tavily)
- 合成: 基于验证过的内部数据或新获取的外部数据生成答案
适用场景:对准确性要求极高的领域,如金融、医疗、法律咨询。
核心流程:检索 → 评估(打分)→ 决策(使用/丢弃/补充)→ 生成。
# 概念性代码,展示CRAG的决策逻辑def corrective_rag_workflow(query, vectorstore, web_search_tool): # 1. 初步检索 retrieved_docs = vectorstore.similarity_search(query, k=5) # 2. 评估检索结果(模拟一个轻量级评估器) # 在实际中,这可能是一个专门训练的微型模型或基于规则的评分器 graded_docs = [] for doc in retrieved_docs: # 简单模拟:通过检查与查询的相关性关键词来评分 relevance_score = naive_relevance_scorer(query, doc.page_content) if relevance_score > 0.7: graded_docs.append(("correct", doc)) elif relevance_score > 0.3: graded_docs.append(("ambiguous", doc)) else: graded_docs.append(("incorrect", doc)) # 3. 决策门 if any(grade == "correct"for grade, _ in graded_docs): # 有合格文档,使用它们 context = "\n".join([d.page_content for g, d in graded_docs if g == "correct"]) print("[CRAG决策]:使用内部知识库。") else: # 内部文档质量不佳,触发备用检索 print("[CRAG决策]:内部知识不足,启动备用检索。") context = web_search_tool.search(query) # 4. 生成 final_prompt = f"基于以下信息回答问题:\n{context}\n\n问题:{query}\n答案:" return llm.invoke(final_prompt)# 模拟一个简陋的相关性打分器def naive_relevance_scorer(query, doc_content): query_words = set(query.lower().split()) doc_words = set(doc_content.lower().split()) overlap = len(query_words & doc_words) return overlap / max(len(query_words), 1)# 假设我们有一个联网搜索的工具(例如 Tavily Search API 的封装)# web_search_tool = TavilySearch()
优点:大幅降低“幻觉”,实现内外知识结合。
缺点:延迟显著增加(通常2-4秒),且需管理外部API成本。
架构4:自适应RAG(Adaptive RAG)- 聪明的“资源调配者”
定位:“效率大师”。它用一个路由(Router) 判断问题复杂度,然后选择最经济高效的路径:简单问题LLM直接答,中等问题用标准RAG,复杂问题才启动多步检索。
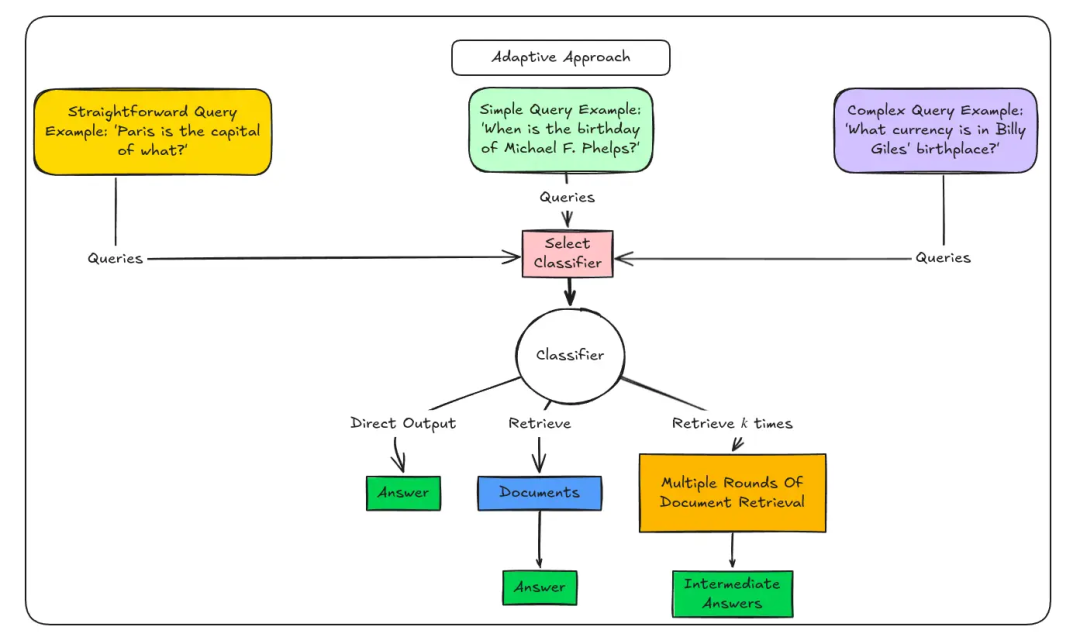
工作原理:
- **复杂度分析:**小型分类器模型对查询进行路由分发。
- 路径A(无需检索): 适用于问候语或大型语言模型已掌握的常识性问题。
- 路径B(标准RAG): 用于简单的事实查证。
- 路径C(多步智能体): 处理需跨多源检索的复杂分析型问题。
适用场景:用户问题复杂度差异大,需要兼顾响应速度与成本。
路径示例:
- 路径A(LLM直接答): “你好”、“谢谢” → 无需检索。
- 路径B(标准RAG): “图书馆开放时间?” → 简单检索。
- 路径C(复杂RAG/Agent): “对比过去五年计算机和金融专业的就业率与起薪” → 启动多步检索与推理。
from langchain_core.runnables import RunnableBranch# 1. 定义路由判断函数(实践中可用一个小型分类器LLM)def route_question(query): simple_keywords = ["你好", "嗨", "你是谁"] complex_keywords = ["比较", "分析", "趋势", "总结过去五年"] if any(kw in query for kw in simple_keywords): return"simple" elif any(kw in query for kw in complex_keywords): return"complex" else: return"standard"# 2. 定义不同处理分支def simple_chain(query): """直接回答,无需检索""" return llm.invoke(f"友好、简洁地回答用户问候或简单问题。问题:{query}")def standard_chain(query): """标准RAG流程(复用之前的retriever)""" docs = retriever.invoke(query) context = "\n".join([d.page_content for d in docs]) return llm.invoke(f"根据上下文:{context}\n回答问题:{query}")def complex_chain(query): """复杂流程,例如多步检索或调用Agent(这里简化为更深的检索)""" print("[自适应RAG]:检测到复杂问题,启用深度检索。") docs = retriever.invoke(query, search_kwargs={"k": 10}) # 检索更多片段 # 这里可以加入更复杂的处理逻辑,如重排序、多查询等 context = "\n---\n".join([d.page_content for d in docs]) return llm.invoke(f"请综合分析以下信息:\n{context}\n\n问题:{query}")# 3. 构建自适应路由链branch = RunnableBranch( (lambda x: route_question(x["query"]) == "simple", lambda x: {"result": simple_chain(x["query"])}), (lambda x: route_question(x["query"]) == "complex", lambda x: {"result": complex_chain(x["query"])}), lambda x: {"result": standard_chain(x["query"])} # 默认分支)# 4. 测试test_queries = ["你好", "年假有多少天?", "分析公司过去三年员工福利政策的变化趋势"]for q in test_queries: response = branch.invoke({"query": q}) print(f"问题:{q}") print(f"路由决策:{route_question(q)}") print(f"答案:{response['result'].content[:100]}...\n")
优点:极致的成本与速度优化,用户体验佳。
缺点:路由模型若误判,会导致回答失败。
四、高阶篇:让检索“更聪明”
架构5:融合RAG(Fusion RAG)- 多角度“会诊”,避免遗漏
定位:解决用户提问方式不佳导致的检索失败。它自动生成同一问题的多个变体,并行检索,然后融合结果,确保高召回率。
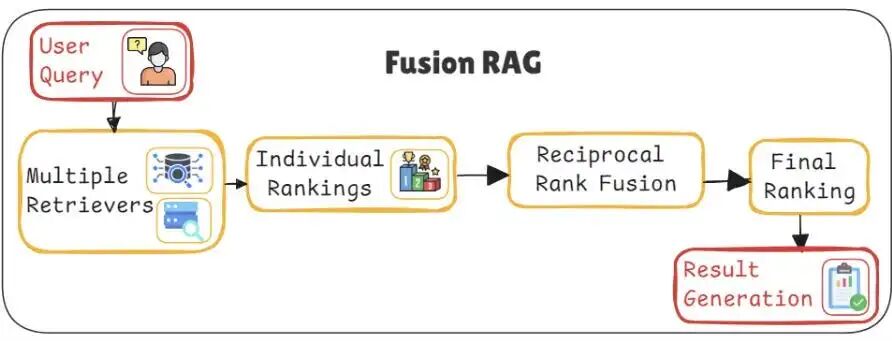
融合式RAG解决了**“模糊性问题”**。多数用户不擅长搜索。融合式RAG通过多角度解析单一查询,确保高召回率。
工作原理:
- **查询扩展:**生成用户问题的3-5种变体。
- **并行检索:**在向量数据库中搜索所有变体。
- **互补排序融合(RRF):**运用数学公式重新排序结果:
- **最终排序:**在多次检索中排名靠前的文档将被提升至顶部。
适用场景:用户提问模糊、口语化,或问题本身涉及多角度时。
核心:查询扩展 + 倒数排序融合 (RRF)。
from langchain.retrievers import ContextualCompressionRetrieverfrom langchain.retrievers.document_compressors import LLMChainExtractorfrom langchain.retrievers.ensemble import EnsembleRetrieverfrom langchain_community.retrievers import BM25Retrieverimport numpy as np# 1. 创建不同类型的检索器进行“融合”# a. 稠密向量检索器 (我们已有的)dense_retriever = vectorstore.as_retriever(search_kwargs={"k": 5})# b. 稀疏检索器 (BM25) - 需要将文档转为文本列表from langchain.retrievers import BM25Retrievertexts = [chunk.page_content for chunk in chunks]bm25_retriever = BM25Retriever.from_texts(texts)bm25_retriever.k = 5# 2. 构建集成检索器ensemble_retriever = EnsembleRetriever( retrievers=[dense_retriever, bm25_retriever], weights=[0.5, 0.5] # 可以调整权重)# 3. (可选)对检索结果进行重压缩/精炼llm_for_compression = ChatOpenAI(temperature=0)compressor = LLMChainExtractor.from_llm(llm_for_compression)compression_retriever = ContextualCompressionRetriever( base_compressor=compressor, base_retriever=ensemble_retriever)# 4. 使用融合后的检索器rag_chain_fusion = RetrievalQA.from_chain_type( llm=llm, retriever=compression_retriever, # 使用融合+精炼的检索器 chain_type="stuff")# 测试:一个模糊的查询query = "那个关于远程办公的规则"result = rag_chain_fusion.invoke({"query": query})print(f"模糊查询:'{query}'")print(f"融合RAG答案:{result['result'][:200]}...")
优点:检索召回率极高,对用户措辞不敏感。
缺点:检索成本成倍增加(3-5倍),延迟更高。
架构6:假设性文档嵌入(HyDE):先“脑补”答案,再按图索骥
定位:一种非常巧妙的反向思维。它发现“问题”和“答案”在语义上并不相似。于是,它先让LLM根据问题“脑补”一段假设性答案,然后用这段“答案”的向量去检索真实文档。
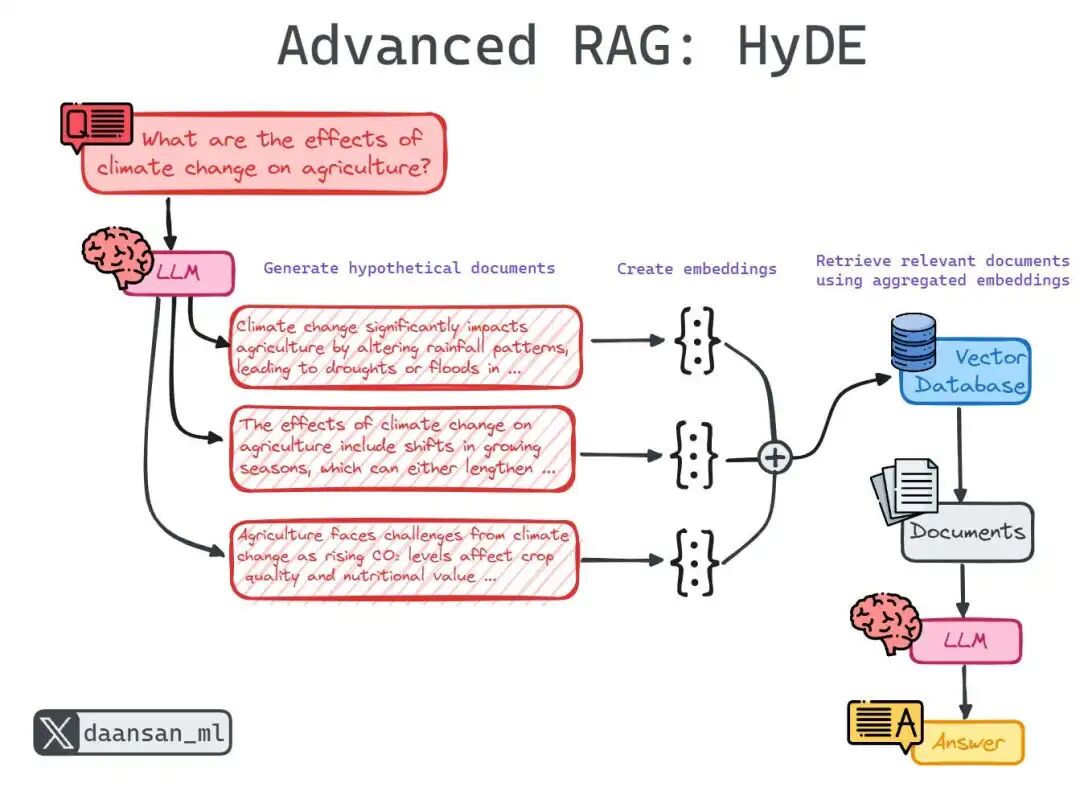
HyDE是一种反直觉却精妙的模式。它认识到“问题”与“答案”在语义上存在差异。通过先生成一个“虚假”答案,它在二者之间架起了一座桥梁。
工作原理:
- **假设生成:**大型语言模型为查询编写虚构(假设性)答案。
- **向量化:**将虚构答案转化为向量。
- **检索匹配:**利用该向量查找与虚构答案风格相似的真实文档。
- **生成最终答案:**基于真实文档撰写最终回复。
适用场景:问题非常抽象、开放,或与知识库文档表述差异大时。
工作流:问题 → 生成假设答案 → 向量化假设答案 → 用该向量检索 → 生成最终答案。
def hyde_retrieval(query, vectorstore, llm): # 1. 假设性文档生成 (Hypothetical Document Generation) hypothetical_prompt = f""" 请针对以下问题,生成一个假设性的、理想的答案段落。 这个段落应该包含回答问题所需的关键事实和表述方式。 问题:{query} 假设性答案: """ hypothetical_answer = llm.invoke(hypothetical_prompt).content print(f"[HyDE] 生成的假设性答案:{hypothetical_answer[:100]}...") # 2. 使用假设性答案的向量进行检索 # 关键:使用与构建索引时相同的embedding模型 embeddings = OpenAIEmbeddings() hypothetical_embedding = embeddings.embed_query(hypothetical_answer) # 在向量库中搜索与假设答案最相似的文档 # 注意:这里演示逻辑,实际需使用支持直接向量查询的接口 relevant_docs = vectorstore.similarity_search_by_vector(hypothetical_embedding, k=3) # 3. 基于真实文档生成最终答案 context = "\n".join([doc.page_content for doc in relevant_docs]) final_prompt = f"基于以下真实文档信息回答问题:\n{context}\n\n问题:{query}\n答案:" final_answer = llm.invoke(final_prompt) return final_answer.content# 测试一个概念性较强的问题query = "如何建立一个积极的企业文化?"result = hyde_retrieval(query, vectorstore, llm)print(f"\n最终答案:{result[:300]}...")
优点:对抽象、概念性问题的检索效果极佳。
缺点:若“脑补”方向完全错误,会带偏整个检索;不适用于简单事实查询。
架构7:自省RAG(Self-RAG)- 拥有“元认知”的AI
定位:让AI在生成过程中自我批判、自我检查。模型被训练在输出中加入特殊的反思标记(如[是否相关?]、[是否有支持?]),当标记为“否”时,模型会暂停,重新检索或改写。
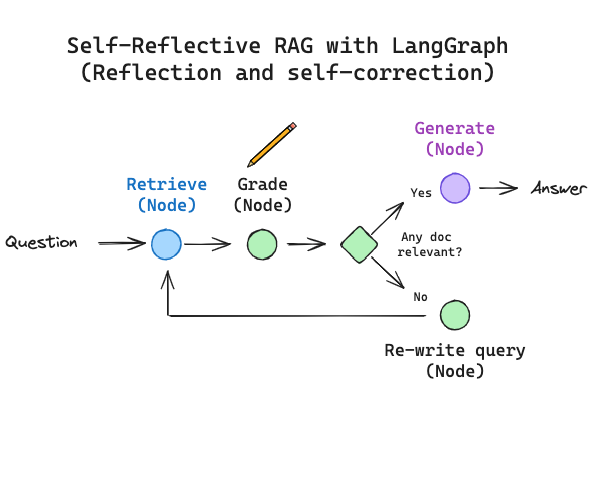 自我RAG是一种精密架构,模型经过训练可对自身推理过程进行批判。它不仅能检索信息,更能生成“反思令牌”,实时审核自身输出结果。
自我RAG是一种精密架构,模型经过训练可对自身推理过程进行批判。它不仅能检索信息,更能生成“反思令牌”,实时审核自身输出结果。
工作原理:
- **检索:**由模型自身触发的标准搜索。
- token生成: 模型在生成文本时同步生成特殊标记,如
[IsRel](是否相关?)、[IsSup](该论点是否得到支持?)和[IsUse](是否具有实用性?)。 - **自我修正:**若模型输出
[NoSup]标记,则暂停操作,重新检索信息并重写句子。
核心:需要专门微调的模型(如Self-RAG-Llama),在生成流中动态决策是否需要检索以及当前输出的可信度。其流程可以理解为:生成 -> 反思 -> (必要时)检索/重写 -> 继续生成。
# 注意:完整Self-RAG需要微调模型。此处展示其“反思”逻辑的思想。def self_rag_style_generation(query, retriever, llm): max_steps = 3 context = "" for step in range(max_steps): # 生成阶段,同时进行“反思” prompt = f""" 问题:{query} 已知上下文:{context} 请生成答案的下一部分,并在每个关键主张后评估其是否需要支持。 例如:“公司的核心价值观是创新[需要支持?是]。...” """ generation_output = llm.invoke(prompt) # 模拟解析输出中的反思标记 if"[需要支持?是]"in generation_output: print(f"[Self-RAG 第{step+1}步]:检测到需要证据的主张,触发检索。") # 提取需要验证的主张,将其作为新查询 claim_to_verify = extract_claim(generation_output) new_docs = retriever.invoke(claim_to_verify) context += "\n" + "\n".join([d.page_content for d in new_docs]) # 继续循环,基于新上下文重新生成或修正 else: print(f"[Self-RAG 第{step+1}步]:生成内容可信,完成回答。") return generation_output return"经过多次检索与验证,答案如下:..." + generation_output# 这是一个高度简化的概念演示,真实Self-RAG在模型内部完成。
优点:事实准确性最高,推理过程透明。
缺点:需要定制模型,计算开销巨大。
五、顶级架构:当RAG成为“智能体”与“关系大师”
架构8:智能体RAG(Agentic RAG)- “调度专家”团队
定位:将RAG从“检索-生成”的被动流程,转变为由智能体(Agent)主动规划、执行、迭代的复杂任务求解过程。智能体可以决定调用哪些工具(数据库、搜索、API)、是否进行多轮交互。
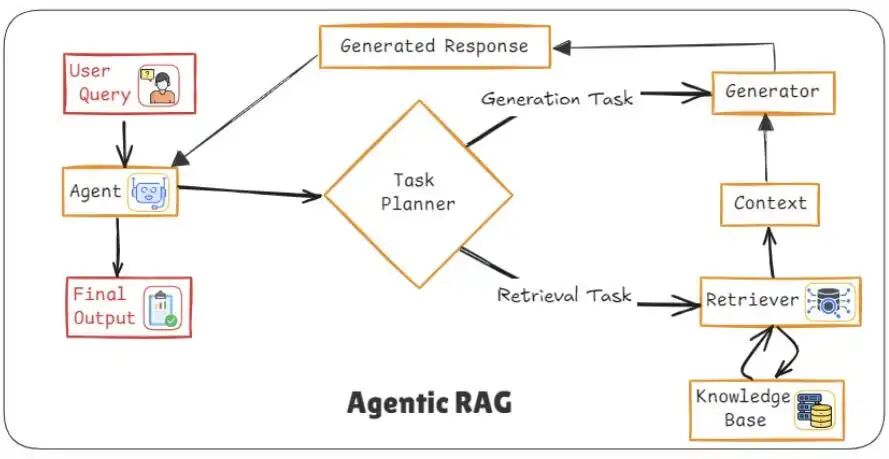
与其盲目抓取文档,它引入了一个自主智能体,在生成答案前会规划、推理并决定如何及何处检索信息。
它将信息检索视为研究而非简单查询。
工作原理:
- 分析阶段:
智能体首先解析用户查询,判定其属于简单查询、多步骤查询、模糊查询或实时数据需求。 - 规划阶段:
将查询分解为子任务并制定策略。
例如:应优先进行向量搜索?网页搜索?调用API?还是提出后续问题? - 执行:
智能体调用向量数据库、网页搜索、内部API或计算器等工具执行步骤。 - 迭代:
基于中间结果,智能体可优化查询、获取更多数据或验证来源。 - 生成:
收集充分证据后,大型语言模型生成基于事实、感知上下文的最终响应。
适用场景:极度复杂、多步骤、需要逻辑推理或实时数据的问题。
Python实现:“根据公司财报、近期新闻和行业报告,分析我们下一季度的主要风险并给出应对建议。”
from langchain.agents import AgentExecutor, create_tool_calling_agentfrom langchain_core.prompts import ChatPromptTemplatefrom langchain.tools.retriever.tool import create_retriever_tool# 1. 将检索器包装成智能体可用的“工具”retriever_tool = create_retriever_tool( retriever, "company_knowledge_search", "搜索公司的内部知识库,如员工手册、政策文件、产品文档等。")# 2. 可以定义更多工具(模拟)# web_search_tool = TavilySearchResults()# calculator_tool = ...# 3. 创建智能体tools = [retriever_tool] # 可以加入更多工具prompt = ChatPromptTemplate.from_messages([ ("system", "你是一个专业的商业分析助手。利用你手头的工具,全面、准确地回答用户问题。"), ("human", "{input}"),])agent = create_tool_calling_llm(llm, tools, prompt)agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)# 4. 执行一个需要规划的任务complex_query = """我们计划推出全员居家办公政策。请先找出公司现有的远程办公指导原则,然后分析可能面临的人力资源和IT支持挑战。"""result = agent_executor.invoke({"input": complex_query})print(result["output"])
LangGraph实现示意(这是更高级的框架,用于构建有状态的智能体工作流):
# 高级概念,展示工作流# 1. Agent分析:“用户想对比五年数据,这需要分步进行。”# 2. Agent规划:# - 步骤1:从知识库检索“计算机专业历年报告”# - 步骤2:从知识库检索“金融专业历年报告”# - 步骤3:调用“数据提取工具”从报告中抓取就业率和起薪# - 步骤4:调用“计算工具”进行对比分析# - 步骤5:生成总结报告# 3. Agent执行并循环,直到得到满意结果。
优点:处理复杂、多步骤、开放式问题的能力极强。
缺点:延迟高,成本高,需要精细的智能体编排。
架构9:图RAG(GraphRAG)- 从“文档检索”到“关系推理”
定位:革命性的范式转变。它不再仅仅检索相似的文本片段,而是检索知识图谱中的实体和关系。它将知识构建成图(节点=实体,边=关系),通过图遍历来发现实体间的连接路径,从而回答涉及多跳推理、因果关系的问题。
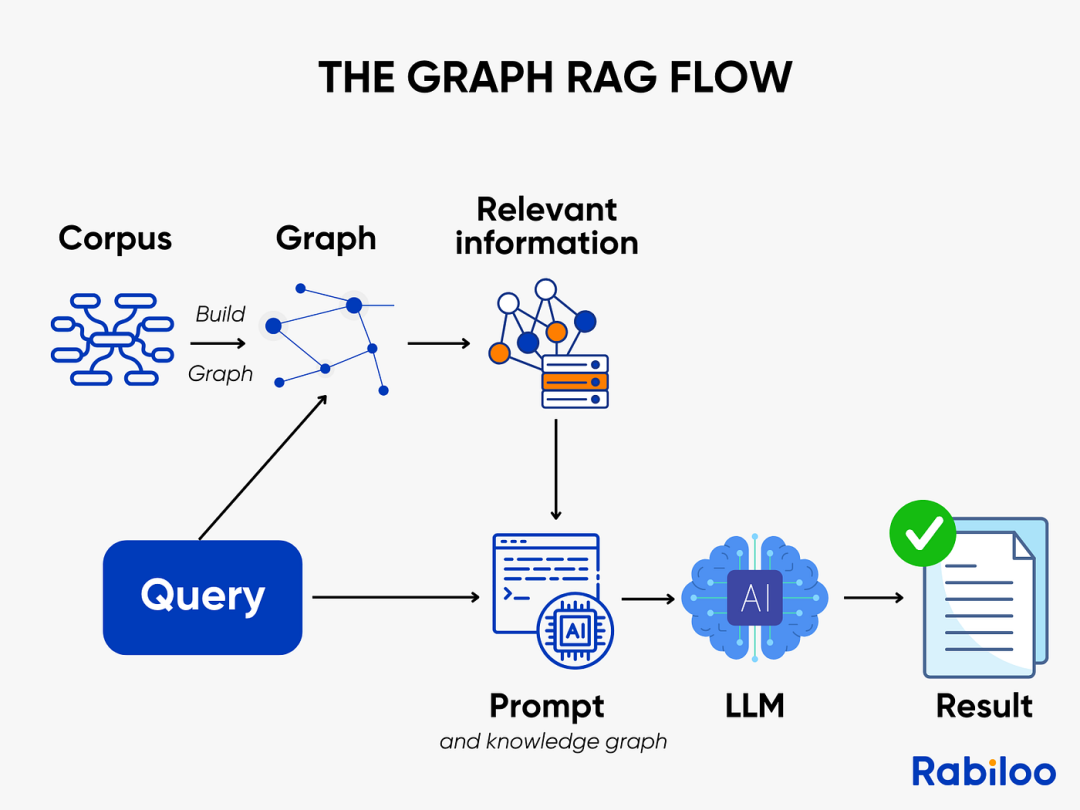
虽然所有现有架构都基于语义相似性检索文档,但GraphRAG检索的是实体及其之间的显式关系。
它不再追问“哪些文本相似”,而是探究“哪些元素相连,如何相连”。
工作原理:
- 图构建:
知识被建模为图结构,其中节点代表实体(人物、组织、概念、事件),边代表关系(影响、依赖于、资助于、受监管于)。 - 查询解析:
分析用户查询以识别关键实体和关系类型,而非仅提取关键词。 - 图遍历:
系统遍历图结构,寻找能跨多跳连接实体的有意义路径。 - 可选混合检索:
常结合图结构使用向量搜索,将实体锚定于非结构化文本中。 - 生成:
大型语言模型将发现的关系路径转化为结构化、可解释的答案。
场景:“美联储加息如何通过风险资本影响到我们公司C轮融资的估值?”
工作流:用户查询 → 识别实体和关系 → 在图数据库中遍历路径(如:美联储 → 提高利率 → 影响 → 风险投资意愿 → 影响 → 初创公司估值) → 生成解释性答案。
Python实现:通常涉及Neo4j、NebulaGraph等图数据库,以及py2neo、langchain-graph等库。代码较为复杂,但其核心优势在于可解释的、基于关系的推理。
# 概念性伪代码,展示Graph RAG思路def graph_rag_query(query, graph_db, llm): # 1. 从查询中提取实体和关系意图 (可使用NER模型) entities = extract_entities(query) # e.g., ["美联储", "加息", "公司估值"] # 2. 在图数据库中查询连接这些实体的路径 # Cypher查询示例 (Neo4j): MATCH p=(:Entity {name:"美联储"})-[:AFFECTS*..3]->(:Entity {name:"公司估值"}) RETURN p paths = graph_db.query_relationship_paths(entities) # 3. 将发现的路径转换为文本描述 context = "" for path in paths: context += f"- {path.describe()}\n" # 4. 生成基于关系的答案 answer_prompt = f""" 基于以下实体间的关联路径,回答问题: {context} 问题:{query} 请清晰阐述其中的因果或影响链条。 答案: """ return llm.invoke(answer_prompt)
优点:擅长因果、多跳推理,输出可解释性强。
缺点:知识图谱构建和维护成本极高,不适用于非结构化、快速变化的知识。
如何选择?一张决策地图给你答案
面对九种架构,莫慌。记住这个五步决策法:
- 无脑第一步:先用标准RAG跑通全流程。基础不牢,地动山摇。
- 按需加功能:
- 需要多轮对话?→ 对话型RAG
- 用户问题五花八门,有难有易?→ 自适应RAG
- 答案必须绝对准确,错了后果严重?→ 校正型RAG (CRAG)
- 解决特定痛点:
- 用户总问不清楚,检索老失败?→ 融合RAG
- 问题很抽象、概念化?→ HyDE
- 需要AI自我审查、高可靠报告?→ 自反思RAG(预算充足时)
- 应对复杂场景:
- 问题需要拆解、规划、使用多种工具?→ 智能体RAG
- 核心是分析人物、事件、事物之间的关系和影响?→ 图RAG
- 大胆做混合:生产系统往往是杂交体。例如:自适应路由 + 标准/校正双通道,让95%的简单请求走高速路,5%的疑难杂症走质检通道。
写在最后
RAG不是魔法,无法拯救糟糕的数据或混乱的业务逻辑。但它确实是将大语言模型从“才华横溢的幻想家”转变为“值得信赖的专业顾问”的最关键桥梁。
从简单的文档问答,到复杂的商业分析与关系推理,RAG的九大架构为你提供了从简到繁的全套工具箱。最好的架构,永远是最适合你当前业务约束和用户需求的那一个,而不是最复杂、最时髦的那一个。
希望本文的解析和代码能成为你探索RAG世界的实用指南。你正在尝试哪种RAG架构?在项目中遇到了哪些独特的挑战?欢迎在评论区分享你的见解与经验!
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献604条内容
已为社区贡献604条内容

所有评论(0)