基于Spring AI的社区志愿助手项目复盘Day3--向量存储
这一章节将讲解如何实现将资源向量化存储,大模型可以基于存储内容完成对用户问题的精准回答;同时与简单demo不同的是,这一需求涉及前后台消息同步,而不是简单的在编译器进行存储。
摘要: 这一章节将讲解如何实现将资源向量化存储,大模型可以基于存储内容完成对用户问题的精准回答;同时与简单demo不同的是,这一需求涉及前后台消息同步,而不是简单的在编译器进行存储。
项目概要
基于传统的社区志愿管理系统进行智能化升级,原系统主要分为后台管理员端和前台用户端:
后台:活动管理、礼品管理、培训管理
前台:活动报名、礼品兑换、培训报名、评价反馈
技术栈
SpringBoot+Spring AI+Redis+Redis-Stack+RabbitMQ+MyBatis+MySQL+Docker+minio
所有的中间件存储在Linux虚拟机的docker中
优化需求
1. 客服询问用户姓名和id,作为聊天界面标题展示,并存储在上下文中
2. 客服具有与项目贴合的身份,如“小志”,编写适当的prompt
3. 客服具备会话记忆和会话回显功能
4. 后台活动信息、培训信息和礼品信息发出后,前台可以同步到这些信息,并根据数据库中有的信息进行回答问题
5. 用户可以在聊天界面提供额外补充的信息进行预约活动、培训,要求智能补齐系统中已经存在的信息,比如当前登录用户的姓名、id
6. 将社区相关文档以pdf形式存入聊天客服,客服可以依据文档回答,并且后台可以动态管理文档
需求4:信息同步和向量化
4.1实现思路
后台正常完成对于活动信息的crud代码实现,改造的地方在于controller层。(礼品、培训等实现逻辑一致)
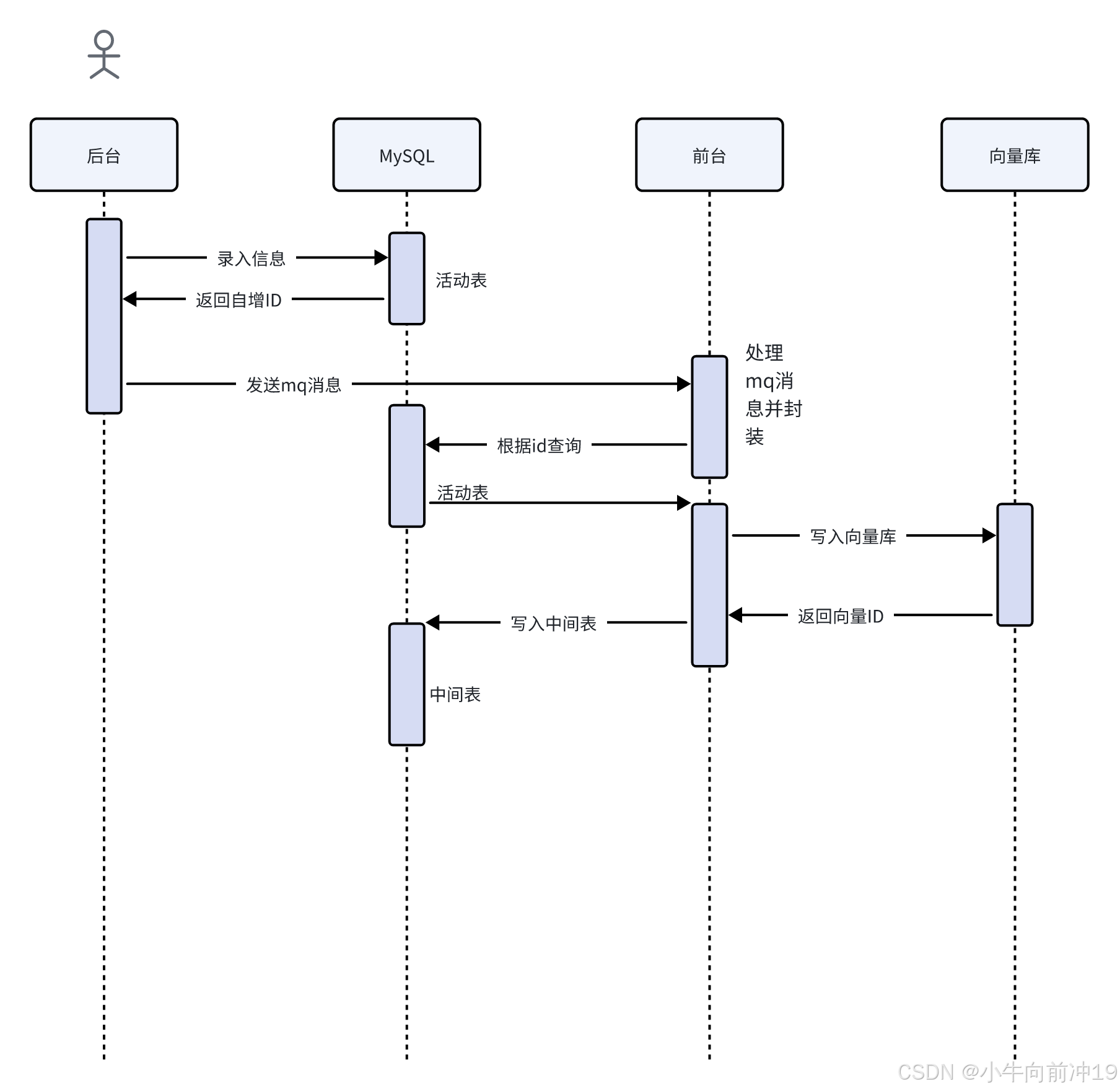
主要流程:
1. 后台操作活动信息并存入活动表中,同时使用消息队列维护一个message(包含了活动的id和类型type)
2. 发送消息队列到前台,前台进行消息处理和封装,根据id和类型查找对应表,例如这里是活动就去查找活动表格
3. 从数据库中拿到数据后进行向量化存入redis-stack,并新增一个中间表(活动id-向量id)便于后续修改删除
4. 修改prompt提示词,让大模型根据向量化的信息进行检索回答
4.2编码实现
Step1:编写消息队列
在后台里编写RabbitSendService类,这里以新增活动为例,编写sendAddActivity方法供controller层调用
public void sendMessage(String ids, int operation, String type) {
MessageDto messageDto = MessageDto.builder()
.ids(ids)
.operation(operation)
.type(type)
.build();
rabbitTemplate.convertAndSend(type, JSON.toJSONString(messageDto));//根据type向不同的queue发送消息 并把messagedto转变为json格式
}
public void sendAddActivity(String ids){
sendMessage(ids,1,"Activity");
}
Step2:发送消息
Controlller层:在操作完数据库之后,将活动id作为参数调用sendAddActivity方法
@Log(title = "活动", businessType = BusinessType.INSERT)
@PostMapping("/add")
@ResponseBody
public AjaxResult addSave(Activity activity)
{
ActivityService.insertAcivity(activity);
rabbitSendService.sendAddActivity(activity.getId());//发送消息到mq 让前端可以接收到新增的活动id 这里插入后自动生成id 才能拿到keyProperty="id": 将生成的主键值设置到实体类的 id 属性
return toAjax(activity!= null);
}Step3:前台接受消息并处理
可以看到在step1编写消息队列相关方法时候,我用“Activity”作为参数,那么培训、礼品都有各自的参数,所以这里前台接受信息时候采用工厂模式去决定到底实例化哪一个,依据就是传递来的信息类型。
工厂模式
- MessageReveiver类:
@Component
@RabbitListener(queuesToDeclare = {
@Queue("Activity"),
@Queue("Peixun")})
public class MessageReceiver {
private final static Logger logger = LoggerFactory.getLogger(MessageReceiver.class);
@Autowired
private VectorServiceFactory vectorServiceFactory;
@RabbitHandler
//消息队列消费端,接受管理后台的增删改信息,详细参数参考MessageDto对象
//处理管理后台传递过来的Rabbitmq消息
public void processMessage(String message) {
logger.info("user hit : message={}", message);
//封装message
MessageDto messageDto = JSON.parseObject(message, MessageDto.class);
//根据messageDto.getType()从工厂获取匹配的实现类
//根据messageDto.getOperation(),获取操作类型:1-新增,2-修改,3-删除
switch (messageDto.getOperation()) {
case 1: // 新增
// 获取对应的向量服务实现 工厂模式
//IVectorService vectorService = vectorServiceFactory.of(messageDto.getType());
//vectorService.addDocument(messageDto);
vectorServiceFactory.of(messageDto.getType()).addDocument(messageDto);
break;注:由容器管理,已经注入,在写的时候不要再重复new:of方法可以拿到已经在容器中的实例,直接调用addDocument方法即可。
//IVectorService vectorService = vectorServiceFactory.of(messageDto.getType());
//vectorService.addDocument(messageDto);
vectorServiceFactory.of(messageDto.getType()).addDocument(messageDto);- VectorServiceFactory类
接受到消息后,先根据操作类型(增删改)进行抉择,比如新增:VectorService作为父类调用工厂方法of选择对应的实例,此方法返回已由Spring容器管理的 materialsVectorService 或 noticeVectorService的Bean
//VectorService类的of方法
public IVectorService of(String mesageType) {
if(mesageType.equals("Peixun")){
return peixunVectorService;
}
return activityVectorService;
}Step4:将消息向量化
可以看到在step3中有addDocument方法,对于不同的信息类型有不同的addDocument方法(涉及不同的数据库表),这里对于不同文件类型的消息处理还可以采用模版模式,后续会进行优化。
- ActivityServiceImpl
@Override
public void addDocument(MessageDto messageDto) {
//获取dto里的messageId,对应Notice表的id
String souceId = messageDto.getIds();
if (souceId == null || souceId.isEmpty()) {
log.error("ID不能为空: {}", messageDto);
return;
}
log.info("messageId: {}", souceId);
//查找activity表,找到后台录入的校园墙记录
Activity activity = activityService.getBySouceId(souceId);
//构建Document对象,并调研store的add保存到向量库
Document document = new Document(activity.getContent());
store.add(Arrays.asList(document));
//从上步中的Document对象,获取id(向量库的id)记录到document_ids表,后续删除要用
String stackId = document.getId();
log.info("向量库的id为:{}", stackId);
documentIdsMapper.add(messageDto.getType(),souceId,stackId);
}到这里,后台发布的活动信息就被向量化到redis-stack中,通过优化prompt就可以让客服基于向量库进行检索,重新拼接prompt给大模型,返回忠于检索的回答。
小结
这一章节简单介绍了基本的实现基于向量库内容回答问题以及前后台消息同步的方法,只是一个简单的demo,如果想进一步提高大模型回答准确率还需要在相似对比和向量化上做更多调整,这一demo对于AI应用开发来说,可以简单了解一下实现的原理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)