【AI 风向标】2026开年新概念 - 万字讲清 Agent Skills
技能工程(Skills Engineering)正重构人机协作方式,通过封装领域知识为可动态加载的指令包,使通用大模型获得专业化执行能力。2026年初,ClaudeSkills从开发者圈层扩散至普通用户,GitHub技能库获5万星标,爆款应用安装量超4800次。Skills采用三层渐进式架构:元数据目录、详细步骤手册和按需加载的参考资料,实现70-90%的token节省。相比传统多Agent架构,
目录
2.2 上下文窗口动态变化过程:Skills 如何参与运行?
Skills vs MCP(Model Context Protocol)
今年年初,以
Claude Skills为代表的技能工程(Skills Engineering)正在重构人机协作的底层逻辑。这一技术通过将可重复的领域知识封装为可动态加载的指令包,使通用大语言模型具备专业化执行能力,和2024年的提示词工程和2025年的上下文工程形成演进链条,Skills 标志着AI应用从对话交互向任务执行的关键跃迁。
当前,Skills 已从开发者圈层渗透至普通职场人士,GitHub 官方 Skills 库收获近 5 万星标,技能商店中出现超4800人安装的爆款应用。
1.Skills 起源和发展轨迹
开年爆火的 Skills 其实早在去年就已经出现,这项技术也是经历了典型的技术扩散轨迹:
2025年10月:Anthropic 发布Agent Skills,彼时限于开发者小范围关注;2025年11-12月:技能规范开放,生态快速扩展;2026年1月:产品更新叠加非编程场景落地,触发病毒式传播。
Skills 的关键转折点在于非技术用户的涌入,大量用户开始将 Claude Skills 用于度假研究、PPT制作、邮件清理、烤箱控制等非编码场景,这种跨界应用推动了技术出圈。
2025年10月16日,Anthropic 在一篇名为 Equipping agents for the real world with Agent Skills 的文章中正式提出Agent Skills概念。
文章开头便引出:“Claude 模型很强大,但真正的落地还需要特定的组织框架、业务流程,以及实际生产知识。为此,我们推出 Agent Skills 这样一个可以直接利用公司内部文件的新生产方式”
Claude is powerful, but real work requires procedural knowledge and organizational context. Introducing Agent Skills, a new way to build specialized agents using files and folders.
可见,Agent Skills旨在解决通用AI只懂道理却不会干活的核心痛点。
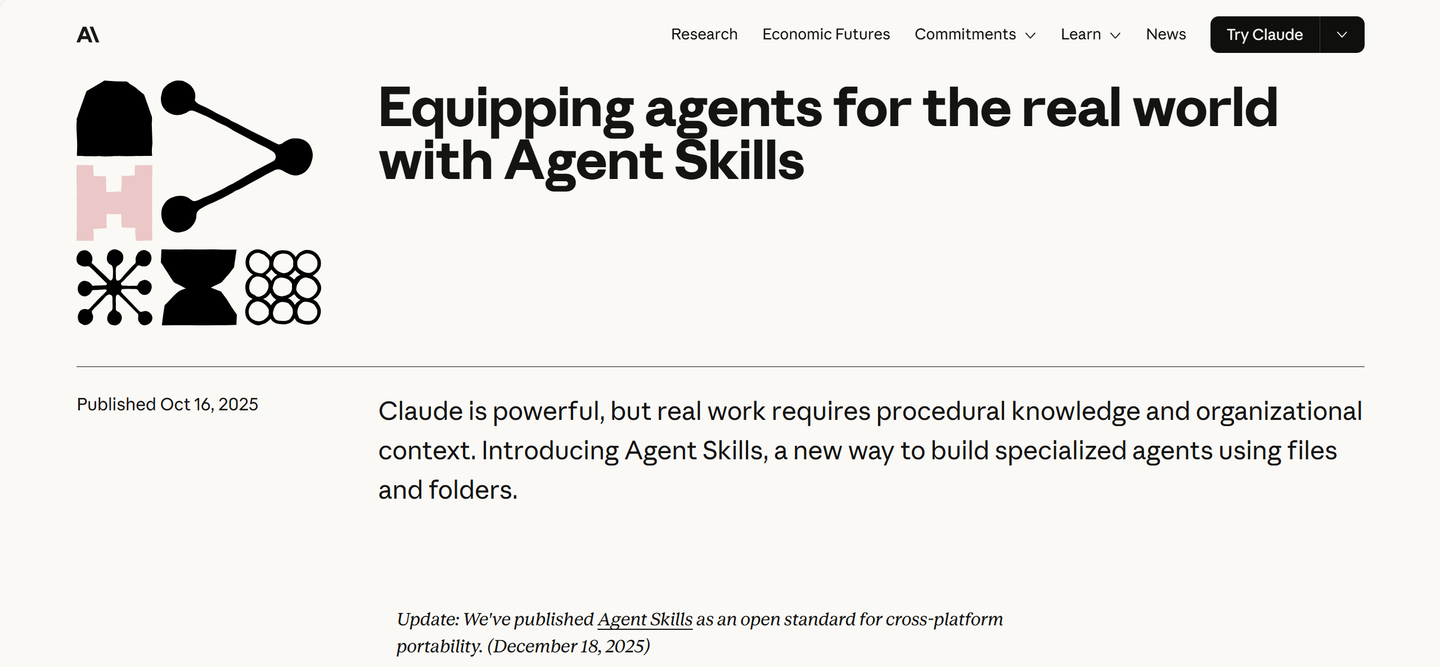
Anthropic 推出 Agent Skills 原文
传统大模型虽能生成代码或文本,但缺乏对特定组织框架、业务流程和品牌规范的深层理解。例如,DeepSeek 虽能编写代码,却不知道开发团队的具体技术栈;Kimi 能生成分析报告,但无法理解企业独特的财务审批链条。
通俗一点来说,原本的通用 Agent 是公司新招来的某个行业专家,即使能力再强,也需要一段 landing 期来熟悉公司内部的业务推进方式、审批流程,甚至是部门间微妙的人际关系。而一个skill就是为这个新入职员工建立的入职手册和原有业务文档。
在多家公司上过班的应该都有体会,公司里流程是否够简单清晰、业务介绍是否够明确,真的很影响工作上手速度和体感。
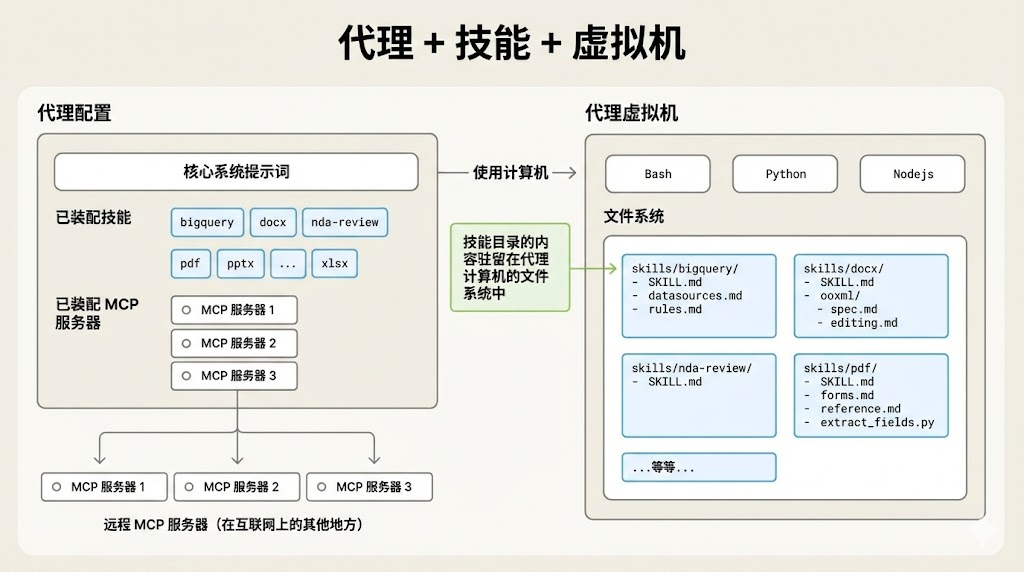
Skills 原理图(翻译版)
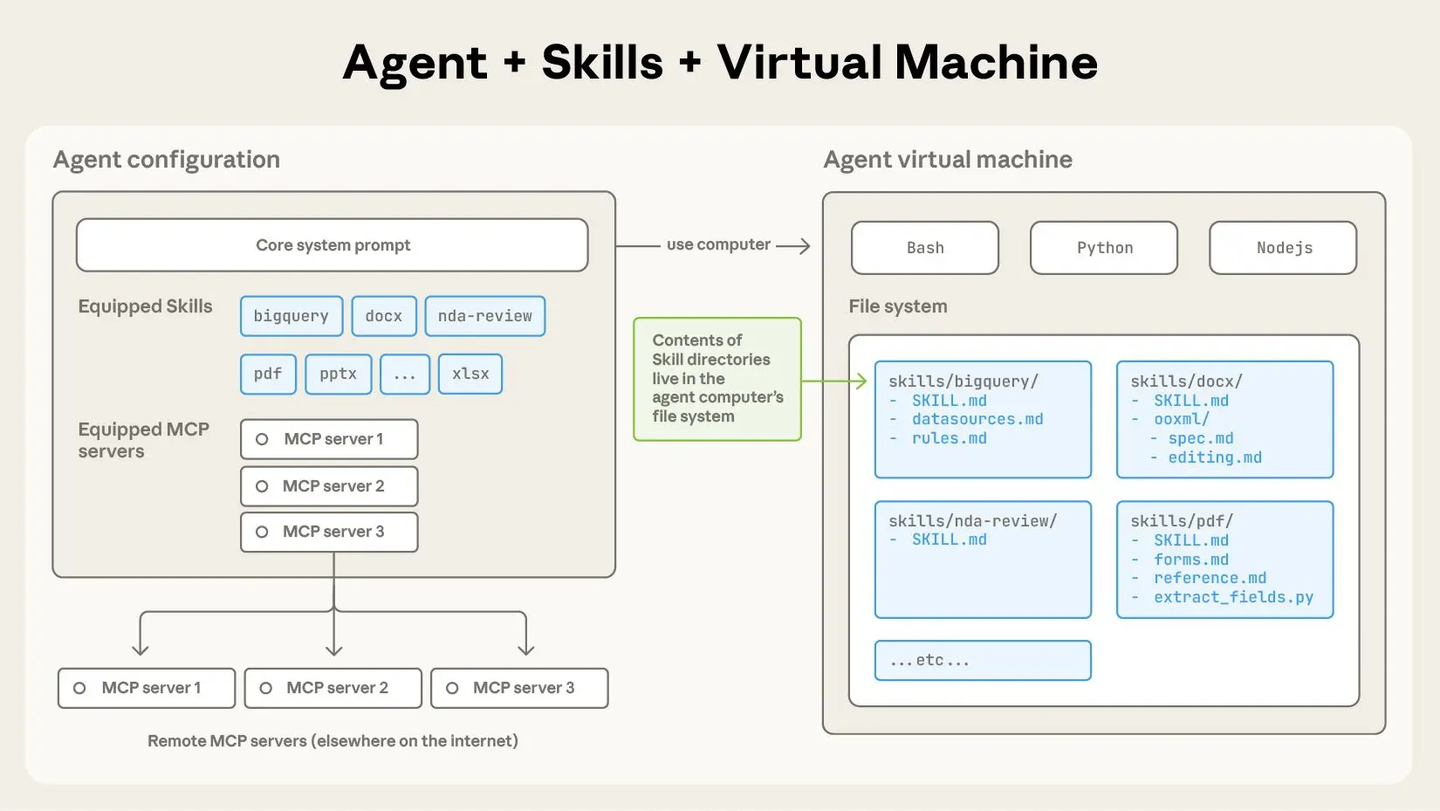
Skills 原理图(Anthropic 原版)
|
现实世界 |
Agent 世界 |
|
员工 |
Agent |
|
岗位说明书 |
核心系统提示词 |
|
技能证书 |
Skills |
|
电脑 |
Agent 虚拟机 |
|
软件 |
Python / Bash |
|
公司系统 |
MCP 服务 |
2025年12月18日,Anthropic 将Skills规范开源为开放标准,并交由 Linux 基金会管理 。这标志着Skills从单一产品功能演变为行业通用标准,与MCP(Model Context Protocol)形成互补生态。
2.通俗讲解:到底什么是 Skills?
2.1 核心原理与架构机制
为真正了解Skills的核心原理和架构机制,我找到了Anthropic最初发布的 Equipping agents for the real world with Agent Skills ,里面 The anatomy of a skill 部分清晰明了地介绍了 Skills 的原理架构。

但在这里我想用开头提到的新员工landing方式来更通俗地讲解:
核心概念:给AI一本工作手册
想象你新招了一位超级聪明的实习生(Claude),但TA刚入职时:
懂通用知识,但不知道公司的具体流程;会写代码,但不懂组里的技术规范;能分析数据,但不知道具体的业务逻辑
Skills就是给这位实习生准备的 Landing 文档。这个过程不是重新训练一个AI,而是把特定领域的操作指南、工具脚本、参考资料打包成文件夹,让TA在需要时查找学习,然后立刻执行。
在架构上,Skills 采用的是三层渐进式披露架构(Progressive Disclosure):
这是Skills最精妙的设计,它就像一本分层的说明书,不是一次性把1000页扔给AI,而是按需加载。
第一层:目录索引(元数据,metadata)
每次对话开始时,AI只看"目录",包括技能名称(最多64字符)和一句话描述(最多1024字符)。
就像这位新入职的实习生,刚接到一个新需求时,先翻一下组内知识库的目录,判断和手头上的项目有没有关系,以此来看需不需要打开查看详细步骤。
这一层只占用约100个token,AI可以同时知道几百个技能的存在,并且不增加任何负担。
第二层:详细步骤(SKILL.md)
当AI通过metadata判断这个任务需要某个skill时,它会调用Bash工具读取选中的SKILL.md,将其中的完整指令加载到上下文中,到这一步AI才真正学会如何具体操作。
在写SKILL.md时需要注意一些技术细节:文件采用YAML前导格式(类似简历开头的个人信息区);包含name、description等元数据(也就是上面提到的第一层);主体是Markdown格式的详细指令。
第三层:参考资料(链接文件)
在真实工作场景下,主手册往往会放不下太复杂的情况(类似于我们平时在公司都没时间看的文档),比如:
各种表单填写规则(forms.md)品牌视觉规范(brand-guide.pdf)代码示例库(examples.py)
而AI只会在特定子任务时才去读取这些文件。比如填表时才看forms.md,做数据分析时忽略它。

一个简单的 SKILL.md 文件示例
|
层级 |
文件 |
触发时机 |
Token 消耗量 |
|
1 |
SKILL.md 索引/目录(元数据) (YAML格式) |
始终可见 |
~100 |
|
2 |
SKILL.md 主体手册 (Markdown格式) |
技能相关时加载 |
~1,500+ |
|
3+ |
链接文件(文档、脚本、数据) |
必要时加载 |
按需加载 |
2.2 上下文窗口动态变化过程:Skills 如何参与运行?
这里的上下文窗口也可以理解为AI调用每一层Skills的触发时机,这里我们沿用Anthropic举的让Claude填写PDF表单的例子。
阶段1:初始状态(对应第一层Skills)
用户需要在一份PDF版的电子合同里填写内容,于是在对话窗口输入“用PDF技能填写这份合同”;AI看到“PDF技能”的描述,判断出“我需要详细操作手册”。
[系统提示] + [技能目录] + [用户消息]
↑
"用PDF技能填写这份合同"阶段2:加载主手册(对应第二层Skills)
当AI判断出需要阅读PDF的操作手册后,就会加载出对应的SKILL.md进行阅读。
[系统提示] + [技能目录] + [用户消息] + [SKILL.md完整内容]
↑
"明白了,先读取PDF,再识别表单字段,然后填写"阶段3:按需加载子手册(对应第三层Skills)
[系统提示] + [技能目录] + [用户消息] + [SKILL.md] + [forms.md]
↑
"这个表单看起来像W-9税务表,按照forms.md的特殊规则处理"阶段4:执行任务
[系统提示] + [技能目录] + [用户消息] + [SKILL.md] + [forms.md] + [执行结果]
↑
"已填写完毕,请检查"整个过程中,AI不会一次性加载所有PDF技能相关的10,000 tokens资料,而是像人类一样边做边学,token消耗量会降低70-90%。
2.3 代码执行:Skills 可以给 AI 配备工具箱
Skills 不仅可以是YAML和Markdown格式的文档,还可以包含提前写好的可执行代码。这一步极大地保证了 Skills 的稳定运行。
首先澄清一件事:Skills 本身不是可执行代码。
一个 Skill 的核心是 SKILL.md(一份大提示词+说明书),它不会自己去跑像Python和JavaScript这样的代码。真正跑代码的主体仍然是 AI 的工具系统(比如Bash、code execution),Skills 只是告诉 AI:“在某一步,请用 Bash 去执行某个脚本,然后再根据结果继续推理。”
一份涉及到代码的标准Skill目录大致是这样:
my-skill/
├── SKILL.md # 说明书(主提示词)
├── scripts/ # 这里放可执行脚本(Python / Bash 等)
│ └── helper.py
├── references/ # 需要读进上下文的文档
└── assets/ # 模板、二进制文件等,只按路径引用其中,scripts/ 里放的是要执行的代码,典型用途:
数据解析、转换(如分析代码库、清洗日志)跑各种命令行工具(git、npm、pdftotext 等)做复杂、多步骤、对结果要求 100% 确定的操作Skill 里通过诸如 python {baseDir}/scripts/analyzer.py ... 这样的命令来引用脚本。
{baseDir} 是一个自动替换的变量,表示当前这个 Skill 在本地的安装路径,这样技能可以在不同机器、不同项目路径下通用,不用写死绝对路径。
那么,AI 如何决定要跑哪个脚本呢?这一步主要靠 LLM 自己读描述做匹配。
对话一开始,AI 只看到了所有 Skills 的name + description列表(存在Skill工具的描述里),比如:
pdf:用于处理 PDF、提取文字、填写表单codebase-visualizer:用于扫描代码库生成结构图
当你说:“帮我把这个 PDF 里的表单字段提取出来”,AI 会觉得这个需求和pdf这个 skill 的描述非常贴近,于是调用 Skill 工具command: "pdf"。
一旦选中了某个 Skill,系统会把pdf/SKILL.md整个读出来,作为一段新的指令注入对话(隐藏在元消息里),在这份指令里,用户会提前写好类似如下内容:
当需要抽取 PDF 表单字段时:
- 调用 Bash 工具执行:
`python {baseDir}/scripts/extract_form_fields.py --input "$PDF_PATH" --output form_fields.json`
- 执行完后,读取 `form_fields.json`,解析其中的字段信息,再根据用户需求进行后续处理AI 读到这段 Markdown,再结合当前任务就会在下一步工具调用中发起一个 Bash 调用,例如:
{
"tool": "bash_code_execution",
"input": {
"command": "python /home/user/.claude/skills/pdf/scripts/extract_form_fields.py --input \"contract.pdf\" --output form_fields.json"
}
}Bash 工具真的在沙箱里跑这条命令,执行脚本,回传命令执行结果(output form_fields.json)。AI 再读取 form_fields.json,用自己的自然语言能力理解这些结果,继续完成后续推理与回答。
官方原文里有一句话很重要:PDF skill 里有个 Python 脚本用于读取 PDF 并提取所有表单字段,Claude 可以运行这个脚本,而不需要把脚本本身或者 PDF 内容加载进上下文。
In our example, the PDF skill includes a pre-written Python script that reads a PDF and extracts all form fields. Claude can run this script without loading either the script or the PDF into context.

这句话背后有两层意思:
脚本文件本身不作为文本喂给模型:上下文里只会出现一句命令(比如python {baseDir}/scripts/extract_form_fields.py...),但脚本的源代码不会被当文本塞进 prompt,节省大量 token。大文件(PDF)也不必全文进上下文:由脚本在沙箱中直接操作 PDF 文件(比如用某个 PDF 库提取表单信息),最后只把结构化结果(如 JSON 字段列表)返回给 Claude,Claude 再基于这些简洁结果进行分析与生成文本。
最终效果是:将“重 IO、重计算、大文件处理”的部分交给脚本,这样既省 token,又提速,还更稳定。
代码执行的价值是用“确定性代码”补足“随机性模型”。LLM 存在两个天然相反的特性:优点是理解、推理、生成都很强;但短板也很明显,计算、排序、格式严谨场景容易出错,同样的提示,多次生成会有差异(模型的非完全确定性)。而代码执行正好与之互补。
典型适合写成脚本的任务:
排序/过滤/统计:用生成文本来排序数百条记录既慢又可能错,但用脚本一次 sort / filter / groupby 就能稳定搞定。复杂文件/目录操作:扫描整个代码库统计语言比例、文件大小;将若干 Markdown 合并为一个文档;将 CSV 转成特定 JSON 结构。多步流水线任务:例如npm install && npm run lint && npm test 这种 CI/CD 流程。调用第三方命令行工具,如pdftotext、ffmpeg、git、exiftool...
在 Skill 中的常见模式是这样的:
## 分析流程(写在 SKILL.md 中)
1. 使用 Bash 工具执行:
`python {baseDir}/scripts/analyzer.py --path "$TARGET_DIR" --output report.json`
2. 用 Read 工具读取 `report.json`
3. 解析其中的字段,生成自然语言总结(风险点、建议等)从架构上看,这是一个清晰的混合链路:Prompt设计好流程 → Claude 做决策 → 通过 Bash / code_execution 工具跑脚本 → 解析结果 → 再继续高级推理和生成。
3.和过往架构的对比:Skills 独特在哪儿?
Skills vs MCP(Model Context Protocol)
很多一线工程师的共识可以概括成这句话:Skills 解决“怎么做”(方法论 / 工作流),MCP 解决“连到哪儿”(连接外部系统)。两者构成互补关系而非替代关系:
|
对比维度 |
Claude Skills |
Model Context Protocol |
|
设计目标 |
封装人类工作流和领域知识为可复用指令 |
为LLM调用外部工具提供统一接口 |
|
触发机制 |
自动检测,无需显式调用 |
代理通过协议显式调用函数 |
|
配置复杂度 |
创建文件夹和Markdown文件,无运行时服务 |
需部署MCP服务器,编写JSON配置 |
|
Token效率 |
渐进披露,初始开销极小 |
通常需预加载API文档,消耗数千tokens |
|
执行环境 |
完全在Claude沙箱内运行 |
外部服务器执行,返回结果给Claude |
|
安全模型 |
运行用户安装的受信任代码 |
通过权限控制外部资源访问 |
|
适用场景 |
嵌入专业知识和内部流程 |
连接实时数据源和遗留系统 |
Skills = 方法论层 / 能力层:把一套业务流程、写作规范、分析步骤,封装成一个可复用的“数字 SOP + 小脚本工具箱”,完全在 Claude 环境里跑。
MCP = 协议层 / 基础设施层:提供一个标准接口,让任何 LLM 可以通过统一协议访问外部系统(数据库、GitHub、ERP、SaaS、IoT…)。
如果把整个 AI 体系想象成一栋楼:
一楼机房:MCP,负责“水电气网”接进来(各种外部系统和工具)楼上的办公室:Skills,负责“大家具体怎么用这些资源干活”(流程、规范、组合动作)
Skills 可以是本地文件夹里的“能力包”,形态上非常朴素:一个文件夹 + 一堆文本/脚本。
my-reporting-skill/
├── SKILL.md # 说明书 + 大提示词 + 流程
├── scripts/ # Python / Bash 等脚本
├── references/ # 参考文档(SOP、模板、规范)
└── assets/ # 其他资源(图标、示例文件等)核心文件 SKILL.md:前面是 YAML(名字、描述、允许用哪些工具),后面是详细的自然语言流程说明。
scripts/ 里的代码:由 AI 通过 Bash 或 code-execution 工具在沙箱里执行,用来做确定性的事情(解析 PDF、排序、跑测试等)。
没有任何“服务端进程”,就是纯文件结构,放在 ~/.claude/skills/、Claude Code 项目目录或通过 API 上传即可生效。
MCP 则完全是另一种设计思路,它是一个开放协议(JSON-RPC 2.0):
Host(宿主):LLM 应用,比如 Claude Code、某个 Agent 框架;Client(客户端):宿主里的 MCP 客户端;Server(服务器):对接具体系统的 MCP 服务(如 GitHub、数据库、CRM)。
在触发和调用机制上,Skills 偏向自动感知,而 MCP 则是显式调用。
Skills 靠“描述匹配”自动激活。会话一开始,AI 拿到的是所有技能的名字 + 一句话描述清单,大概只几十~几百 token,几乎不占上下文。当用户提出一个任务时,AI 会“读懂”需求,然后自己判断:“这个更像 PDF 处理技能”、“这个更像 财报撰写技能”。于是触发对应 Skill,加载它的SKILL.md,再根据里面写好的流程决定是否调用脚本、读参考文件等。
关键是,你不需要显式写“请调用 XX Skill”,它更像“智能提示模板选择器 + 工作流执行器”。
而对 MCP 来说,每个外部能力基本就是一个工具函数:像 github.listPullRequests(repo="xxx")、erp.createInvoice(...) 之类。LLM / Agent 在推理过程中,如果判断需要某个工具,就会构造一个 call_tool 请求,客户端用 JSON‑RPC 发给对应的 MCP Server,再拿回结果。
所以 MCP 侧更像传统“函数调用系统 + RPC 协议”,谁调用哪个工具,是一步一步显式决策出来的。
关于这部分,后续我会单独写一篇文章详细介绍两者的区别以及融合应用。
Skills vs 传统Agent架构
先给一个直观类比:
传统 Agent = 很多“不同员工”协作;
Skills = 一个“核心员工”,根据场景换不同身份。
|
传统多 Agent 架构 |
Skills 架构 |
|
一个总控Agent下面挂一堆子 Agent:写代码的、查资料的、出报告的、做评审的……它们之间要传消息、切上下文、协调工具使用。 |
只有一个 Agent(例如 Claude),但它可以按需加载不同的 Skill。技能本身是一组文件(说明书 + 脚本 + 参考资料),按需加载,像给这个 Agent 随时换“专业模式”。 |
LangChain 的架构文章甚至把 Skills 叫作一种“轻量级、单 Agent 版的 quasi-multi-agent 架构”:只用一个 Agent,就拿到了多 Agent 的好处(多角色、多专长、分工清晰),但没有那么多进程和消息传递负担。
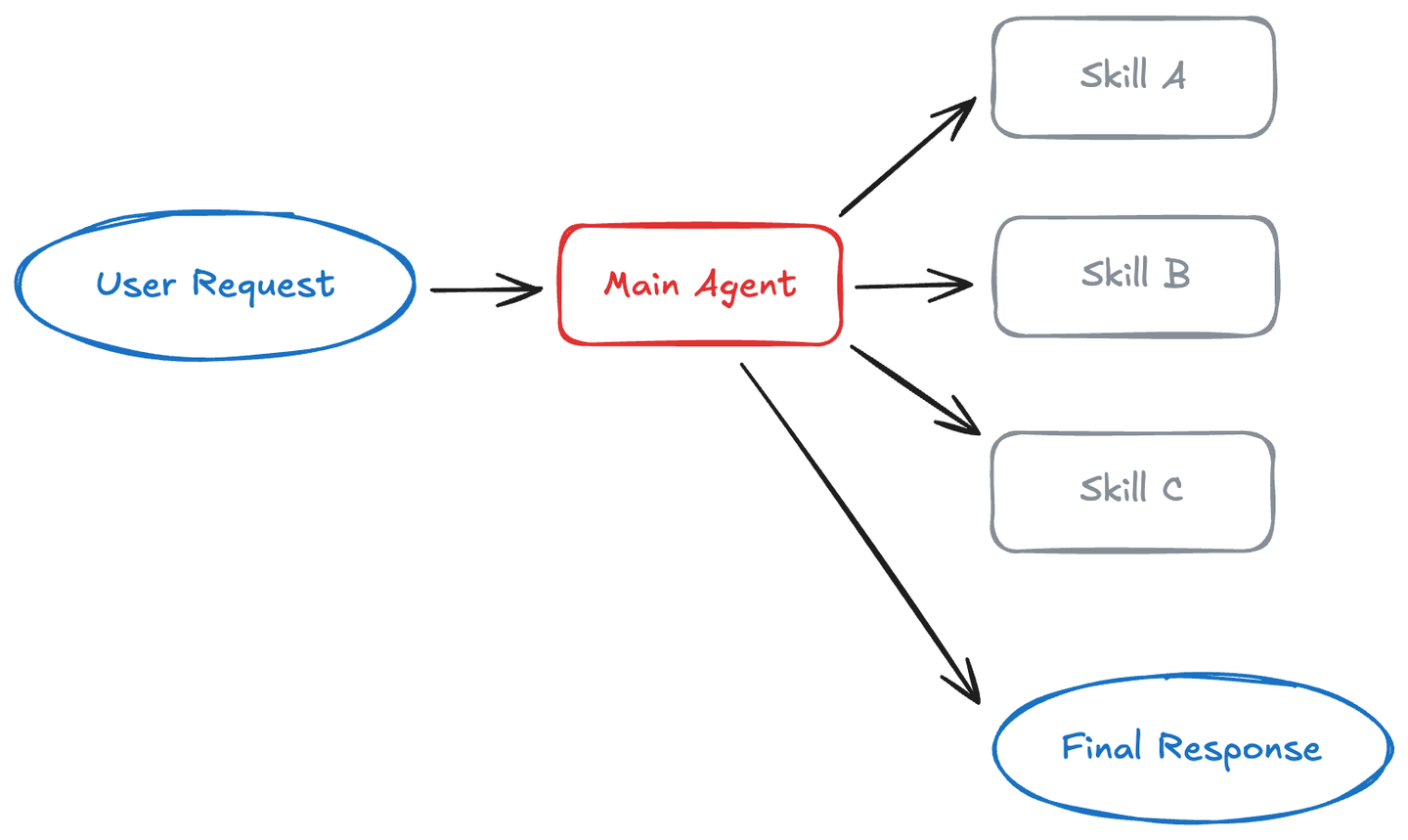
LangChain 讲解 Skills 原文插图
先回顾一下,传统 Agent 架构一般怎么做?
单体大 Agent:一个超长 system prompt+一堆工具。
最早一代的做法是一个 Agent,系统提示词里一次性写进:角色定义(你是一个资深 XXX 专家);工作流程(先问需求、再列计划、再执行);所有工具/接口怎么用;还有若干“风格要求”“公司背景”...
但问题是prompt 越写越长,一点点规范都往里塞,最终变成“提示垃圾场”(prompt sludge);维护起来也很困难,想改一个流程就要动整段大提示;同时不同项目、不同团队之间难以复用,token消耗还会因巨长的上下文而无意义增大。
后来大家开始搞 Multi-Agent 架构:一个总控 + 多个专职 Agent。
Orchestrator Agent:负责理解用户目标,决定把任务拆成哪些步骤。决定每一步交给哪个子 Agent 做。多个子 Agent:“规划 Agent”(只负责写计划),“执行 Agent”(根据计划做具体动作),“评审 Agent”(只负责检查和打分),甚至加入更多的UI 文案 Agent、法务 Agent、财务 Agent 等等。
这个架构很强,但问题也很明显:
路由与编排逻辑复杂:要写一大堆“如果是XX任务,就交给XX Agent” 的规则;要设计消息格式、上下文裁剪、错误恢复。上下文切换成本高:每个 Agent 有自己的 system prompt 和 context;信息在多个 Agent 间来回传递时,要不断摘要、压缩、转译,容易丢信息和变形。很难沉淀经验:每个 Agent 虽然能访问外部记忆(向量库、数据库),但工作方法本身往往还是写在各自 prompt 里。
结果就是新加一个 Agent 就要重新写一套怎么干活的 prompt,导致多个团队重复造轮子。Anthropic 的研究员曾经就在采访里吐槽过“今天很多 Agent 聪明但失忆,每次任务都像从头来一遍,不会真正变成越干越熟的老员工。”
而 Skills 的出现,很好地解决了传统 Agent 的问题,用户不再需要为“每个业务线”单独造一个 Agent,而是只有一个 Agent,但它可以:
需要写合同时 → 加载“合同起草 Skill”需要审代码时 → 加载“代码评审 Skill”需要写财报时 → 加载“财报生成 Skill”
每个 Skill 就是一个“小专长”,而不是一个独立 Agent 进程。
技术上,Skills 像动态 persona + 工作流的组合。
LangChain / http://Builder.io 在这一点上总结得很形象:传统多 Agent 相当于是换 Agent = 换一个完全独立的“人格 + 工具配置 + 环境”,而Skills 模式相当于不换 Agent,只给当前这个 Agent 换“角色+手册”。所以你可以把 Skill 理解成:一个可插拔的“角色配置 + 操作手册 + 工具调用套路”,在需要时临时加载进当前 Agent 的上下文,让它戴上一顶特定的专业帽子。
以下是 Agent 和 Skills 在5个关键维度的对比:
|
传统多 Agent |
Skills |
|
|
复杂度:编排流程 vs 管理技能 |
要设计:Agent 拆分:哪些职能要拆成独立 Agent?调度策略:什么条件下把任务交给谁?消息协议:Agent A 如何跟 Agent B 说话?用什么格式?很多工程工作不是在做业务逻辑,而是在“搭框架”。 |
不引入额外 Agent 实例,只是给同一个 Agent更多“专业模式”:你写的是一个个 Skill 文件夹(SKILL.md + 脚本),调度策略由模型自己通过“技能描述匹配”来决定用哪个 Skill。 |
|
上下文与 token:多 Agent 反复传话 vs Skills 渐进加载 |
每个 Agent 有自己的系统提示词和上下文,互相传消息要压缩、提取摘要、转述,整个过程容易失真、丢细节。复杂场景下,多 Agent 对话本身就消耗大量 token。 |
按“三级渐进式披露”来管理上下文:启动时只曝光所有 Skills 的名称 + 简要描述(几十 token);真需要某个 Skill 时,才加载它完整的 SKILL.md;再有更细的附加资料(forms.md、规范文档等),也是按需再读。 |
|
专业知识与可复用性:Prompt 片段 vs 可共享技能包 |
各自有独立的长 Prompt,写法、风格都不统一;复用方式往往是“复制粘贴一段提示词到另一个 Agent 的配置里”;公司内部难以形成统一的“知识资产形式”,很难管理版本和共享。 |
把“怎么做好一件事”的方法论,固化成:一个 SKILL.md(自然语言写的流程与规范),和若干脚本、参考文档、模板。这套东西可以直接放入版本库,走 Git 流程;可以在团队间共享、评审、复用;可以构成企业内部的“技能库”(Skill Library)。 |
|
团队协作与边界:Agent 团队 vs Skill 团队 |
不同团队可能“各养一个 Agent”:销售Agent、法务团队的 Agent、技术团队的 Agent。优点是隔离明确,但也容易变成一个公司一堆 Agent 应用,体验割裂。 |
整个公司可以只有少数几个核心 Agent 产品;各业务线、各团队负责“自己那摊技能”:市场部维护“品牌文案 Skill”法务部维护“合同审阅 Skill”财务部维护“报销审核 Skill”所有这些技能都装在同一个 Agent 身上,用户只跟一个界面打交道。 |
|
调试与可观测性:多 Agent 调流程 vs 单 Agent 看技能调用 |
出问题时要查:是哪个 Agent 的 prompt 有问题?是哪一次消息上下文被截断?是路由逻辑把任务发错人了吗?调试面很多,比较分散。 |
通常只需要问三个问题:Claude 有没有选对技能?选对技能后,SKILL.md 里的步骤设计是否合理?里面的脚本/参考文档是否有 bug 或过期?调优路径非常清晰,适合快速迭代。 |
但也并不是说 Skills 就会完全颠覆和替代 Agent,业界还是存在几个共识的必须多Agent的场景:
需要“物理隔离”的场景:某些任务需要严格不同的权限配置(只读 vs 可写生产环境);某个安全敏感模块必须跑在隔离环境,不能跟别的逻辑混在一起,此时用独立 Agent + 独立工具配置更安全。需要完全不同模型或推理策略:规划 Agent 用大模型、温度低、思考步长长,执行 Agent 用便宜模型、温度高,追求速度,评审 Agent 用最贵模型,只做关键环节质量把关。任务之间需要非常干净的上下文隔离:比如安全审计、红队演练、法务审查等,不希望被之前聊天内容污染,这类用独立 Agent 比在同一个 Agent 里换 Skill 更干净。
在这方面,http://Builder.io 的总结很实用:默认先用 Skills 扩展你现有的 Agent,只有当你遇到需要换模型、需要强权限隔离、上下文实在被污染等问题时,再考虑上新的Agent或子Agent。
参考资料
为什么 Claude Skills 的爆发点在 2026 年 1 月?(X)
Equipping agents for the real world with Agent Skills(Anthropic)
Claude can now create and edit files(Anthropic)
Anthropic - Skills(Github)
Claude Agent Skills: A First Principles Deep Dive(leehanchung.github)
Claude Skills vs. MCP: A Technical Comparison for AI Workflows(intuitionlabs)
Choosing the Right Multi-Agent Architecture(langchain)
Agent Skills vs. Rules vs. Commands(builder.io)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)