Elastic Attention:将 MoE 路由引入 Attention,让大模型长文本推理“该省省,该花花”
Elastic Attention 是我们在 Dynamic Sparse Attention 方向的一次尝试。通过引入 MoE 路由机制,我们打破了静态稀疏注意力的限制,证明了“动态路由”在 Attention 层同样大有可为。目前代码、模型和论文均已开源,欢迎大家 Star、引用和交流!PaperCodeModel如果你对长文本优化、MoE 架构或底层算子优化感兴趣,欢迎在评论区留言讨论!
0. 省流版(TL;DR)
- 痛点:长文本推理中,Full Attention 太慢太贵,固定比例的 Sparse Attention 又容易在困难任务上掉点。
- Method:Elastic Attention。在 Attention 层引入类似 MoE 的 Router(路由器),根据输入内容,动态决定每个 Head 是走 Full Attention(全关注)还是 Sparse Attention(稀疏关注)。
- 工程优化:手写了 Fused Kernel,在一个 Kernel 内并行处理稀疏和稠密计算,拒绝 Python 层面的串行调度延迟。
- 效果:在 LongBench 等多个榜单上超越 DuoAttention、InfLLM-v2 等基线,性能逼近(部分超越) Full Attention,但速度显著提升 。
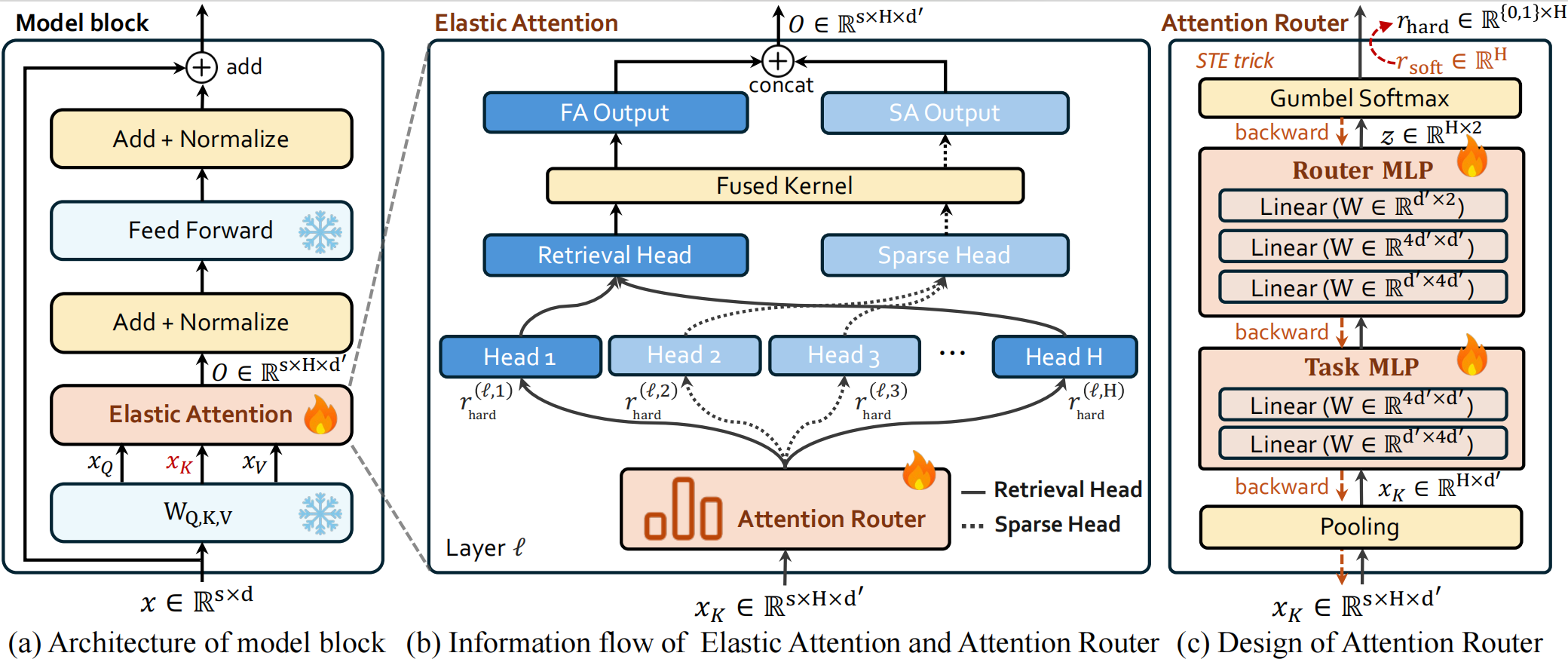
1. 为什么我们需要“弹性”的注意力?
大模型处理长文本时,Attention 的 复杂度是最大的拦路虎 。
为了解决这个问题,业界提出了很多 Hybrid Attention(混合注意力) 方案,比如 DuoAttention 或 PruLong。它们的核心思想是:一部分 Head 负责看全局(Full Attention),一部分 Head 只看局部或滑动窗口(Sparse Attention) 。
但现有的方法有一个明显的问题:
即使是 Hybrid 策略,其“稀疏 vs 稠密”的比例通常是静态的或者是预先设定好的 。
然而,我们在实验中发现,下游任务对稀疏度的敏感性截然不同 :
- Sparsity-Robust 任务(如文档摘要):只需要粗粒度信息,很高的稀疏度也能由不错的效果。
- Sparsity-Sensitive 任务(如多跳 QA):需要精准检索细节,稀疏度一高,性能立马崩盘。
如果模型不能动态调整计算策略,就必然会在“效率”和“效果”之间顾此失彼。 于是,我们想到了 MoE。
2. Elastic Attention:Attention 层面的 MoE
MoE(Mixture-of-Experts)的核心魅力在于 Dynamic Computation(动态计算)。既然 MLP 层可以路由到不同的专家,为什么 Attention 层不能路由到不同的计算模式呢?
2.1 核心架构:Attention Router
我们在预训练好的 LLM(如 Qwen3, Llama-3.1)中插入了一个轻量级的 Attention Router 。它的工作原理如下:
- 输入感知:Router 接收当前的 Key hidden states 作为输入 。
- 路由决策:通过一个简单的 MLP 网络,Router 为每一层的每一个 Head 生成一个路由信号 r r r 。
- r = 0 r = 0 r=0:该 Head 执行 Full Attention (FA),确保精准召回。
- r = 1 r = 1 r=1:该 Head 执行 Sparse Attention (SA),大幅节省计算 。
- 结果融合:最后将不同模式计算出的结果 Concat 起来 。
整个过程完全是 Instance-aware(输入感知) 的。面对简单的 Token 或任务,Router 会自动加大 SA 的比例;面对复杂的推理,它会自动切换回 FA。
训练Trick:为了让离散的路由决策(0或1)可导,我们使用了 Gumbel-Softmax 结合 Straight-Through Estimator (STE) 技术,确保在反向传播时梯度能正常流动 。
2.2 并不增加负担
大家可能会担心 Router 会不会很重?
完全不会。对于 8B 模型,Attention Router 仅增加了 每层 0.27M 参数,且不需要对 Backbone 进行重新训练,只需 12小时(8卡 A800) 的轻量级微调即可完成适配 。
3. 硬核工程优化:Fused Kernel
这是我们在工程实现上花费精力最多的地方。
在 PyTorch 层面实现这种混合注意力通常很慢,因为你需要先把 Head 分成两组(FA组和SA组),分别计算后再拼回去。这种 Serial Dispatch(串行调度) 会导致 GPU 上的 Kernel Launch 开销巨大,且破坏了流水线并行 。
为了解决这个问题,我们基于 Triton/CUDA 开发了 Fused Kernel(融合算子) 。
- 统一视角:我们将路由决策作为 Metadata 传入 Kernel 。
- 并行执行:Kernel 内部通过 Thread Block 分支逻辑,让同一个 Kernel Launch 可以同时处理执行 FA 的 Head 和执行 SA 的 Head 。
- 效果:相比 PyTorch 原生实现,Prefill 阶段获得了显著的加速,显存占用也大幅降低 。
4. 实验结果:效果与速度的双赢
我们在 Qwen3-4B/8B 和 Llama-3.1-8B 上进行了广泛验证 。
4.1 性能表现
在 LongBench-E 和 LongBench-V2 等主流榜单上,Elastic Attention 的平均性能均优于现有的 SOTA 方法(如 InfLLM-V2, DuoAttention, PruLong) 。
特别是在 RULER(长度外推测试)中,我们将上下文扩展到 256K,Elastic Attention 依然保持了极高的性能稳定性,而其他基线方法在超长文本下往往出现严重衰退 。
4.2 任务自适应性
最有意思的发现是 Router 的行为模式。如下图(论文 Figure 6)所示,对于 Code(代码) 任务,模型自动分配了约 85% 的稀疏度;而对于 QA(问答) 任务,稀疏度则降低到 68% 左右 。
这完美印证了我们的初衷:模型学会了根据任务难度“看菜下碟”。
5. 总结与展望
Elastic Attention 是我们在 Dynamic Sparse Attention 方向的一次尝试。通过引入 MoE 路由机制,我们打破了静态稀疏注意力的限制,证明了“动态路由”在 Attention 层同样大有可为。
目前代码、模型和论文均已开源,欢迎大家 Star、引用和交流!
- Paper: arXiv:2601.17367
- Code: GitHub Link
- Model: ModelScope Link
如果你对长文本优化、MoE 架构或底层算子优化感兴趣,欢迎在评论区留言讨论!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)