企业专属AI从0到1:避开隐私雷区,用你的数据安全微调大模型
传统微调方法,数据必须“接触”模型,风险不可控。对于企业和业务人员,理解其原理和流程,有助于你更好地与技术团队沟通需求,评估外部方案,甚至利用现有的低代码平台快速开启试点项目。它旨在让你能无代码或低代码地把自己的数据安全地“喂”进模型,直观地看到模型如何变得更“懂你”,是入门和实践的绝佳工具。本文将为你拆解其中的核心原理,并提供一个清晰的实践路径,让你即使没有深厚的代码基础,也能理解并启动安全可控
引言:为什么企业微调大模型,隐私是头等大事?
想象一下,你是一家律所的合伙人,想用一个AI助手来快速整理案件卷宗。你手里有成千上万份包含客户敏感信息的文档。直接把这些“机密”丢给一个公开的AI模型去学习,无异于把客户档案摊开在公共广场上——数据泄露、隐私违规、商业机密外泄的风险极高。
这就是当前企业想用大模型(如GPT、LLaMA等)面临的核心矛盾:一方面,用自己的数据微调模型,能让AI更懂业务,产出价值巨大;另一方面,数据安全法和行业法规(如GDPR、HIPAA)严令禁止敏感数据出域。传统微调方法,数据必须“接触”模型,风险不可控。
因此,隐私保护下的微调,不是可选项,而是企业AI落地的生死线。本文将为你拆解其中的核心原理,并提供一个清晰的实践路径,让你即使没有深厚的代码基础,也能理解并启动安全可控的模型定制。
如果你觉得从头搭建技术栈太复杂,想快速验证业务效果,可以关注像 LLaMA-Factory Online 这样的低门槛微调平台。它旨在让你能无代码或低代码地把自己的数据安全地“喂”进模型,直观地看到模型如何变得更“懂你”,是入门和实践的绝佳工具。
技术原理深入浅出:给AI训练加上“隐形护盾”
怎么做到既让模型从数据中学到东西,又不让它“记住”具体的数据细节呢?核心思想是给学习过程添加可控的“噪音”和设置严格的“纪律” 。主要有两大法宝:
1. 差分隐私:给数据戴上“模糊面具”
这是隐私保护的黄金标准。你可以把它理解为一个严格的数学承诺:
“对于模型来说,单个个体的数据是否存在,不应该显著影响其最终输出。”
通俗比喻:就像一个严格的匿名调研。如果公司里多一个人或少一个人参加调研,最终的统计报告(比如“80%员工满意食堂”)不应该发生可察觉的变化。这样,从报告中就无法推断出任何特定个体的回答。
在微调中如何实现?
- 梯度裁剪:在反向传播计算参数更新(梯度)时,给每个数据的更新幅度设置一个上限(比如不允许任何单个数据对模型的改变超过“1”)。这就像规定每个学生给老师提意见时,音量不能超过某个分贝,防止个别声音过大。
- 噪声注入:在汇总了所有数据的更新方向后,加入一点精心计算的随机噪声(通常是高斯噪声)。这就像在最终的调研报告数字上,随机加/减一点点,让报告无法精确还原任何一个人的原始答案。噪声大小由一个叫 ε(epsilon) 的参数控制,ε越小,噪声越大,隐私保护越强,但模型精度可能下降。
2. 参数高效微调:只动“冰山一角”,风险自然小
全量微调动辄调整数百亿参数,就像为了学做一道菜重写整本食谱,计算量大且容易“记住”过多细节。现在主流方法是 LoRA(低秩适配) 。
- 核心思想:不直接改动大模型原有的海量参数(冻结的“基础食谱”),而是在旁边附加一些小小的、专门针对新任务的“补充便签”(适配器)。训练时只更新这些“便签”。
- 隐私优势:因为“基础食谱”不动,模型从你的数据中学到的“新知识”被限制在很小的“便签”参数里,这本身就降低了原始数据被编码到模型深层的风险,泄露面大大缩小。
把两者结合:用LoRA进行参数高效微调,同时在LoRA参数的更新过程中应用差分隐私(梯度裁剪+噪声注入)。这就构成了一个强大且高效的隐私保护微调方案。
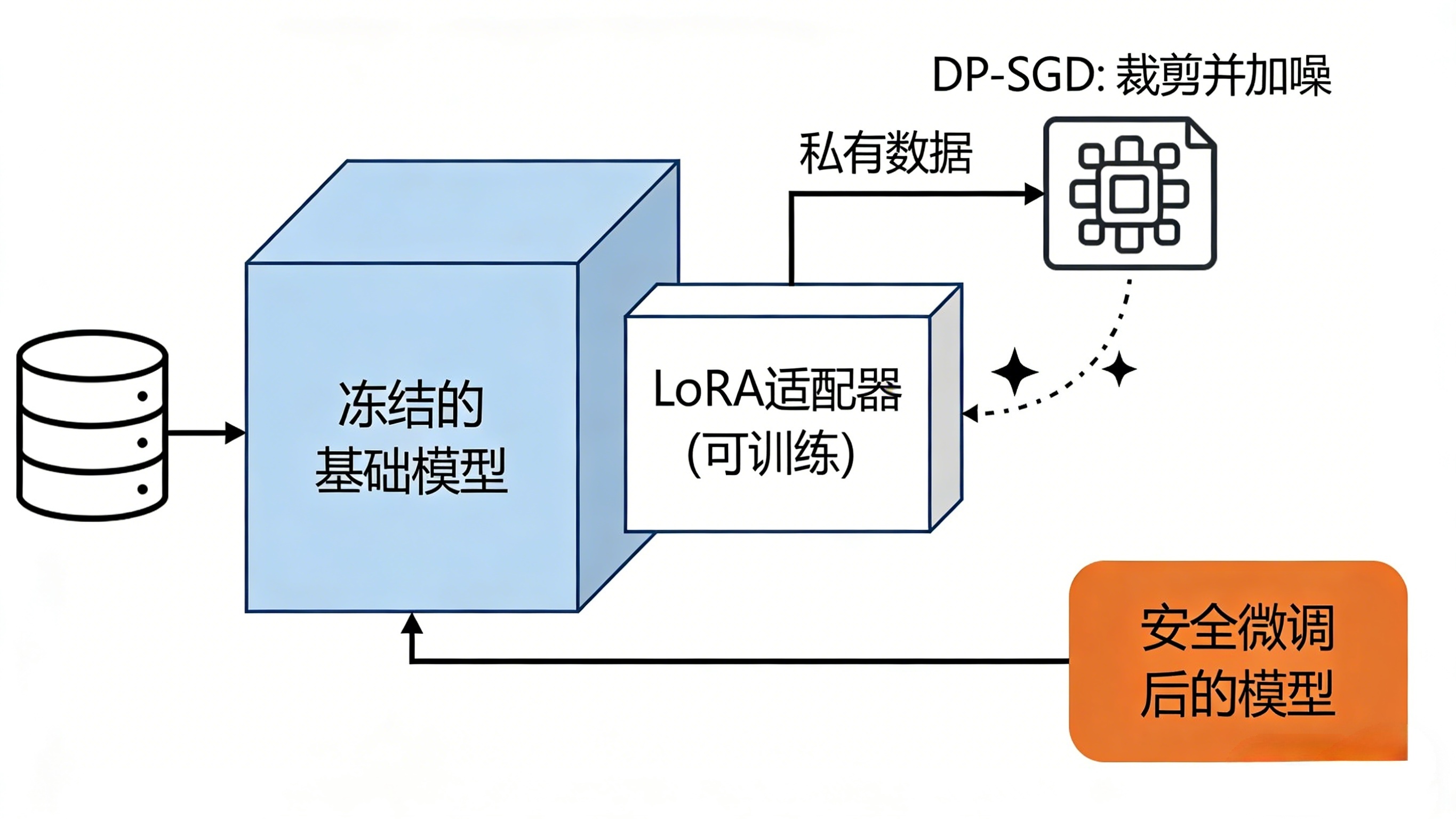
实践步骤:从零开始的隐私安全微调之旅
理解了原理,我们来看如何动手。这里提供一个清晰的步骤框架:
第一步:环境与数据准备
-
环境搭建:建议使用Python虚拟环境。安装核心库:
PyTorch,Transformers(Hugging Face模型库),PEFT(用于LoRA),Opacus或Privacy-Evaluator(用于差分隐私)。 -
数据预处理:这是安全的第一道关卡。
- 脱敏:使用工具自动识别并掩蔽人名、身份证号、电话、地址等个人身份信息。
- 格式化:将数据整理成模型接受的对话(Instruction-Output)或文本补全格式。
- 划分:按比例(如8:1:1)分为训练集、验证集和测试集。
第二步:配置隐私保护训练
这里以使用 PEFT + Opacus 为例,给出概念性代码框架:
python
# 1. 加载基础模型和分词器
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "meta-llama/Llama-2-7b-chat-hf" # 例如LLaMA-2
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# 2. 配置LoRA,只微调注意力相关的一小部分参数
from peft import get_peft_model, LoraConfig
lora_config = LoraConfig(
r=8, # 低秩矩阵的维度,越小参数量越少
lora_alpha=32,
target_modules=["q_proj", "v_proj"], # 指定在哪些模块上加“便签”
lora_dropout=0.1,
)
model = get_peft_model(model, lora_config) # 现在模型绝大部分参数被冻结了
# 3. 包装数据加载器
from torch.utils.data import DataLoader
train_dataloader = DataLoader(your_train_dataset, batch_size=4, shuffle=True)
# 4. 注入差分隐私引擎(核心!)
from opacus import PrivacyEngine
privacy_engine = PrivacyEngine()
model, optimizer, privacy_loader = privacy_engine.make_private(
module=model,
optimizer=torch.optim.AdamW(model.parameters(), lr=2e-4),
data_loader=train_dataloader,
noise_multiplier=1.1, # 控制噪声大小,与ε相关
max_grad_norm=1.0, # 梯度裁剪的阈值
)
# 5. 训练循环
for epoch in range(5):
for batch in privacy_loader:
# ... 前向传播,计算损失
loss.backward()
optimizer.step()
optimizer.zero_grad()
# 查询当前隐私消耗
epsilon, best_alpha = privacy_engine.accountant.get_privacy_spent(delta=1e-5)
print(f"Epoch {epoch}: 隐私预算消耗 ε = {epsilon:.2f}")
关键参数解读:
noise_multiplier和max_grad_norm:共同决定了隐私保护强度(ε)。epsilon (ε):隐私预算。你可以把它想象成“隐私货币”。ε越小,保护越强(通常ε在1-10之间是常见的企业级选择)。训练过程会不断“花费”这个预算,花完(达到设定值)就必须停止。
第三步:模型评估与部署
- 效果评估:在预留的测试集上评估微调后模型的任务准确率,与未加隐私保护的标准微调对比,了解隐私带来的性能折损。
- 隐私审计:进行简单的成员推断攻击测试——尝试用一些训练数据和非训练数据去“问”模型,观察模型对训练数据是否表现出异常的“熟悉度”(如更低的困惑度)。一个好的隐私保护模型应该让攻击者难以区分。
- 安全部署:将训练好的LoRA适配器(一小部分文件)与基础模型结合,部署在内网安全的API服务器后。部署时同样要加上访问控制、请求审计和输出过滤,防止模型被恶意滥用或通过反复查询泄露信息。
效果评估:如何判断微调是否成功且安全?
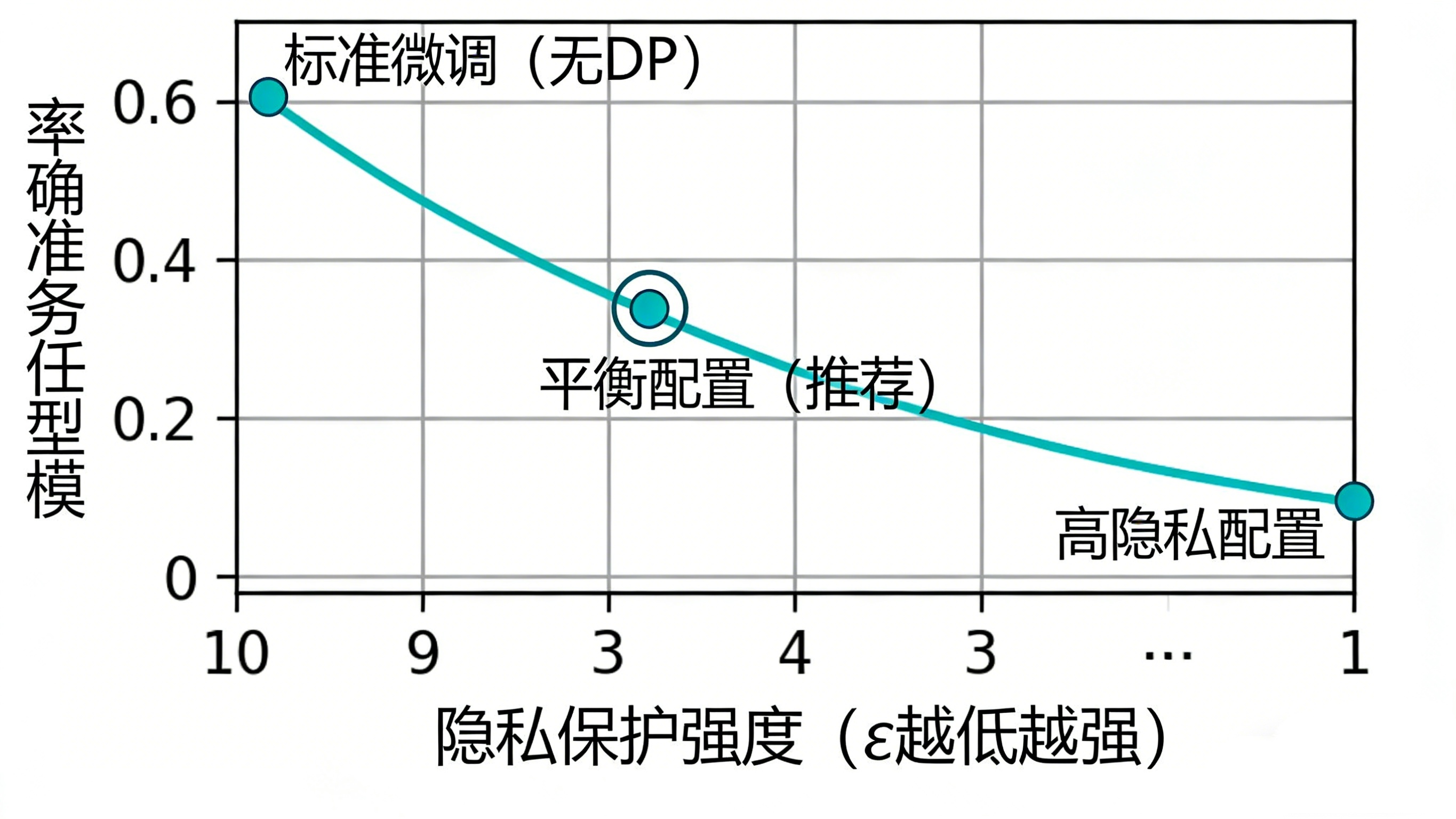
成功的隐私保护微调需要平衡两个维度:
-
效用性:模型在指定任务上表现好。
- 指标:任务相关的准确率、F1分数、BLEU分数等。
- 方法:在干净的测试集上评估。
-
隐私性:模型没有记忆或泄露具体训练数据。
- 指标:最终消耗的隐私预算 ε。这是你的核心保障。同时可以辅以:
- 成员推断攻击成功率:攻击者正确猜测一条数据是否在训练集中的概率,越接近50%(随机猜)越好。
- 敏感数据重构难度:尝试从模型参数或输出中反推原始数据,理论上应极其困难。
一个典型的权衡曲线是:随着你要求更低的ε(更强的隐私保护),模型的最终任务精度往往会有所下降。你的目标就是为你的业务场景找到一个 “可接受的精度损失” 与 “足够强的隐私保障” 之间的甜蜜点。
总结与展望
为企业数据安全地微调大模型,已从理论研究走向工程实践。通过 差分隐私(DP) 和 参数高效微调(如LoRA) 的组合拳,我们可以在数据不出域的前提下,有效地将领域知识注入模型,打造安全、合规、专属的AI助手。
对于开发者而言,掌握这套技术栈是未来的重要竞争力。对于企业和业务人员,理解其原理和流程,有助于你更好地与技术团队沟通需求,评估外部方案,甚至利用现有的低代码平台快速开启试点项目。
未来展望:技术仍在快速发展,如联邦学习(让数据完全留在本地,只交换模型更新)、完全同态加密(在加密数据上直接计算)等更强大的技术正逐步从实验室走向应用。但当下,DP+LoRA已是经过验证、相对成熟且高效的最佳实践起点。
希望这篇指南能为你拨开迷雾。如果你对某个细节感兴趣,欢迎留言深入探讨。记住,在AI时代,让数据安全地创造价值,是我们共同的责任与机遇。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)