传音今年的薪资还不错,冲了!
不管是否做 AI 相关的工作,建议都要学习了解下面这些核心概念:什么是大语言模型 (LLM) :了解其基本工作方式(输入 Prompt -> 输出 Completion)、主要能力(文本生成、理解、摘要、翻译、问答等)以及局限性(知识截止、幻觉等)。提示工程 (Prompt Engineering) 基础 : 学习如何设计有效的 Prompt 来引导模型产生期望的输出。掌握基本技巧,如提供清晰指令
传音也开奖了!上海和深圳这边的 Java 开发能开到 30w~40w,重庆这边稍微低一些,Java 开发能开到 17w~25w。
具体开的薪资通常会和学历挂钩,双非是最低档,92 会高不少,是否是硕士也有影响。
可能很多朋友都不知道传音这家公司,在国内的存在感也确实低。不过,它被称为非洲手机之王,非洲市占率第一,且全球目前都在发力,已经是全球第四大智能手机销售商。
这家公司的手机主打一个便宜,所以在收入低的地区比较受欢迎。

我看了影视飓风洋人电子垃圾那期,视频里的非洲老哥表示当地人还是更喜欢 iPhone,但这玩意比较稀缺,二手的价格也比较贵。
和国内的其他手机厂商(如 OPPO、Vivo)一样,传音每年校招都会招聘不少 Java 开发,社招也会经常放出 Java 岗位。并且,传音对学历很包容,就算你是双非,也没关系,放心冲,很多拿到 offer 的都是双非。
那传音的面试难度怎么样呢?根据我看过的面经分享来看,还是非常简单的,技术一般的同学可以捡漏一波。
下面给大家分享一位读者的传音研发岗校招面经,大家感受一下,难度真的很低(很多非技术问题这里就直省略了)。
概览:

一个程序从编译到运行的全流程
Java 程序从源代码到运行的过程如下图所示:
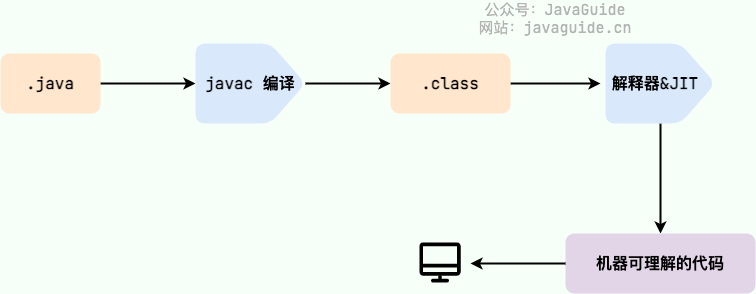
Java程序转变为机器代码的过程
需要格外注意的是 .class->机器码 这一步。在这一步 JVM 类加载器首先加载字节码文件,然后通过解释器逐行解释执行,这种方式的执行速度会相对比较慢。而且,有些方法和代码块是经常需要被调用的(也就是所谓的热点代码),所以后面引进了 JIT(Just in Time Compilation) 编译器,而 JIT 属于运行时编译。当 JIT 编译器完成第一次编译后,其会将字节码对应的机器码保存下来,下次可以直接使用。而我们知道,机器码的运行效率肯定是高于 Java 解释器的。这也解释了我们为什么经常会说 Java 是编译与解释共存的语言 。
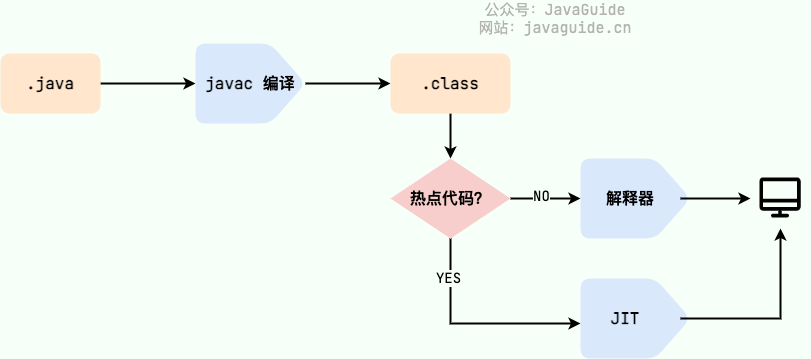
Java程序转变为机器代码的过程
HotSpot 采用了惰性评估(Lazy Evaluation)的做法,根据二八定律,消耗大部分系统资源的只有那一小部分的代码(热点代码),而这也就是 JIT 所需要编译的部分。JVM 会根据代码每次被执行的情况收集信息并相应地做出一些优化,因此执行的次数越多,它的速度就越快。
篇幅限制下面就只能给大家展示小册部分内容了。整理了一份核心面试笔记包括了:Java面试、Spring、JVM、MyBatis、Redis、MySQL、并发编程、微服务、Linux、Springboot、SpringCloud、MQ、Kafc
需要全套面试笔记及答案
【点击此处即可/免费获取】
为什么要有虚拟机
虚拟机(JVM)的存在主要是为了三大好处:
-
跨平台:它是实现一次编译,到处运行的关键。我们的 Java 代码被编译成通用的字节码,然后由各个平台专属的 JVM 来翻译成当地的机器码执行。
-
自动内存管理:JVM 自带垃圾回收(GC),帮我们自动管理内存。开发者不用像写 C++那样手动释放内存,极大地减少了内存泄漏和程序崩溃的风险,让我们更专注于业务。
-
性能优化:JVM 里的 JIT(即时编译器)会在程序运行时,把频繁执行的热点代码动态编译成高效的本地机器码,让 Java 在很多场景下也能拥有接近原生语言的性能。
所以,JVM 不仅是为了跨平台,更是 Java 强大、稳定、高效的基石。
Java 和 C++ 的区别?
我知道很多人没学过 C++,但是面试官就是没事喜欢拿咱们 Java 和 C++ 比呀!没办法!!!就算没学过 C++,也要记下来。
虽然,Java 和 C++ 都是面向对象的语言,都支持封装、继承和多态,但是,它们还是有挺多不相同的地方:
-
Java 不提供指针来直接访问内存,程序内存更加安全
-
Java 的类是单继承的,C++ 支持多重继承;虽然 Java 的类不可以多继承,但是接口可以多继承。
-
Java 有自动内存管理垃圾回收机制(GC),不需要程序员手动释放无用内存。
-
C ++同时支持方法重载和操作符重载,但是 Java 只支持方法重载(操作符重载增加了复杂性,这与 Java 最初的设计思想不符)。
-
……
Exception 和 Error 有什么区别?
在 Java 中,所有的异常都有一个共同的祖先 java.lang 包中的 Throwable 类。Throwable 类有两个重要的子类:
-
Exception:程序本身可以处理的异常,可以通过catch来进行捕获。Exception又可以分为 Checked Exception (受检查异常,必须处理) 和 Unchecked Exception (不受检查异常,可以不处理)。 -
Error:Error属于程序无法处理的错误 ,我们没办法通过不建议通过catch来进行捕获catch捕获 。例如 Java 虚拟机运行错误(Virtual MachineError)、虚拟机内存不够错误(OutOfMemoryError)、类定义错误(NoClassDefFoundError)等 。这些异常发生时,Java 虚拟机(JVM)一般会选择线程终止。
异常可以被定义为静态变量吗?
绝对不能。因为异常的堆栈信息是在它被 new 出来的那一刻被捕获和固定的。
如果你把异常定义成一个 static 变量,那么它的堆栈信息就永远是类加载时那个点的堆栈,而不是真正抛出异常时的业务代码位置。
这会导致你看日志的时候,看到的堆栈信息是完全错误的,会严重误导问题排查。比如,异常明明发生在 methodA() 里,但日志却显示它发生在静态代码块里。
所以,正确的做法永远是在需要的地方 throw new Exception(),来保证捕获到最准确的异常现场。
介绍一下 Java 集合
Java 集合,也叫作容器,主要是由两大接口派生而来:一个是 Collection接口,主要用于存放单一元素;另一个是 Map 接口,主要用于存放键值对。对于Collection 接口,下面又有三个主要的子接口:List、Set 、 Queue。
Java 集合框架如下图所示:
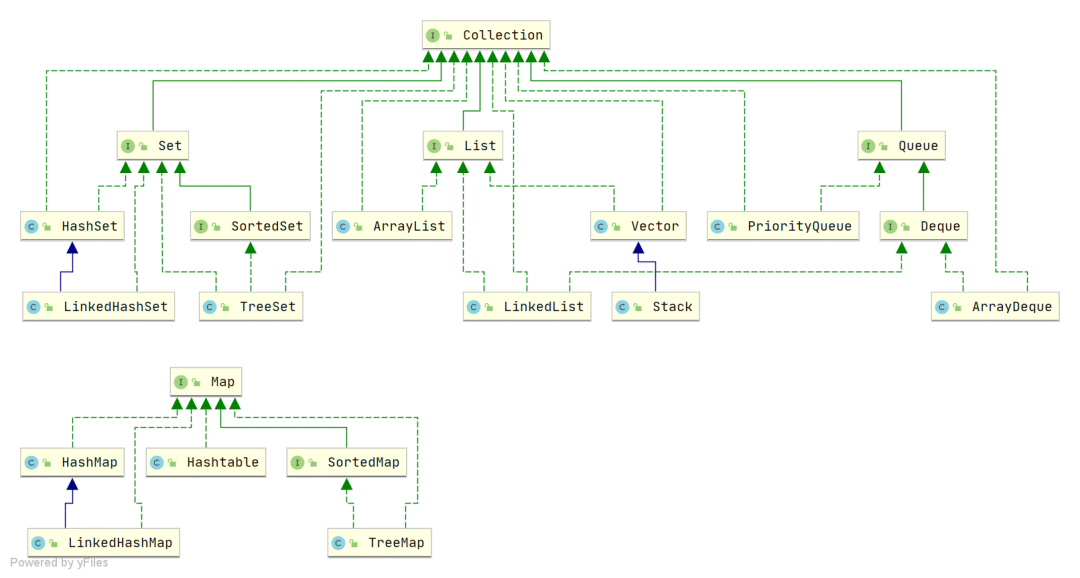
Java 集合框架概览
注:图中只列举了主要的继承派生关系,并没有列举所有关系。比方省略了AbstractList, NavigableSet等抽象类以及其他的一些辅助类,如想深入了解,可自行查看源码。
LinkedList 插入和删除元素的时间复杂度
-
头部插入/删除:只需要修改头结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
-
尾部插入/删除:只需要修改尾结点的指针即可完成插入/删除操作,因此时间复杂度为 O(1)。
-
指定位置插入/删除:需要先移动到指定位置,再修改指定节点的指针完成插入/删除,不过由于有头尾指针,可以从较近的指针出发,因此需要遍历平均 n/4 个元素,时间复杂度为 O(n)。
这里简单列举一个例子:假如我们要删除节点 9 的话,需要先遍历链表找到该节点。然后,再执行相应节点指针指向的更改,具体的源码可以参考:LinkedList 源码分析[1] 。
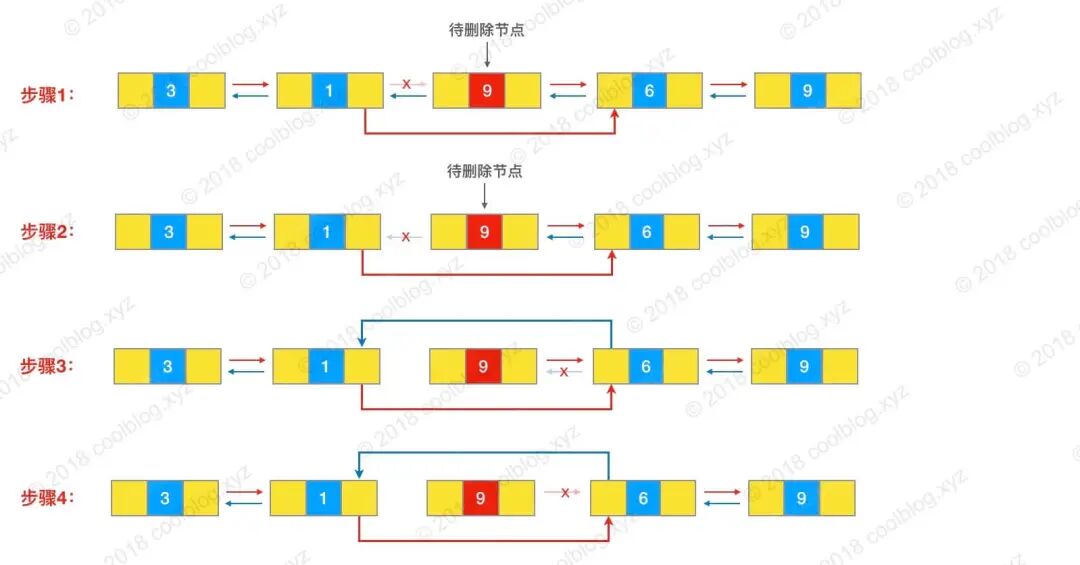
unlink 方法逻辑
为什么 HashMap 后期链表会变为红黑树
这样做的目的是减少搜索时间:链表的查询效率为 O(n)(n 是链表的长度),红黑树是一种自平衡二叉搜索树,其查询效率为 O(log n)。当链表较短时,O(n) 和 O(log n) 的性能差异不明显。但当链表变长时,查询性能会显著下降。
并发与并行的区别
-
并发:两个及两个以上的作业在同一 时间段 内执行。
-
并行:两个及两个以上的作业在同一 时刻 执行。
最关键的点是:是否是 同时 执行。
为什么要使用多线程?
先从总体上来说:
-
从计算机底层来说: 线程可以比作是轻量级的进程,是程序执行的最小单位,线程间的切换和调度的成本远远小于进程。另外,多核 CPU 时代意味着多个线程可以同时运行,这减少了线程上下文切换的开销。
-
从当代互联网发展趋势来说: 现在的系统动不动就要求百万级甚至千万级的并发量,而多线程并发编程正是开发高并发系统的基础,利用好多线程机制可以大大提高系统整体的并发能力以及性能。
再深入到计算机底层来探讨:
-
单核时代:在单核时代多线程主要是为了提高单进程利用 CPU 和 IO 系统的效率。 假设只运行了一个 Java 进程的情况,当我们请求 IO 的时候,如果 Java 进程中只有一个线程,此线程被 IO 阻塞则整个进程被阻塞。CPU 和 IO 设备只有一个在运行,那么可以简单地说系统整体效率只有 50%。当使用多线程的时候,一个线程被 IO 阻塞,其他线程还可以继续使用 CPU。从而提高了 Java 进程利用系统资源的整体效率。
-
多核时代: 多核时代多线程主要是为了提高进程利用多核 CPU 的能力。举个例子:假如我们要计算一个复杂的任务,我们只用一个线程的话,不论系统有几个 CPU 核心,都只会有一个 CPU 核心被利用到。而创建多个线程,这些线程可以被映射到底层多个 CPU 核心上执行,在任务中的多个线程没有资源竞争的情况下,任务执行的效率会有显著性的提高,约等于(单核时执行时间/CPU 核心数)。
介绍一下自己的项目
作为求职者,我们可以从哪些方案去准备项目经历的回答:
-
梳理项目全貌:
-
一句话概括项目:用简洁的语言说清楚这个项目是做什么的(核心业务/目标)以及为什么要做(项目背景、要解决什么痛点)。
-
核心功能与亮点:介绍项目的主要功能模块,特别是那些技术含量高或业务价值大的部分。
-
技术架构与选型:能清晰地说明项目的整体技术架构(比如是微服务、单体?用了哪些中间件?),并解释为什么选择这些技术(技术选型的考量)。准备好可能被要求画简要架构图或解释关键模块设计。
-
-
明确你的角色与贡献:
-
你的角色:清楚说明你在项目中担任的角色(比如核心开发者、模块负责人、项目经理等)。
-
具体职责:你具体负责了哪些模块或任务?
-
关键贡献(重中之重!):用 STAR 法则 (Situation, Task, Action, Result) 来准备几个实际案例。重点突出你通过具体行动取得了可量化的成果或解决了关键问题,一定要具体场景,而非罗列技术。例如,“负责优化 XX 接口,通过 A、B、C 措施,将响应时间从 X 降低到 Y,提升了 Z% 的用户体验”。
-
-
准备解决问题的亮点案例:
-
挖掘挑战:回忆项目中遇到的最棘手的技术难题、性能瓶颈、或者复杂的业务逻辑实现。这个在面试中很可能会问到,例如面试官会问你:“面试中遇到了什么困难?如何解决的?”。
-
展现思路:详细说明你是如何分析问题(用了什么工具?怎么定位的?)、思考解决方案(考虑了哪些方案?为什么选择最终方案?)、最终如何解决的,以及结果如何。
-
提炼收获:从解决这个问题的过程中,你学到了什么?技术上有什么成长?或者对业务有了更深的理解?
-
-
深入理解关键技术:吃透你在这个项目中用到的技术(举个例子,你的项目经历使用了 Seata 来做分布式事务,那 Seata 相关的问题你要提前准备一下吧,比如说 Seata 支持哪些配置中心、Seata 的事务分组是怎么做的、Seata 支持哪些事务模式,怎么选择?)。
对 AI 相关的知识有学习了解吗?
不管是否做 AI 相关的工作,建议都要学习了解下面这些核心概念:
-
什么是大语言模型 (LLM) :了解其基本工作方式(输入 Prompt -> 输出 Completion)、主要能力(文本生成、理解、摘要、翻译、问答等)以及局限性(知识截止、幻觉等)。
-
提示工程 (Prompt Engineering) 基础 : 学习如何设计有效的 Prompt 来引导模型产生期望的输出。掌握基本技巧,如提供清晰指令、上下文、示例(Few-shot Learning)。这是应用开发中最直接、最高频的交互方式。
-
嵌入 (Embeddings) 与向量数据库 (Vector Databases) : 理解文本如何被转换为向量(Embeddings),以及向量数据库(如 Milvus, Chroma, Weaviate, Pinecone, ES 向量搜索)在相似性搜索中的作用。这是实现 RAG 的关键技术。
-
检索增强生成 (RAG - Retrieval-Augmented Generation) : 掌握 RAG 的核心思想——结合外部知识库(通过向量检索)来弥补 LLM 自身知识的不足或实现基于私有数据的问答。这是目前最主流的大模型应用模式之一。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)