云原生可观测性:日志、指标、追踪三位一体
本文探讨云原生环境下的可观测性体系建设,提出将日志(Loki)、指标(Prometheus)和追踪(Jaeger)有机融合的解决方案。通过轻量级日志方案Loki+Promtail、Prometheus指标监控、OpenTelemetry分布式追踪等技术,构建可关联分析的统一视图。重点介绍了各组件部署配置方法、数据采集原理及Grafana整合方案,并基于RED方法设计告警规则。最终实现日志可查、指标
“服务又慢了,但不知道是哪个环节出问题。”
“日志分散在几十个 Pod 里,查个错误要翻半天。”
“Prometheus 有指标,Jaeger 有链路,Loki 有日志,但它们彼此割裂,没法联动分析。”
如果你在生产环境中遇到过这些困境,说明你的可观测体系尚未形成闭环。
真正的云原生可观测性,不是堆砌三个工具,而是将 Logging(日志)、Metrics(指标)、Tracing(追踪) 有机融合,构建一个可关联、可下钻、可告警的统一视图。本文将带你从原理到实践,搭建一套轻量、高效、生产就绪的可观测系统。
一、Logging:Loki + Promtail,轻量高效的日志方案
传统 ELK(Elasticsearch + Logstash + Kibana)资源消耗大、运维复杂。而 Loki 采用“只索引元数据,不索引日志内容”的设计,大幅降低存储与计算开销。
架构组成:
- Loki:日志存储与查询引擎;
- Promtail:日志采集代理,运行在每个节点,将容器日志发送给 Loki;
- Grafana:统一查询与展示界面。
部署方式(Helm):
helm repo add grafana https://grafana.github.io/helm-charts
helm install loki grafana/loki-stack --set promtail.enabled=true查询示例(LogQL):
{namespace="staging", app="user-service"} |= "error"优势:
- 与 Prometheus 标签体系一致,天然支持多维筛选;
- 存储成本仅为 ELK 的 1/5~1/10;
- 通过
job,pod,namespace等标签快速定位日志。
二、Metrics:Prometheus 抓取原理 + Go Exporter 编写
Prometheus 是云原生指标监控的事实标准,其核心是 Pull 模型:定期从目标服务的 /metrics 端点拉取数据。
抓取流程:
- 应用暴露
/metrics(文本格式); - Prometheus Server 根据
scrape_configs定期抓取; - 数据存储在本地 TSDB,支持 PromQL 查询。
在 Go 服务中集成 Exporter:
import (
"net/http"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
var (
httpRequestCount = prometheus.NewCounterVec(
prometheus.CounterOpts{
Name: "http_requests_total",
Help: "Total HTTP requests",
},
[]string{"method", "path", "status"},
)
)
func init() {
prometheus.MustRegister(httpRequestCount)
}
func handler(w http.ResponseWriter, r *http.Request) {
// 业务逻辑
status := "200"
httpRequestCount.WithLabelValues(r.Method, r.URL.Path, status).Inc()
}
func main() {
http.Handle("/metrics", promhttp.Handler())
http.HandleFunc("/api/user", handler)
http.ListenAndServe(":8080", nil)
}关键点:
- 使用
CounterVec、Histogram等类型建模业务指标; - 指标命名遵循
<namespace>_<subsystem>_<name>规范; - 避免高基数标签(如用户 ID),防止 TSDB 膨胀。
三、Tracing:OpenTelemetry Collector + Jaeger
分布式追踪用于还原跨服务的完整调用链。当前主流方案是 OpenTelemetry(OTel):
- OTel SDK:集成到应用中,生成 Span;
- OTel Collector:接收、处理、转发 Trace 数据;
- Jaeger / Tempo:存储与可视化后端。
在 Go 服务中启用 OTel:
import (
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/jaeger"
"go.opentelemetry.io/otel/sdk/trace"
)
func initTracer() {
exp, _ := jaeger.New(jaeger.WithCollectorEndpoint())
tp := trace.NewTracerProvider(trace.WithBatcher(exp))
otel.SetTracerProvider(tp)
}每个 HTTP 请求会自动创建 Root Span,gRPC 或 HTTP 调用会传播 Trace Context(通过 traceparent Header)。
🔗 OTel 追踪需在《微服务》【追踪篇】的 Go 服务中集成 SDK,才能实现跨服务链路串联。 若未集成,Jaeger 中将只看到孤立片段,无法形成完整链路。
四、统一视图:Grafana 三位一体整合
Grafana 不仅是图表工具,更是可观测数据的统一入口。
三大数据源配置:
- Prometheus:添加为
Metrics数据源; - Loki:添加为
Logs数据源; - Jaeger / Tempo:添加为
Traces数据源。
关键能力:跨数据源关联
- 在 Metrics 图表中点击异常时间点 → 自动跳转到对应日志;
- 在 Trace 详情页中查看某 Span 的日志(需应用将
trace_id写入日志); - 使用
${__traceId}变量在 Loki 中查询关联日志。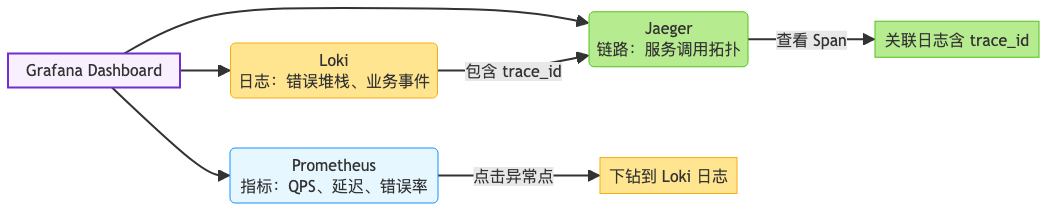
五、告警:基于 RED 方法设置阈值
RED 方法(Rate, Errors, Duration)是微服务监控的黄金标准:
- Rate:每秒请求数(QPS);
- Errors:错误率(HTTP 5xx / gRPC error);
- Duration:请求延迟(P95/P99)。
Prometheus 告警示例:
groups:
- name: user-service
rules:
- alert: HighErrorRate
expr: rate(http_requests_total{status=~"5.."}[5m]) / rate(http_requests_total[5m]) > 0.05
for: 2m
labels:
severity: warning
annotations:
summary: "User service error rate > 5%"
- alert: HighLatency
expr: histogram_quantile(0.95, rate(http_request_duration_seconds_bucket[5m])) > 1.0
for: 5m
labels:
severity: critical告警原则:
- 基于业务影响,而非技术指标(如 CPU 使用率);
- 设置合理
for时间,避免抖动误报; - 与 PagerDuty、企业微信等打通,确保及时响应。
结语:可观测性是稳定性的基石
一个成熟的云原生团队,必须具备:
- 日志可查:快速定位错误上下文;
- 指标可度量:量化系统健康状态;
- 链路可追踪:还原跨服务调用路径;
- 告警可行动:提前发现并响应异常。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 50
50 0
0- 0



 已为社区贡献57条内容
已为社区贡献57条内容

所有评论(0)