基于书生大模型的AI搜索引擎FreeKnowledge AI | 与书生共创
随着书生大模型开源生态的不断壮大,越来越多的产品和平台纷纷接入书生大模型。科研人员依托书生大模型持续探索创新,取得了丰富的研究成果;社区用户也不断创造出令人耳目一新的项目。“与书生共创”将推出一系列文章,聚焦这些合作与创新案例。欢迎订阅并踊跃投稿,一起分享经验与成果,共同推动大模型技术的应用与发展。本文来自社区投稿,作者邬雨航,书生大模型实战营学员,将向大家介绍孵化于书生大模型实战营的项目 Fre
随着书生大模型开源生态的不断壮大,越来越多的产品和平台纷纷接入书生大模型。科研人员依托书生大模型持续探索创新,取得了丰富的研究成果;社区用户也不断创造出令人耳目一新的项目。“与书生共创”将推出一系列文章,聚焦这些合作与创新案例。欢迎订阅并踊跃投稿,一起分享经验与成果,共同推动大模型技术的应用与发展。
本文来自社区投稿,作者邬雨航,书生大模型实战营学员,将向大家介绍孵化于书生大模型实战营的项目 FreeKnowledge AI,一款完全免费的 AI 知识搜索引擎。
鸣谢
大家好,我是上海工程技术大学的研一学生邬雨航,特别感谢书生大模型对本项目的 API 支持以及宣传。同时感谢以下同学的参与:烟台大学王文政同学(特别感谢)、上海工程技术大学张恒华同学。
特别要提的是,实战营提供的免费课程、模型和算力的支持,极大地帮助了像我这样的普通学生。在此,我表示衷心的感谢!
动机
目前,像 DuckDuckGo 这类免费搜索接口获取外部知识时常出现内容残缺、结果不稳定,尤其是小众问题更难拿到高质量原文;而 Bocha、Exa 等效果好的 API 又价格不菲。为此,我们开源了完全免费的 FreeKnowledge AI,在高灵活度爬取网页内容的同时,通过 InternLM2.5-7B 大模型对网页进行清洗,自动抽取出逻辑通顺、信息密度高的核心内容,既保证了知识质量,也实现了零成本调用。
相关链接:
- https://github.com/InternLM/InternLM
- https://internlm.intern-ai.org.cn/api/document?lang=zh
- https://openxlab.org.cn/
- https://github.com/VovyH/FreeKnowledge_AI
- https://pypi.org/project/FreeKnowledge-AI/
简单的使用方式
本地部署:
- 首先安装依赖(目前版本 0.3.1):
pip install FreeKnowledge-AI
- 初始化一系列参数,并编写一个简单的示例:
from FreeKnowledge_AI import knowledge_center
# 1.Initialize the knowledge agent
center = knowledge_center.Center()
question = "2024年上海工程技术大学研究生复试分数线"
flag = True # Flag indicates whether a large model is needed, and the output content will be more beautiful and standard.
mode = "BAIDU" # Currently only supports "BAIDU" and "DUCKDUCKGO"。
# 2.Respond to external knowledge
results = center.get_response(question, flag, mode)
for result in results:
print(f"{result}\n\n")
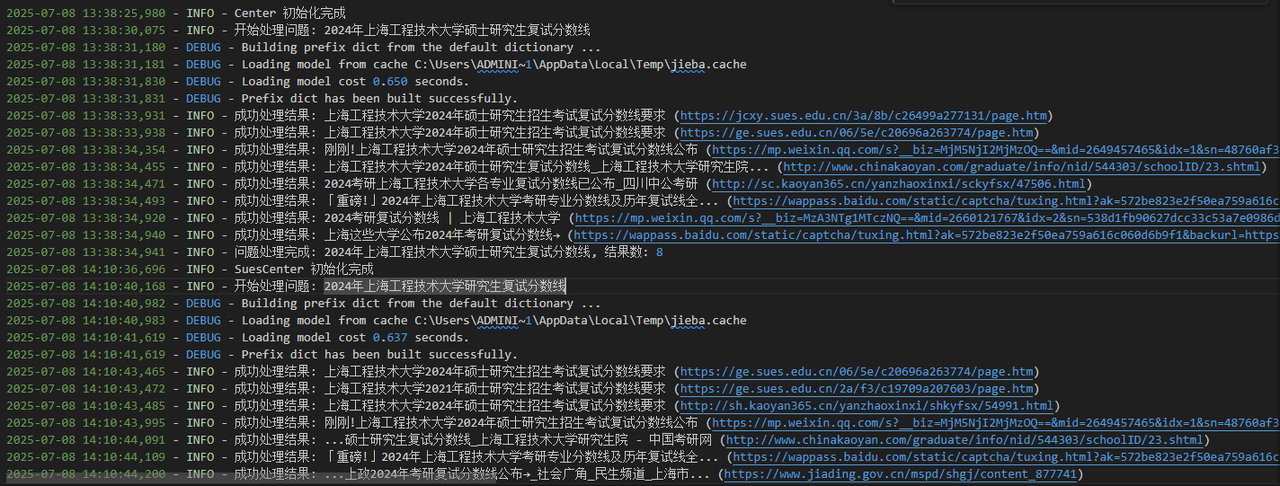
- 日志:
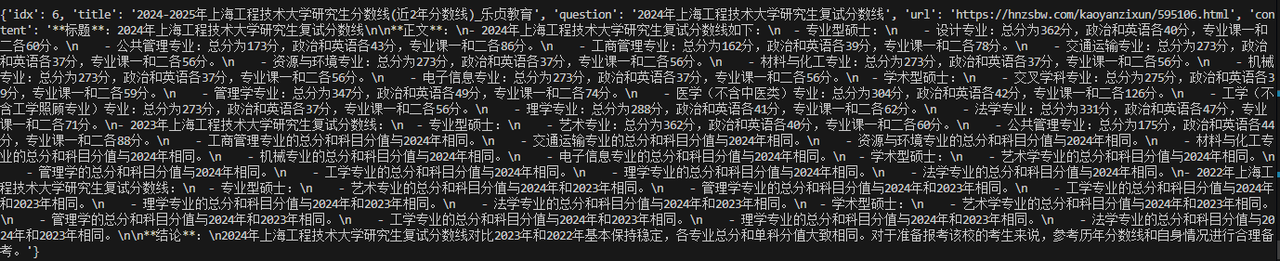
- 控制台输出:

OpenXLab 的使用
本项目已上传到 OpenXLab 平台,直接在 OpenXLab 应用中心搜索 “FreeKnowledgeAI” 即可访问,应用链接:https://openxlab.org.cn/apps/detail/wwz1111/FreeKnowledgeAI
灵活的参数控制
我们允许传入各种参数以更好地控制输出,包括:
question: 用户输入的问题 (必填)。flag: 是否使用大型模型提取已抓取的外部知识的核心内容(默认为 True)。
注:我们默认使用的是 InternLM2.5-7B 模型。
mode: “BAIDU”、“DUCKDUCKGO” (默认为 “DUCKDUCKGO”),或 “URL_SPECIFIC”。
注:使用“DUCKDUCKGO”时需要使用 VPN,而“BAIDU”则不需要。我们推荐使用 “DUCKDUCKGO”,因为抓取的结果更准确,但百度的响应速度会更快。
specific_url:指定要直接抓取的确切 URL。
示例:“https://docs.python.org/3/tutorial/
model:您可以选择要使用的大型模型(默认为 “internlm/internlm2_5-7b-chat”)。base_url:模型的base_url。key: 传入你自己的密钥。max_web_results: 获取抓取的外部知识数量(默认 5)。save_format:指定保存结果的格式。设置为 “json” 可自动将结果保存到以您的问题命名的文件中(例如,“your_question.json”)。
错误提示:
当您无法获取网站内容时,请不要担心,只需多等一会儿,因为有些网站需要验证。另一种解决方案是增加重试次数和线程休眠时间。
完整示例
from FreeKnowledge_AI import knowledge_center
center = knowledge_center.Center()
question = "2025年EMNLP会议的主题是什么?"
flag = True
mode = "DUCKDUCKGO"
results = center.get_response(question, flag, mode, model="internlm/internlm2_5-7b-chat",
base_url="xxxx", key = "xxx", max_web_results = 2)
for result in results:
print(f"{result}\n\n")
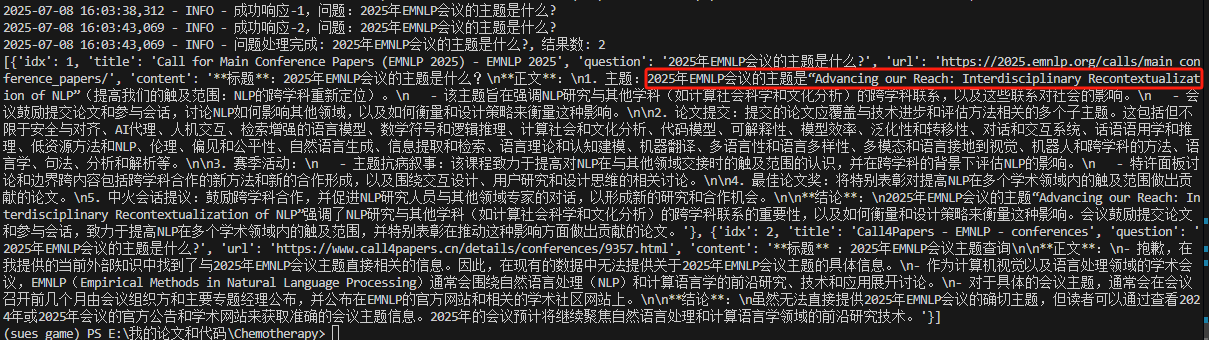
可以发现 FreeKnowledge-AI 能够很好地找到最相关的内容,即“Interdisciplinary Recontextualization of NLP”。

对比其他搜索引擎(直接调用API)
使用同一个问题——2025年EMNLP会议的主题是什么? 对比下其他搜索引擎的返回结果。
DuckDuckGo API
DuckDuckGo 是一个较大的搜索引擎,其英文搜索质量较好,中文搜索质量很差。(其实都很一般)
from duckduckgo_search import DDGS
from pprint import pprint
with DDGS() as ddgs:
pprint([r for r in ddgs.text("EMNLP2025年的会议主题", region='cn-zh', max_results=10)])
很不稳定:
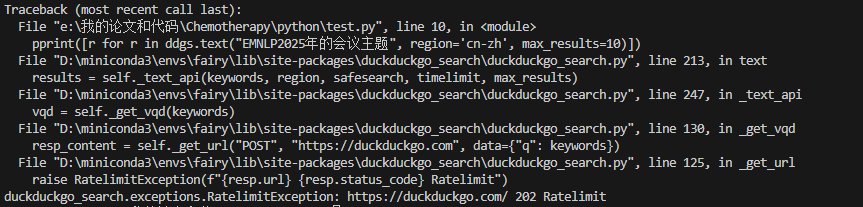
成功时的效果:可以发现生成的内容与问题不太相关。
**优点:**免费,响应速度快。
**缺点:**不稳定,生成内容质量不高。
BoCha API
支持自然语言搜索的 Web Search API,能从近百亿网页和生态内容源中搜索高质量世界知识,包括新闻、图片、视频、百科、机酒、学术等。效果比 DuckDuckGO API 要好很多且稳定,但是需要付费。
相关链接:https://bochaai.com/
# BoCha AI Search Python SDK
import requests, json
from typing import Iterator
BOCHA_API_KEY = "YOUR-API-KEY"
BOCHA_API_URL = "https://api.bochaai.com/v1/ai-search"
def bocha_ai_search(
query: str,
api_key: str,
api_url: str = "https://api.bochaai.com/v1/ai-search",
freshness: str = "noLimit",
answer: bool = False,
stream: bool = False
):
""" 博查AI搜索 """
data = {
"query": query,
"freshness": freshness,
"answer": answer,
"stream": stream
}
resp = requests.post(
api_url,
headers={"Authorization": f"Bearer {api_key}"},
json=data,
stream=stream
)
if stream:
return (json.loads(line) for line in parse_response_stream(resp.iter_lines()))
else:
if resp.status_code == 200:
return resp.json()
else:
return { "code": resp.code, "msg": "bocha ai search api error." }
def parse_response_stream(resp: Iterator[bytes]) -> Iterator[str]:
"""将stream的sse event bytes数据解析成line格式"""
for line in resp:
if line:
if line.startswith(b"data:"):
_line = line[len(b"data:"):]
_line = _line.decode("utf-8")
else:
_line = line.decode("utf-8")
yield _line
response = bocha_ai_search(
api_url=BOCHA_API_URL,
api_key=BOCHA_API_KEY,
query="EMNLP2025年的会议主题",
freshness="noLimit",
answer=False,
stream=False
)
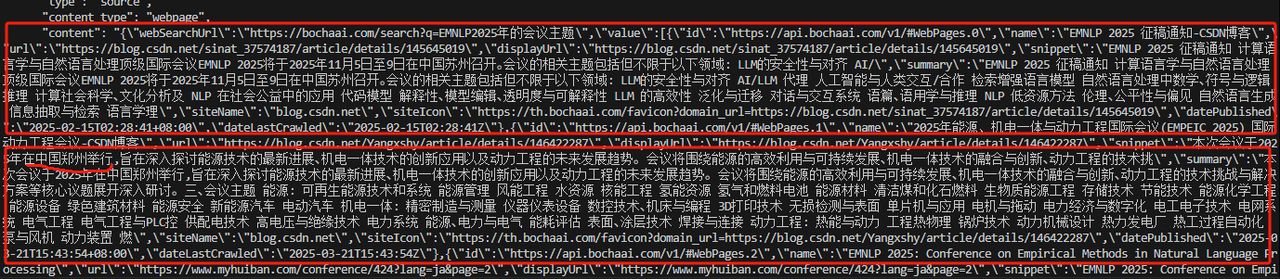
print(json.dumps(response))
对结果仔细分析可发现,虽然博查API返回的第一个结果跟问题“EMNLP2025年”相关,但是内容阐述的是征稿涉及的方向,缺少最关键的内容,即“跨学科”。其次返回的第二个结果跟 EMNLP 完全不相干。

exa API
Exa API 是作者用过所有外部知识接口里效果最好的一个,无论是内容的相关程度和排版都是最好的,但是需要付费(大概0.015美金一个问题,返回5-10个结果)。
from exa_py import Exa
exa = Exa(api_key = "xxxx")
result = exa.search_and_contents(
"2025年EMNLP会议的主题是什么?",
text = True,
num_results = 5
)
print(result)
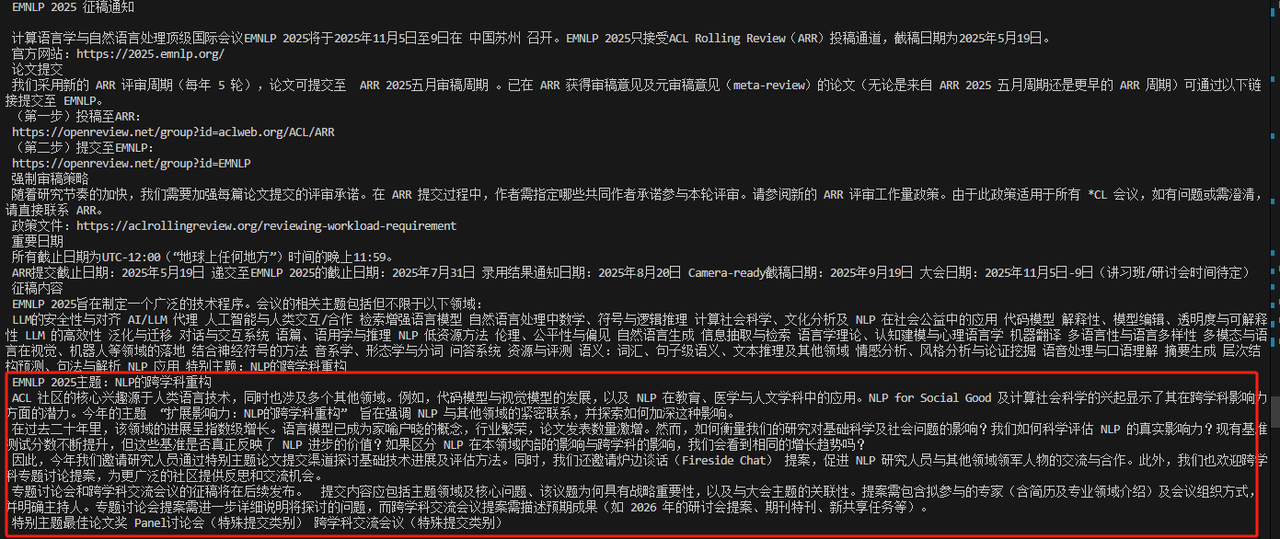
实验对比
数据集的构建:由于目前对于搜索引擎的评估数据集较为缺乏,目前存在的数据集大多都是开放性问答的数据,这对准确评估搜索引擎在真实复杂场景下的检索与推理能力构成了显著阻碍。因此我们构建了覆盖多个领域的综合性评测数据集,用于作为搜索引擎评测的统一基准。该数据集包括学术搜索数据集与医疗数据集,所有查询均为非开放式且具有较高难度。每个查询均在原始来源网站上配有可验证的答案,并经过领域专家的独立交叉校验。数据集进一步划分为基于事实的判断类问题与基于事实的简答类问题两类,我们还将持续扩展至其他学科领域,并开放更新版本。在评测过程中,我们将各搜索引擎的输出输入至InternLM3-8B模型,由其统一对比搜索生成答案与可验证的答案,以确保结果评估的一致性与可靠性。其中Example 1和Example 2为学术领域样本示例。
Example 1:
{
"query": "EMNLP 2024的投稿主题是否包括计算社会科学与文化分析?",
"domain": "学术",
"ground_truth": true,
"answer_type": "boolean"
}
Example 2:
{
"query": "ACL 2025主题轨道的核心内容是什么?",
"domain": "学术",
"ground_truth": "聚焦自然语言处理模型的泛化能力,包括如何增强模型在组合性、结构性、跨任务、跨语言、跨领域及鲁棒性等多维度的泛化能力,探究影响泛化的因素,评估泛化能力的有效方法,以及大语言模型在泛化方面的关键局限性等",
"answer_type": "entity"
}
Example 3 和Example 4 为医疗领域样本示例。
Example 3:
{
"query": "ACL 2025主题轨道的核心内容是什么?",
"domain": "学术",
"ground_truth": "聚焦自然语言处理模型的泛化能力,包括如何增强模型在组合性、结构性、跨任务、跨语言、跨领域及鲁棒性等多维度的泛化能力,探究影响泛化的因素,评估泛化能力的有效方法,以及大语言模型在泛化方面的关键局限性等",
"answer_type": "entity"
}
Example 4:
{
"query": "根据共识,儿童脓毒性休克液体复苏的首剂液体选择是什么?推荐剂量是多少?",
"domain": "医疗",
"ground_truth": "首剂液体选择等渗晶体液,剂量为20ml/kg,于5-10分钟内静脉推注",
"answer_type": "entity"
}
实验结果
为比较 FreeKnowledge AI 与 Bocha、Duckduckgo 的效果,我们构建了一个基于人工智能判别的评估框架。具体而言,首先利用三种搜索工具分别在两个数据集上检索全部答案;随后由 AI 判定检索结果中是否包含对应的答案。若包含,则记为“是”;否则记为“否”。
实验结果如表 1 与表 2 所示。结果表明,FreeKnowledgeAI 在两个数据集上均优于其他两种主流搜索工具。特别是在包含大量时效性信息的学术数据集上,FreeKnowledgeAI 相较于 Bocha 与 Duckduckgo 分别实现了 34% 与 39.5% 的性能提升。
| 方法 | 正确数量 | 准确率 |
|---|---|---|
| Bocha | 14/200 | 7% |
| Duckduckgo | 3/200 | 1.5% |
| FreeKnowledgeAI | 82/200 | 41% |
表1:学术数据集评测结果
| 方法 | 正确数量 | 准确率 |
|---|---|---|
| Bocha | 86/200 | 43% |
| Duckduckgo | 13/200 | 6.5% |
| FreeKnowledgeAI | 138/200 | 69% |
表2:医疗数据集评测结果
结论
FreeKnowledge-AI 是一款完全免费的 AI 知识搜索引擎。与同类免费工具相比,它返回的结果更精准、更稳定;与Bocha、Exa 等付费服务相比,其内容相关性毫不逊色,却无需任何费用。唯一的不足是检索耗时略长。最后,再次感谢上海人工智能实验室书生大模型对本项目的支持。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)