【论如何对LLM进行反向育儿——错的也当对的训?】——两篇关注错误样本的论文-A3PO和Glow【阅读笔记】
本期介绍两篇关注如何使用错误样本的论文 ,一篇是 *Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards*,后面简称`A3PO`另一篇是 *Learning from Mistakes: Negative Reasoning Samples Enhance Out-of-Domain General
很巧,这周又刷到了两篇观点比较接近的论文,LLM这个方向是在经受饱和式研究投入吗😂,
一篇是 Rethinking Sample Polarity in Reinforcement
Learning with Verifiable Rewards,后面简称A3PO
另一篇是 Learning from Mistakes: Negative Reasoning Samples Enhance Out-of-Domain Generalization *,后面简称GLOW
这两个简称都是作者自己起的方法名。这两个工作一个面向RL一个面向SFT,都在强调训练中的负样本对训练的健康带来了积极影响。
Rethinking Sample Polarity in Reinforcement Learning with Verifiable Rewards
一句话总结
这篇文章通过实验观察到,在RLVR中,:
其一、训练【正样本】会让LLM更喜欢输出正样本中出现过的Token。
其二、训练【负样本】则能促进【策略熵增】。
由此,作者对DAPO训练函数中 Advantage 的计算细节进行了改造,在训练初期↓:
一方面,提高【正样本】中低 prob Token的 Advantage;
另一方面,降低【负样本】中高 prob Token的 Advantage(负样本的Advantage 为负,降低即是放大幅值,增强惩罚)。
这一方法,让7-8B规模Qwen系列模型在AIME数据集上获得了约3个点的提升。
** 正样本和负样本,分别指的是Roll-out的结果与ground-truth 相同和不同的样本。
文章细节
1. 将Advantage拆成正负样本两部分

DAPO 的一层改进就是对 AAA 动态scale和clip,而A3PO的作者的观察就始于把AAA拆成了正样本和负样本两部分。
而在RLVR的框架下,正确的答案 Reward =1 ,A3PO的作者把他作为正样本PPP,错误的答案reward =0 ,A3PO作为负样本NNN。A3PO 作者分别放大了APA_PAP 和 ANA_NAN,来观察可能出现什么情况↓。下图中NSR就是把APA_PAP的乘数变为0,这就只有负样本影响训练了。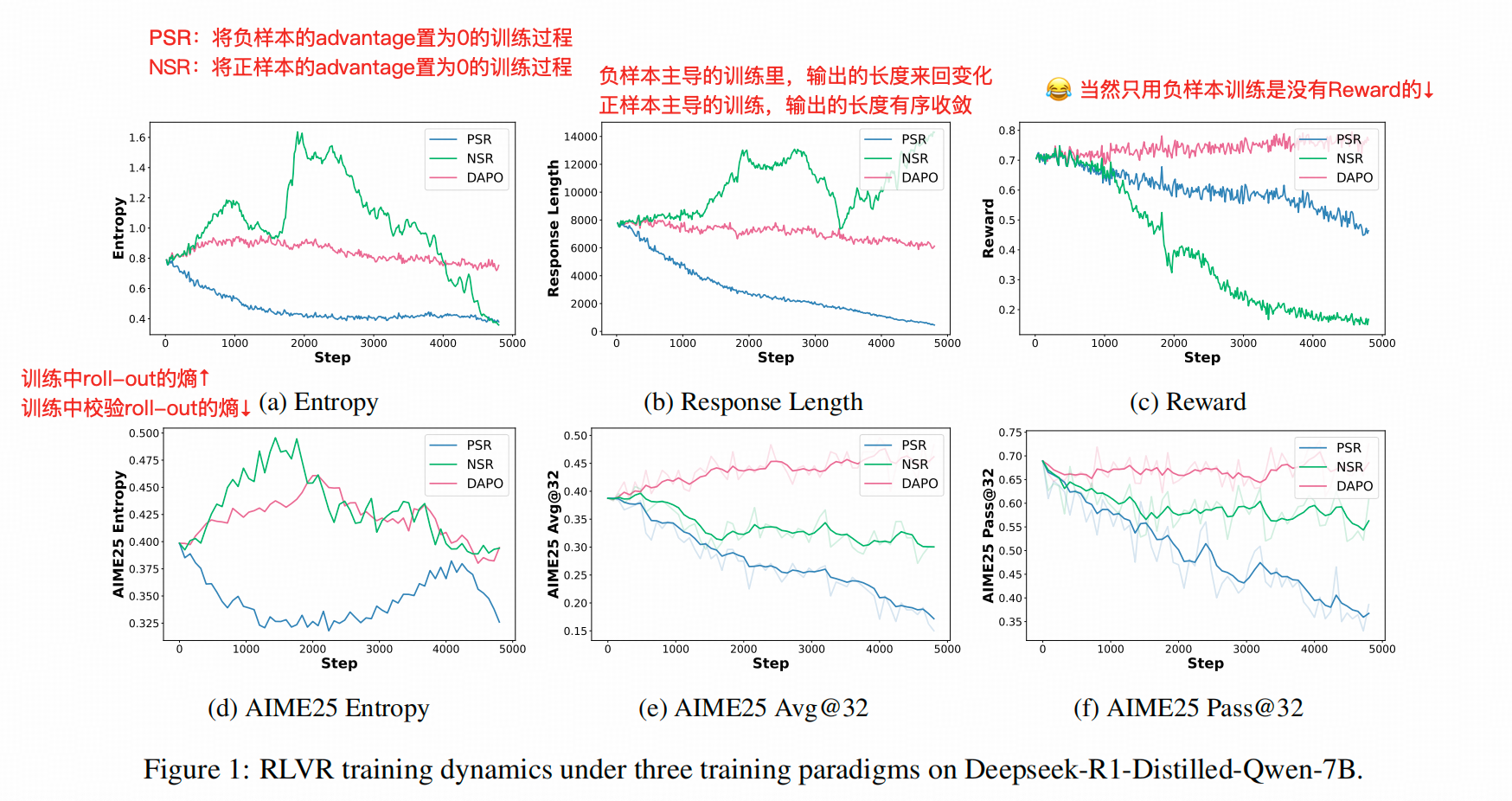
一个显眼的观察就是,只训练负样本带来的Advantage(NSR)能够显著放大LLM的熵,←_← 当然,这也没啥用,Reward崩了。
2. 把视野聚焦到Token级别
作者发现,仅回传正样本的Advantage(PSR),能够明显放大正样本中出现过的辞藻(Token)。仅回传负样本(NSR)的Advantage,能够刺激模型输出新的辞藻(Token)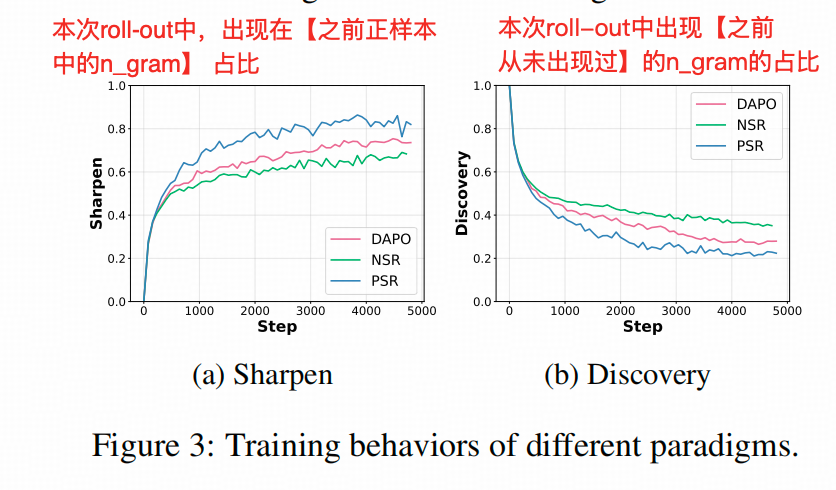
借用The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning 的图(这个图画得非常好(๑•̀ㅂ•́)و✧)很容易看清楚这个机制。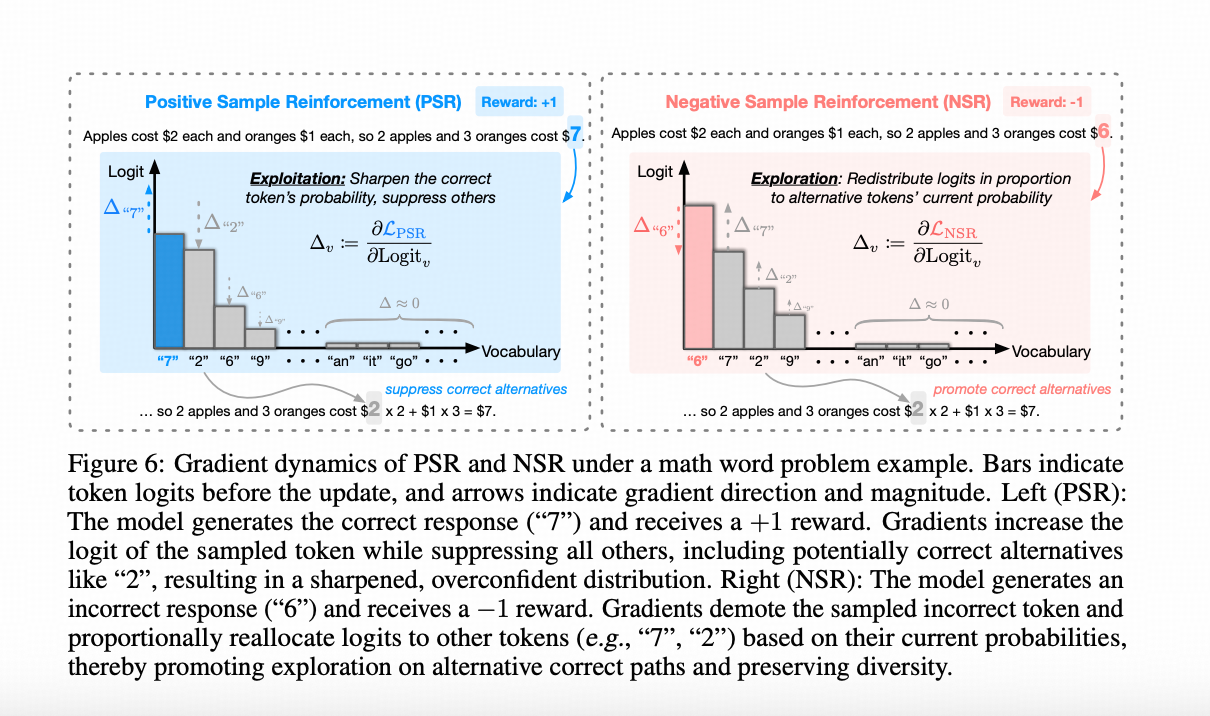
3. 对已出现但低概率的Token有影响吗?
确定了方向性的影响之后,作者测试了程度性的影响:作者将正样本的Advantage缩小到原来的1/5(下图PL0.2),或扩大到原来的5倍(下图PL5),以对比,在训练过程中,LLM输出概率较高/较低的Token会受到什么影响。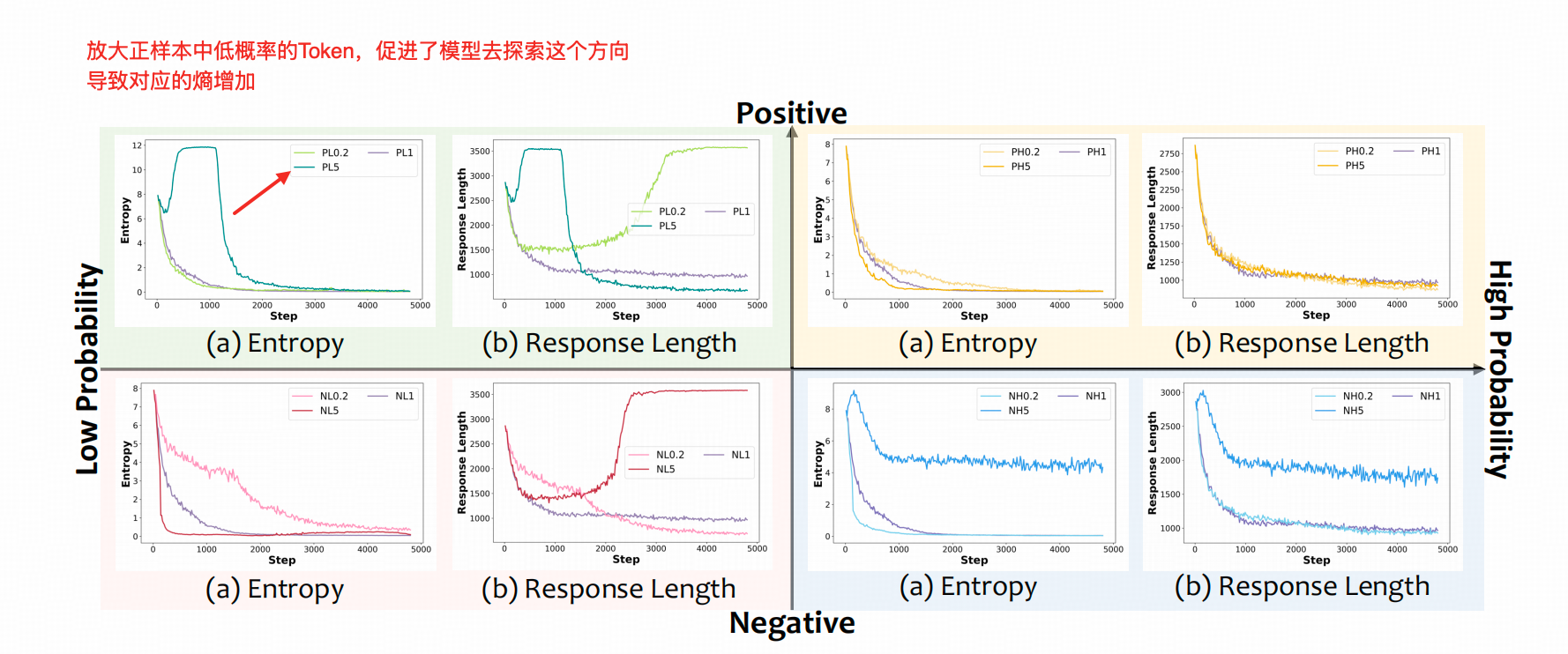
结果发现👆🏻,将正样本中低概率的Token的Advantage放大5倍,整个模型低概率Token的熵都疯狂增加了一段时间。
将负样本中的低概率的Token的Advantage放大5倍,整个模型的高概率Token的熵都较高。
这里有几个细节需要澄清:
其一,高概率和低概率Token的设定,一个roll-out(一个batch所有roll-out)输出Token中,prob的前20% 和最后20%。应该是个动态设定,因为我在正文和附录里都没有找到作者提前收集Token并计算分布,进而进行标记的动作。
其二、作者没有解释为什么PL5在训练中期,熵突然雪崩。因为作者只配了response length,没有给Reward图,也很难说这种雪崩是收敛了,还是直接训崩了。
其三、这张图(也包括文中的figure5)没有清楚说是整个LLM输出的策略熵还是对应Token的熵的变化。(结合作者打图的特点和他的解决方案,应该指的是模型输出的策略熵,但既然作者没有明说,我也只能描述为高概率Token的熵或低概率Token的熵)
4.作者的方案
他的做法是,在训练的初期,放大【正样本中低概率】的Token和【负样本中高概率】的Token对应的Advantage。
其中ρ\rhoρ是固定值,α\alphaα也是固定值,这样随着训练步数的增加,ρ−αs\rho-\alpha sρ−αs 随着训练步数增加而减少。
5. 效果怎么样
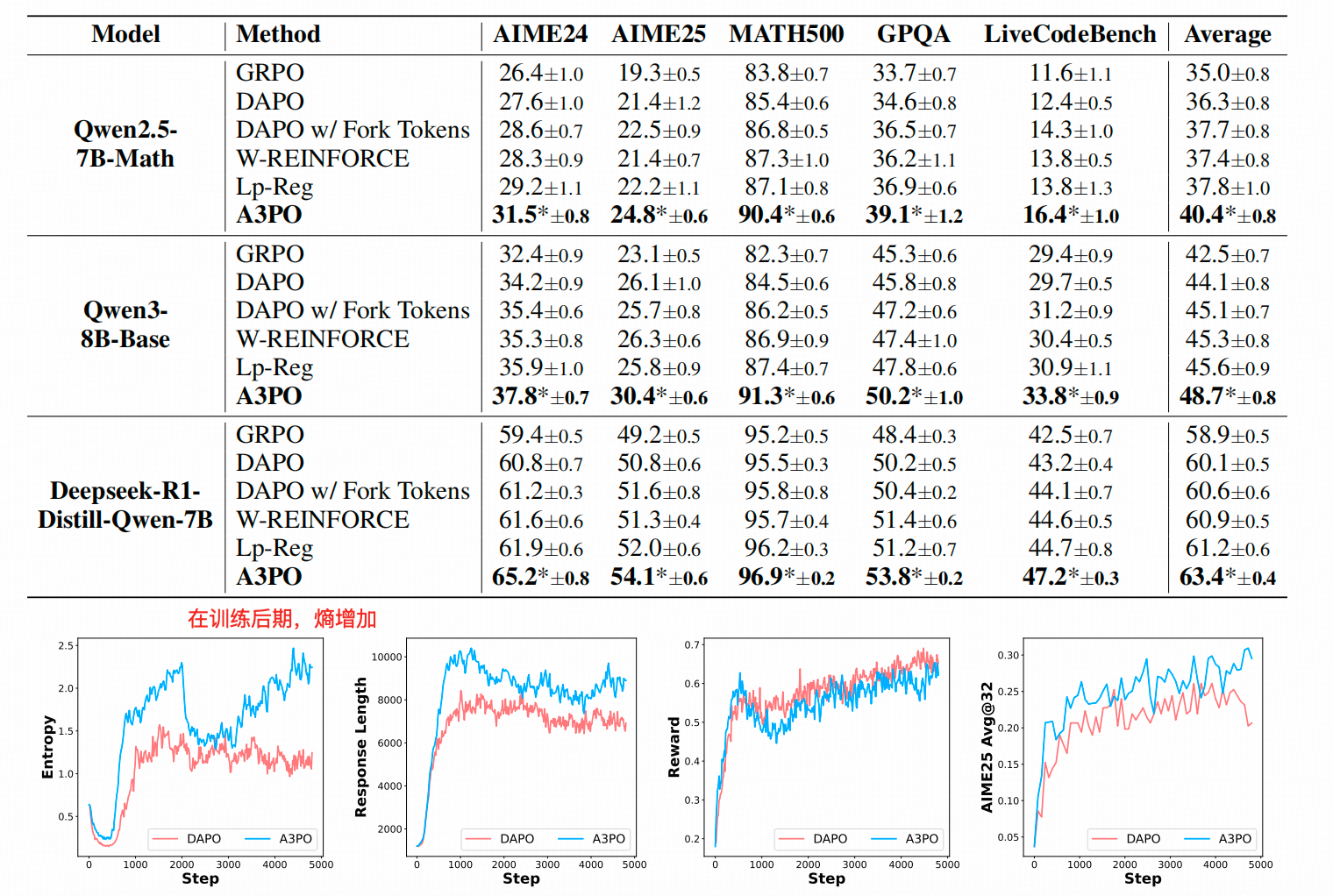
单看结果表,指标涨了。但这里有两个问题:
其一、这是average@32,而不是一般用的pass@16或32;
其二、图中,中后期的熵增现象作者没有解释,但这是一种非常特异的现象,尤其是在作者配置的放大效果到200步就没有了的情况下。
Learning from Mistakes: Negative Reasoning Samples Enhance Out-of-Domain Generalization
一句话总结
作者首先利用8B模型在数学推理任务上生成推理Trace,并将其分为【正样本】(答案对)和【负样本】(答案错),并用单独使用【正样本】或【负样本】训练推理任务,发现OOD数据集上,单独使用【负样本】训练的模型,泛化能力更强。
分析时,作者把【负样本】分成9大类,但他没有基于这些分类深入展开,而是直接跳到他提出的训练方案:放大那些【在两个epoch间loss下降缓慢】的Token的loss,并展示了该方法对OOD性能的提升。
有趣的细节
1. 用负样本训练的OOD泛化性比较
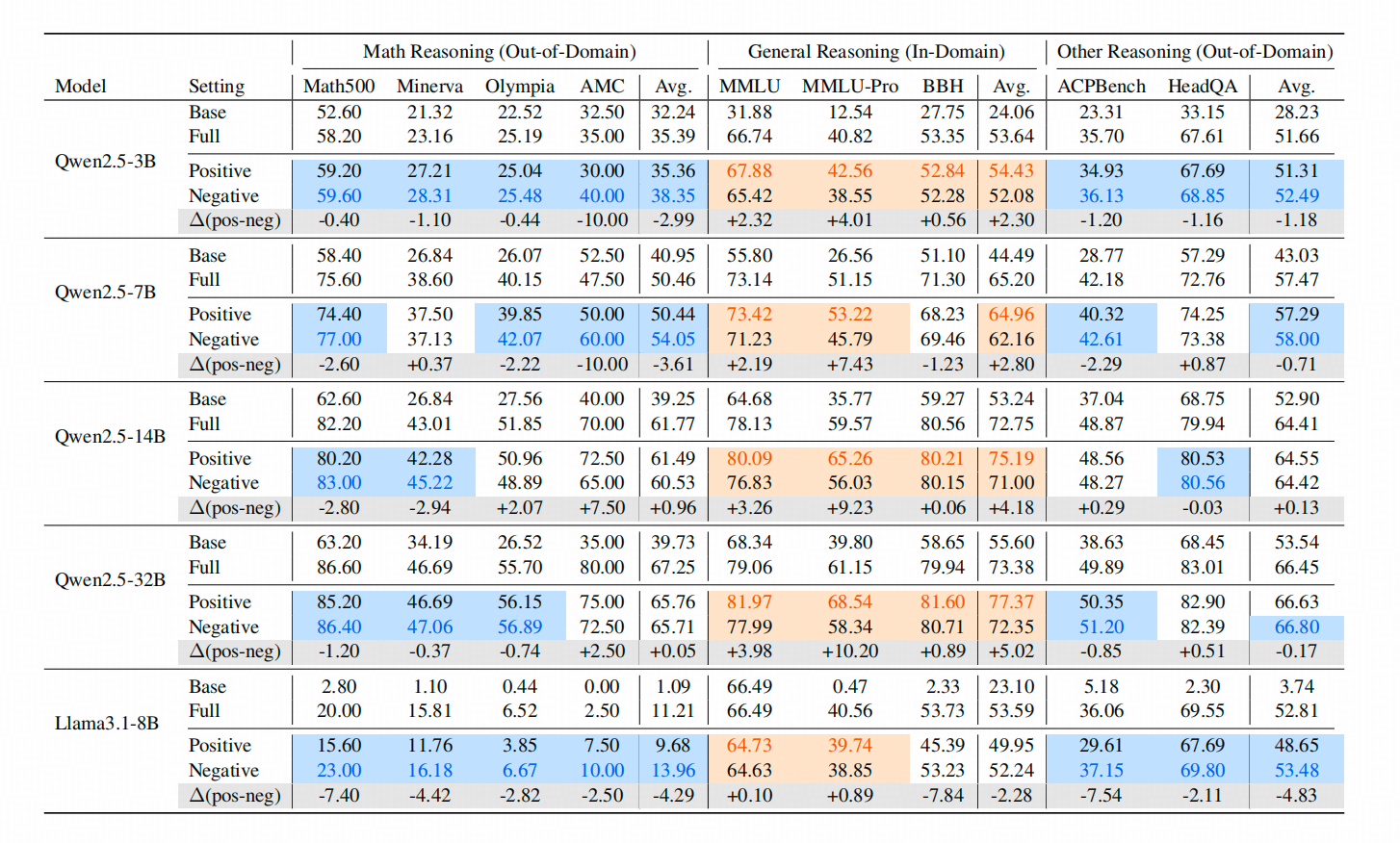
作者在MMLU上,用Qwen8B生成了一批正样本和负样本,然后观察在数学任务和医疗、规划等推理任务的能力与基线1——【完全不训练】和基线2【用正负样本同时训练】对比效果。结果可以看到,在一些OOD数据集上,单独使用【负样本训练】的结果更好一点点。
那么自然引出一个关键问题——这里的负样本都是哪儿有问题呢?
2. 8B模型生成负样本的大类
作者用LLM(Gemini)给生成的负样本分类几个大类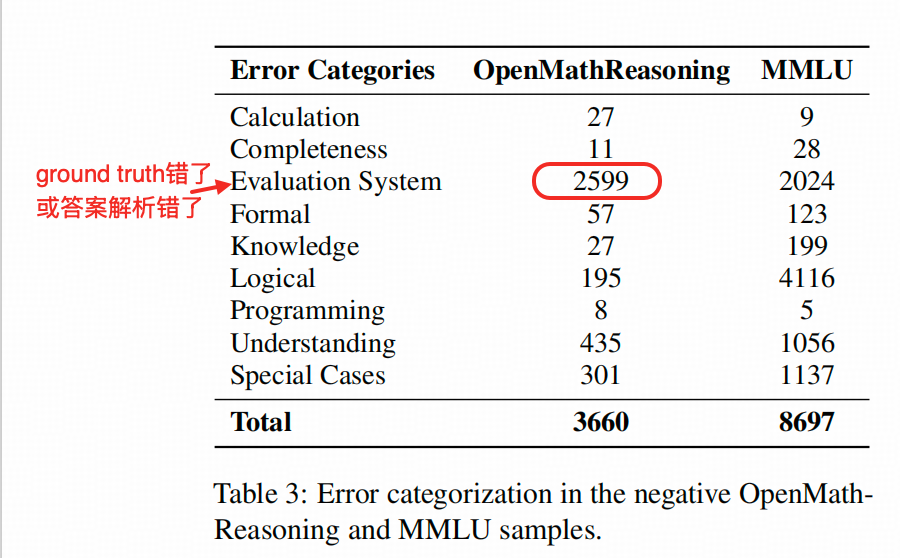
大类下还有小类,以OpenMathReasoning中最大比例的“Evaluation System”这类错误为例,下图中紫色的部分,代表了作者标记的这类错误在负样本集中的数量。labeled Error在作者的打标prompt里的说明是“Incorrect Ground Truth”——即数据集的答案错了,这也是我这里没有讨论作者关于OpenMathReasoning数据集相关结果的原因——如果这么大比例是标错了,那负样本就不是负样本,是正样本了呀。😂
我本来觉得作者这个比较负样本训练后跟正样本训练后 不同Token的熵变化的图是一个很好实验图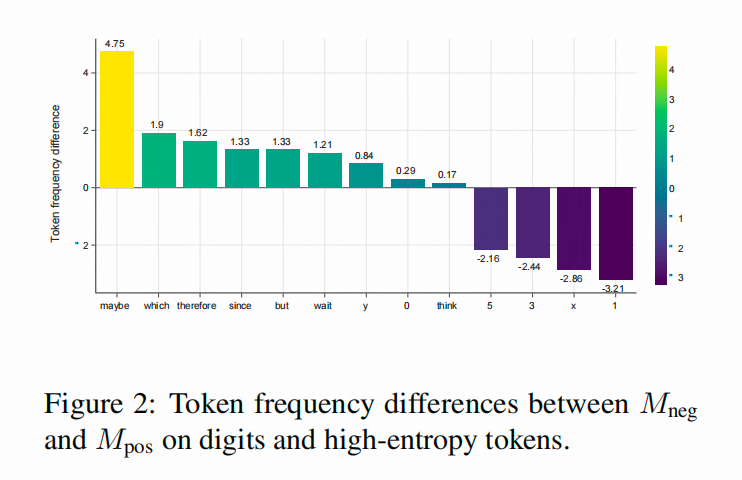
但是,因为这个图是从OpenMathReasoning的相关实验中打出来的,现在就说不清楚,到底是怎么回事了(+﹏+)~
3. 作者方法
作者在【从分析现象推导解法】这部分的推理其实有点问题,作者的解法Glow的推出也有点跳跃,跟负样本也不是特别有关系。这里只简单说一下他的方案,也是Token-wise loss weighting类的方案。
作者这个集给Token Loss加权的方案是将两个Epoch之间,同一个解中同一个Token对应的Loss的差值(Loss下降越大,权重越低)作为加权因子,用sigmoid函数给这个因子做个01化扭曲。就这样一个操作,当然,作者的实验结果表显示结果相对于标准SFT效果更好。
评价和感想
- 给Token上加权是一个给SFT做微创新的老路,我之前在行为知识编辑任务上也用过,但这个点终究是个Trick,工业场景用一用就算了,学术场景希望还是能得到更General,范式更简单的方案。
- 2025年,RLVR这个方向已经被卷没边了。一周内,刷到相似方向的文章已经是我的预期了,一方面这是xhs的推荐算法好😂,一方面也确实是因为卷。
- 但是我们应该注意到,这种卷得益于已经被配置好的实验环境:能够检验正确与否的任务,质量不错的推理数据集,逐渐配置完善的训练和推理框架……这都很重要,但最近好像也很少看到这类setup问题的研究。感受上,现在很应该把当前的setup外推一层,比如,从数学这类准备好Ground Truth的问题外推到可在Agent的帮助下验证结果问题有哪些?评估下来,其中哪些和更多的场景关联性更高,更值得作为Meta实验来考虑?实验环境怎么配置?
- 从这一周刷到的新文章看,一方面好像研究方向上无题可解,另一方面,LLM在生产端(我在企业)又是哪儿哪儿都得调。这些年工作下来,看到的从来都是学术界在定义问题,企业界在优化用法。那现在学术界定义的问题是什么呢?Self-Envoving Agent吗?
- 上个月,Measuring Agents in Production这篇文章的角度就很好,调查到企业的应用Agent的过程中——平均调用工具量其实并不多,主要的生产方式仍然是人机协作(因为不符合人类预期和要求),幻觉仍然是比较严重的要处理的问题。这些都是不需要假想的实际情况。2026年,我们能在几月看到新篇章的开启呢?(Deepseek你不要在春节搞事情😂)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)