当大模型遇见数据库:LLM如何革新数据管理
摘要 人工智能技术正在重塑数据库管理领域(AI4DB),传统方法在查询优化、索引推荐等方面已展现潜力,但面临动态适应性差、泛化能力有限、运维成本高等瓶颈。大语言模型(LLM)的兴起为数据库管理带来新机遇,其强大的语言理解、推理和泛化能力推动系统向"以意图为中心"演进。LLM4DB框架包含五大核心组件:检索增强生成(RAG)、领域特定微调、提示管理、智能体和向量数据库,协同实现智
用于数据库管理的人工智能技术(AI for Database Management,简称 AI4DB)是一个近年来逐渐受到关注的研究方向,其核心目标是利用人工智能技术来辅助或自动完成传统数据库系统中的关键任务。传统的 AI4DB 方法(指利用传统人工智能技术如经典机器学习、深度学习模型等)已经在查询优化、索引推荐等方面展现了可观的潜力,但其固有的局限性也日益凸显,尤其是在处理当今高度动态和复杂的数据环境时。
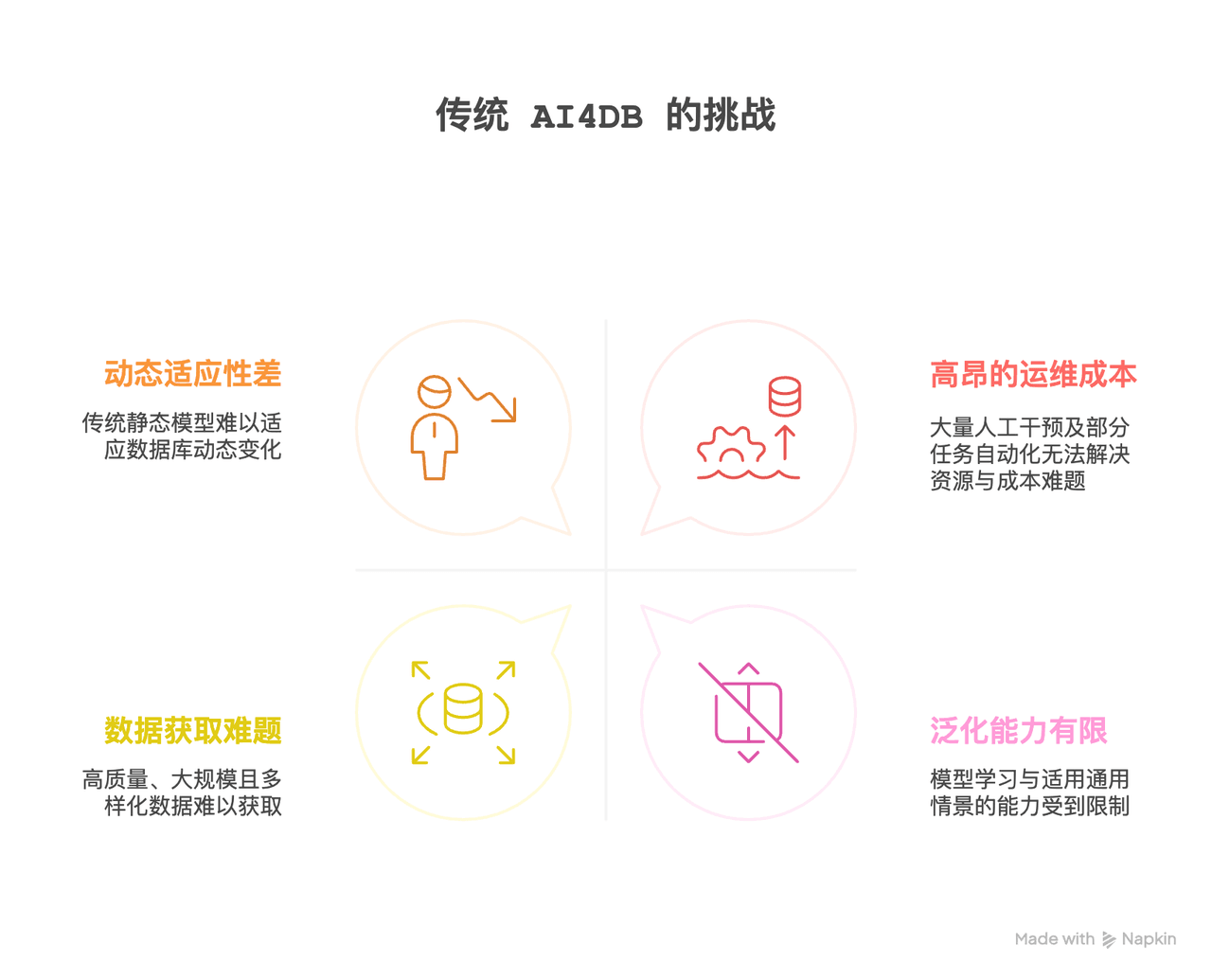
具体而言,传统 AI4DB 面临以下主要瓶颈:
-
动态适应性差:数据库本质上是动态的,数据会频繁地进行插入、删除和更新操作,导致数据分布和输入输出关系随时间演变。传统机器学习模型通常假设数据分布是静态的,一旦发生概念漂移,模型的预测准确性就会降低。为了维持性能,系统不得不频繁地重新训练模型,这既耗时又昂贵。
-
泛化能力有限:“泛化”指的是模型在未见过的场景中保持良好性能的能力。许多 AI4DB 的研究专注于为特定、有限的条件设计解决方案,这阻碍了模型学习和适应通用情景的能力。例如,一个为特定数据库实例或特定工作负载优化的模型,很难直接迁移到新的数据库或变化了的工作负载上。又或者,一个为 TPCH 数据集设计的查询优化模型,可能在另一种业务数据库(如金融或电商系统)中无法直接适用,必须重新训练或调参才能达到可接受的性能。
-
高昂的运维成本和人力依赖:传统数据库系统通常需要大量的人工干预来进行配置、调优和维护,这不仅消耗资源,也容易出错。虽然,AI4DB 系统旨在自动化部分任务,但模型的训练、验证、部署和持续监控本身也带来了新的复杂性和成本。
-
数据获取与模型可解释性难题:高质量、大规模且多样化的训练数据是大多数 AI 模型取得良好性能的前提。但在 AI4DB 领域,获取此类数据往往很困难,因为数据可能涉及安全敏感信息,或者依赖于数据库管理员(DBA)的经验知识,难以大规模收集。
LLM 带来的新机遇:强大的语言理解、推理和泛化能力
自 2020 年左右,随着数据库系统面临数据规模快速增长、场景日益多样化、工作负载高度动态等挑战,学术界和工业界逐渐意识到传统 AI4DB 方法发展已进入瓶颈期。与此同时,自 2022 年 OpenAI 发布 ChatGPT 以来,大语言模型(Large Language Model, LLM)在自然语言理解与生成、复杂任务规划和跨任务迁移能力方面展现出颠覆性潜力。
LLM 的“横空出世”不仅是模型规模和性能上的跃迁,更标志着人工智能范式的重大转变,也为数据管理系统的智能化带来了前所未有的可能性。LLM 凭借其强大的自然语言理解、上下文建模、复杂推理与泛化能力,正在深刻地重塑人们与数据的交互方式,推动数据库管理系统从“以过程为中心(Process-centric)”向“以意图为中心(Intent-centric)”演进。在传统数据库使用中,用户需要理解数据库架构、掌握 SQL 语法并明确指定操作过程,而在 LLM 驱动的系统中,用户可以仅通过自然语言表达“想要什么”,而将“如何实现”的过程交由模型自动规划和执行。
下表从多个角度对传统 AI4DB 与 LLM4DB 能力做了对比。
| 能力 | 传统 AI4DB | LLM4DB |
|---|---|---|
| 自然语言理解 | 有限/主要基于关键词或规则 | 先进的、上下文相关的、意图驱动的 |
| 推理能力 | 限于特定训练任务/基于规则 | 复杂的、多步骤的、具备常识的 |
| 泛化能力 | 较差,难以应对概念漂移和新场景 | 强大,少量数据即可适应新任务/表结构 |
| 动态环境适应性 | 低,需要频繁重新训练 | 更高,可通过提示或高效微调适应 |
| 用户交互界面 | 通常为编程接口/SQL | 自然语言、对话式 |
| 知识获取与利用 | 依赖结构化训练数据/显式规则 | 从海量非结构化文本、代码、文档中学习;可利用先验知识 |
| 开发与维护成本 | 专用模型成本高,持续调优 | 由于迁移学习,成本可能更低,但推理成本是考量因素 |
表1: 传统AI4DB与LLM4DB能力对比
LLM4DB 整体技术框架
将 LLM 的强大能力应用于数据库管理(LLM4DB),需要一个精心设计的技术框架。这个框架通常围绕着几个核心组件构建,并通过一个典型的工作流程将这些组件协同起来,以响应用户请求并提供智能化的数据服务。
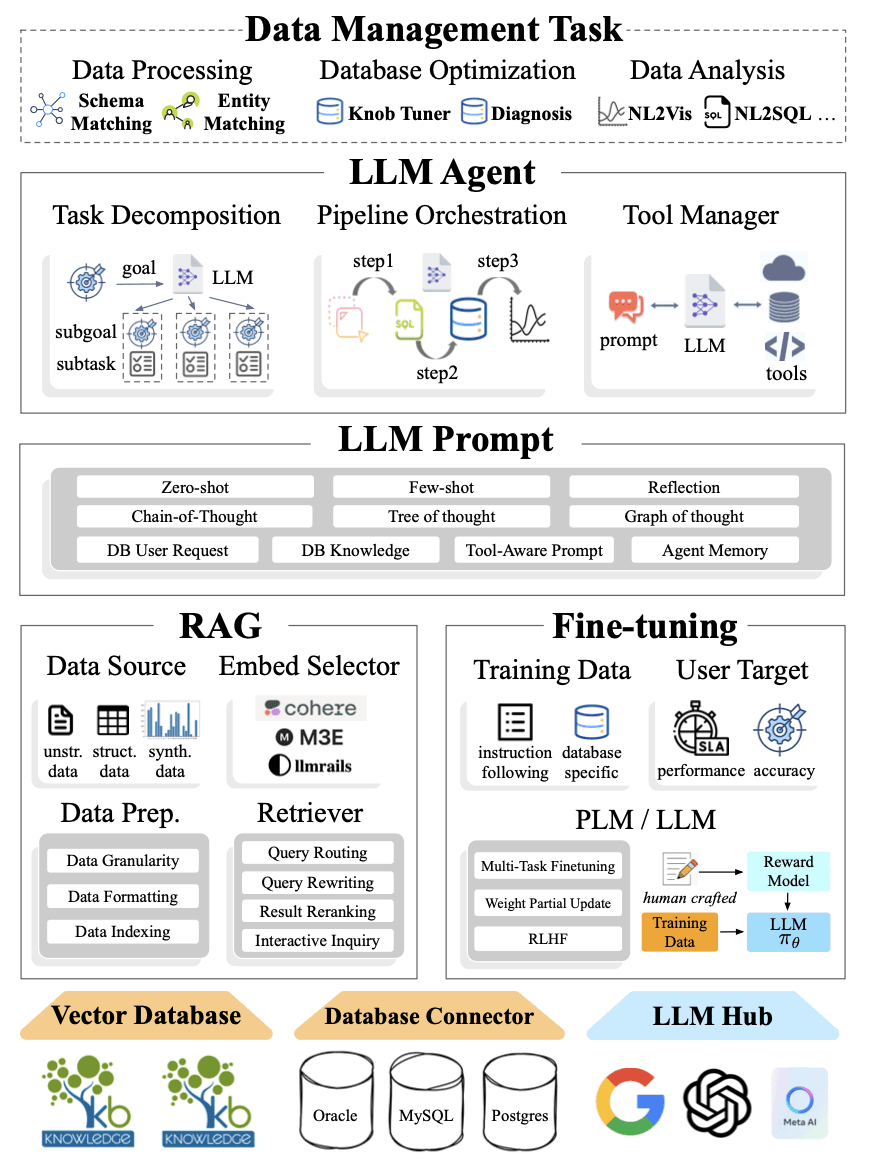
架构图出自LLM for Data Management (Li, Guoliang, Xuanhe Zhou, and Xinyang Zhao. “LLM for Data Management.” Proceedings of the VLDB Endowment 17.12 (2024): 4213-4216.)
五大核心组件:构建智能数据管理新范式
LLM4DB 的技术框架主要依赖以下五个核心组件,它们共同构成了智能数据管理的新范式:
-
RAG (检索增强生成 - Retrieval Augmented Generation):RAG 是提升 LLM 在特定领域知识准确性和时效性的关键技术。其核心思想是在 LLM 生成回答之前,先从一个外部知识库(如数据库本身、相关文档、向量数据库等)中检索与用户查询相关的信息,并将这些信息作为上下文提供给 LLM。
-
领域特定微调 (Domain-Specific Fine-tuning):虽然 LLM 具有强大的通用能力,但在特定数据库或业务场景下,通过领域特定微调可以进一步提升其性能和相关性。微调是指在一个较小的、与特定领域或任务高度相关的数据集上继续训练预训练好的 LLM。
-
LLM 提示管理 (LLM Prompt Management):提示(Prompt)是用户与 LLM 交互的主要方式,其质量直接影响 LLM 的输出效果。
-
LLM 智能体 (LLM Intelligent Agents):LLM 智能体是将 LLM 作为核心“大脑”,赋予其自主规划、使用工具、记忆和与环境交互能力的系统。
- 向量数据库 (Vector Databases):向量数据库专门用于存储、索引和查询高维向量数据。
在 LLM4DB 框架中,它们扮演着至关重要的角色:
| 核心组件 | 主要功能 | 关键技术/挑战 |
|---|---|---|
| RAG (检索增强生成) | 通过从外部知识库检索信息来增强LLM响应的准确性和时效性,减少幻觉。 | 向量数据库、语义检索、上下文整合 |
| 领域特定微调 | 使预训练LLM适应特定数据库、业务领域或任务,提升专业场景下的性能。 | PEFT (LoRA, QLoRA)、高质量领域数据集、防止灾难性遗忘 |
| LLM提示管理 | 设计、优化和管理输入给LLM的指令,以引导模型产生期望的、一致的输出。 | 提示工程(零样本、少样本、思维链)、提示版本控制、提示测试与评估 |
| LLM智能体 | 赋予LLM自主规划、使用工具、记忆和与环境交互的能力,以完成复杂数据任务。 | 任务分解、工具调用、记忆机制(短期、长期)、多智能体协作 |
| 向量数据库 | 高效存储和检索高维向量数据(如文本、图像的语义嵌入),支撑RAG和语义搜索。 | 近似最近邻 (ANN) 索引算法(如HNSW)、可扩展性、数据同步 |
表2: LLM4DB 核心组件及其主要功能
典型应用场景
LLM 凭借其独特的自然语言处理、推理和生成能力,正在数据管理的各个方面开辟新的应用场景。从提升数据库自身运行效率,到简化数据处理流程,再到赋能更智能的数据分析,LLM 正逐步成为数据领域不可或缺的“智能伙伴”。
数据库优化
传统数据库优化依赖于复杂的启发式规则、成本模型以及数据库管理员(DBA)的经验。LLM 的出现为数据库优化带来了全新的思路,使其能够更智能、更自适应地管理和提升数据库性能。
-
智能查询优化 (Intelligent Query Optimization):LLM 能够理解 SQL 查询的语义和用户的意图,而不仅仅是语法结构。基于这种理解,LLM 可以:
-
生成更优的执行计划:传统查询优化器在面对复杂查询或数据分布快速变化时,可能无法找到最优执行计划。LLM可以通过学习大量的查询模式和性能数据,甚至结合数据库的实时状态信息,来生成或推荐更高效的执行计划。例如,LLM-QO 框架将查询优化视为一个序列生成任务,通过微调 LLM 来直接生成高质量的查询计划,实验表明其在多种工作负载下均优于传统优化器和一些已有的学习型优化器。
-
自动查询重写:LLM 可以分析用户编写的 SQL 查询,识别其中潜在的低效部分(如不必要的连接、冗余的子查询等),并自动将其重写为性能更佳的等价查询。这对于不熟悉SQL性能调优的用户尤其有价值。
-
-
索引推荐 (Index Recommendation):选择合适的索引对于数据库查询性能至关重要,但手动创建和维护索引是一项复杂且耗时的工作。LLM 可以:
-
分析工作负载和数据模式:通过分析历史查询日志、数据库的表结构(schema)和数据统计信息,LLM 可以理解哪些列经常被用于查询条件、连接或排序,从而推荐创建最能提升整体性能的索引组合。
-
考虑约束条件:LLM 在推荐索引时,还可以考虑存储空间限制、索引维护开销等约束条件,以达到性能和资源消耗的平衡。例如,LLMIdxAdvis 框架将索引推荐建模为一个序列到序列的任务,输入工作负载、存储约束和数据库环境信息,直接输出推荐的索引列表。
-
数据预处理
数据预处理是任何数据分析或机器学习项目中的关键步骤,往往占据了整个项目周期的大部分时间。传统的数据预处理工作,如数据清洗、转换、集成等,通常是劳动密集型且易出错的“脏活累活”。LLM 的引入,为这些任务带来了智能化的解决方案,能够显著提升效率和质量。
-
智能数据清洗 (Intelligent Data Cleaning):LLM 能够理解数据的语义和上下文,从而更智能地识别和处理数据中的错误和不一致性。
-
识别异常值和不合逻辑的值:例如,LLM 可以根据一列数据的上下文(如年龄列不应出现负数,或者某个国家名称不应出现在另一个国家的州/省列表中)来识别看似合理的错误值。
-
处理缺失值:LLM 可以根据上下文信息,更合理地推断和填充缺失值,而不仅仅是使用简单的均值、中位数或固定值填充。
-
格式标准化和不一致性修复:例如,将不同格式的日期统一为标准格式,或者修正同一实体(如公司名称)的多种不同写法。 尽管 LLM 在处理行内上下文相关的简单错误方面表现出色,但在识别需要跨多行理解数据分布的复杂错误(如趋势异常、数据偏差)方面仍有局限性。
-
-
数据转换与格式化 (Data Transformation and Formatting):LLM 强大的文本生成和理解能力使其非常适合执行复杂的数据转换任务。
-
非结构化/半结构化数据转结构化:例如,从自由格式的文本描述(如产品评论、医疗记录、合同文档)中提取关键信息,并将其转换为结构化的表格数据。STROT 等框架利用结构化提示和反馈引导的推理来解释和转换结构化数据。
-
代码生成用于数据转换:LLM 可以根据用户的自然语言描述(如“将所有金额从美元转换为人民币,并计算总和”)生成相应的 Python 或 SQL 代码来执行数据转换。
-
-
数据增强 (Data Augmentation):在机器学习任务中,高质量的训练数据至关重要,但获取大量标注数据往往成本高昂。LLM 可以用于生成合成数据,以扩充现有的训练集。
-
生成合成结构化数据:LLM-TabFlow 等方法利用LLM的推理能力捕捉表格数据中列与列之间的复杂关系,并结合扩散模型等技术生成新的、与原始数据分布相似的表格数据,同时试图保留这些关系。GPT-4o 也被用于生成合成的临床表格数据集。
-
文本数据增强:对于 NER 等 NLP 任务,LLM-DA 等技术可以在上下文层面(如改写句子)和实体层面(如替换同类型实体)对已有文本数据进行增强,生成更多样化的高质量训练样本。
-
智能分析
LLM 最令人兴奋的应用之一,无疑是其在数据分析领域的潜力。通过将复杂的分析过程转化为更自然、更具交互性的体验,LLM 正在逐步降低数据分析的门槛,使得更多非专业用户也能从数据中获取洞察,真正迈向“人人都是数据分析师”的时代。
-
自然语言到 SQL 的转换 (Natural Language to SQL - NL2SQL):这是 LLM 在数据分析中最直接也最受欢迎的应用之一。用户可以用日常语言提出数据查询请求,LLM 则负责将其准确地翻译成可执行的 SQL 语句。例如,业务人员可以直接问“告诉我上个月销量最高的五款产品及其对应的销售额”,而无需编写复杂的 SQL JOIN 和聚合查询。
-
自动化报告与洞察生成 (Automated Report and Insight Generation):LLM 不仅能执行查询,还能对查询结果进行理解、分析,并自动生成易于理解的文本摘要、关键洞察和结构化报告。
-
对话式分析与商业智能 (Conversational Analytics and BI):LLM 正在推动数据分析从静态报表和仪表盘向动态的、交互式的对话体验演进。用户可以通过多轮对话与 LLM 进行数据探索:
-
融合结构化与非结构化数据洞察 (Integrating Structured and Unstructured Data Insights):LLM 能够处理和理解非结构化文本数据(如客户评论、社交媒体帖子、销售代表的通话记录等),并从中提取有价值的信息和情感倾向。当这些从非结构化数据中获得的洞察与来自数据库的结构化数据(如销售额、客户人口统计信息)相结合时,企业可以获得对业务状况、市场趋势和客户行为更为全面和立
结语
大语言模型(LLM)与数据库的融合,不仅仅是对现有数据管理技术的简单增强或功能叠加,它更预示着一场深刻的范式革命——我们正在迈向一个以 AI 为核心驱动力的“AI 原生”数据管理新时代。在这个新时代,数据库系统本身将变得更加智能、主动和富有洞察力。
参考资料
In-Context Adaptation to Concept Drift for Learned Database Operations, https://arxiv.org/html/2505.04404v1
SurveyX-Automated Survey Generation, http://www.surveyx.cn/assets/img/pdfs/Database/auto.pdf
Thinking with Knowledge Graphs: Enhancing LLM Reasoning Through Structured Data, https://arxiv.org/html/2412.10654v1
Why your databases could be the AI advantage you’re missing, https://cloud.google.com/transform/why-databases-could-be-the-ai-advantage-youre-missing-gen-ai
Can Large Language Models Be Query Optimizer for Relational Databases?,https://arxiv.org/html/2502.05562v1
LLMIdxAdvis: Resource-Efficient Index Advisor Utilizing Large Language Model, https://arxiv.org/html/2503.07884v1
Exploring LLM Agents for Cleaning Tabular Machine Learning Datasets, https://arxiv.org/abs/2503.06664
The Effectiveness of Large Language Models in Transforming Unstructured Text to Standardized Formats, https://arxiv.org/html/2503.02650v2
The STROT Framework: Structured Prompting and Feedback-Guided Reasoning with LLMs for Data Interpretation, https://arxiv.org/html/2505.01636v1
Text Data Augmentation for Large Language Models: A Comprehensive Survey of Methods, Challenges, and Opportunities, https://arxiv.org/html/2501.18845v1
Large language models generating synthetic clinical …, https://www.frontiersin.org/journals/artificial-intelligence/articles/10.3389/frai.2025.1533508/full

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 24
24 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)