用一个简单的例子解释RAG的核心实现——本地的 ChromaDB 是如何配合千问(Qwen)生成测试用例的
摘要:本文介绍了一种结合本地ChromaDB和千问(Qwen)模型的RAG(检索增强生成)技术方案,用于精准生成测试用例。该系统分为知识准备和用例生成两个阶段:首先将项目文档分割、向量化后存入ChromaDB;当用户提出需求时,系统先检索相关文档片段,再结合千问模型生成符合业务规则的测试用例。该方法有效解决了大模型的"幻觉"问题,确保测试用例基于最新业务逻辑。文中还提供了核心实
·
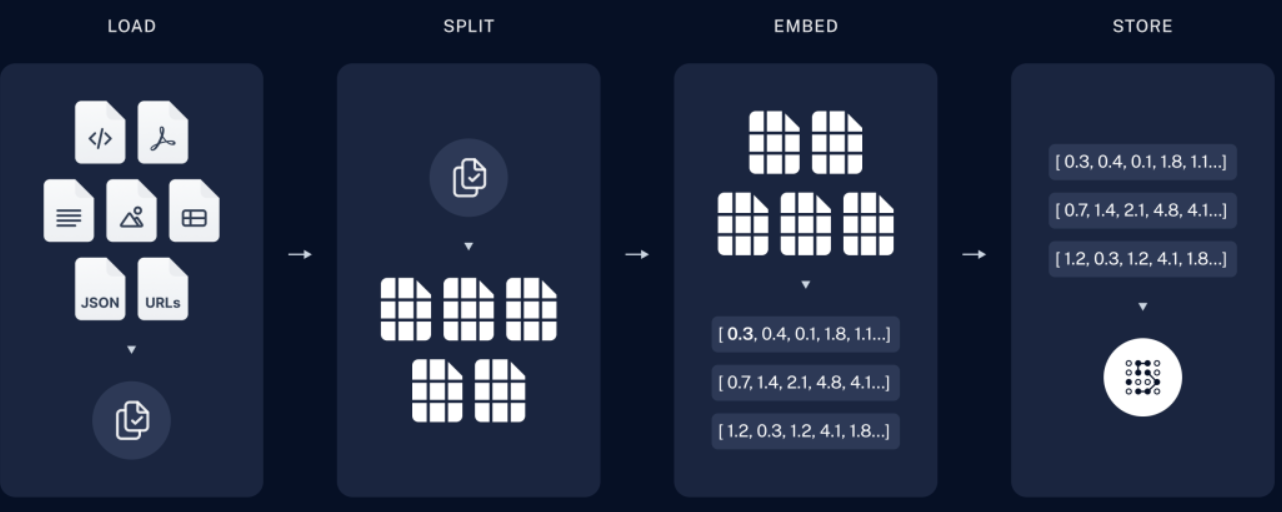
本地的 ChromaDB 配合千问(Qwen)模型生成测试用例,其核心技术逻辑依然是 RAG(检索增强生成)。简单来说,这个过程就像是给一个博学但不了解你公司细节的实习生(千问模型),配了一本实时更新的项目百科全书(ChromaDB)。当你要生成测试用例时,系统会先让 ChromaDB 从“百科全书”里找出和当前需求最相关的几页,然后把这几页内容连同你的指令一起交给千问模型,让它据此写出精准的测试用例。以下是这套系统运作的具体技术流程说明:
第一阶段:知识准备(建立“百科全书”)
在生成用例之前,你需要先让 ChromaDB “读”完你们项目的资料。这一步通常只需要做一次,或者在需求变更时更新。
- 数据收集:收集与测试相关的资料,例如:
- PRD 文档(产品需求文档)
- API 接口文档(Swagger/Postman JSON 或 Markdown)
- 历史测试用例库
- 数据库设计文档(ER 图或 Schema)
- 文本分割(Splitting):将这些长文档切分成一个个小的文本块(Chunks)。比如把一个 10 页的 PRD 切成 50 个段落。
- 向量化(Embedding):
- 调用一个嵌入模型(Embedding Model,千问通常配套使用
text-embedding-v1或开源的BGE等),将每个文本块转换成一串长长的数字(向量)。 - 这串数字代表了这段文字的“语义”。
- 调用一个嵌入模型(Embedding Model,千问通常配套使用
- 存入 ChromaDB:将这些“文本块 + 向量”存入本地的 ChromaDB 数据库中。此时,数据库就建立好了索引,随时准备被检索。
第二阶段:生成测试用例(“查资料 + 写作业”)
当你输入一个新的需求(例如:“为用户登录接口生成测试用例”)时,系统开始运作:
1. 检索(Retrieval)—— “去书里找答案”
- 用户输入:你输入需求:“用户登录需要校验手机号格式和密码长度”。
- 向量化查询:系统同样使用嵌入模型,将你的这句需求转换成向量。
- 相似度搜索:ChromaDB 接收到这个向量后,会在数据库中进行“扫库”,计算你输入的需求与数据库中所有文本块的“语义距离”。
- 返回上下文:找出最相关的 3-5 个文本块。例如:
- 文本块 A:“手机号必须是 11 位,且以 1 开头。”
- 文本块 B:“密码长度限制为 6-20 位。”
- 文本块 C:“错误尝试 5 次后锁定账户。”
2. 增强(Augmentation)—— “把资料摊在桌上”
- 系统将刚才检索到的“相关文本块”(A、B、C)和你的原始指令拼接在一起,形成一个新的、信息量巨大的“超级提示词(Prompt)”。
3. 生成(Generation)—— “千问写用例”
- 调用千问模型:将上面拼接好的“超级提示词”发送给千问大模型(可能是本地部署的 Qwen-7B/14B,也可能是云端的 API)。
- 模型推理:千问模型读取了这些具体的业务规则(上下文),结合它自身学到的通用测试方法论(如等价类划分、边界值分析),开始推理。
- 输出结果:生成结构化的测试用例。
具体效果对比示例
如果没有 ChromaDB(纯千问模型):
- 输入:“生成登录测试用例”
- 输出:千问会根据它训练数据里的通用登录逻辑生成用例。它可能会猜手机号是 11 位,但也可能猜错,或者不知道你们特有的“锁定规则”。这叫“幻觉”风险。
有 ChromaDB(RAG 模式):
- 输入:“生成登录测试用例”,同时 ChromaDB 检索出:“手机号 11 位”、“密码 6-20 位”、“5 次锁定”。
- 输出:千问生成的用例会严格遵守这些规则。
- 用例1:输入 10 位手机号,预期结果:提示格式错误。
- 用例2:连续输错 5 次密码,预期结果:账户锁定。
技术实现的关键代码逻辑(伪代码)
如果你是在开发这个工具,核心逻辑如下:
import chromadb
from openai import OpenAI # 这里可以是千问的兼容接口
# 1. 初始化 ChromaDB 客户端
client = chromadb.PersistentClient(path="/path/to/your/test_knowledge_db")
collection = client.get_collection("prd_documents")
# 2. 用户输入的需求
user_requirement = "请为用户注册接口生成测试用例,要求包含边界值和异常场景。"
# 3. 在 ChromaDB 中检索相关文档
results = collection.query(
query_texts=[user_requirement],
n_results=5 # 检索最相关的5个片段
)
# 提取出检索到的文本
retrieved_docs = "\n".join(results['documents'])
# 4. 构建给千问模型的 Prompt
final_prompt = f"""
你是一名资深测试工程师。请根据以下【参考知识】和【测试需求】生成测试用例。
【参考知识】(来自 ChromaDB):
{retrieved_docs}
【测试需求】:
{user_requirement}
【要求】:
- 覆盖正常流、异常流、边界值。
- 输出格式为 Markdown 表格。
"""
# 5. 调用千问模型
qwen_client = OpenAI(
api_key="your_qwen_api_key",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1" # 千问兼容OpenAI的接口
)
response = qwen_client.chat.completions.create(
model="qwen-plus", # 或者你本地部署的 qwen-7b-chat
messages=[{"role": "user", "content": final_prompt}]
)
# 6. 输出生成的测试用例
print(response.choices.message.content)总结
ChromaDB 的作用是解决千问模型的“知识滞后”和“知识不匹配”问题。它确保了模型生成的测试用例是基于你们最新的、私有的业务逻辑,而不是凭空想象的。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献42条内容
已为社区贡献42条内容

所有评论(0)