RAG 深度实践系列(三):RAG 技术演变与核心架构的深度剖析
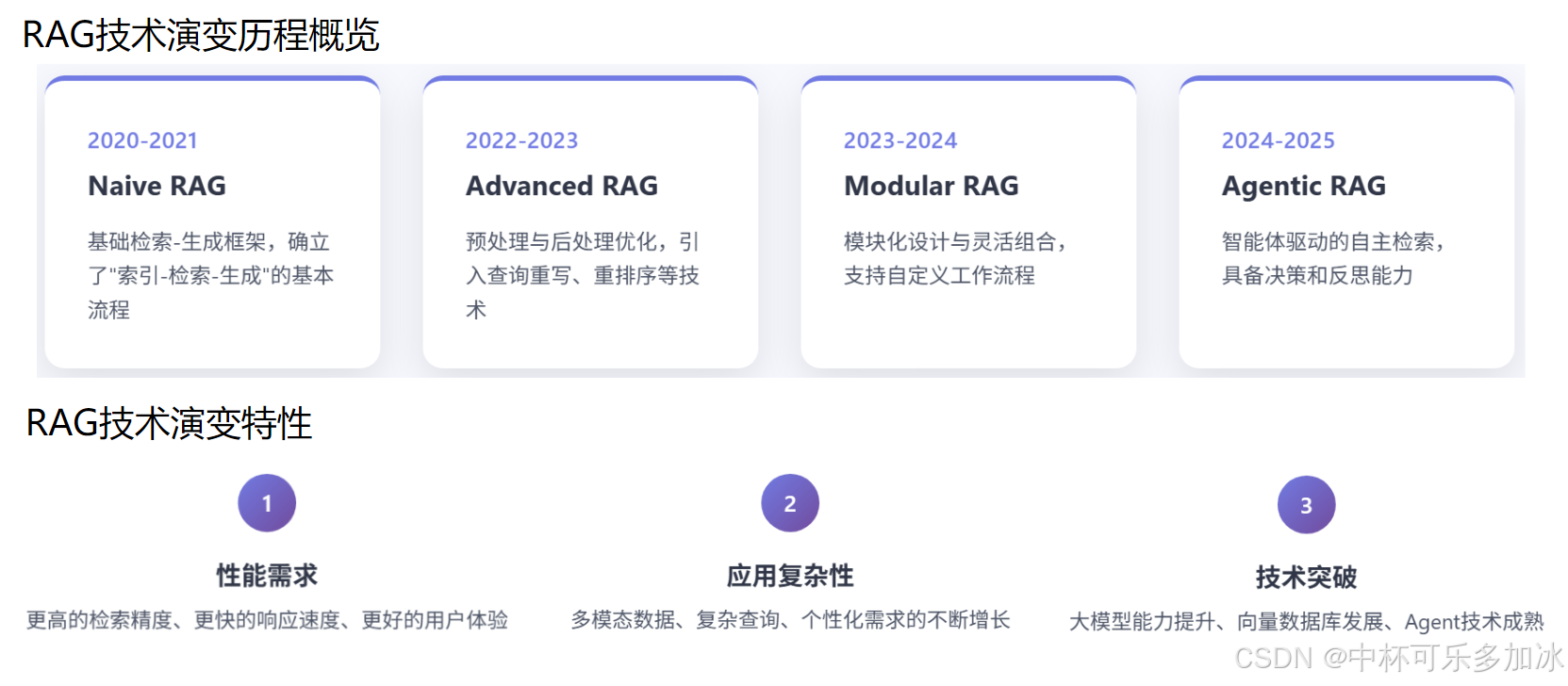
RAG技术经历了从基础检索到智能决策的演进过程:Naive RAG确立基本范式但存在语义破坏和单一检索局限;Advanced RAG通过查询优化、混合检索和重排序等精细化手段提升性能;Modular RAG实现模块化架构,GraphRAG引入知识图谱增强逻辑推理;最终Agentic RAG结合智能体技术,具备自主决策、任务规划和自我反思能力。这一演进体现了RAG系统从被动知识搬运到主动智能决策的转
一、 RAG 范式演进:从知识搬运工到智能决策者
检索增强生成(RAG)技术的发展史,是一部不断挑战大型语言模型(LLM)局限性、追求系统级智能的演进史。RAG 的演变并非简单的功能叠加,而是对“如何高效、可靠地将外部知识融入 LLM 推理过程”这一核心问题的持续探索。我们可以将 RAG 的演进脉络划分为四个清晰的阶段:Naive RAG 确立基本范式,Advanced RAG 聚焦精细化优化,Modular RAG 追求架构灵活性,最终 Agentic RAG 实现自主决策与智能化。
在 RAG 的实践中,许多开发者在面对复杂场景时,常因缺乏对架构演进逻辑的深刻理解而陷入困境:如何将知识图谱(GraphRAG)融入向量检索?如何设计一个具备自我反思能力的 Agentic RAG 系统?如何平衡实时性与准确性?
为了帮你填补从懂原理到能落地的关键拼图,AI大学堂基于大量的业务实战经验,精心打磨课程,正式推出 RAG工程师认证。这份证书将是你系统化掌握 AI 落地核心能力的绝佳机会,认证现已开启,限时免费,点击文末🔗认证链接开始学习!
1.1、 Naive RAG:范式的确立与固有局限
Naive RAG(朴素 RAG)是 RAG 技术的起点,其核心思想是“索引-检索-生成”的线性流程。它解决了 LLM 在特定领域知识上的“无知”问题,通过将文档分块、向量化,并使用单一的向量相似度检索来召回上下文。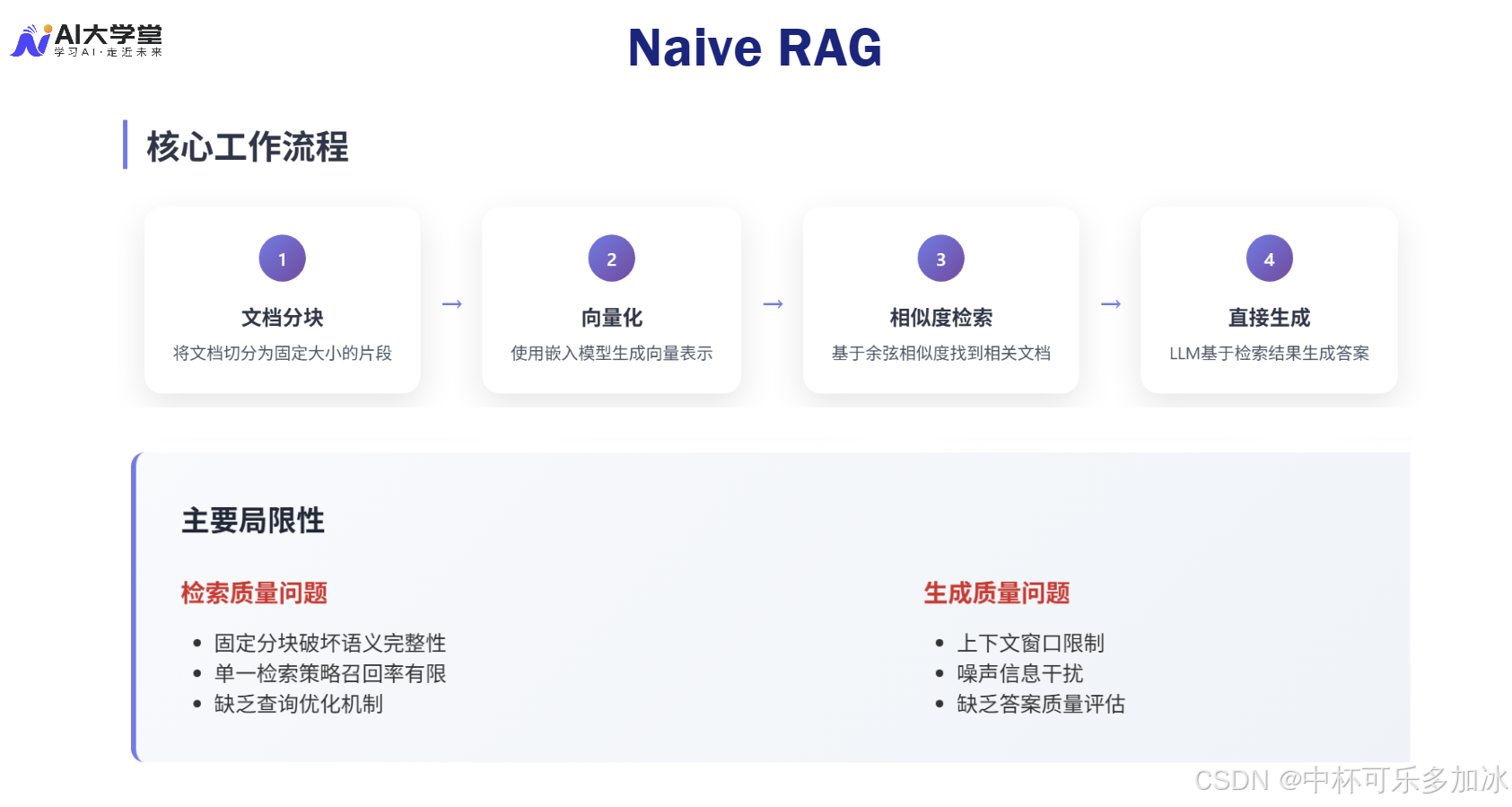
然而,Naive RAG 的局限性是显而易见的,也是驱动后续演进的根本原因:
- 分块的语义破坏:固定大小的分块策略极易在语义边界处截断,导致单个块的语义信息不完整或被稀释,直接影响嵌入模型的编码质量。
- 单一检索的盲区:仅依赖向量相似度检索,无法有效处理词汇不匹配(Lexical Gap)问题,对同义词、专业术语或需要精确关键词匹配的查询,召回率低下。
- 缺乏查询优化:用户查询的模糊性、歧义性未被处理,直接影响了检索信号的质量。
Naive RAG 就像一个被动的“知识搬运工”,它只能机械地执行预设的流程,缺乏对信息质量的判断和对查询意图的深度理解。
1.2、 Advanced RAG:精细化优化与多阶段精炼
Advanced RAG(高级 RAG)是 RAG 走向工业级应用的关键一步,其核心在于在 Naive RAG 的基础上,引入了大量的预检索和后检索优化机制,将流程从线性转变为多阶段精炼。
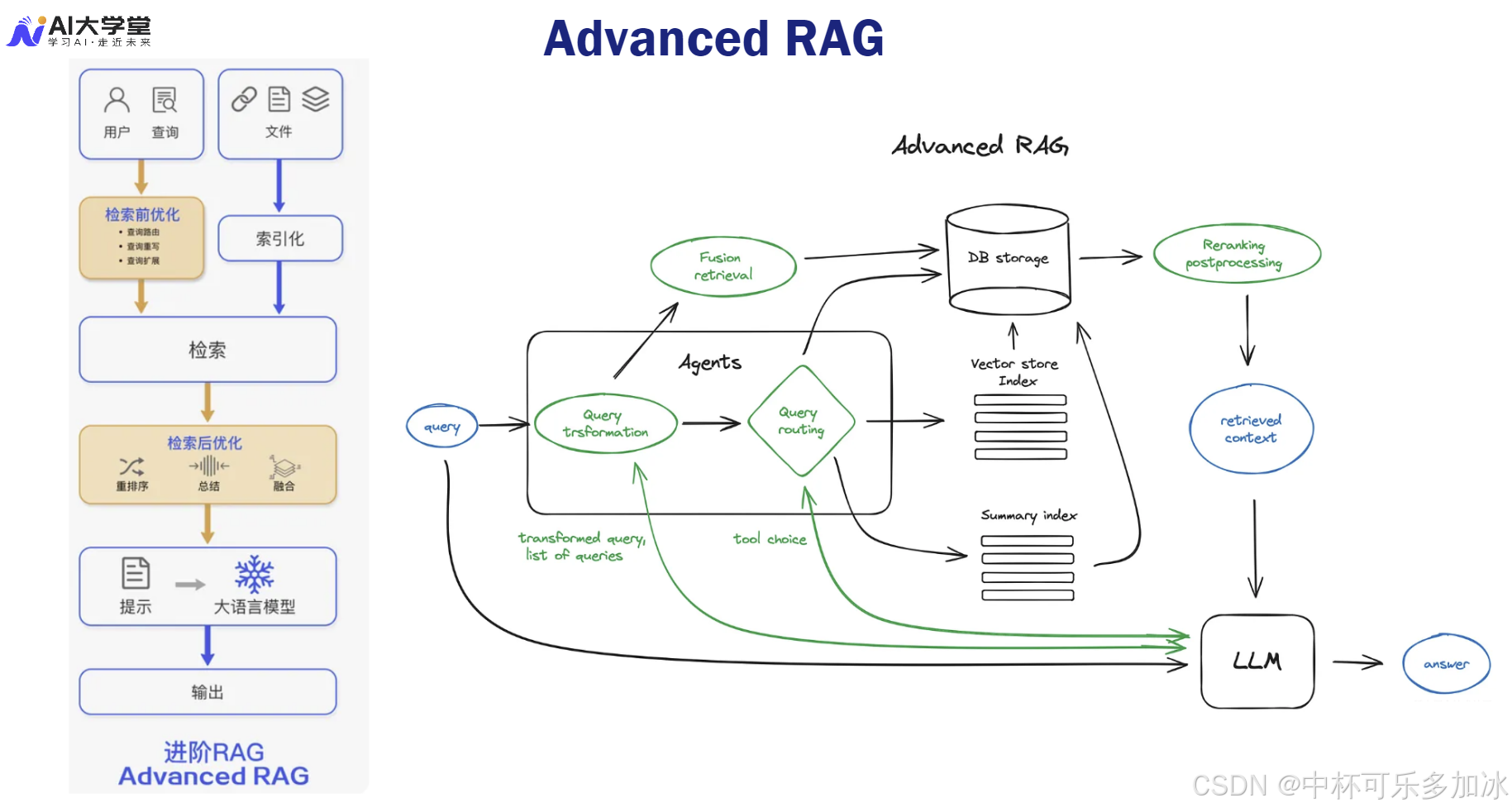
1.2.1、 预检索优化:增强查询信号的艺术
预检索优化的目标是生成更强大的检索信号,以克服用户查询的局限性:
- 查询重写与扩展:利用 LLM 将原始查询改写成更清晰、更具体的版本,或生成多个变体查询以增加检索覆盖面。
- 假设性文档嵌入(HyDE):这是最具创新性的技术之一。它利用 LLM 的生成能力,根据查询生成一个“假设性答案”,然后用这个假设性答案的向量去检索真实文档。由于假设性答案包含了更丰富的语义和更接近文档的词汇,它能显著提高检索的准确性,尤其是在处理抽象概念时。
- 多查询生成:利用 LLM 生成多个子查询,并行执行检索,然后合并结果,以应对复杂查询和多角度信息需求。
1.2.2、 检索与后处理优化:从召回到准确率的飞跃
Advanced RAG 在检索和后处理环节的优化,是其性能飞跃的关键:
- 混合检索(Hybrid Retrieval):将基于关键词的稀疏检索(如 BM25)与基于语义的稠密检索(向量检索)进行融合。这种融合的数学逻辑在于,通过 RRF(Reciprocal Rank Fusion) 等算法,将两种不同相关性度量(词频-逆文档频率与向量余弦相似度)的结果进行加权排序,实现优势互补,最大化召回率和准确率。
- 语义分块策略:取代固定分块,采用基于句子、段落或标题的语义分块,确保每个块的语义完整性。更进一步的策略是父文档检索,即用小块进行检索,但返回包含该小块的更大“父文档”作为 LLM 的上下文,以平衡检索精度和上下文丰富度。
- Cross-Encoder 重排序:这是提升准确率(Precision)的利器。与 Bi-Encoder 独立编码查询和文档不同,Cross-Encoder 将查询和文档拼接后一起输入模型,从而捕捉两者之间细粒度的交互信息。虽然计算成本高,但其对相关性的判断更为精确,通常用于对 Bi-Encoder 召回的 Top-K 结果进行二次精排。
- 上下文压缩与验证:通过 LLMLingua 等技术对检索结果进行压缩,减少 LLM 的输入 Token 数量,降低成本并提升效率。同时,引入额外的 LLM 或规则引擎对最终答案进行事实一致性验证,以降低幻觉风险。
二、 Modular RAG 与 GraphRAG:架构的灵活性与知识的结构化
Advanced RAG 解决了性能问题,但随着应用场景的复杂化,系统对灵活性和可扩展性提出了更高的要求,由此催生了 Modular RAG(模块化 RAG)。
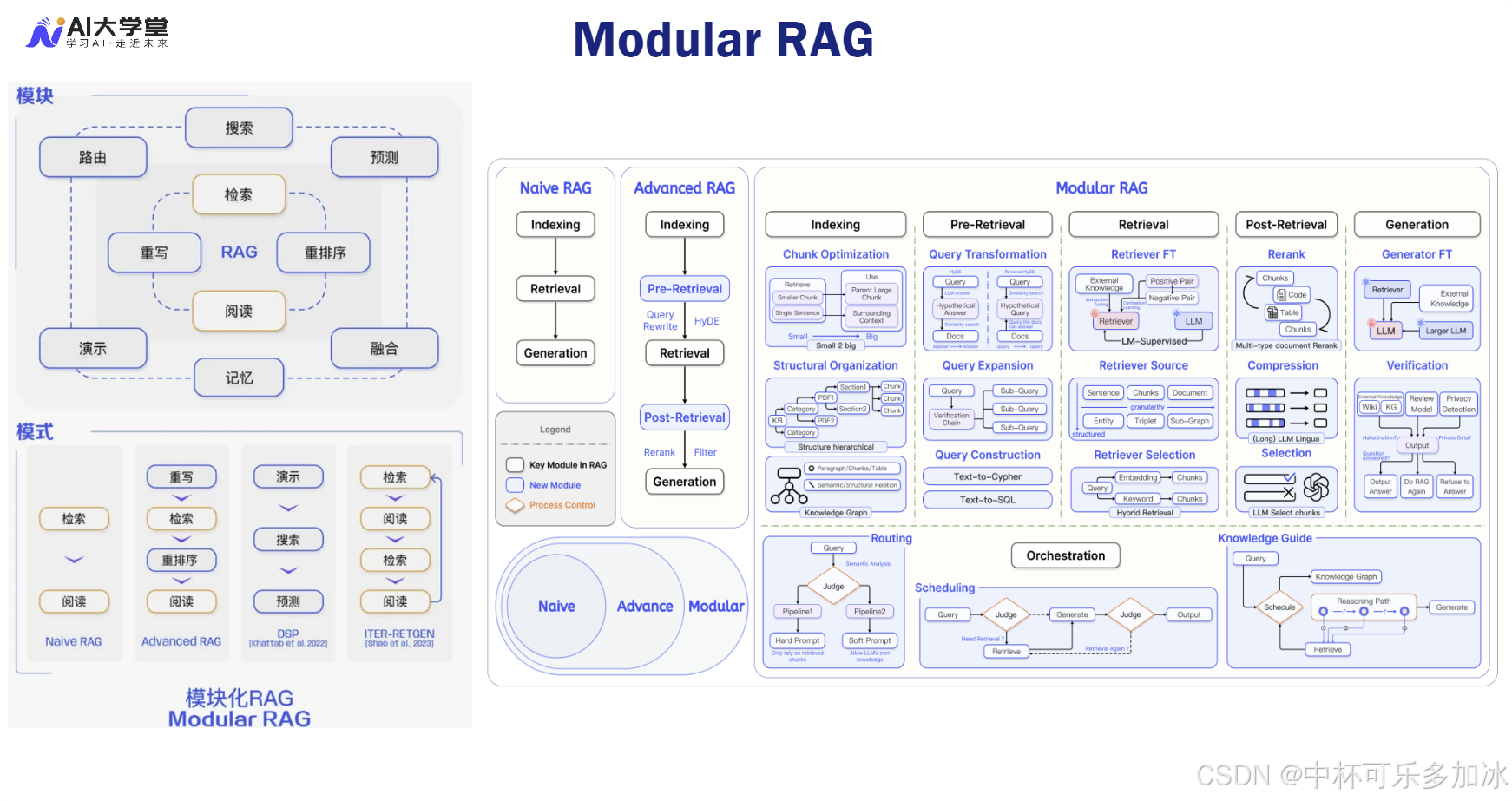
2.1、 Modular RAG:解耦与定制化的架构哲学
Modular RAG 的核心思想是解耦:将 RAG 流程中的各个功能(如查询重写、检索、重排序、验证)抽象为可插拔的独立模块。这种架构哲学使得 RAG 系统不再是一个固定的流水线,而是一个可以根据任务需求动态组装的“乐高积木”。
这种架构的优势在于:
- 定制化工作流:可以根据不同的业务场景(如法律问答、代码生成、财务分析)定制不同的模块组合和执行路径。
- 独立优化与迭代:每个模块可以独立进行技术选型和优化(例如,针对法律文档使用专门微调的嵌入模型,针对代码使用基于 AST 的分块器),互不影响。
- 支持复杂逻辑:通过模块的条件组合(根据查询类型选择不同检索器)和循环组合(实现多跳检索),能够处理 Advanced RAG 难以应对的复杂逻辑。
在 Modular RAG 的实践中,DSP(Differentiable Search Path,可微搜索路径) 等框架提供了理论基础,它将 RAG 流程视为一个可优化的计算图,允许通过端到端的方式对整个流程进行微调,从而实现系统级的性能提升。
2.2、 GraphRAG:从语义相似到逻辑推理的飞跃
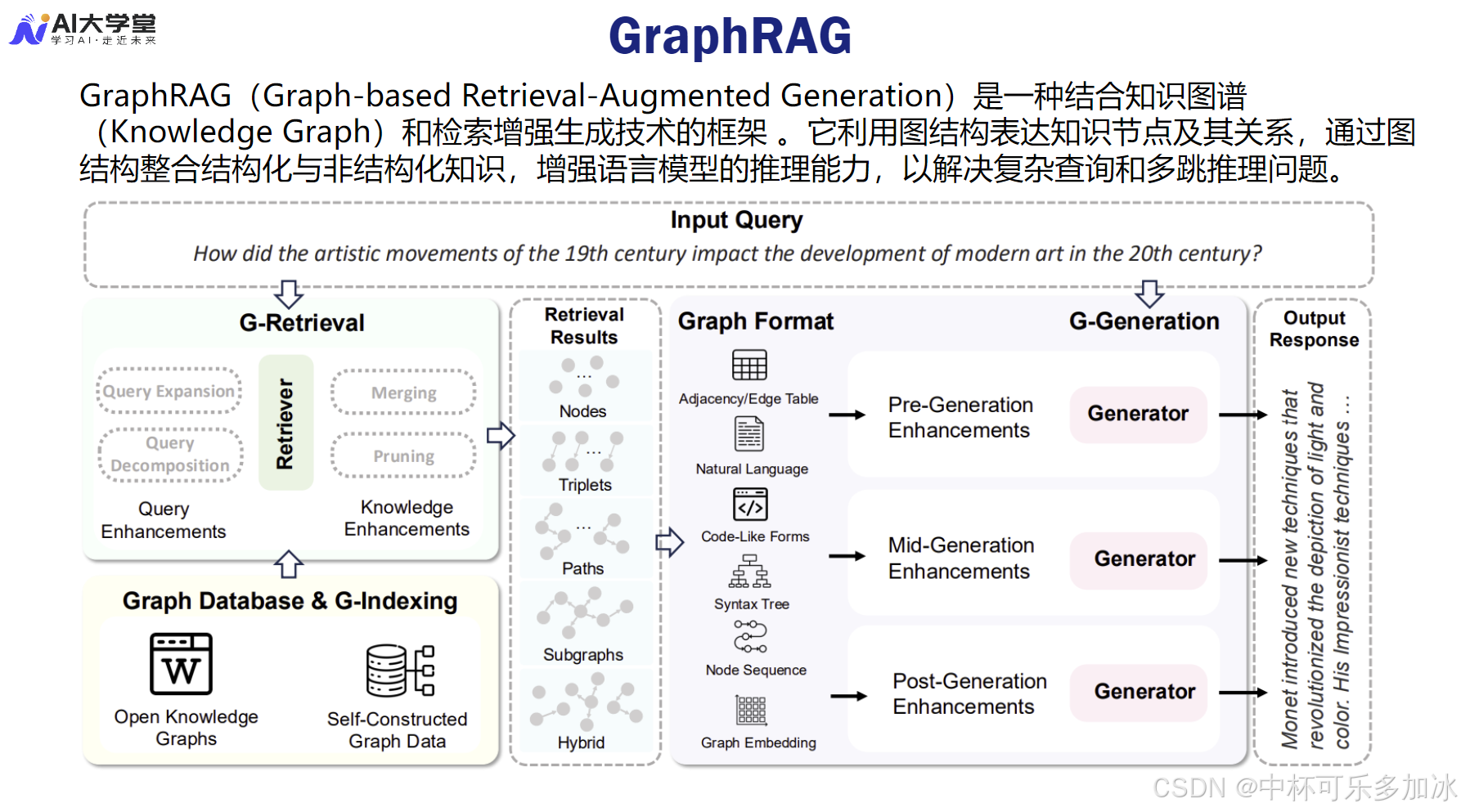
在 Modular RAG 的范畴内,GraphRAG(基于知识图谱的 RAG)是解决复杂推理问题的关键技术。它解决了传统向量检索的根本缺陷:缺乏逻辑关联和因果推理能力。
GraphRAG 的工作原理是将知识库中的实体和关系构建成一个知识图谱(KG)。检索过程不再仅仅是文本块的相似度匹配,而是:
- 实体与关系提取:利用 LLM 或 NLP 工具从查询和文档中提取关键实体和关系。
- 图谱路径搜索:在 KG 中搜索连接查询实体和目标实体的路径。
- 结构化上下文:将搜索到的图谱路径(即逻辑链条)作为结构化上下文提供给 LLM。
这种方式使得 LLM 能够进行更复杂的多跳推理(Multi-hop Reasoning)。例如,要回答“A 公司的创始人 B 投资了哪些 C 领域的公司?”这样的问题,GraphRAG 可以沿着“A 公司 -> 创始人 B -> 投资关系 -> C 领域公司”的路径进行精确搜索,并提供清晰的逻辑链条,极大地增强了答案的事实准确性和可解释性。GraphRAG 的引入,标志着 RAG 系统从“知识搬运工”正式进化为“逻辑推理者”。
三、 Agentic RAG:自主决策与自我反思的智能化巅峰
RAG 技术的最新前沿是 Agentic RAG(智能体 RAG),它代表了 RAG 系统从被动执行到主动智能的最终形态。Agentic RAG 将 AI 智能体(Agent)技术与 RAG 深度融合,赋予系统自主决策、工具使用、任务规划和自我反思的能力。
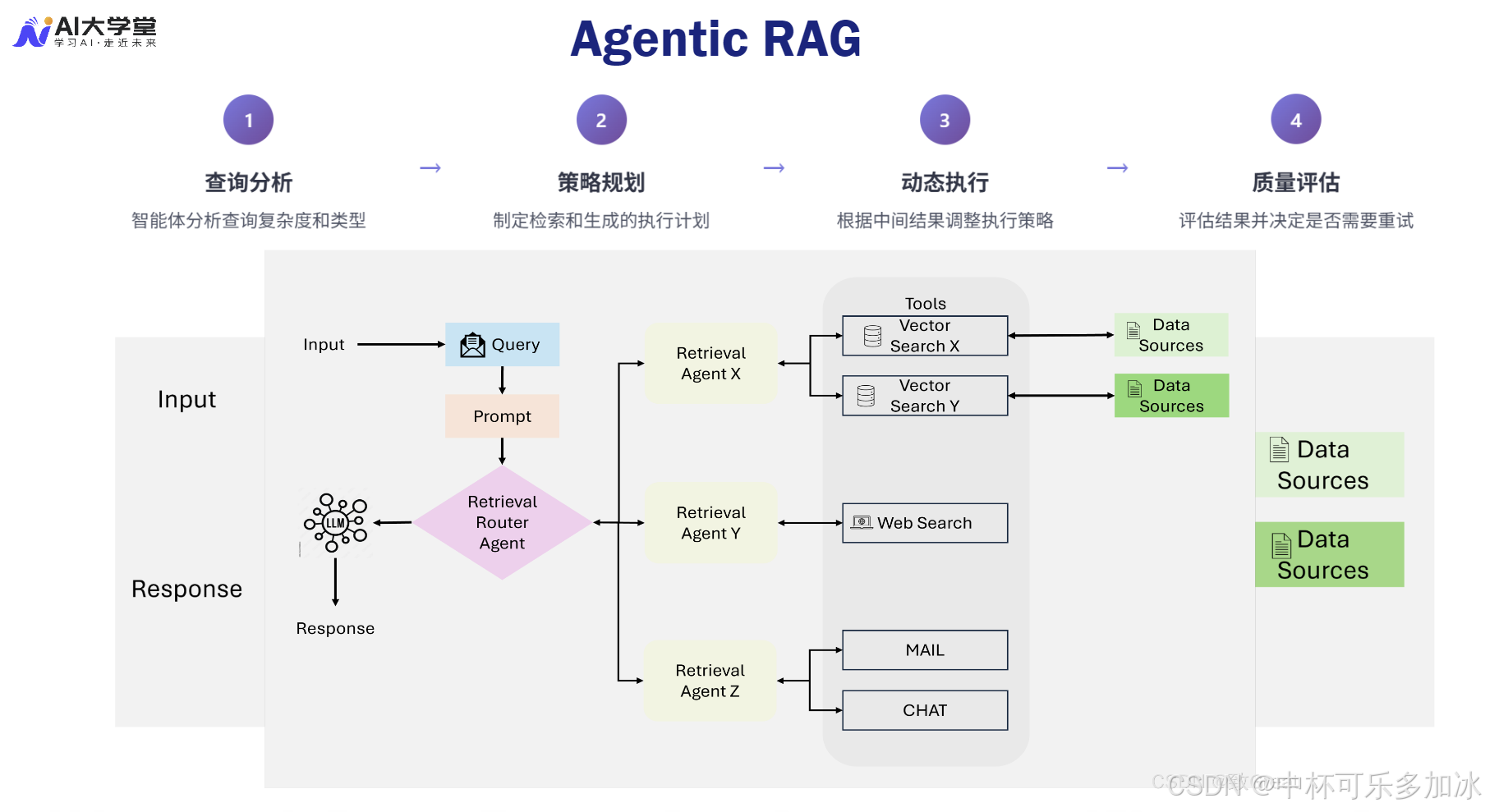
3.1、 Agentic RAG 的核心机制:ReAct 与反思
Agentic RAG 的核心在于其智能体框架,其中 ReAct(Reasoning and Acting) 框架是主流实现之一。ReAct 机制允许 LLM 在生成答案之前,进行推理(Reasoning) 和行动(Acting) 的交替循环:
- 推理(Reasoning):LLM 分析当前任务、已有的信息和下一步的目标,生成一个清晰的思考过程。
- 行动(Acting):LLM 根据推理结果,决定调用哪个工具(如向量检索器、搜索引擎、代码解释器或 GraphRAG 模块),并执行相应的操作。
这种机制使得 Agentic RAG 能够动态地规划复杂的任务。例如,在处理一个需要多步推理的法律查询时,Agent 会将问题分解为多个子任务,并动态选择工具:
- 步骤 1(推理):分析查询,判断需要检索法律条文和计算赔偿金。
- 步骤 1(行动):调用 GraphRAG 模块检索最新的法律条文。
- 步骤 2(推理):分析检索结果,确定计算公式,判断需要外部计算工具。
- 步骤 2(行动):调用 代码解释器或 API 工具执行赔偿金计算。
更高级的 Agentic RAG 引入了自我反思(Self-Reflection) 机制。在生成答案后,Agent 会利用另一个 LLM 或预设的评估指标(如 RAGAS 框架)对答案进行评估。如果评估结果不理想,Agent 会反思其推理过程和行动步骤,识别错误,并调整策略重新执行,形成一个完整的优化闭环。这种反思与优化能力,是 Agentic RAG 实现高度智能化和鲁棒性的重要保障。
3.2、 Agentic RAG 的应用与挑战
Agentic RAG 的应用场景集中在对复杂性、准确性和智能化程度要求极高的领域:
- 智能法律助手:处理需要多跳推理、多工具协同(法律数据库、计算工具)的复杂法律查询。
- 金融研究分析:自主规划数据检索、图表生成、趋势分析等一系列步骤,生成结构化的研究报告。
- 复杂系统故障诊断:Agent 根据故障描述,自主调用日志检索工具、代码库、知识图谱,逐步缩小故障范围并提出解决方案。
然而,Agentic RAG 也面临巨大的挑战:
- 成本与延迟:每一次推理和行动都需要 LLM 调用,导致成本和延迟显著增加。
- 工具调用稳定性:Agent 对外部工具的调用必须高度稳定和可靠,否则一次失败的行动可能导致整个流程崩溃。
- 可解释性:Agent 的决策过程虽然有 ReAct 的推理记录,但其复杂性使得最终的可解释性仍然是一个难题。
四、 RAG 系统的未来趋势:多模态、实时化与可信 AI
RAG 技术的演进仍在加速,未来的发展将聚焦于突破现有架构的边界,使其能够更好地适应真实世界的复杂性和动态性。

4.1、 多模态 RAG:重构语义空间
当前 RAG 主要处理文本,但现实世界是多模态的。多模态 RAG 的目标是将文本、图像、音频、视频等不同模态的数据融入统一的 RAG 框架。这要求构建统一的多模态表示模型,将不同模态的信息映射到同一个语义空间中,实现跨模态的检索、理解和生成。例如,用户可以上传一张设备故障的图片和一段描述,系统能够从包含技术手册(文本)、维修视频(视频)的知识库中检索信息,并生成包含文本和图片标注的维修指南。
4.2、 实时 RAG 与增量索引:拥抱时效性
在金融、新闻、实时监控等领域,信息的时效性至关重要。未来的 RAG 系统必须是实时 RAG,能够处理流式数据并进行增量索引更新。传统的 RAG 知识库是静态的,更新成本高昂。实时 RAG 需要采用先进的流处理技术和向量数据库的增量索引能力,确保 LLM 始终能够访问到最新、最准确的知识,从而避免生成过时或错误的信息。
4.3、 可信 RAG 与评估体系的深化
随着 RAG 在关键领域的应用,可信 AI 成为核心要求。未来的 RAG 系统将更加注重:
- 可解释性:不仅提供答案,还要提供清晰的引用来源和 推理路径(尤其是 Agentic RAG 和 GraphRAG)。
- 鲁棒性:能够抵御对抗性攻击和知识库中的恶意注入。
- 评估体系深化:除了传统的召回率和准确率,RAGAS 等评估框架将更加普及,利用 LLM 自身的能力来量化答案的忠实度(Faithfulness) 和上下文相关性(Context Relevance),实现数据驱动的持续优化。
RAG 的演进是一个从“能用”到“好用”,再到“智能”的螺旋式上升过程。它清晰地展示了 AI 系统如何通过架构创新,将 LLM 的生成能力与外部知识的可靠性完美结合,从而构建出更强大、更可靠的下一代智能应用。
🚀 进阶之路:从架构演进到工程落地
本文深入剖析了 RAG 的技术演变与核心架构,但从原理到工程化落地,仍有许多实战细节需要掌握。例如,如何高效部署 RAGFlow、如何使用 RAGAS 进行量化评估,以及如何针对特定行业进行优化。
为了帮助您系统化地掌握这些核心能力,AI大学堂基于一线实战案例,精心打磨了 RAG工程师认证 课程。这份认证覆盖了从基础概念、核心组件、高级优化到工程化实战的全链路知识体系,旨在助您打破理论与落地的壁垒,将知识真正内化为职场竞争力。
课程体系层层递进,直击落地痛点:
| 课程模块 | 核心实战价值 |
|---|---|
| 技术演变与核心架构 | 深度解析从基础流水线到 GraphRAG 及 Agentic RAG 的演进脉络,助你把握前沿架构趋势。 |
| 从零搭建 RAG 系统 | 实战代码开发,从 0 到 1 实现文档处理、检索与生成模块,打破技术黑盒。 |
| RAGFlow 部署与使用 | 生产环境必修课,手把手教学环境搭建与组件集成,实现高效任务流转。 |
| 优化与效果评估 | 引入 RAGAS 等评估框架,利用数据量化表现,精准提升系统质量。 |
限时免费认证现已开启,立即点击下方链接,开启您的 RAG 进阶学习之旅:
🔗 认证链接:
https://www.aidaxue.com/course/1190?video_id=5212&ch=ai_daxue_csdn

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)