人工智能基础知识笔记三十五:几个LLM的Leaderboard的网站
本文主要介绍了LLM的6个Leaderboard,可以通过这些Leaderboard全访问了解每个模型的优势和劣势,以及性价比。可以在选择模型时,根据使用大模型的目的,有针对性地提前了解每个模型的特点。
LLM(大语言模型)的 Leaderboard 是评估和比较不同大语言模型性能的公开排行榜。它的核心目的是 为社区提供一个客观、可比较的基准,以衡量模型的综合能力,从而推动整个领域的透明化、标准化和健康发展。
其主要作用可以分解为以下几个关键方面:
1、核心目的
-
建立标准化评估基准:在模型能力多样且发展迅速的情况下,Leaderboard 通过一套固定的任务和数据集,为所有模型提供了一个“统一考场”,使得横向对比成为可能。
-
促进透明与开源:尤其是对于开源模型,Leaderboard 是展示其能力、挑战闭源模型(如GPT-4、Claude)的重要窗口。它鼓励研究机构和企业公开模型并接受社区检验。
-
驱动技术进步:排行榜会形成一种健康的竞争环境,激励各团队针对评估指标优化模型架构、训练方法和数据工程,从而推动技术边界不断前移。
-
指导研究与资源分配:让研究者和机构了解当前的技术前沿和不同技术路线的优劣,从而明智地决定研究方向与资源投入。
2、主要作用
-
为用户和开发者提供选型参考:
-
技术选型:开发者可以根据榜单分数,快速筛选出在特定任务(如代码生成、数学推理、多语言理解)上表现优异的模型,节省评估成本。
-
成本效益分析:许多榜单会同时考虑模型性能和参数规模/计算成本,帮助用户在“大而强”的模型和“小而精”的模型之间做出权衡。
-
-
评估模型的综合能力:
-
主流Leaderboard(如 Open LLM Leaderboard, Chatbot Arena)通常覆盖多个维度的能力测试:
-
学术/推理能力:使用MMLU(多学科选择题)、GSM8K(数学)、HumanEval(代码)等基准测试。
-
知识理解:使用TruthfulQA(真实性)、BBH(复杂推理)等。
-
综合对话与实用性:通过人类或AI裁判进行众包盲测(如Chatbot Arena的Elo排名),评估模型在开放对话中的实际体验。
-
-
-
揭示模型的优缺点与偏见:
-
通过细分任务的得分,可以清晰地看出一个模型是“通才”还是“专才”。例如,某个模型可能在数学上很强,但在法律知识上表现平平。这有助于用户根据自身场景选用。
-
3、典型的LLM Leaderboard
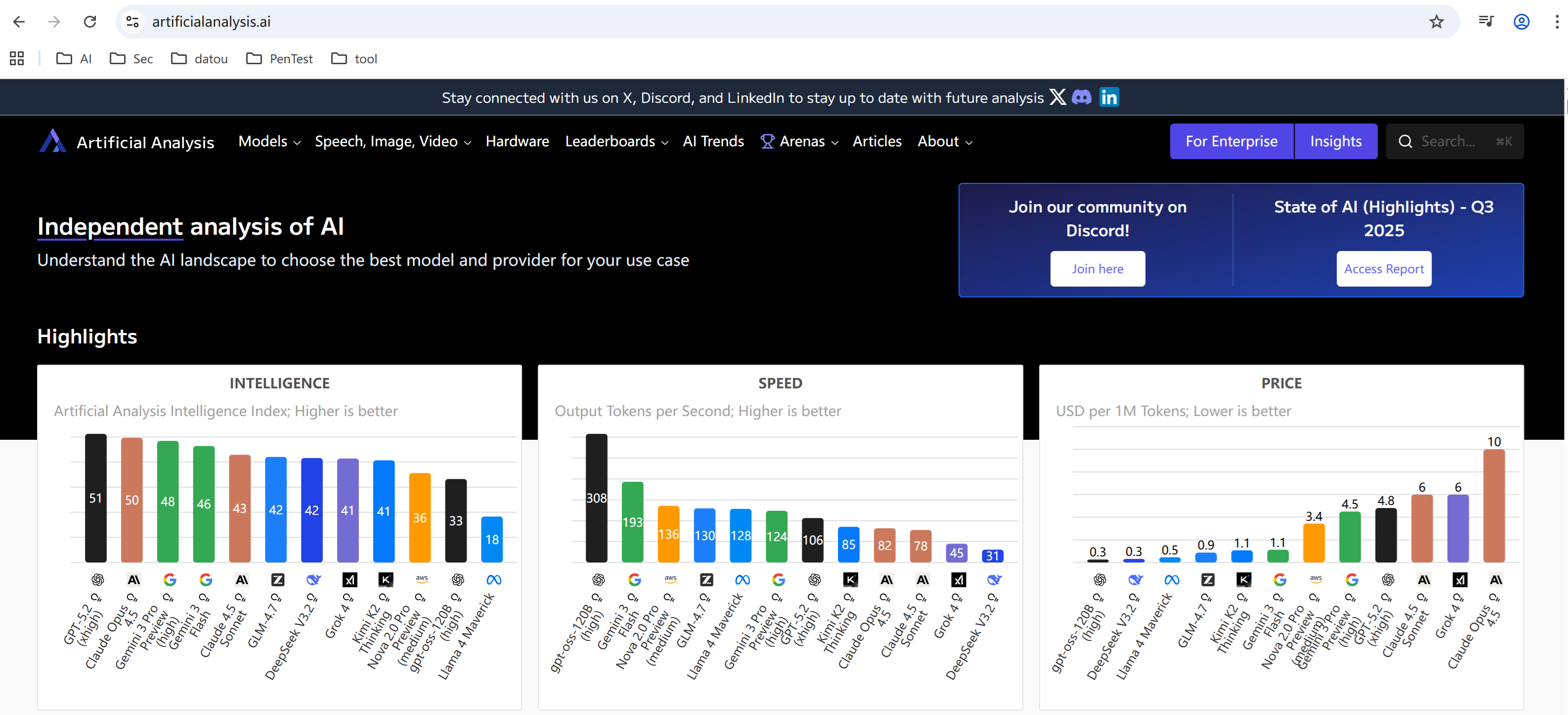
3.1 https://artificialanalysis.ai/
三维度综合性价比评估: 独树一帜地从“智能、速度、价格”三个维度进行量化评分和可视化对比,并提供个性化推荐工具,是进行生产选型和成本权衡的实用指南。
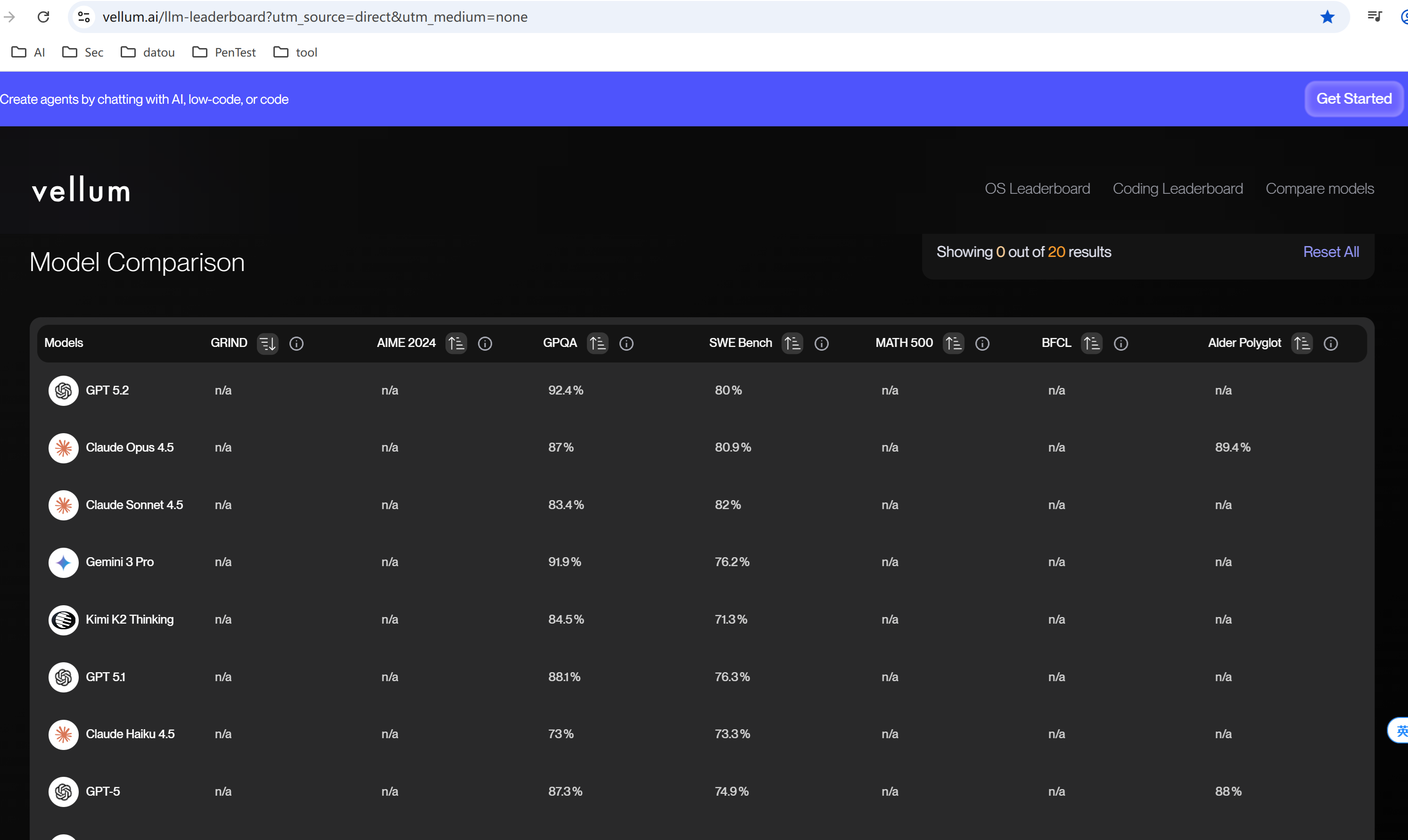
3.2 https://www.vellum.ai/llm-leaderboard?utm_source=direct&utm_medium=none
真实生产任务性能评估: 侧重于评估模型在贴近真实业务场景的复杂任务(如指令遵循、结构化输出、创意写作)上的表现,对应用开发者有直接参考价值。
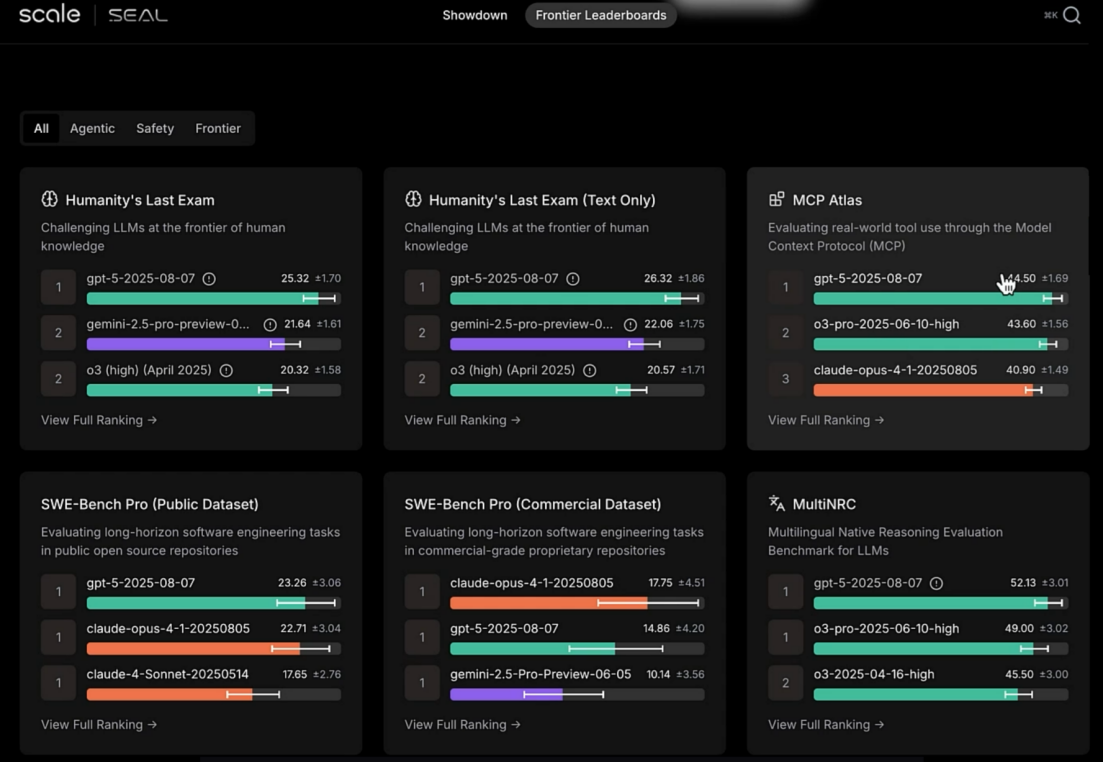
3.3 https://scale.com/leaderboard
企业级能力与安全性评估: 评测维度通常超越纯性能,更关注事实准确性、安全性、有害内容规避、可控性等企业级应用关心的关键指标。
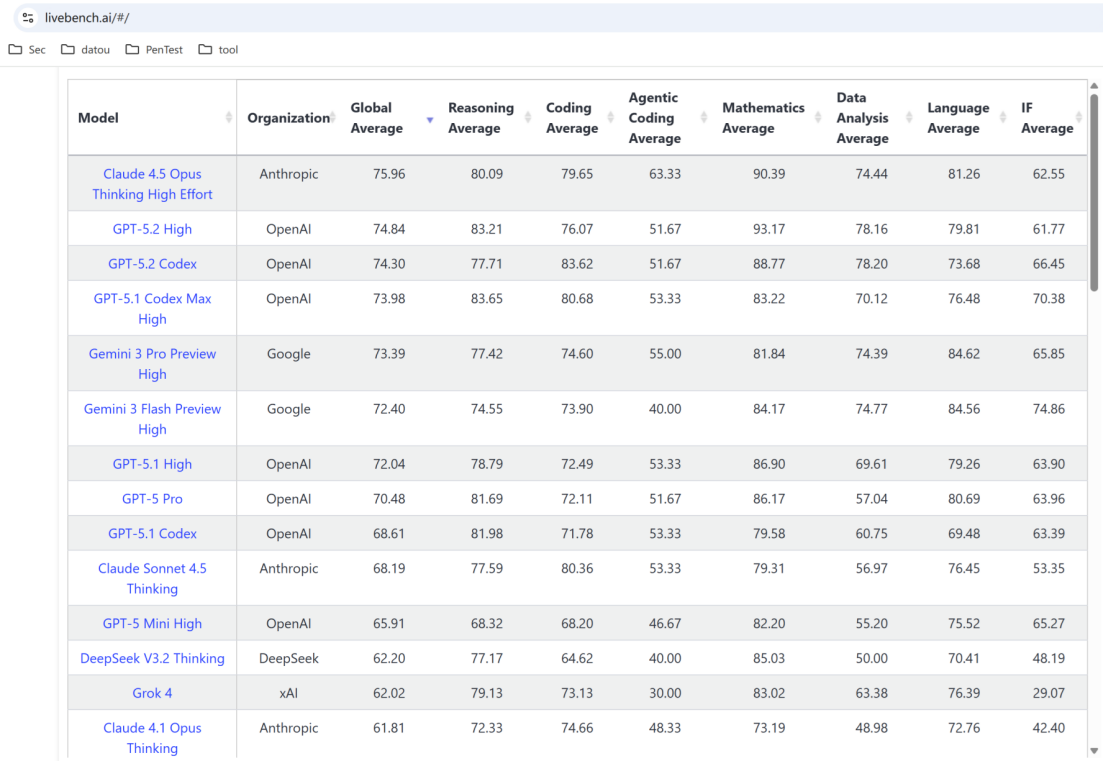
3.4 https://livebench.ai/#/
动态、防作弊的持续评估: 其评测数据集持续更新且未公开,旨在防止模型“刷榜”,更能考验模型的泛化能力和应对未知新任务的真实水平。
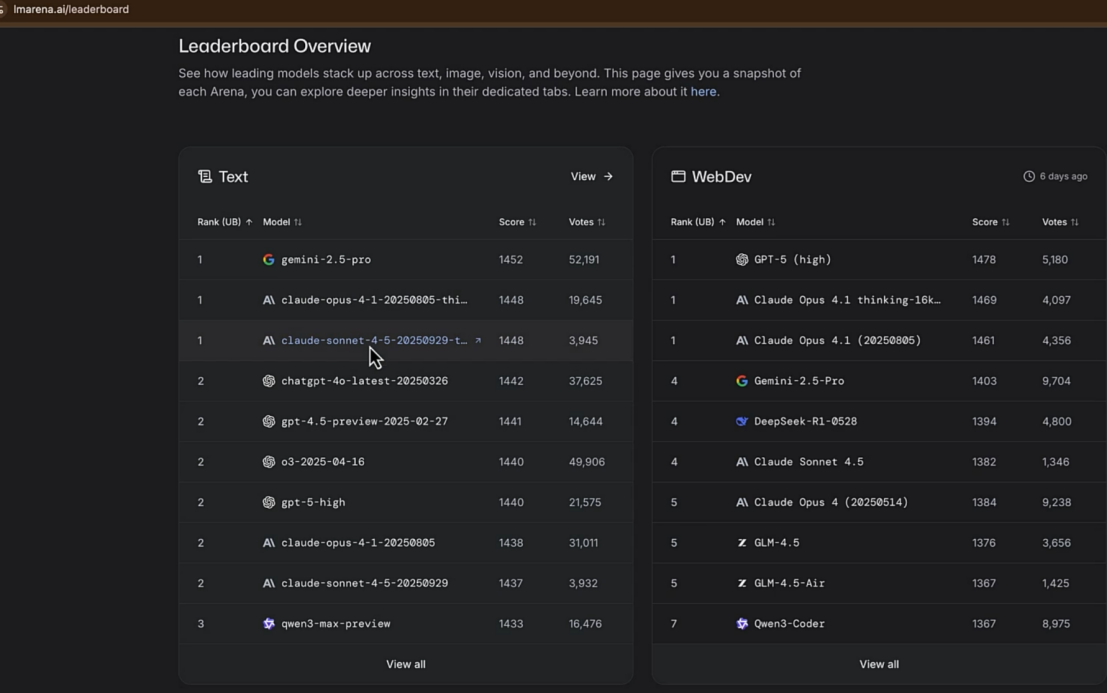
3.5 https://lmarena.ai/leaderboard
基于人类偏好的盲测排名: 完全通过全球用户对匿名模型的对话进行投票,用“Elo评分”机制生成排名,最直接地反映普通用户的主观体验和偏好。
3.6 https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard
开源模型的标准化基准测试: 专注于开源模型,在多个经典学术基准(如MMLU, GSM8K)上运行标准化、可复现的测试,是开源社区的核心参考。
不过,根据https://huggingface.co/blog/open-llm-leaderboard-future,目前huggingface的Leaderboard暂停进行更新,进行了重构升级,未来的重构方向:他们计划建立一个 “更全面、更健壮、更难以被游戏化” 的新一代评估平台。何时能够重启更新,时间尚未可知。
4 如何根据你的目标选择榜单?💡
-
为商业应用选型:应综合参考 Artificial Analysis(性价比)、Vellum(任务表现)和 Scale(安全合规)。
-
追踪模型前沿能力:LiveBench 能有效反映模型的泛化和推理潜力。
-
选择开源模型:Hugging Face Open LLM Leaderboard 是首选,可辅以 Chatbot Arena 了解对话体验。
-
关注大众用户体验:直接查看 LMSYS Chatbot Arena 的Elo排名和用户投票详情。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 15
15 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)