具身智能大模型---香港大学之UniVLA
UniVLA提出了一种创新的跨具身视觉-语言-动作通用策略学习框架,突破了传统具身智能模型的三大局限:通过无监督视频学习减少标注依赖、构建任务中心的隐式动作空间实现跨机器人形态迁移、采用轻量级适配降低部署成本。实验表明,该框架在多个操控和导航基准测试中性能显著优于现有方法,仅用少量数据即可达到SOTA效果,并在真实机器人部署中展现出80%以上的任务成功率与10Hz实时控制能力,为具身智能的通用化发
1 前言
之前已经介绍过多篇应用于自动驾驶领域的大模型,本篇博客主要介绍一个应用于具身智能机器人的大模型。
现有具身模型通常依赖人工标注的数据与固定的动作空间,难以适应未训练过的新任务与新场景,通用性受限。同时,不同机器人系统在摄像头视角、本体感知输入、关节结构、动作空间和控制频率上存在差异,训练一套通用的机器人策略面临巨大挑战。
由香港大学、OpenDriveLab 与智元机器人(AgiBot)联合提出的跨具身视觉 - 语言 - 动作(VLA)通用策略学习框架---UniVLA。
2 UniVLA
UniVLA,旨在实现跨不同机器人本体、场景与任务的通用策略学习。UniVLA 旨在解决三大核心痛点:
- 标注依赖:摆脱对大规模动作标签的依赖,利用无标注视频学习。
- 具身锁定:打破单一机器人形态限制,实现跨机械臂、移动平台等的技能迁移。
- 效率瓶颈:降低预训练与下游适配的计算与数据成本,提升部署效率。
2.1 架构
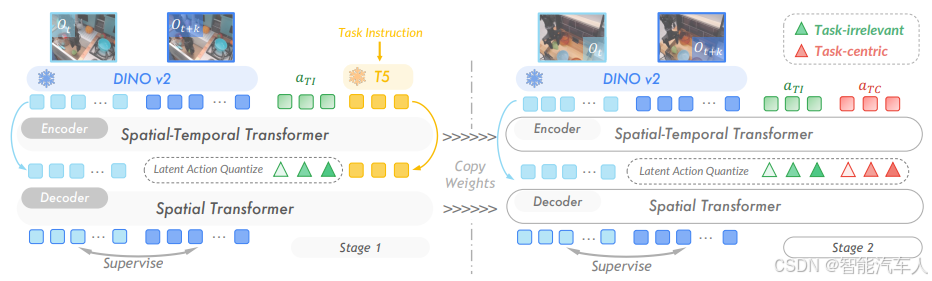
构建以任务为中心的隐式动作空间,让模型可以从海量无标签视频中学习任务相关且高效泛化的动作表示。通过逆动力学建模并使用 VQ - VAE 进行离散化,将动作预测划分为隐式动作学习、通用策略预训练、动作解码与部署等几个阶段,如下图所示。
- 特征提取与任务过滤
- 视觉特征:采用 DINOv2 提取视频帧特征,冻结骨干网络避免任务无关信息干扰。
- 语言指令:Prismatic - 7B 编码任务语义,构建任务相关的特征空间,过滤背景、光照等无关动态。
- 隐式动作生成
- 基于逆动力学模型,无监督从视频中学习动作序列的隐式表征,形成任务中心隐式动作空间,统一不同具身的动作描述。
- VLA 策略学习
- 融合视觉特征、语言指令与隐式动作,通过 Transformer 训练通用策略,输出隐式动作序列。
- 下游适配
- 针对目标机器人,训练轻量级动作解码器,将隐式动作映射为机器人可执行的底层控制指令,适配成本低。
2.2 实验验证
- 多个操控基准测试:在 LIBERO、CALVIN 等多个操控基准测试中,UniVLA 展现出优越的通用性与任务适应能力,在四项评估指标中成功率平均提升达 18.5%。仅使用人类视频预训练(Ego4D),UniVLA 也能在 LIBERO - Goal 中达到 SOTA 效果。在少样本情况下,UniVLA 性能优势明显,在 LIBERO 长程任务基准上仅用 10% 数据击败了全量数据微调的 OpenVLA。
- 导航任务:在导航场景中,UniVLA 的表现也优于 OpenVLA,将 Oracle 成功率拉到较高水平,在多任务上性能全面领先,预训练计算量<1/20,下游数据量<1/10。
- 真实机器部署:在真实机器部署中,UniVLA 可以实现(闭环)10Hz 以上的实时推理控制,在多个任务中展现出高精度、高鲁棒的操作能力,平均成功率达到 80% +,推理时延远低于 OpenVLA。
如下表所示:
| 任务类型 | 测试平台 | 核心优势 |
|---|---|---|
| 操作任务 | LIBERO、Bridge - V2 | 仅用人类视频预训练,达到 SOTA 精度,优于 OpenVLA |
| 导航任务 | Habitat - 2.0 | 跨场景泛化能力强,适配不同移动机器人 |
| 真实机器人部署 | 智元机械臂、移动平台 | 快速适配,完成取放、导航等复杂任务 |
3 总结
UniVLA提出了一种创新的跨具身视觉-语言-动作通用策略学习框架,突破了传统具身智能模型的三大局限:通过无监督视频学习减少标注依赖、构建任务中心的隐式动作空间实现跨机器人形态迁移、采用轻量级适配降低部署成本。
目前人形机器人是一个非常热的领域,资本也在追逐,对于感兴趣的朋友,也是一个不错的方向。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)