【ACP-LLM】大模型篇 2
本章介绍了大模型的文本生成工作流程。
📚 2. 大模型是如何工作的
近几十年来,人工智能经历了从基础算法到生成式AI的深刻演变。
生成式AI通过学习大量数据可以创造出全新的内容,如文本、图像、音频和视频,这极大地推动了AI技术的广泛应用。
常见的应用场景包括智能问答(如通义千问、GPT)、创意作画(如Stable Diffusion)以及代码生成(如通义灵码)等,涵盖了各个领域,让AI触手可及。

智能问答作为大模型最经典且广泛的应用之一,是我们探索大模型工作机制的最佳范例。
接下来将介绍大模型在问答场景中的工作流程,帮助你更深入地理解其背后的技术原理。
2.1. 大模型的文本生成工作流程
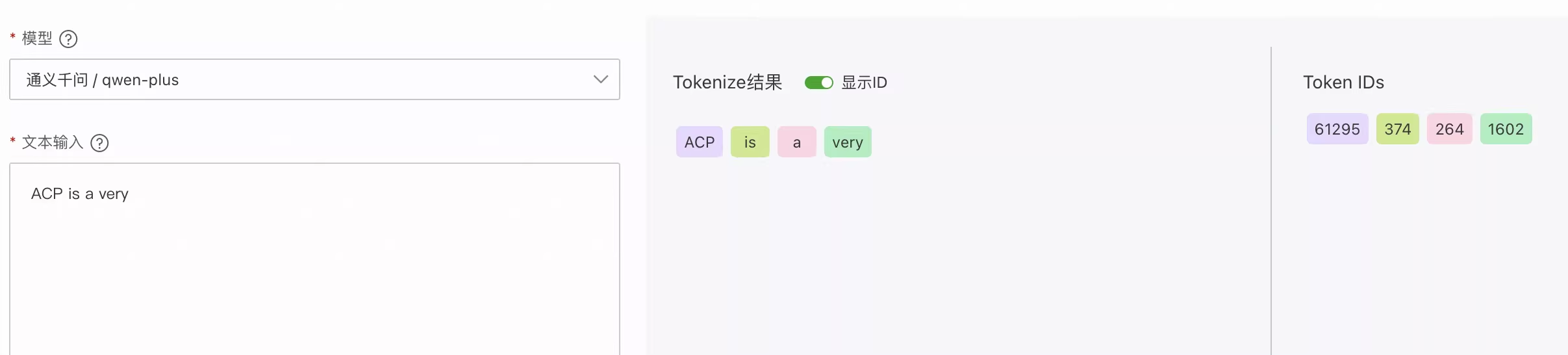
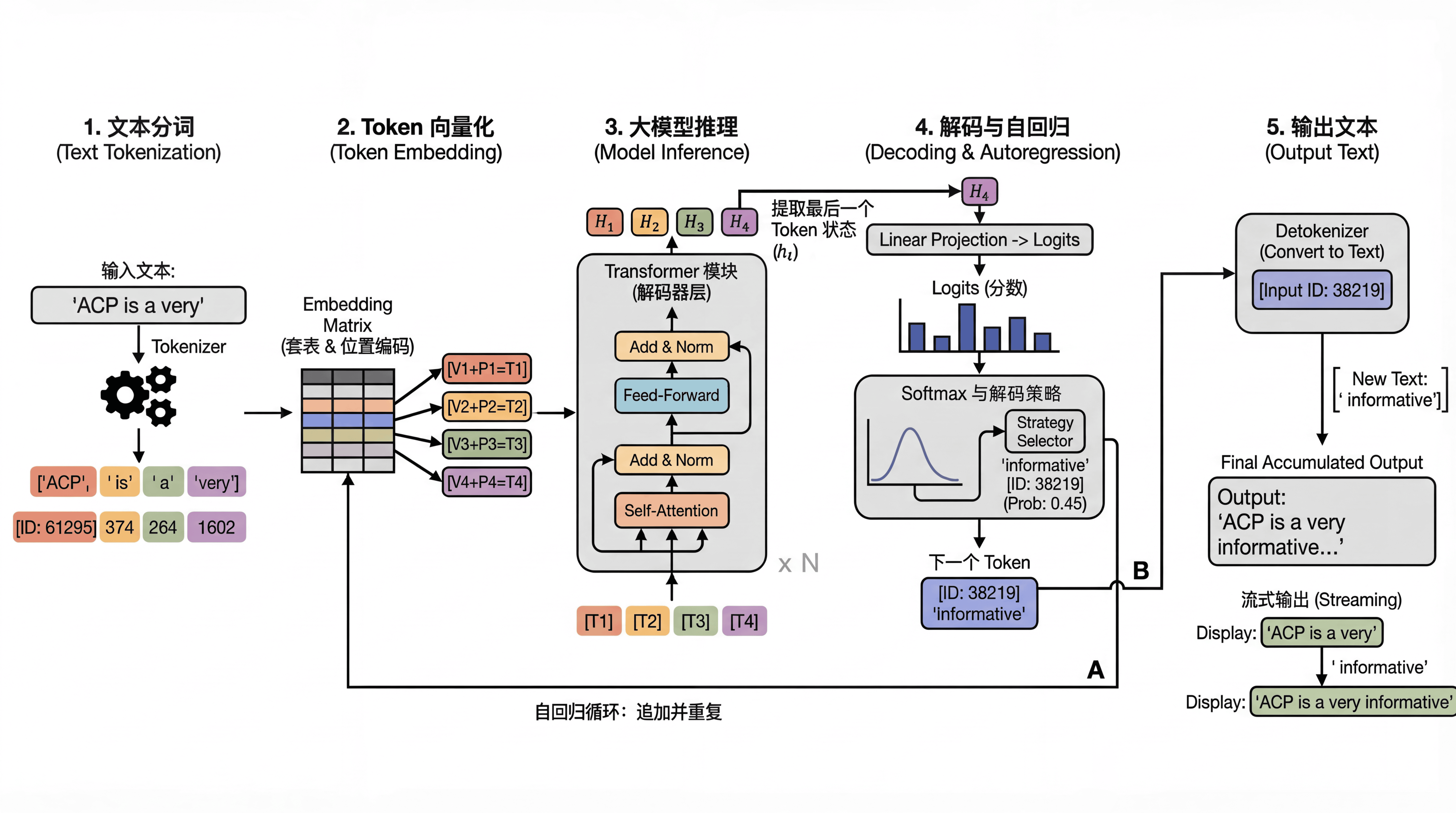
让我们以一个简单的输入"ACP is a very"为例,来具体看看大模型是如何一步步处理这个输入,并最终生成完整句子的。

大模型的文本生成流程可以分为五个阶段:
第一阶段:文本分词
计算机无法直接理解人类的文字。
因此,第一步需要将我们输入的文本“ACP is a very”转换成计算机能够处理的数字格式。
这个过程被称为Tokenization(分词)。
Token 是分词器(Tokenizer)把文本编码后得到的基本单元,每个 token 对应词表中的一个整数 ID。
需要注意的是,token 通常是子词片段或字符片段,不一定等于一个完整的"词",也不一定具有独立语义。
比如英文单词可能被拆成词根和后缀,中文可能按字或常见词组切分,空格和标点也可能被编码进 token。
以"ACP is a very"为例,Tokenizer 会将其编码成若干 token,并为每个 token 分配一个 ID。
如果你对通义千问(Qwen)的分词细节感兴趣,可以查阅其官方文档:Tokenization 说明。
第二阶段:Token 向量化
虽然我们得到了数字 ID 序列,但这些 ID 本身的数值大小并没有实际意义
(比如,ID 500 并不意味着它在语义上就比 ID 50 更“重要”或“相关”)。
为了让模型理解 token 的真实含义,我们需要将这些离散的 ID 转换成包含丰富语义信息的数学表示——向量 (Vector)。

这个转换通过一个被称为 Embedding 矩阵 的巨大表格完成。
简单来说,就是用 token ID 在这个大表格里“查表”,取出对应的那一整行向量。
每个 token 的向量都包含了其在多维度语义空间中的坐标。
此外,语言的顺序至关重要(“我帮你”和“你帮我”截然不同)。
但基础的 Transformer 模型本身并不直接处理时序信息。
因此,还需要额外给每个 token 向量添加**位置信息 (Positional Encoding)**,让模型能够区分出 “我” 是第一个词,“你” 是第三个词,以此类推。
第三阶段:大模型推理

现在,携带了语义和位置信息的向量序列被送入 Transformer 模型的解码器层 (Decoder Blocks) 进行计算。
这个过程被称为前向计算 (Forward Pass)。
向量序列会逐层穿过数十个甚至上百个结构相似的解码器层,在因果自注意力机制(Causal Self-Attention) 和前馈神经网络 (Feed-Forward Network) 的作用下,文本向量中的信息被一次一次压缩和提取。
我们最终会得到最后一个 token(也就是 “very”)所对应的**隐藏状态向量 (Hidden State)**。
这个向量可以被认为是模型在阅读了 “ACP is a very” 之后,对接下来可能出现的内容的一个高度浓缩的“思考总结”。

最后,这个“思考总结”向量会通过一个线性投影层,映射到整个词汇表的维度,得到一个庞大的分数向量 (Logits)。
第四阶段:解码与自回归

在得到 logits 之后,大模型还需要经过 softmax 函数计算,将这些 logits 重新映射为一种概率分布 P ( next_token ∣ context ) P(\text{next\_token} \mid \text{context}) P(next_token∣context),表示每个 token 被选中的概率。
最后,大模型会根据一个解码策略来决定最终输出哪个 token。
解码策略主要分为两类:
- 近似确定性解码:
如贪心解码(Greedy Decoding),每次选概率最高的token,或Beam Search保留多个候选路径。 - 随机采样解码:如
Top-p(Nucleus Sampling)、Top-k Sampling,从高概率的候选集合中随机抽取。
很多在线服务默认使用随机采样解码,因此即使输入完全相同,也可能出现"回答略有不同"的现象。
通过调整 temperature,你可以改变 softmax 输出概率分布的"尖锐程度"。temperature 越低,token 之间的概率差异越大,概率分布越集中于少数的高概率 token,模型输出越确定。temperature 越高,输出概率分布越平坦,模型的输出多样性越高。
配合 top_p(控制参与采样的候选集合范围)等参数,你可以在模型输出的多样性与稳定性之间做权衡。
你可以在下一小节中进一步了解这些参数。
例如,下图展示了模型预测出的部分候选 token 及其概率(实际词汇表远比这大得多):

一旦选定了下一个 token(比如模型选择了 “informative”),这个新生成的 token 就会被追加 (append) 到原始输入序列的末尾,形成新的输入 “ACP is a very informative”。
然后,模型会基于这个新序列,重复第三和第四阶段,继续预测下一个 token。
这个"文字接龙"的过程称为**自回归生成(Autoregressive Generation)**。
模型的自回归循环会持续进行,直到满足某个停止条件:
- 生成了特殊的终止符 (
End-of-Sequence,EOS token)。 - 达到了预设的最大生成长度限制。
- 生成了用户指定的停用词序列。
不同模型系列的终止符不同。
| 模型 | 终止符 |
|---|---|
| Deepseek V3.2 | <|end▁of▁sentence|> |
| GPT 系列 | <|endoftext|> |
| GPT-OSS | <|return|> |
| LLaMA/Mistral | < /s> |
| Pad Token | <|endoftext|> |
| Qwen3 | <|im_end|> |
第五阶段:输出文本
最后,系统会将整个生成过程中的 token ID 序列转换回人类可读的字符串,并呈现给我们。
我们经常看到的流式输出 (Streaming) 效果,其实是服务端每生成一个或几个 token,就立刻将其解码并增量地发送到你的界面上。
由于 token 可能是子词片段,所以在流式显示时,有时会看到一个词被分成几部分输出,或者空格的出现时机看起来有些奇怪,这都是正常现象。
完整工作流程
以下是大模型的文本生成的完整工作流程图:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)