震惊!不微调也能让AI变强?Manus上下文工程揭秘,让大模型迭代速度提升10倍!
Manus作为AI代理代表,通过上下文工程而非模型微调实现能力提升,其架构历经六次重构。核心理念包括以文件系统为终极上下文、采用主从式Multi-Agent架构、极简设计以及模型与应用层解耦。通过上下文卸载、缩减、隔离和缓存等实践,Manus实现了从周级到小时级的迭代速度,并建立了Benchmark作为唯一护城河和数据飞轮机制,使AI能力持续进化。
一、Agent元年回顾
2025年作为Agent元年,元旦期间看了不少Agent架构的复盘,很认可知乎博主周星星的观点,Agent架构已逐步收敛至以 Claude Agent SDK 和 Deep Agent 为代表的架构。
首先,Agent架构在持续激烈地演进着,10月份Manus的分享中透露他们的Agent架构已经经历了五次重构,离他们3月份发布早期预览版开始才过去7个月,这应该是最好的证据了。
但是,10月份前后出现了收敛的迹象,LangGraph 1.0正式发布,并同时推出Deep Agent;Claude正式将Claude Code SDK更名为Claude Agent SDK,并发布博客《Building agents with the Claude Agent SDK》。
那到底收敛到了一个什么样的架构呢?
- 它是个Agent Loop,配合相应的工具,从而来处理复杂、多步的任务
- 它通常采用Main Agent + Sub Agent的主从架构,从而隔离Agent的上下文,同时避免Agent通信带来的困难。
- 它通常包含一个planning阶段,来对复杂、多步任务进行规划和拆解
- 它可以利用文件系统进行上下文管理,包括offload、reduce、retrieve、isolate、cache等操作
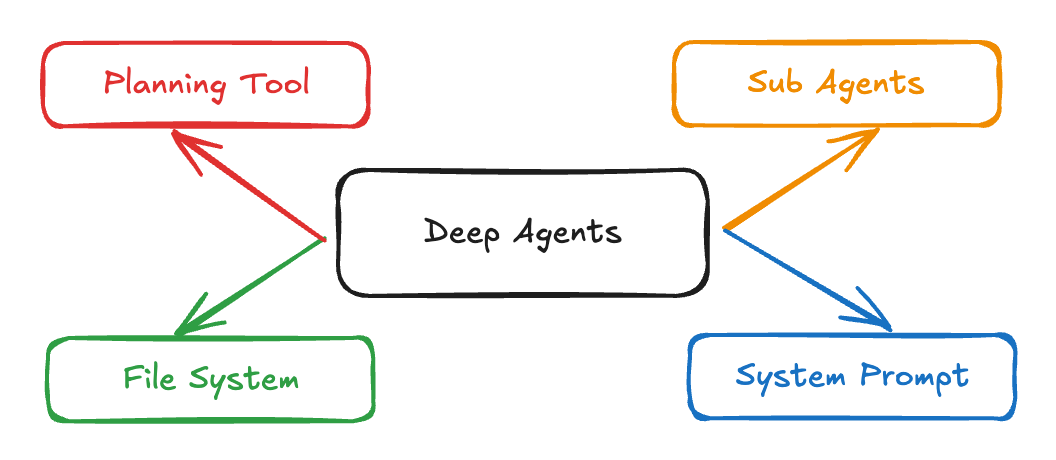
这次我们先深入研究一下Manus的架构。
二、Manus历次产品更新与架构重构
10月份Manus的分享中透露他们的Agent架构已经经历了五次重构(加上11月份的Manus 1.6,至少有六次),自2025年3月首次发布以来才过了7个月。其核心升级集中在上下文工程、执行效率、规划能力以及复杂任务交付四个维度。
- 上下文工程的持续优化:Manus在上下文工程方面不断探索,在上下文卸载方面,为了应对“工具爆炸”带来的上下文混淆,将工具列表从单层扁平架构升级为三层架构,分别为原子函数层、沙盒工具层、代码/包层。除此之外,他们在上下文压缩、上下文隔离也诞生了非常多的最佳实践。
- 执行效率升级:通过持续的架构重构,任务完成速度从早期的约 15 分钟缩短至 4 分钟以内
- 规划机制进化:早期版本通过不断读写
todo.md文件来复述目标,但这会消耗大量 Token 和交互轮次。后来他们升级后采用专门的规划 Agent,以实现更专业的任务拆解与进度管理,显著节省了 Token 成本。 - 交付能力逐步扩展:Manus 从简单的任务执行进化为复杂产物的全流程交付,包括全栈 Web 应用开发、Wide Research
以下是从时间维度进行梳理的Manus的产品和能力升级时间线:
| 时间节点 | 版本 | 重点更新 | 核心突破 |
|---|---|---|---|
| 2025.03 | 1.0 | • 全球首发通用 AI Agent • 推出 Browser Operator • 支持自主多步任务拆解与执行 | 自主执行: 突破了传统 AI “只说不做”的限制,能直接操控网页完成任务。 |
| 2025.10 | 1.5 | • 全栈 Web 应用开发功能上线 • 1.5架构:运行速度较4月份提升4倍,归功于单个任务扩展的上下文窗口 | 生产力跃迁: 不再只是爬取数据,而是能独立交付可运行的生产级软件。 |
| 2025.11 | 1.6 | • 推出迄今最强引擎 Manus 1.6 Max,任务成功率大幅提升 • Max架构:通过更先进的规划和问题解决架构,带来了可衡量的性能提升 • 开放移动端应用开发能力 • Design View:互动式画布,支持精准修图 • 优化Wide Research子智能体并行效率 | 多模态与全平台: 覆盖移动端开发,并引入了更精细的视觉交互能力。 |
三、Manus的核心架构理念
3.1 以上下文工程为中心
Manus 架构最显著的特征是不依赖模型微调,而是将所有技术投入在上下文工程上,这一理念有两个方面的核心价值:
1)迭代速度从“周级”到“小时级”的进化:在传统的开发模式中,通过微调模型来提升 Agent 能力通常需要数周的时间进行数据清洗、人工标注和反复训练。Manus 通过上下文工程,可以在几小时而非几周内交付改进。这种“天级”甚至“小时级”的反馈循环,使得产品能够快速响应用户需求和市场变化。
2)Agent效果与底层模型保持“正交”关系:Manus 团队认为模型进步是“上涨的潮水”,而 Manus 是“顺流而上的船”,而非固定在海床上的柱子。通过将应用逻辑(上下文工程)与底层模型能力清晰解耦,Manus 能够直接享受 SOTA 模型(如 Claude 3.7 或 Gemini 3)带来的红利,而无需重新训练自己的垂直模型。
3.2 文件系统作为终极上下文
为了解决上下文爆炸的问题,许多代理系统实现了上下文截断或压缩策略。但过度激进的压缩不可避免地导致信息丢失。所以Manus中将文件系统视为终极上下文:大小不受限制,天然持久化,并且代理可以直接操作。模型学会按需写入和读取文件——不仅将文件系统用作存储,还用作结构化的外部记忆。基于文件系统可以设计可恢复的的压缩策略,同时大大缩减了上下文的大小。
3.3 反“拟人化”的Multi-Agent架构
不同于市场上将 Agent 划分为设计师、程序员等角色的做法,Manus 认为那是受限于人类能力局限的组织形态,AI 模型比人类更全能,不应受限于人类的组织分工约束。因此他们采用非对等的Multi-Agent架构。
- 主从架构:采用 Main Agent - Sub Agent 结构,核心由通用规划器、执行器和知识管理器组成。
- SubAgent as Tool:将子智能体实现为可调用的工具,而非对等的对话通讯,以减少通讯摩擦和信息损失。
3.4 极简主义架构设计
Manus 的架构理念中包含一种去工程化的倾向,遵循“Less Structure, More Intelligence”。他们发现,最大的技术跳跃往往来自于简化架构和信任模型,而非增加复杂的逻辑套路或预设工作流。其目标是让模型的工作变得更简单,而不是更复杂。
3.5 模型层与应用层Co-Design设计
Manus的核心理念是:“应用层做船,模型层做水”。他们坚持将应用逻辑与模型能力解耦,通过极致的上下文工程来弥补现有模型在 Agent 场景下的短板,并利用其作为头号客户的影响力反向塑造模型层的演进,尤其在以下几个方面的能力:
1)解决工作负载与对齐模式的错位:目前的大模型主要为 Chatbot(聊天机器人)设计,在 Agent 场景下存在明显的不适应,特别是Prefilling与Decoding的比例变长、急于结束任务的上下文压力、交错式推理的ReAct范式。
2)提升Tool Integrated Reasoning能力:现有的长思维链(CoT)推理模型(如 O1 系列)并不完全适合 Agent,Agent更需要交错式思考的能力,因为Agent 不需要“缸中之脑”式的闭门造车,而需要工具集成的推理,即在获得工具返回的观察结果后,进行简短、精准的中间推理,决定下一步动作。此外,指令遵循也需要继续提升,纯推理模型在 Agent 场景下,其指令遵循能力和工具调用的准确性有时反而会下降。
3)从长上下文转向“压缩意识”:模型应该具备压缩意识,学会像人一样,将非必要的中间过程整理成文档存储,而不是让上下文无限增长。当需要使用的时候,模型能够意识到信息已被卸载到文件系统中,并进行读取。
4)提升复杂环境下的韧性与异步交互能力:模型需要提升错误恢复能力,通过专门训练对非代码类错误(如环境报错、资源受限)的处理能力,能够寻找替代路径而非陷入死循环或直接放弃。模型还需要提升异步交互适应,因为Agent将逐渐处于持续工作状态,用户可能随时插入新指令或补充信息。模型层需要适应这种非对称、异步的通信模式。
5)提升多模态工具的集成能力:在全栈网页开发场景,通过 VLM(视觉语言模型)直接审查自身生成的网页或 UI 是否可用是一种比拆分复杂工作流更高效、成本更低的方案。Agent需要调用多模态工具返回的截图(如浏览器页面),但是目前模型对这种“作为工具结果的多模态输入”效果不佳。
四、Manus的上下文工程实践
秉持着以上下文工程为中心的架构理念,Manus在对外分享中提到了上下文卸载(Context Offloading)、上下文缩减(Context Reduction)、上下文隔离(Context Isolation)、上下文缓存(Context Cache)等方面的具体实践。
4.1 上下文卸载
上下文卸载是一种通过外部工具或存储系统将信息保存在LLM上下文窗口之外的策略。其核心机制是利用文件系统、沙盒环境或“便笺”(Scratchpad)等形式构建结构化的外部记忆,允许智能体在需要时按需读写数据,而不是将所有观察结果和中间状态一直保留在原本有限且昂贵的活跃上下文中。
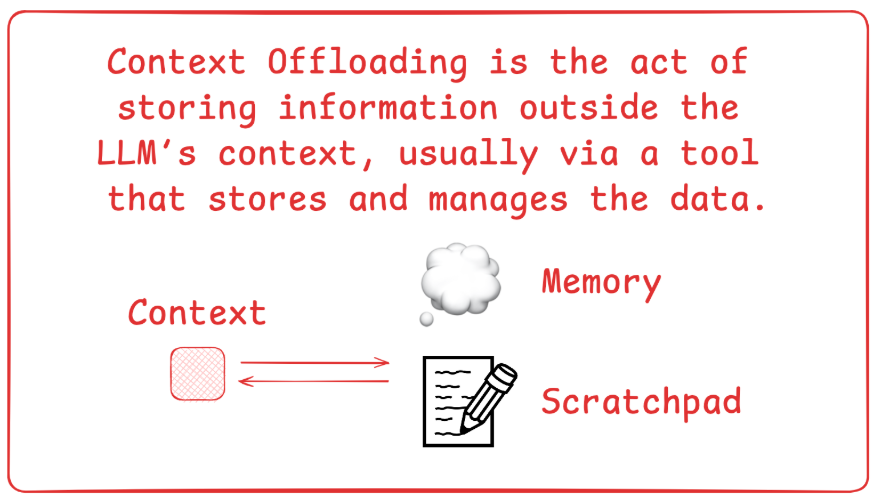
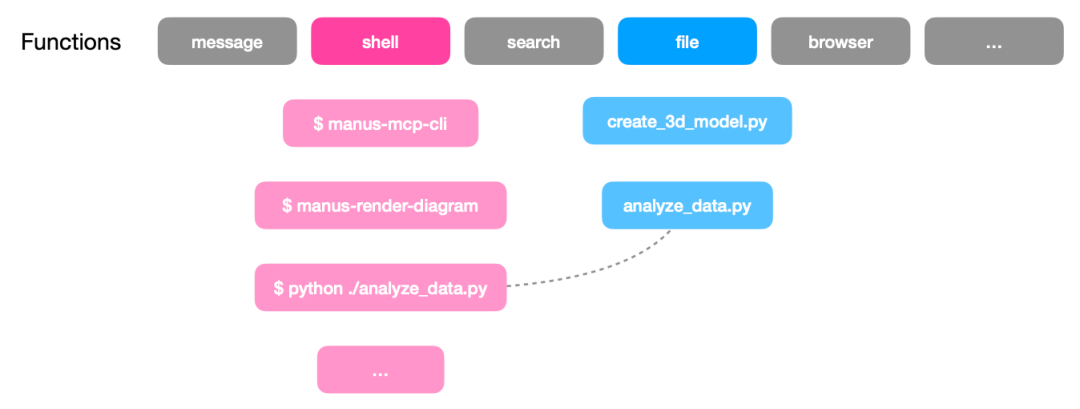
通常人们说offload时,通常指的是将工作上下文的部分内容移到外部文件中。在此基础上,Manus为了应对“工具爆炸”带来的上下文混淆,设计了工具卸载的方案,他们将工具空间升级为三层架构,只将第一层工具加载到上下文中,三层抽象设计分别为:
- 原子函数层(Function Calling):保留约 10-20 个核心、高频、模式安全的工具(如读写文件、浏览器操作)。
- 沙盒工具层(Sandbox Utilities):对应下图中的红色工具,直接在虚拟机沙盒中通过 Shell 调用预装程序(如 FFmpeg、MCP CLI),将具体工具定义排除在 Context 之外。
- 代码/包层(Code/Packages):对应下图中的蓝色工具,让 Agent 编写动态 Python 脚本一次性执行复杂串行逻辑,减少 LLM 往返交互。
其实,熟悉Claude Skill的同学应该已经感受到了,他们思路上是高度一致的,底层核心都是“渐进式披露”的理念。
4.2 上下文缩减
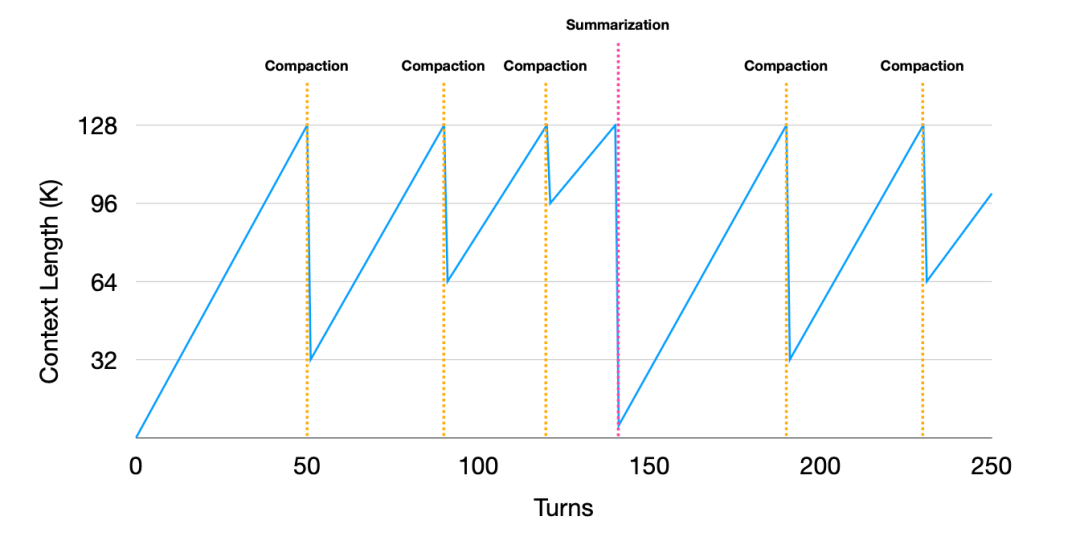
1)轨迹的可逆精简(Context Compaction)
Context Compaction是指移除可从文件系统重建的信息(如冗长的文件内容),过程可逆。这是 Manus 优先使用的手段。它会移除所有可以从文件系统或外部状态中重新构建的信息。以下图为例,在执行 file_write 工具调用后,Manus 会在上下文中删除冗长的 content(文件内容)字段,仅保留 path(路径)。这种方法是可逆的,如果模型后续需要该信息,可以通过路径重新读取,从而在不丢失任何关键细节的前提下显著缩短上下文。
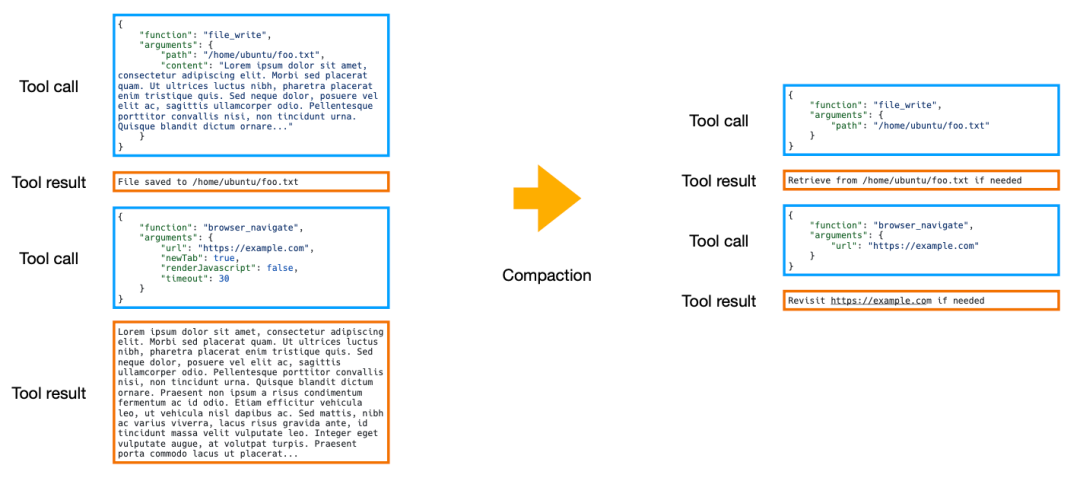
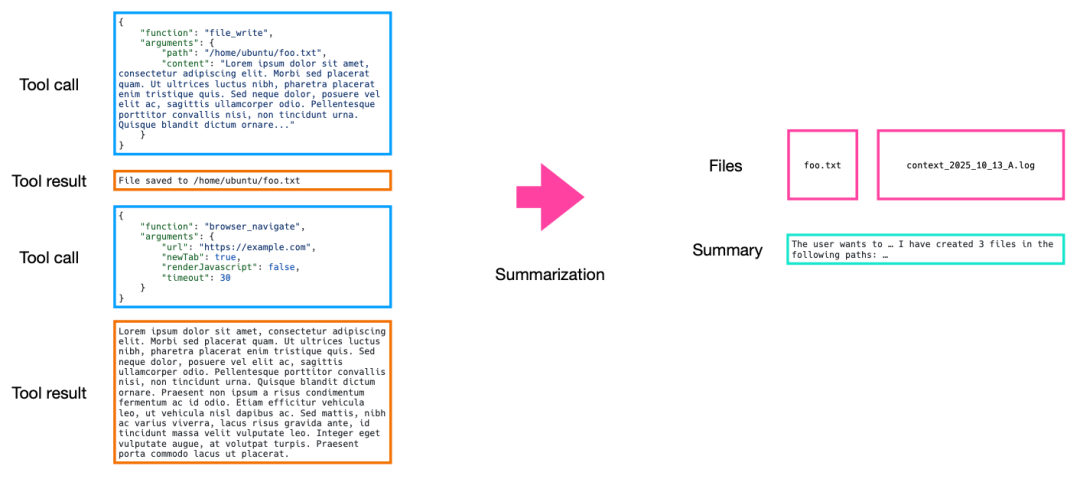
2)轨迹的不可逆摘要(Context Summarization)
Context Summarization是指在接近“腐烂阈值”时进行不可逆压缩,但保留最近的原始调用详情以维持模仿学习。Manus一般在精简操作无法释放足够空间时,才会触发摘要操作。在摘要之前,Manus 会将完整的原始上下文导出为文本或日志文件存入文件系统,确保以后仍可找回。摘要时会使用完整数据而非精简版,并保留最近几轮的完整工具调用详情,以防止模型由于丢失近期记忆而导致回复风格或任务进度的漂移。
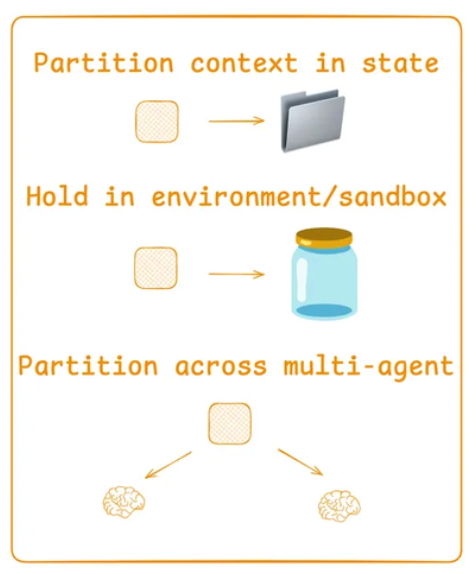
4.3 上下文隔离
上下文隔离是指在多智能体之间、Agent与沙盒环境之间或者用结构化状态对象来存储图像、音频或大型代码执行结果等高消耗数据,仅向LLM回传当前步骤必须的变量或摘要,从而在保持状态持久化的同时,有效隔离“上下文污染”并精准控制模型的注意力焦点。
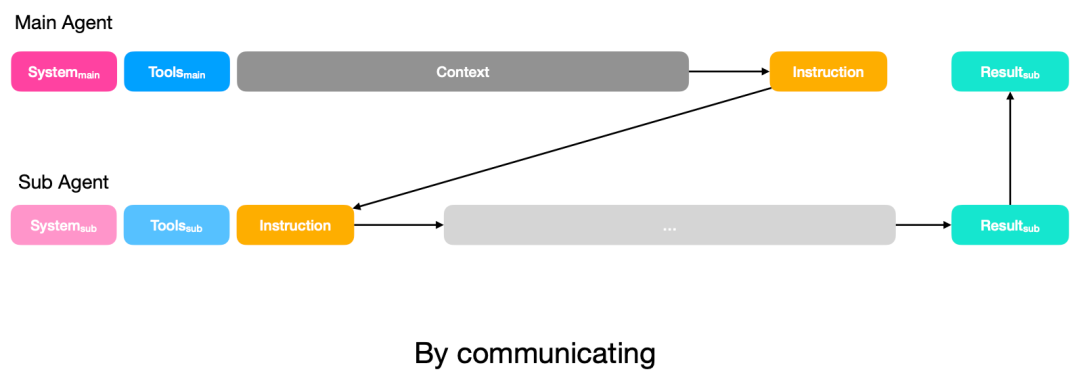
Manus 实现上下文隔离的核心理念是采用 Main-Sub Agent架构,并将子智能体视为可调用的工具(Agent as Tool)。这种设计旨在防止中间过程产生的冗余信息“污染”主对话流,从而提升任务的稳定性和 Token 效率。
此外,根据任务复杂度,Manus 灵活应用了两种不同的隔离策略:
1)通信策略(By Communicating):子智能体仅接收简洁的指令。适用于短期、目标明确的任务(如搜索特定代码片段)。主智能体不关心执行路径,只拿结果,从而实现完全隔离,。
2)共享上下文策略(By Sharing Context):在涉及深度研究等复杂场景时,允许子智能体“分叉(Fork)”并共享主上下文。虽然这增加了 Token 成本且无法复用 KV 缓存,但能确保子智能体理解复杂的历史背景。
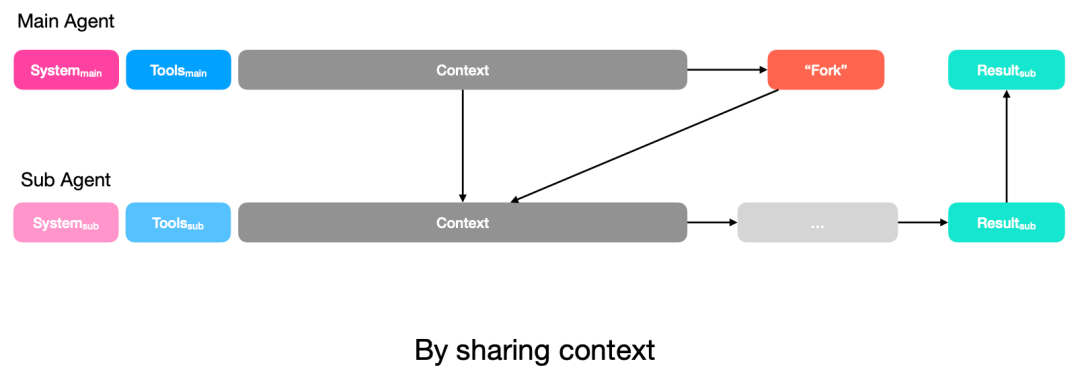
4.4 上下文缓存
在 Manus 的技术架构中,KV Cache 被视为生产阶段最重要的单一技术指标。他们为此进行了以下实践:
1)上下文工程优化
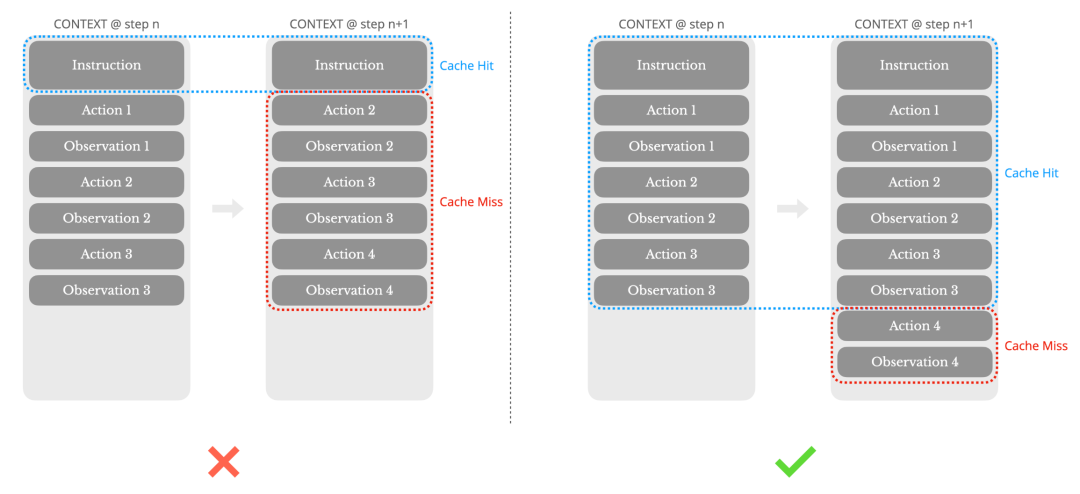
为了保持缓存前缀的稳定性,Manus 遵循以下准则:
• 保持前缀稳定:避免在系统提示词开头放置动态信息(如精确到秒的时间戳),否则会导致其后的所有缓存失效。
• 只追加(Append-only)模式:上下文历史严格保持只追加,不修改过往的操作或观察结果。
• 序列化确定性:确保上下文序列化(如 JSON 化)的过程具有确定性,例如保持 JSON 键的顺序固定,防止因序列化差异破坏缓存。
• 显式缓存断点:在不支持自动增量缓存的框架中,手动在上下文末尾(如系统提示词结束处)标记缓存断点(Cache Breakpoints)。
2)架构层面的缓存优化
• 分层行动空间:Manus 将工具调用分为原子层、沙盒工具层和代码层。这种设计避免了在上下文中频繁动态添加或删除工具定义,从而防止了上下文混淆并保护了 KV 缓存的稳定性,。
• 主从架构:通过主智能体调度子智能体的模式,可以更好地复用主逻辑的缓存,实现“省钱且跑得快”。
3)基础设施与模型选择
• 偏好闭源旗舰模型:Manus 倾向于使用 Claude、Gemini 等闭源模型,一个核心原因是这些厂商拥有比开源方案更成熟、更稳定的全球分布式缓存基础设施,在大规模并发下成本更低。
• 拒绝参数化个性化:Manus 坚持不使用 LoRA 等参数化微调来实现个性化,因为这会降低批处理效率并使缓存难以复用,最终导致推理成本上升。
• 会话路由一致性:对于自托管模型(如使用 vLLM),Manus 使用 Session ID 等技术将请求一致地路由到同一工作节点,以确保缓存命中。
五、其它最佳实践
5.1 Benchmark
Manus 认为Benchmark是 AI 公司唯一的护城河,其实践的核心理念在于将“品味”通过量化的衡量标准转化为可落地的产品力。由于传统的学术基准与用户真实体感存在严重脱节,Manus 构建了一套从“可验证结果”到“主观美学”的多维度评测体系。他们进行了以下的一些实践:
1)Benchmark是Taste的落地工具:Manus 认为评测指标决定了团队努力的方向。好的 Benchmark 是将创始人或产品负责人的品味对齐到研发过程的唯一工具,否则团队容易在错误的目标上南辕北辙。
2)不能只依赖公开Benchmark:Manus 早期关注 GAIA、SWE-bench 等学术指标,但发现即使在这些榜单表现优异,用户的真实评分也不一定高,因为用户更关注网站是否美观、易用等难以自动量化的细节。
为此,Manus 建立了由三部分组成的评测架构:
| 评测层级 | 评估方式 | 核心价值 |
|---|---|---|
| 用户反馈(金标准) | 收集已完成会话的 1-5 星评分。 | 最真实的生产力反馈,直接指导迭代方向。 |
| 内部自动化测试 | 基于可验证结果(如代码运行成功、数据提取准确)的专用数据集。 | 确保 Agent 执行事务性任务时的稳定性和正确率。 |
| 主观评估团队 | 雇佣大量实习生进行人工盲测,评估视觉吸引力和交互体验。 | 衡量“美学”和“品味”等无法通过 Reward Model 自动实现的指标。 |
此外,Manus还有一套评估Agent架构未来适应性的方法Weak-to-Strong Evaluation,他们先锁死当前的 Agent 框架,分别运行同系列模型的弱版本和强版本。如果框架能让强弱模型之间的性能增幅(Delta)最大化,则证明该架构具有极强的未来适应性,这就让架构能够随着未来模型的不断变强而随之升级。
5.2 数据飞轮
Manus采用了无参数进化的方案,不依赖参数微调,而是通过集体反馈实现进化。利用用户对 Agent 的修正和反馈,将成功的模式沉淀为系统原生的认知。
1)收集用户反馈:在任务执行中,用户会通过纠正偏好(教)或直接修正错误结果(修)来提供反馈。
2)提取共性失败模式:系统会分析大量用户交互中的执行痕迹,挖掘出通用的失败模式和用户共识,并将其转化为系统原生的一部分,。
3)平台级经验聚合:Manus 不仅仅做单用户的记忆挖掘,更倾向于在所有用户层面聚合共性的经验教训,以文字形式的知识在后续任务中动态注入。
为什么不采用参数化微调方案呢?他们认为通过模型微调构建飞轮的做法存在严重缺陷:
- 迭代速度脱节:模型微调的周期(以周/月计)远慢于产品经理的思维速度(以小时计),会拖慢初期迭代。
- 保质期极短:在 DeepSeek 等快速迭代的背景下,SOTA 模型的保质期仅 1-1.5 个月。如果过度依赖自研微调模型,会导致系统难以无缝迁移到更强的基座模型上。
- 推理效率下降:参数化个性化(如 Multi-LoRA)会破坏 Batch Size 的规模效应,导致推理延迟和成本上升。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献635条内容
已为社区贡献635条内容

所有评论(0)