Voyager:让 GPT-4 在《我的世界》里自主探索、终身学习
Voyager 是第一个在 Minecraft 中实现**终身学习**的 LLM 驱动智能体——它能**自己给自己布置任务**,**自己写代码执行**,**自己验证成功与否**,还能把学会的技能**存成"技能库"供以后调用**。在 160 轮探索中,它发现的物品数量是基线方法的 3.3 倍,解锁钻石工具的速度快了 15 倍。
Voyager:让 GPT-4 在《我的世界》里自主探索、终身学习
论文标题:Voyager: An Open-Ended Embodied Agent with Large Language Models
arXiv 链接:https://arxiv.org/abs/2305.16291
发布时间:2023年5月
作者团队:英伟达、加州理工学院、UT Austin、斯坦福、威斯康星大学
📖 一句话总结
Voyager 是第一个在 Minecraft 中实现终身学习的 LLM 驱动智能体——它能自己给自己布置任务,自己写代码执行,自己验证成功与否,还能把学会的技能存成"技能库"供以后调用。在 160 轮探索中,它发现的物品数量是基线方法的 3.3 倍,解锁钻石工具的速度快了 15 倍。
🎯 这篇论文想解决什么问题?
具身智能体的"天花板"在哪?
传统的游戏 AI(比如 AlphaGo、OpenAI Five)都是靠海量强化学习训练出来的:给定一个明确目标,用奖励信号不断调参。但这种方式有几个致命问题:
- 目标是人定的:你得告诉它"去挖钻石",它才会去挖。它不会自己决定"今天想学钓鱼"。
- 技能不可迁移:学会挖钻石的策略,换个地图可能就失效了。
- 没法终身学习:训练完就定型了,不会随着游戏推进学新东西。
这就像培养一个员工,你只能让他干一件事,而且干完就"退休"了。
Minecraft 为什么是理想的测试场?
《我的世界》是一个开放世界沙盒游戏,有 300+ 种物品、复杂的合成配方、无限大的地图。它的特点:
- 没有固定目标:你可以挖矿、建房、打怪、养殖,全凭自己探索
- 技能有层级:先学会砍树,才能做木镐;有了木镐才能挖石头;有了石头才能做更好的工具
- 环境多样:森林、沙漠、雪地、地下矿洞……不同地形需要不同策略
这就是一个天然的**课程学习(Curriculum Learning)**场景:从简单任务逐步升级到复杂任务。
已有方法的局限
在 Voyager 之前,已经有人尝试用 LLM 控制游戏智能体:
| 方法 | 思路 | 问题 |
|---|---|---|
| ReAct | 用思维链生成"思考 → 行动"序列 | 对开放式目标无从下手 |
| Reflexion | 在 ReAct 基础上加自我反思 | 没有技能积累机制 |
| AutoGPT | 把大目标拆成子目标 | 子目标执行经常卡住 |
这些方法的共同问题是:每次都从头开始。就算你昨天学会了做铁剑,今天还得重新探索一遍。
🧠 Voyager 的核心设计
Voyager 的精妙之处在于它把 LLM(GPT-4)当成一个**“万能工具人”**——不调参数,不做微调,只通过黑盒 API 调用,让 GPT-4 同时扮演三个角色:
- 课程规划师:决定下一步学什么
- 程序员:写代码执行任务
- 验收员:检查任务有没有完成
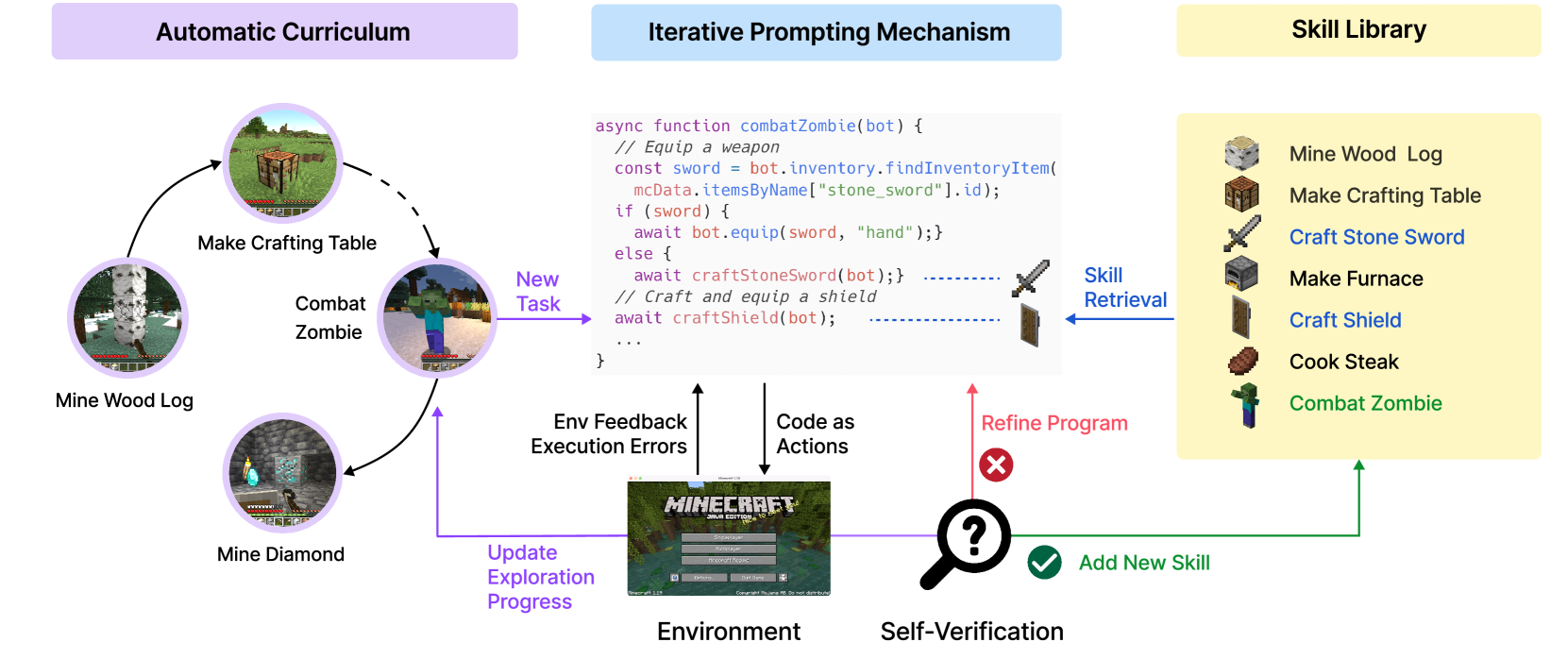
图1:Voyager 的核心架构——自动课程、技能库、迭代提示三大模块协同工作
这张图展示了 Voyager 的完整工作流程:左侧是自动课程模块,负责根据当前状态提出新任务;中间是技能库,存储了所有学会的技能代码;右侧是迭代提示机制,通过环境反馈、执行错误和自我验证不断改进代码。
2.1 自动课程:让 GPT-4 给自己"布置作业"
传统强化学习需要人工设计奖励函数,而 Voyager 干脆让 GPT-4 自己决定下一步该学什么。
工作原理
GPT-4 会根据以下信息,提出一个"刚刚好难"的任务:
输入信息:
├── 当前状态:背包里有什么、装备了什么、周围有什么方块和生物
├── 历史记录:已完成的任务、失败的任务
├── 探索进度:去过哪些地方、发现过什么
└── 约束条件:不要提太难的任务、鼓励多样化探索
输出:
"下一个任务:用铁锭制作一把铁剑"
关键设计:好奇心驱动
Prompt 中有一条关键指令:
“我的最终目标是发现尽可能多的事物,下一个任务不应该太难,也不应该已经完成过。”
这就像一个好奇心旺盛的孩子:刚学会走路,就想去探索隔壁房间;探索完了,又想出去看看外面的世界。

图2:自动课程提示的详细组成——包括指令、智能体状态、已完成/失败任务列表等
这张图展示了自动课程模块的提示词结构:顶部是指令部分,强调探索多样性;中间是智能体的实时状态(背包、装备、周围环境等);底部是已完成和失败任务的列表,用于追踪探索进度。
额外加分项:自问自答
为了让任务提议更"接地气",Voyager 还用 GPT-3.5 生成一些自问自答作为上下文。比如:
- Q: 我现在在哪个生物群系?A: 平原
- Q: 这个群系有什么特色?A: 有很多马,适合驯养
这些信息帮助 GPT-4 提出更有针对性的任务,比如"驯服一匹马"。
2.2 技能库:代码就是记忆
这是 Voyager 最精彩的设计——它把学会的每个技能都存成一段 JavaScript 代码。
为什么用代码而不是神经网络?
| 存储方式 | 优点 | 缺点 |
|---|---|---|
| 神经网络权重 | 可以泛化 | 不可解释、容易遗忘 |
| 代码 | 可解释、可复用、不会遗忘 | 需要正确生成 |
代码的好处是显而易见的:一段"砍树"的代码,今天能用,明天还能用;在这个世界能用,换个世界还能用。而且你可以看到它具体做了什么,出了问题好排查。
技能库结构
技能库
├── 基础技能
│ ├── collectWood() # 收集木头
│ ├── craftWoodenPickaxe() # 制作木镐
│ └── mineStone() # 挖石头
├── 进阶技能
│ ├── smeltIronOre() # 冶炼铁矿
│ ├── craftIronSword() # 制作铁剑
│ └── fightZombie() # 打僵尸
└── 高级技能
├── mineDiamond() # 挖钻石
└── buildHouse() # 建房子
每个技能存储时会附带一个描述嵌入(用 text-embedding-ada-002 生成),方便后续检索。
技能检索:找到最相关的代码
当要执行新任务时,Voyager 会:
- 把任务描述转成嵌入向量
- 在技能库中找 Top-5 最相似的技能
- 把这些技能代码放进 Prompt,作为"参考示例"
这就是**上下文学习(In-Context Learning)**的威力:GPT-4 看几个例子,就能写出类似风格的新代码。
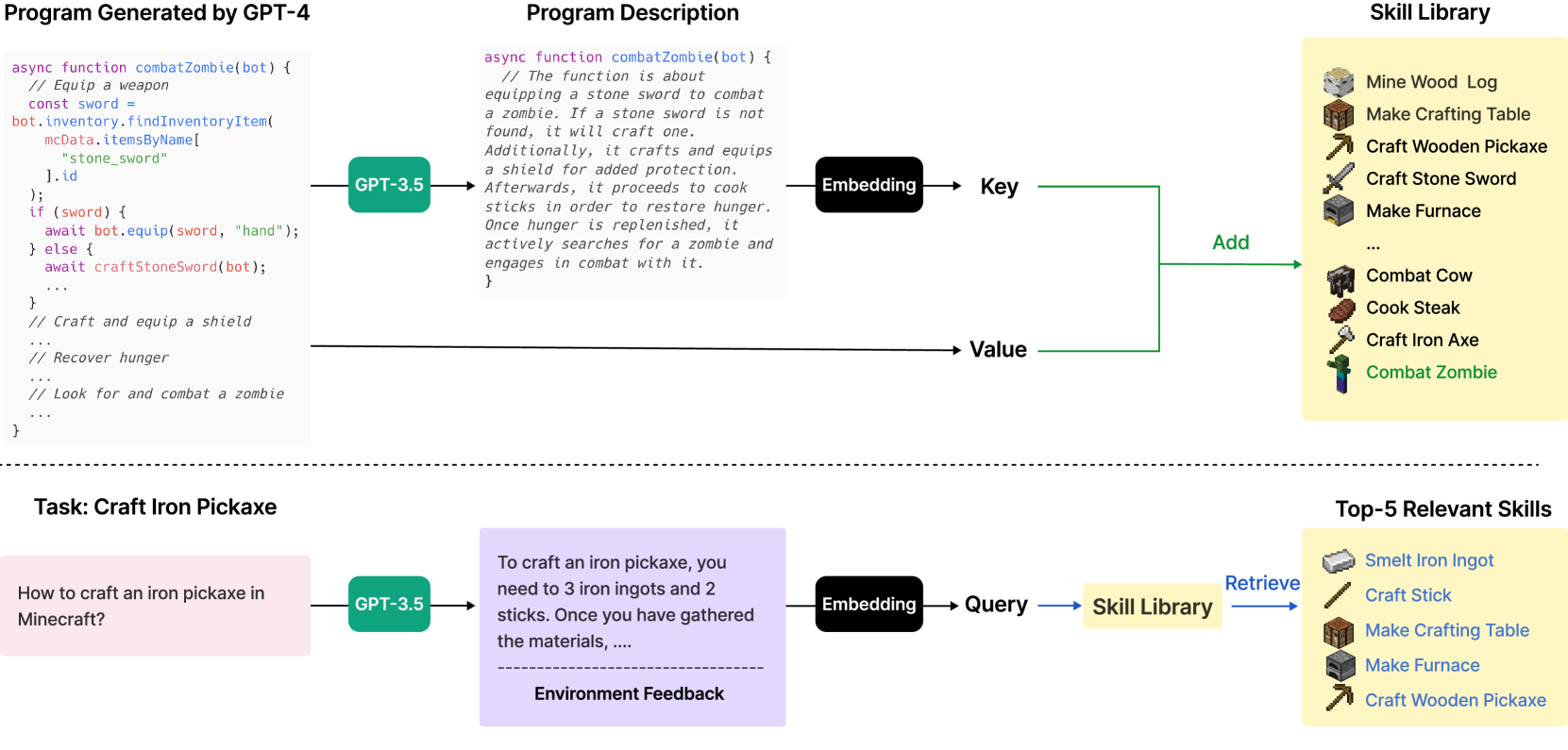
图3:技能库的工作流程——从检索相关技能到生成新代码,再到验证并存入库
这张图清晰展示了技能管理的闭环:当收到新任务时,系统先用嵌入向量检索相关技能作为参考;GPT-4 基于这些参考生成新代码;代码执行后通过验证,成功的技能会被添加到技能库中,索引其描述嵌入。
代码复用的链式效应
关键洞察:复杂技能可以调用简单技能。
比如"制作铁剑"的代码可能长这样:
async function craftIronSword(bot) {
// 先确保有铁锭
await collectIronOre(bot); // 调用基础技能
await smeltIronOre(bot); // 调用进阶技能
// 再确保有木棍
await collectWood(bot); // 调用基础技能
await craftSticks(bot); // 调用基础技能
// 最后制作铁剑
await bot.craft("iron_sword");
}
这种组合性(Compositionality)让技能库的价值随着时间指数增长。
2.3 迭代提示:让代码"自己改自己"
写代码谁都会出 bug,GPT-4 也不例外。Voyager 的解决方案是迭代改进——代码有问题就改,改到能用为止。
三种反馈来源

图4:迭代提示的三种反馈来源——环境反馈、执行错误和自我验证
这张图展示了迭代提示的核心机制:执行代码后,系统会收集三种反馈信息,然后把它们整合到下一轮的 Prompt 中,让 GPT-4 修正代码中的问题。
1. 环境反馈
来自游戏状态的变化,告诉 GPT-4 “事情做到哪一步了”:
环境反馈:
"我需要铁胸甲,但现在只有 2 个铁锭。还需要:6 个铁锭。"
2. 执行错误
来自代码解释器的报错信息:
执行错误:
"TypeError: bot.craft is not a function at line 15"
有了这个信息,GPT-4 就知道该改哪里。
3. 自我验证
这是最有意思的部分——Voyager 用另一个 GPT-4 实例来判断任务是否完成。
验证 Prompt:
"任务:收集 10 块木头
当前背包:oak_log x 12
请判断任务是否完成,如果没完成请说明原因。"
验证结果:
"任务完成 ✓"
如果任务失败,验证模块还会给出批评意见:
验证结果:
"任务失败 ✗
批评:你试图直接挖铁矿,但没有石镐。建议先制作石镐。"
迭代循环
while True:
code = GPT4_generate_code(task, feedback, errors, critique)
result = execute(code)
if self_verify(result):
skill_library.add(code)
break
else:
feedback = get_environment_feedback()
errors = get_execution_errors()
critique = get_critique()
实测中,大多数任务在 3-4 轮迭代内就能成功。
🧪 实验设计与结果
实验设置
- LLM:GPT-4 (gpt-4-0314) 生成代码,GPT-3.5 做辅助任务
- 嵌入模型:text-embedding-ada-002
- 游戏环境:基于 MineDojo 框架,用 Mineflayer JavaScript API 控制
- 评估维度:发现物品数、技术树解锁速度、地图遍历距离
基线方法
由于当时没有现成的 LLM Minecraft 智能体,作者自己实现了三个基线:
| 基线 | 增强配置 |
|---|---|
| ReAct | 提供实验反馈和智能体状态 |
| Reflexion | 在 ReAct 基础上加执行错误和自我验证 |
| AutoGPT | 用 GPT-4 做任务分解,提供完整状态信息 |
这保证了对比的公平性——所有方法都用 GPT-4,都能看到相同的信息。
主实验结果
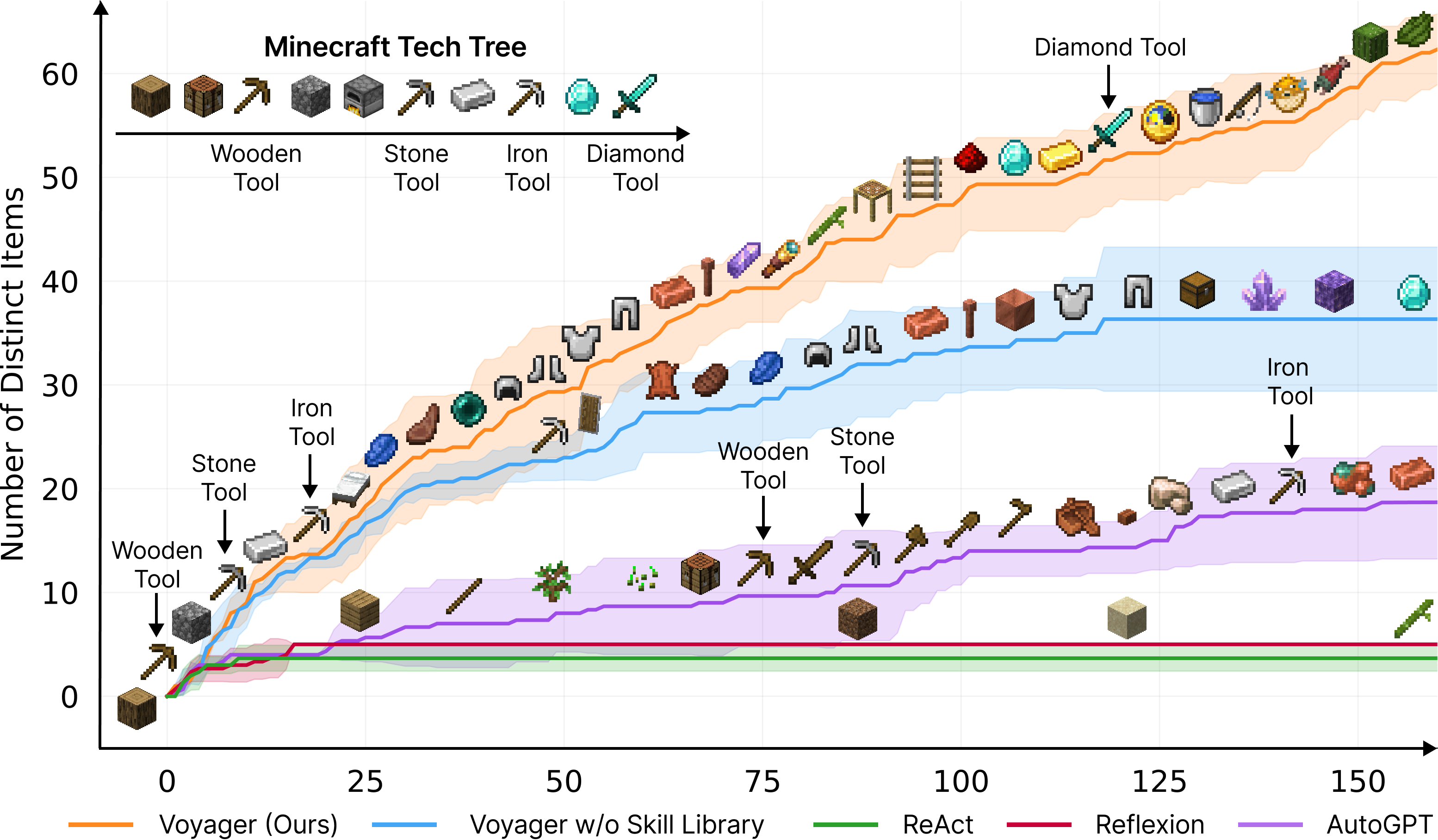
图5:Voyager vs 三个基线方法的探索性能对比——独特物品发现数量随迭代次数的变化
几个关键数字:
| 指标 | Voyager | AutoGPT | ReAct | Reflexion |
|---|---|---|---|---|
| 160轮发现物品数 | 63 | 19 | 18 | 16 |
| 解锁木质工具 | 17轮 | 260轮 | - | - |
| 解锁石质工具 | 32轮 | 272轮 | - | - |
| 解锁铁质工具 | 64轮 | - | - | - |
| 解锁钻石工具 | ✓ | ✗ | ✗ | ✗ |
Voyager 是唯一解锁钻石级别的方法。而其他三个方法,在 160 轮内甚至都没摸到铁器时代。
为什么差距这么大?
- ReAct/Reflexion 困在"低级循环"里:它们对"探索"这种抽象目标无从下手,经常重复做同一件事
- AutoGPT 的子任务执行会卡住:虽然能分解目标,但执行每个子任务时没有技能积累
- Voyager 有复利效应:学会的技能可以复用,后期进展越来越快
地图遍历能力
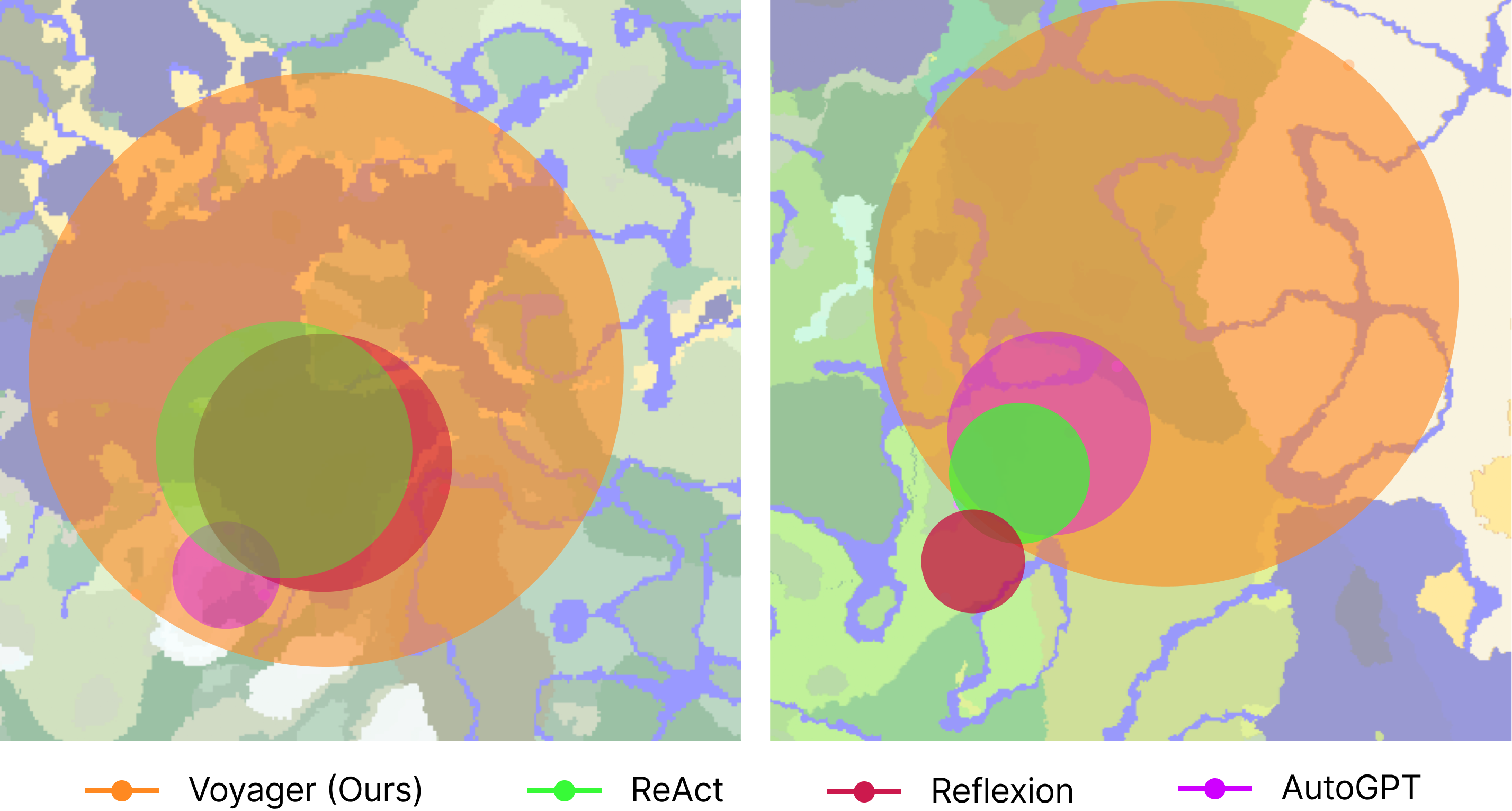
图6:各方法的地图遍历范围对比——Voyager 探索的区域明显更广
这张图直观展示了各方法的探索范围。Voyager(红色)遍历的区域是其他方法的 2.3 倍。它不仅在原地打转,而是真的在"探索世界"。
零样本泛化能力
这是最硬核的测试:把学到的技能迁移到全新的世界,执行从未见过的任务。
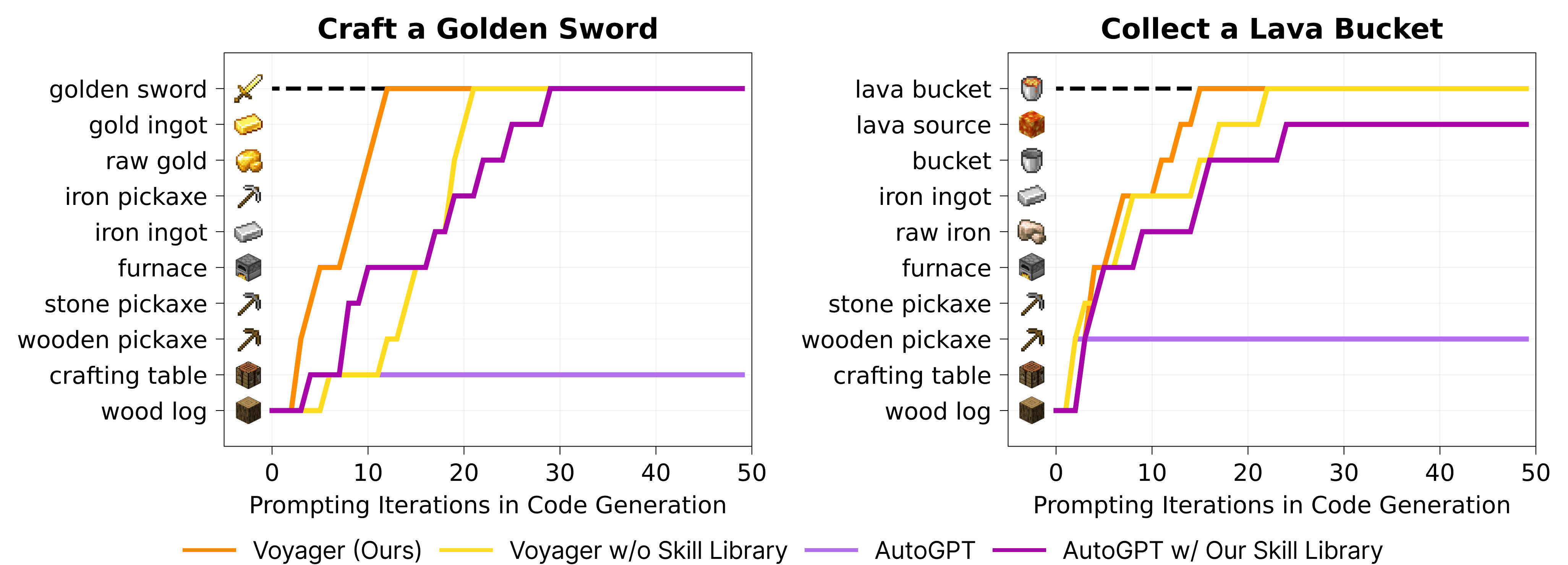
图7:零样本泛化测试——在新世界中解决未见任务的成功率
测试任务包括:
- 用铁剑杀僵尸
- 制作并装备钻石胸甲
- 把小麦和牛奶放进箱子
结果很有意思:
| 方法 | 成功率 |
|---|---|
| Voyager (带技能库) | 100% |
| Voyager (不带技能库) | 20% |
| AutoGPT (带 Voyager 技能库) | 60% |
| AutoGPT (不带技能库) | 0% |
两个重要发现:
- 技能库是核心资产:没有技能库的 Voyager 和 AutoGPT 都很挣扎
- 技能库可以跨方法共享:Voyager 学到的技能,AutoGPT 也能用
🔬 消融实验:哪个模块最重要?
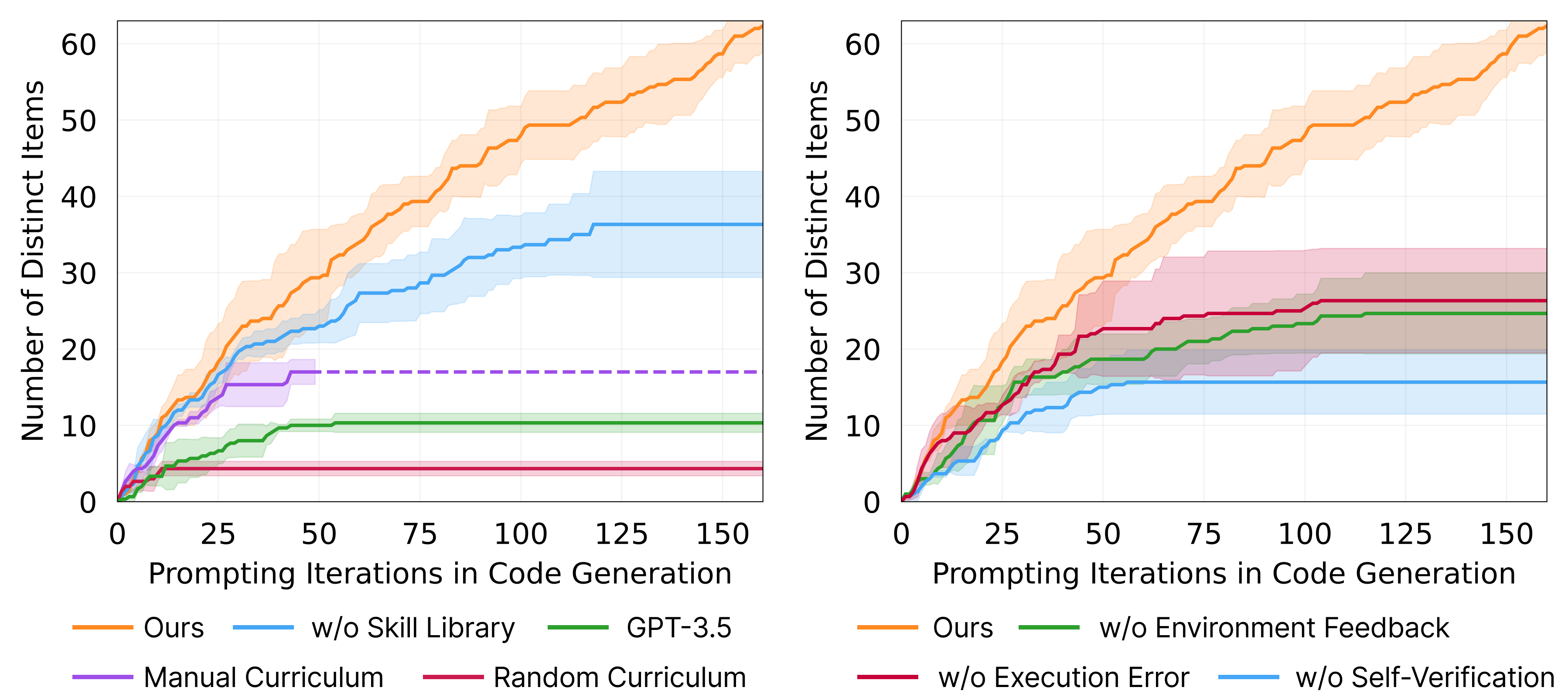
图8:消融实验——移除各模块后的性能下降程度
作者系统地测试了每个设计决策的贡献:
| 消融设置 | 发现物品变化 | 分析 |
|---|---|---|
| 随机课程(替换自动课程) | -93% | 任务太难或太简单都会卡住 |
| 移除技能库 | -46% | 后期没法复用,只能重新学 |
| 移除自我验证 | -73% | 不知道成功没成功,乱改代码 |
| 移除环境反馈 | -23% | 改代码时没有方向 |
| 移除执行错误 | -16% | 语法错误靠猜 |
| 用 GPT-3.5 替代 GPT-4 | -82% | 代码生成质量暴跌 |
几个关键发现:
自动课程是生命线:随机布置任务基本等于废了。好的课程设计让智能体始终在"舒适区边缘"学习。
自我验证比想象中重要:没有验证模块,智能体经常"自我感觉良好"但实际没完成任务,导致技能库里存的都是错误代码。
GPT-4 的代码生成能力不可替代:GPT-3.5 在复杂任务上的代码质量差太多,导致连锁反应——代码差 → 任务失败 → 没新技能 → 后续任务更难。
🤔 我的观点与讨论
为什么 Voyager 能 work?
回头看,Voyager 的成功并不意外。它踩中了几个关键点:
1. 把 LLM 当"通才"用,而不是"专才"
大多数研究喜欢微调 LLM 让它专精某个任务。Voyager 反其道而行——GPT-4 什么都干一点:规划、写码、验收。这种全栈式使用反而释放了 LLM 的潜力。
2. 用代码作为"外部记忆"
LLM 的上下文窗口是有限的,但代码可以无限积累。这相当于给 LLM 装了一个无限容量的长期记忆。
3. 闭环反馈
"生成代码 → 执行 → 反馈 → 改进"的循环让系统可以自我纠错。这比单次生成可靠得多。
潜在局限性
成本问题:每次迭代都要调用 GPT-4 API。作者在论文里也坦承,跑完整个实验的 API 成本不低。对于需要大规模训练的场景,这个成本可能不可接受。
幻觉问题:GPT-4 有时会提出不可能完成的任务。比如在沙漠里建议"去找一棵橡树"。这需要额外的检查机制来过滤。
对 API 的依赖:Voyager 完全依赖 GPT-4 的能力。如果 API 响应变慢或者能力退化,整个系统就会受影响。没有本地模型的备选方案。
仅限单人游戏:目前的设计没有考虑多智能体协作或对抗场景。
工程落地建议
如果你想把 Voyager 的思想用到自己的项目:
1. 技能库是最值得借鉴的
不管是做 RPA、游戏 AI 还是自动化测试,"把成功的操作存成代码片段"这个思路都适用。关键是设计好检索机制。
2. 自我验证很关键
不要相信 LLM 的"自信心"。用另一个模型或规则系统来验证输出,能显著提高可靠性。
3. 迭代比单次更稳
给 LLM 改错的机会。把反馈信息(尤其是错误信息)喂回去,让它修正。
对后续研究的启发
Voyager 发表后,LLM Agent 领域迎来了爆发。我们现在看到的很多设计——工具调用、记忆系统、反思机制——多少都能在 Voyager 里找到影子。
它证明了一件事:不需要训练专门的神经网络,通过巧妙的 Prompt 工程和系统设计,通用 LLM 就能展现出惊人的具身智能。
这对做 Agent 研究的人来说是个好消息:门槛降低了。但同时也意味着,真正的差异化得在系统设计上下功夫,而不是比谁有更多 GPU。
📊 与其他方法的对比总结
| 特性 | Voyager | ReAct | Reflexion | AutoGPT |
|---|---|---|---|---|
| 自主任务提议 | ✓ | ✗ | ✗ | 部分 |
| 技能复用 | ✓ | ✗ | ✗ | ✗ |
| 代码生成 | ✓ | ✗ | ✗ | 部分 |
| 自我验证 | ✓ | ✗ | 部分 | ✗ |
| 迭代改进 | ✓ | 部分 | ✓ | 部分 |
| 终身学习 | ✓ | ✗ | ✗ | ✗ |
| 零样本泛化 | ✓ | ✗ | ✗ | ✗ |
🔗 相关资源
- 论文:https://arxiv.org/abs/2305.16291
- 项目主页:https://voyager.minedojo.org/
- 代码:https://github.com/MineDojo/Voyager
- MineDojo 框架:https://minedojo.org/
💡 要点回顾
-
三大核心模块:自动课程(自己给自己布置作业)、技能库(把学会的技能存成代码)、迭代提示(代码出错就改)
-
关键创新:用 GPT-4 同时担任规划者、执行者和验收者,不需要微调模型
-
核心优势:技能可复用、可组合,产生复利效应;零样本迁移到新世界
-
实验结果:发现物品 3.3x,解锁钻石级别的唯一方法,行进距离 2.3x
-
最大贡献:证明了 LLM 驱动的具身智能体可以实现真正的终身学习,而不只是"做完一个任务就退休"
这篇论文来自英伟达首席科学家 Jim Fan 团队,发表后迅速成为 AI Agent 领域的经典之作。它不仅在 Minecraft 里取得了亮眼的实验结果,更重要的是提出了一套完整的、可复用的智能体设计范式。如果你在做 LLM Agent 相关的研究或产品,Voyager 的三模块架构绝对值得仔细研读。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献61条内容
已为社区贡献61条内容

所有评论(0)