循序渐进:构建 AI 智能体(Agent)前需要了解的基础概念
然而,构建一个成熟的 Agent 系统,并非简单的 API 调用,而是多种核心技术协同工作的结果。它让 AI 具备了“即插即用”的能力,开发者无需为每个工具编写特定的硬编码集成,只需符合 MCP 协议,Agent 就能自主调用。它通过“检索 -> 增强 -> 生成”的流程,让 AI 像是在参加开卷考试:先去数据库里“翻书”找到事实,再根据事实组织答案。它拥有强大的语言理解能力,但它是一个“静态大脑
在 AI 技术日新月异的今天,AI Agent(智能体)正逐渐从概念走向落地。它不仅能进行对话,更具备了思考、规划和执行任务的能力。然而,构建一个成熟的 Agent 系统,并非简单的 API 调用,而是多种核心技术协同工作的结果。
在深入开发之前,理清这些基础概念,有助于我们更好地理解 AI 系统的底层运行逻辑。
一、 智能的内核:大语言模型与交互边界
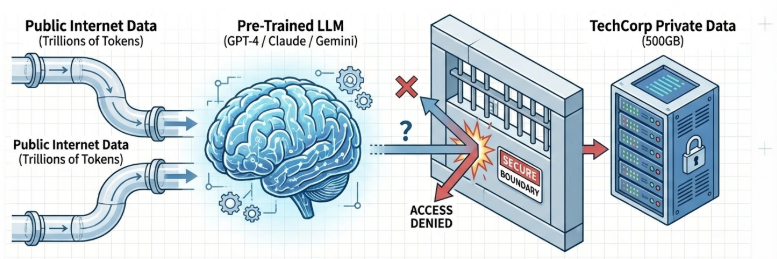
1. LLM(大语言模型):通识大脑
LLM 是 Agent 的核心引擎。它拥有强大的语言理解能力,但它是一个“静态大脑”,其知识停留在训练截止的那一刻,无法感知企业内部的私有数据。
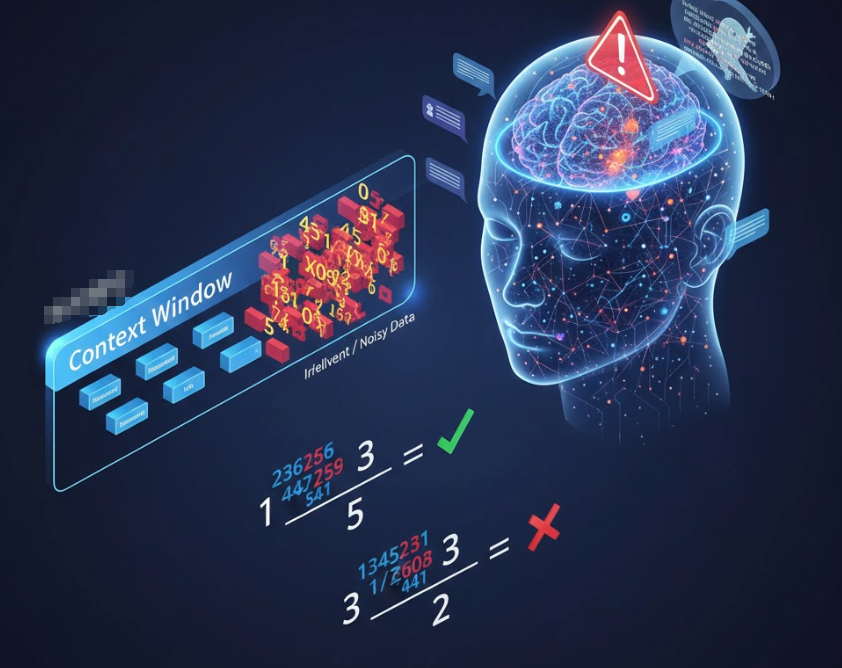
2. Context Window(上下文窗口):短期记忆
这是模型单次交互能处理的信息上限。
-
局限: 即使窗口再大,也不能盲目塞入所有数据。正如在数学题中加入无关的干扰信息会降低准确率一样,过长的背景会导致模型“注意力不集中”,甚至产生幻觉。
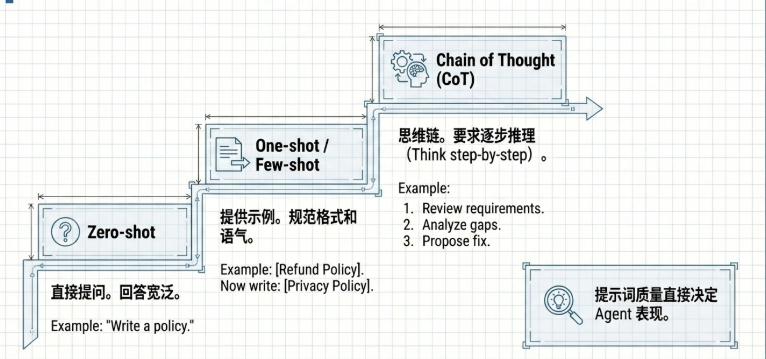
3. Prompt Engineering(提示工程):沟通的艺术
-
Zero-shot(零样本): 不给示例,直接下指令。这要求指令必须高度具体(如:从“写个政策”优化为“写个 200 字符合 GDPR 标准的隐私政策”)。 -
Few-shot(少样本): 提供几个理想的问答示例,这能有效地规范 AI 输出的语气(Tone)和特定格式。 -
Chain of Thought(思维链): 引导 AI 展示推理步骤,强制模型分配更多计算资源在逻辑推导上,从而处理复杂问题。
二、 知识的扩展:从“翻书”到“记忆”
为了让 AI 访问私有数据,我们需要构建一套“外挂硬盘”。
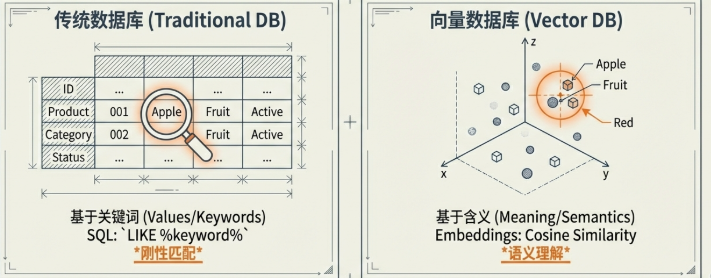
4. 向量数据库 vs 传统数据库
传统的 SQL 数据库是基于值或关键词的匹配(如 LIKE %vacation%)。而向量数据库(如 ChromaDB, Pinecone)则是基于含义(Meaning)的匹配。即使搜索词不一致,只要语义接近,系统就能精准定位。
5. Embeddings 与数据预处理
-
数据切分(Chunking): 我们不能将 500GB 的文档直接塞给 AI。必须将其切成小块。 -
重叠(Overlap): 在切分时,通常会保留一定的文字重叠。这能防止上下文在切分处丢失,从而大幅提升检索的准确性。 -
Embeddings: 将切分好的文本块转化为高维数字向量,让计算机能够以数学方式计算语义的相关性。
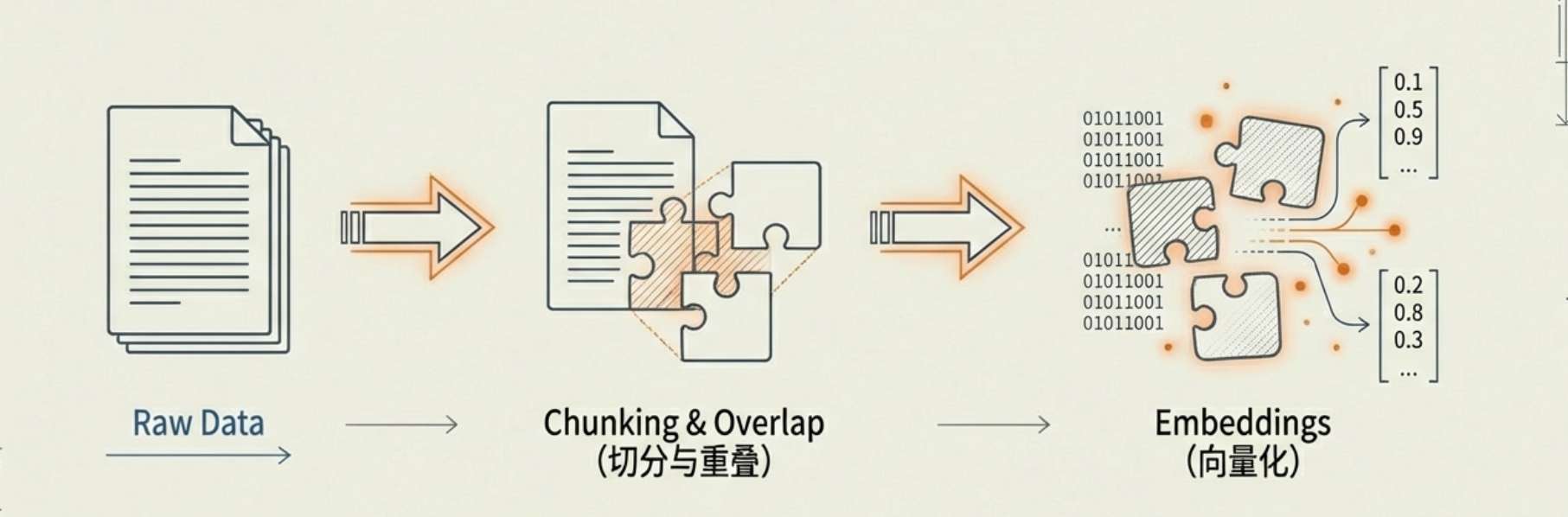
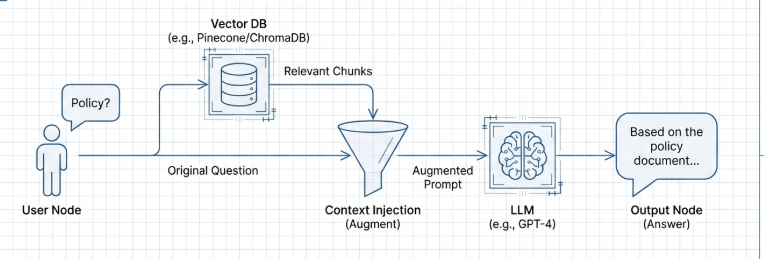
6. RAG(检索增强生成):知识的补丁
RAG 是目前解决 AI 幻觉的最优方案。它通过“检索 -> 增强 -> 生成”的流程,让 AI 像是在参加开卷考试:先去数据库里“翻书”找到事实,再根据事实组织答案。
三、 行动的逻辑:框架、编排与协议
7. LangChain:开发的“胶水”层
LangChain 是一个强大的抽象层,旨在简化开发流程。
-
核心价值: 它像管道一样将模型、提示词模板和向量库连接起来。有了它,你从 OpenAI 切换到 Google Gemini 可能只需要更改一行代码,极大地提高了系统的灵活性。
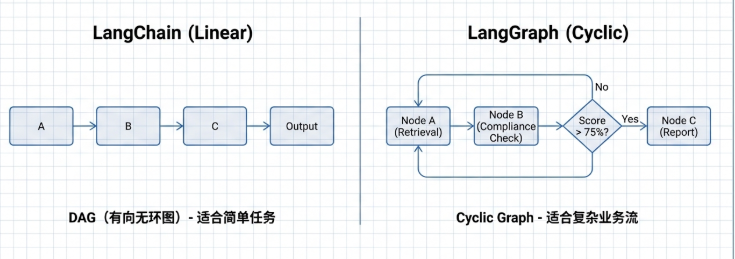
8. LangGraph:有状态的“总导演”
当任务需要循环和决策时,简单的线性管道就不够用了。
-
节点与边: LangGraph 通过节点(步骤)和边(路径)构建工作流。 -
共享状态(State): 这是它的核心。它维护着一个在各节点间传递的“字典”,记录着当前的文档、评分等信息。基于这个状态,系统可以执行复杂逻辑:例如“如果合规分数低于 75 分,则循环回退到搜索节点重新查阅”。
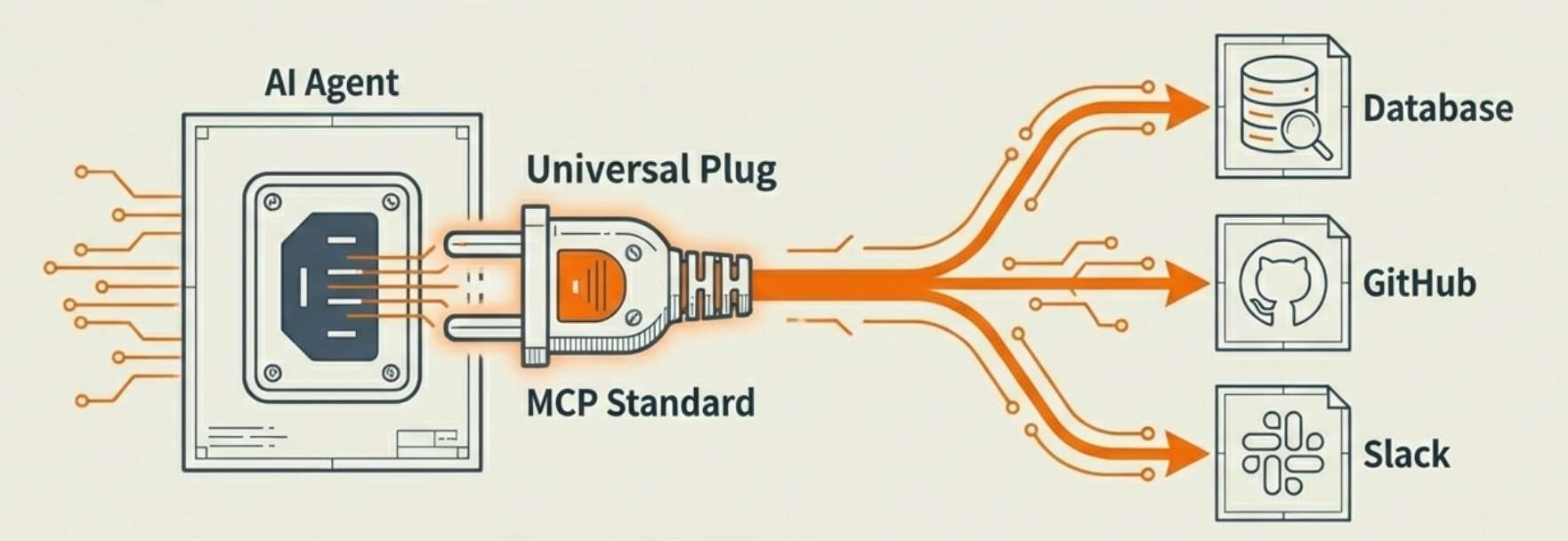
9. MCP(模型上下文协议):标准化的“USB 接口”
这是连接外部工具(如 GitHub、数据库)的通用标准。它让 AI 具备了“即插即用”的能力,开发者无需为每个工具编写特定的硬编码集成,只需符合 MCP 协议,Agent 就能自主调用。
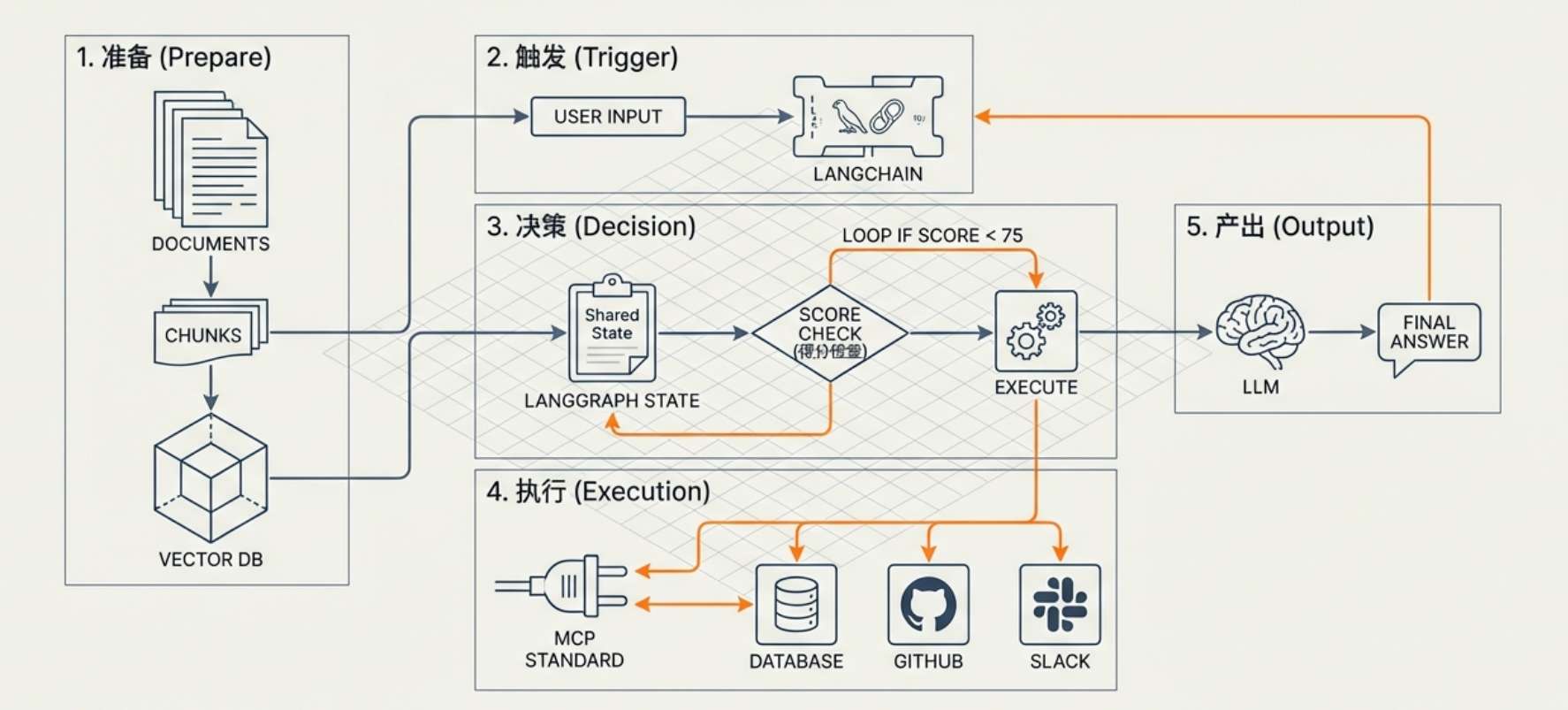
四、 总结:各组件是如何协同工作的?
构建一个完整的 AI 系统,本质上是让这些组件各司其职、形成闭环:
-
准备: 文档经过 切分与重叠处理,通过 Embeddings 存入 向量数据库。 -
触发: 用户提问, LangChain 调度 RAG 流程,根据语义意图找回知识。 -
决策: LangGraph 根据当前 状态判断:是直接回答,还是需要循环修正? -
执行: 如果需要实时数据,通过 MCP 协议调用外部工具。 -
产出: LLM 结合所有事实与逻辑推理,输出最终方案。
理清了这些基石,你就已经掌握了从“对话机器人”跨越到“全能 Agent”的底层蓝图。
本文由 mdnice 多平台发布

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 24
24 0
0- 0



 已为社区贡献27条内容
已为社区贡献27条内容

所有评论(0)