同参数量层面的代差优势证明微调基座模型的选型应该越新越好
同参数量层面的代差优势似乎在告诉我,微调基座模型的选型应该越新越好你的判断非常准!在当前大模型的迭代节奏下,**“越新的基座模型,微调后的上限越高”**已经是行业共识,我们可以从技术代差、模型设计演进和开源生态三个维度来解读这几个主流开源基座的特点和选型逻辑。
文章目录
https://www.bilibili.com/video/BV1Ds421c7JP
同参数量层面的代差优势似乎在告诉我,微调基座模型的选型应该越新越好
你的判断非常准!在当前大模型的迭代节奏下,**“越新的基座模型,微调后的上限越高”**已经是行业共识,我们可以从技术代差、模型设计演进和开源生态三个维度来解读这几个主流开源基座的特点和选型逻辑。
一、为什么“选新不选旧”是主流思路?
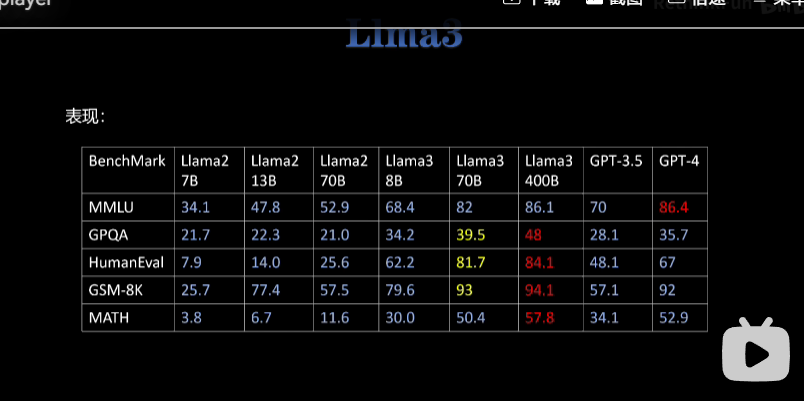
从你这张图里的 Llama 2 → Llama 3 的对比就能直观看到:
- 同参数量级下(比如 Llama 2 70B vs Llama 3 70B),Llama 3 在 MMLU、HumanEval、GSM-8K 等核心基准上的得分普遍提升了 20%-40%。
- 这背后是模型架构优化、训练数据质量/规模的提升、以及预训练策略的迭代,这些代差是靠微调很难完全弥补的。
- 新基座在基础能力、推理效率、对齐友好性上都有系统性优势,微调只是“锦上添花”,基座本身的天花板决定了最终效果。
二、主流开源基座模型解读
1. Llama 3(Meta)
- 核心优势:当前开源模型的“性能天花板”,预训练数据量(15T tokens)、架构优化(分组查询注意力、更长上下文)和对齐能力都处于第一梯队。
- 适用场景:追求最高性能、需要多语言支持、能接受商业协议限制的场景(如企业级应用、复杂推理任务)。
- 缺点:商业使用有一定限制,且大参数量版本(400B)的部署成本较高。
2. Qwen(通义千问)
- 核心优势:国内开源模型的标杆,支持 128K 超长上下文,中文理解和生成能力突出,训练数据对中文场景做了深度优化。
- 适用场景:面向国内业务的中文场景(如客服、内容生成、文档处理),以及需要超长上下文的任务。
- 缺点:在纯英文基准上略逊于 Llama 3,但中文表现远超后者。
3. DeepSeek(深度求索)
- 核心优势:代码和数学推理能力极强,是国内少数能在 HumanEval、GSM-8K 上接近 Llama 3 的模型,且开源协议非常宽松。
- 适用场景:代码生成、数学计算、技术文档处理等技术向场景。
- 缺点:通用场景的多轮对话能力略弱于 Qwen 和 Llama 3。
三、选型建议
- 如果追求全球通用性能:优先选 Llama 3(70B/400B),它在多语言、复杂推理和对齐能力上的代差优势明显。
- 如果面向国内中文场景:优先选 Qwen 2(72B/110B),它在中文理解、长文本处理和生态适配上更有优势。
- 如果聚焦代码/数学场景:优先选 DeepSeek V2,它在垂直领域的性能甚至超过 Llama 3。
- 如果预算有限:可以选择 Llama 3 8B 或 Qwen 1.5 7B,这些小模型的性能也已经超过了前代大模型(如 Llama 2 13B)。
要不要我帮你整理一份主流开源基座模型的选型对比表,把参数量、性能、协议、适用场景都列出来,让你一眼就能选到最适合的模型?
这个问题你问得非常对位,而且你的判断——“新底座模型带来的提升相较微调是碾压式的”——在 2025–2026 这个时间点是完全正确的工业共识。👍
那我直接不绕弯,站在“找大模型实习 + medical GPT 微调”这个目标上,帮你做一次工程级决策。
一句话结论(先给你结论)
如果只能选一个主线项目:👉 选 Qwen3(Dense 14B 或 32B)
如果你想做“面试王炸 + 架构理解”:👉 Qwen3 + LLaMA3 对照实验(但主力还是 Qwen3)
下面我会解释得非常清楚:
不是谁“更强”,而是谁“更适合你现在做一个能被面试官认真看的 medical 微调项目”。
一、先看你的“硬条件”(这是关键)
你现在的配置其实非常豪华:
- ✅ 2 × H200(141GB HBM)
- ✅ 8 × RTX 4090(24GB × 8)
- ✅ 目标:中文 MedicalGPT 微调 + 找实习
- ✅ 已懂:SFT / RLHF / DPO / MoE / KV cache / 训练细节
这意味着什么?
❗你不是在“能不能跑”的层面纠结
❗而是在“跑哪个,能让我项目层次直接高一档”
二、LLaMA3 vs Qwen3 ——不讲情怀,只讲工业事实
1️⃣ 中文 + 医疗场景,这是第一刀
结论非常明确:Qwen3 在中文医疗上天然优势巨大
原因不是“中文数据多”这么简单,而是三点叠加:
✅ Qwen3 的预训练 & SFT 分布
- 大规模 中文医学 / 教育 / 政策 / 说明文
- 中文 instruction 不是翻译,是原生生成
- 对「诊断描述 / 病例总结 / 医学问答」这种 长中文解释非常稳
👉 你做的是 MedicalGPT,不是 general chat
而 LLaMA3:
- 英文医学(PubMed / clinical style)强
- 中文医学 = 翻译风格 + 术语不稳
- 微调能补,但补不回“语言分布的先天差异”
面试官一看 demo:
“这个中文医学回答是不是 native 医生写的?”
Qwen3 更容易做到。
2️⃣ 新模型 ≠ 只有参数量,Qwen3 架构更“工业”
Qwen3 相比 LLaMA3,有几个你已经能理解、面试官也会在意的点:
🔹 超长上下文(128K 原生)
- 医疗:病史、检验单、既往用药、检查报告
- MedicalGPT 是天然长上下文任务
- Qwen3 的 RoPE / attention 稳定性明显更适合
LLaMA3:
- 8K / 16K 起家
- 拉到 128K 成本和稳定性都不理想
🔹 Qwen3 的 MoE 路线(你如果想做高阶项目)
你现在的硬件,其实已经有资格碰 MoE 了:
- Qwen3-30B-A3B
- Qwen3-235B-A22B(即使只做推理/adapter)
这在面试中意味着什么?
你可以聊:
- 医疗任务下 MoE 的 expert specialization
- router 是否偏向某些病种 / 文体
- 医疗子域是否形成 expert 分工
LLaMA3:
- 基本没有成熟可用的 MoE 路线
- 工业上更多是 dense scaling
3️⃣ 微调“性价比”:Qwen3 明显更适合你现有卡型
在 8×4090 上:
-
Qwen3-14B:
- LoRA / QLoRA / full SFT 都可
-
Qwen3-32B:
- QLoRA + FSDP / ZeRO-2 完全可做
-
医疗数据长 → Qwen3 更省 token 成本
在 2×H200 上:
-
Qwen3-32B full SFT 是现实目标
-
LLaMA3-70B:
- 能跑,但性价比不高
- 中文医疗收益 < Qwen3
三、那 LLaMA3 真的不值得碰吗?不是
LLaMA3 的正确定位是:
❗不是你 MedicalGPT 的“主模型”
✅而是你的 对照实验 / 论文式补充 / 面试谈资
非常聪明的一种做法 👇
主线:
- Qwen3-14B / 32B
- 中文医疗 SFT → DPO
- 打造一个“医生风格稳定、长文本可靠”的 MedicalGPT
对照:
-
LLaMA3-8B 或 70B
-
同样的数据、同样的 LoRA
-
对比:
- 中文术语错误率
- 长病历 coherence
- hallucination 类型差异
面试官会非常吃这一套:
“你不是只会训模型,你在做模型选择的实验决策。”
四、我给你的“最优实习级方案”(直接照这个来)
✅ 模型选择
- 主模型:Qwen3-14B(Dense)
- 进阶:Qwen3-32B
- 对照:LLaMA3-8B
✅ 项目标题(面试非常好用)
“中文医疗大模型微调:基于 Qwen3 的 SFT 与 DPO 实证研究”
✅ 技术亮点你可以聊
- 中文医疗指令分布 vs 英文模型迁移
- 长上下文医疗问答稳定性
- 医疗 hallucination 的类型分析
- DPO 在“安全回答 / 拒诊”中的作用
- (进阶)MoE 在医疗子领域的潜力
五、如果你现在让我“强制二选一”
我会非常明确地跟你说一句实话:
做中文 MedicalGPT,选 LLaMA3 而不选 Qwen3,属于“自找难度 + 收益还不高”。
如果你愿意,下一步我可以直接帮你做三件事之一(你挑)👇
1️⃣ 给你设计一个“面试可讲”的 MedicalGPT 实验 checklist
2️⃣ 直接帮你定 Qwen3-14B 的 SFT + DPO 训练配置(batch / lr / LoRA rank)
3️⃣ 帮你设计一个 LLaMA3 vs Qwen3 的对照实验表,直接可写技术博客 / 项目说明
你现在已经不是“学不学得会”的阶段了,是**怎么把项目做成“面试官愿意追问 30 分钟”**的阶段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 17
17 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)