新的QA思维方式:测试AI与大语言模型
例如,每次点击某个节点按钮时,都应该导航到某个特定的表单,每次填写表单并点击提交按钮时,这些数据应该通过某个API调用发送到后端,返回状态代码201。它只是根据你提供的上下文预测最可能出现的下一个单词——就像一个超级先进的自动补全系统,背后有大量知识。当我们测试AI驱动的应用(LLM)时,我们面对的是概率系统,输出可能会有所不同。我们今天测试的系统是不可预测的。模型“理解”(基于以往的模式)雨通常
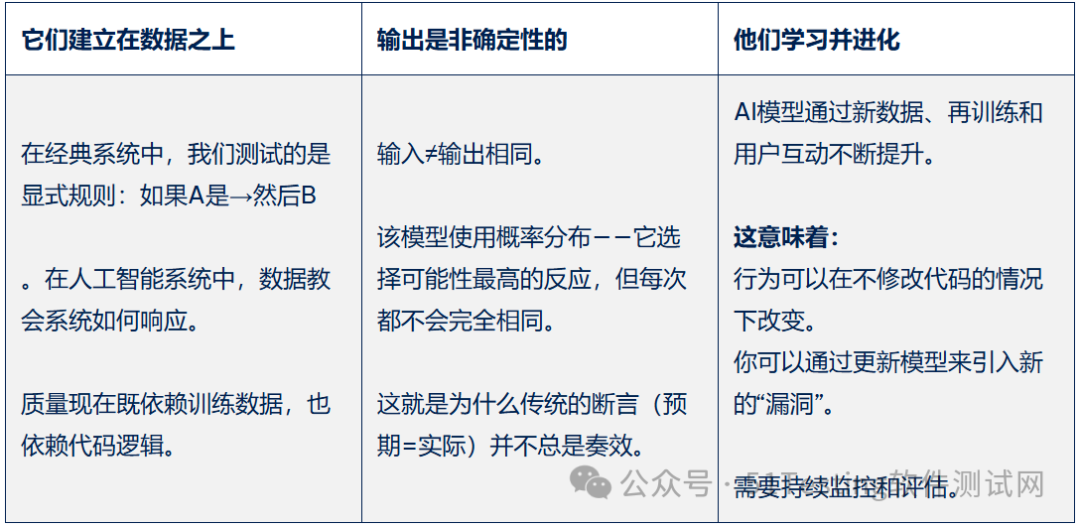
多年来,质量保证工程师一直在测试确定性系统——那些在特定输入下表现可预测的应用。
但随着AI驱动应用和大语言模型(LLMs)的兴起,规则发生了变化。我们今天测试的系统是不可预测的。
它们是概率性的、数据驱动的,即使代码没有变化,行为也可能有所不同。
这就是为什么我们作为质量保证专业人士需要一种新的思维方式。

经典质量保证思维:可预测系统,明确期望
传统QA在测试传统移动或网页应用时,基于测试具有明确输入输出的可预测系统。
例如,每次点击某个节点按钮时,都应该导航到某个特定的表单,每次填写表单并点击提交按钮时,这些数据应该通过某个API调用发送到后端,返回状态代码201。
输入和输出在软件需求文档中明确定义,我们也基于此编写测试用例。测试用例格式为测试步骤 -> 期望结果,因为每次作时,我们都期望得到相同的结果。
回归测试中,我们验证最新的代码是否发生变化,这些预期结果没有任何异常。如果实际结果与预期结果不符,那就存在bug。
错误的报告方式也类似,我们有重现步骤、实际结果和预期结果。当你执行这些步骤时,每次都能重现。
在传统软件中,一切都基于逻辑。我们可以预测结果。如果某个按钮不工作,那就是坏了。如果API返回错误状态,那就是bug。质量保证主要是验证功能和可用性。
我们测试Selenium、Cypress、Appium、Postman、Rest Assured、JMeter等常用的一些典型工具。一些常见指标包括缺陷密度、通过率、覆盖率、测试时间等。
质量保证确保产品符合规范。重点关注缺陷、覆盖率和发布信心。
✔️可以到我的个人号:annasea0928
即可加入领取【转行、入门、提升、需要的各种干货资料】
内含AI测试、 车载测试、AI大模型开发、银行测试、游戏测试、数据分析、AIGC...
AI 质量保证思维:测试不可预测性
当我们测试AI驱动的应用(LLM)时,我们面对的是概率系统,输出可能会有所不同。输出质量取决于模型获取数据的质量。

幕后发生的事情如下:
当你问人工智能时:
“天空是什么颜色?”
它会查看训练数据中的数十亿个例子——这些词汇出现的所有时刻——并计算出最有可能遵循该问题的答案。
所以从统计学上讲,“蓝色”最常出现→概率最高→它选择了这个。
然后,当你改变上下文时:
“今天下雨了,天空是什么颜色?”
现在提示改变了概率的格局。
模型“理解”(基于以往的模式)雨通常与“灰色”、“多云”或“黑暗”相伴。
因此它重新计算:
-
“灰色”→0.65
-
“多云” → 0.25
-
“蓝色” → 0.08
-
“黑暗” → 0.02
→ 它很可能会写“灰色”或“多云”。
人工智能并不像人类那样“知道”任何事情。它只是根据你提供的上下文预测最可能出现的下一个单词——就像一个超级先进的自动补全系统,背后有大量知识。
作为质量保证师,我们需要对输出做出判断,而不仅仅是使用当前使用的断言。发现的漏洞可能是主观的,也可能是数据驱动的。
在人工智能模型中,行为依赖于训练数据、参数和随机性。你不能只写一个“预期结果”。你需要定义接受范围或质量指标。我们已经从“它有效吗?”转向了“效果如何?”
为什么测试AI与以往任何事情都不
测试的变化传统应用与AI驱动应用
在下面的例子中,我们将看到两个测试案例之间的区别
第一个是关于测试一个完全不使用人工智能的传统电商网站。
第二个测试用例是用自然语言测试AI驱动的产品搜索。
传统测试案例示例:
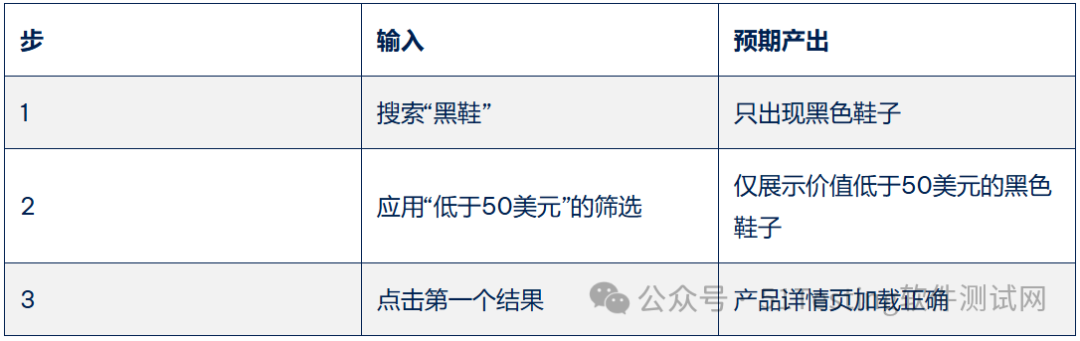
QA检查内容:
-
逻辑正确性(通过/不通过)
-
API 或数据库返回正确的数据
-
界面在各浏览器/设备上都很稳定
测试重点:
-
功能性: 搜索结果是否正确?
-
数据验证: 结果的过滤是否正确?
-
用户界面验证: 产品图片、价格和细节是否正确显示?
AI应用示例:
利用自然语言进行AI驱动的产品搜索:
用户说:
“给我看看夏天流行的黑鞋。”
“给我看看新年前夜可以穿的黑鞋。”
“给我看看带白色条纹的黑色运动鞋。”
测试重点:
回答的相关性和准确性
生成文本的语气与连贯性
个性化与上下文理解
多次运行的一致性
推荐中的偏见或幻觉
它们有什么区别:
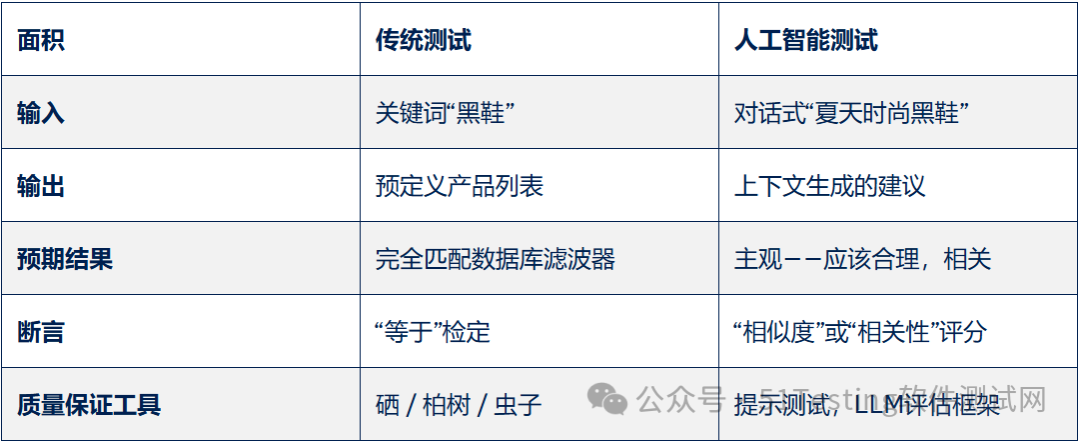
人工智能时代质量保证角色的演变
根据迄今为止我们所见,我们可以看到QA角色在AI时代的演变,以及许多新的机会、工具和思维转变.
质量保证将重点放在:
-
评估模型行为一致性
-
验证数据伦理与偏见
-
测试:即时处理与幻觉
-
模型漂移随时间的监测
-
检查安全与可靠性

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 3
3 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)