揭秘 AlphaGo 的大脑:一文读懂蒙特卡洛树搜索 (MCTS):10 步通关教程
网上关于 MCTS(蒙特卡洛树搜索)的原理讲解很多,但能从直觉到公式,再到代码落地讲透的却很少。本文将分 10 个章节,像剥洋葱一样拆解 MCTS。我们要抛弃复杂的深度学习框架,仅用纯 Python,从最基础的“多臂老虎机”原理讲起,推导 UCB 公式,直到手写出一个完整的、能玩井字棋的 AI。无论你是 DRL 初学者还是想探究 AlphaGo 原理的开发者,这篇文章都能带你彻底通关。
前言
网上关于 MCTS(蒙特卡洛树搜索)的原理讲解很多,但能从直觉到公式,再到代码落地讲透的却很少。本文将分 10 个章节,像剥洋葱一样拆解 MCTS。我们要抛弃复杂的深度学习框架,仅用纯 Python,从最基础的“多臂老虎机”原理讲起,推导 UCB 公式,直到手写出一个完整的、能玩井字棋的 AI。无论你是 DRL 初学者还是想探究 AlphaGo 原理的开发者,这篇文章都能带你彻底通关。
你将获得什么?
理解“探索与利用”的数学本质
掌握 UCB 与 PUCT 核心公式
弄懂 AlphaGo Zero 的训练闭环逻辑
弄懂一套纯 Python 实现的 MCTS 通用框架代码
第一讲:直觉与核心思想 —— 什么是“蒙特卡洛”与“树搜索”?
在进入复杂的算法之前,我们需要先建立物理直觉。蒙特卡洛树搜索(Monte Carlo Tree Search, MCTS)听起来很吓人,但拆解开来,它由两部分组成:
蒙特卡洛
树搜索
1. 什么是“树搜索”?(The Tree)
想象你在下象棋。现在的棋局是状态 A(根节点)。
-
你可以走“马”,这会变成状态 B。
-
你可以走“炮”,这会变成状态 C。
-
对手再走一步,状态 B 又会分叉成 B1, B2...
这就像一棵不断生长的树。
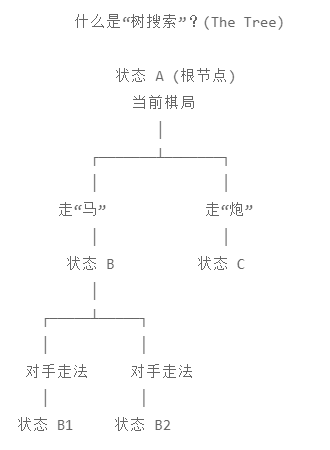
传统搜索的困境: 在围棋或复杂的即时战略游戏中,这棵树太大了。如果你想用“穷举法”算出每一步的输赢,可能宇宙毁灭了你还没算完第一步。这就是维度的诅咒。我们需要一种更聪明的方法,只搜索那些“最有希望”的分支。
2. 什么是“蒙特卡洛”?(The Monte Carlo)
“蒙特卡洛”这个名字来源于著名的赌城。在计算机科学中,它代表“通过随机采样来估算结果”的方法。
直觉案例:计算圆的面积
假设一个正方形里面画了一个不规则的形状,你想知道它的面积,但你不会积分。怎么办?
你可以抓一把豆子,随机撒在这个正方形里面。
-
如果总共撒了 1000 颗豆子。
-
有 300 颗落在了那个不规则形状里。
-
那么这个形状的面积大约就是总正方形面积的 30%。
这就是蒙特卡洛方法:不追求精确解析解,通过大量的随机实验来逼近真理。
3. MCTS:两者的完美结合
现在,把上面两个概念结合起来。
MCTS 的核心逻辑是:我不需要算出这盘棋后面几百步的所有变化。我只需要让 AI 在脑海里“随机模拟”把这盘棋下完,看看谁赢了。
假设你走进一家没去过的餐厅,菜单上有 A、B、C 三道菜,你想知道哪道最好吃。
-
纯随机 (Pure Monte Carlo): 你闭着眼随机点。今天点 A,明天点 B,后天点 C。吃了 100 次后,你统计出 A 最好吃。这太慢了,而且你会吃很多次难吃的 C。
-
MCTS 的做法:
-
先试吃 A、B、C 各一次(探索)。
-
发现 A 好像挺好吃,C 很难吃。
-
接下来的 10 次里,你有 8 次点 A(利用,因为A好吃),1 次点 B(怕错怪了B),0 次点 C(C太难吃,不理它了)。
-
通过这种方式,你把有限的“胃口”(计算资源)集中在了最有希望的 A 上,同时也稍微照顾了一下 B。
-
4. 为什么 MCTS 适合强化学习?
这是最关键的认知:
-
不需要“评估函数” (Evaluation Function): 传统的国际象棋 AI 需要人类告诉它“丢了皇后扣 9 分”。但 MCTS 不需要。它只需要知道最后是赢了还是输了。这使得它非常适合那些人类很难定义“当前局势好坏”的游戏(比如围棋,或者复杂的调度任务)。
-
随时停止: 它的算法是迭代的。你想让它思考 1 秒,它就跑 100 次模拟;给它 10 秒,它就跑 10000 次模拟。时间越久,越聪明,非常灵活。
第一讲总结
-
树搜索提供了决策的结构(我该走哪一步)。
-
蒙特卡洛提供了评估的方法(通过随机把游戏玩到底,统计胜率)。
-
MCTS 就是在树的结构上,通过不断的随机模拟,逐渐把搜索重心向高胜率的分支倾斜的算法。
在第一讲中,我们建立了一个概念:MCTS 通过“模拟”未来来做决策。
现在,我们要把这个概念具体化。MCTS 并不是魔法,它是一个不断重复的死循环。在计算机思考的几秒钟内,这个循环可能会运行成千上万次。每一次循环,树就会长大一点点,AI 就会变聪明一点点。
每一次循环,都必须严格经历这四个阶段:
-
选择 (Selection)
-
扩展 (Expansion)
-
模拟 (Simulation)
-
回溯 (Backpropagation)
这是 MCTS 的灵魂。请务必把这四个词刻在脑子里。

第二讲:MCTS 的四个生命周期
1. 选择 :老马识途
一切从根节点 (Root Node) 开始。根节点代表当前的棋局。
我们需要从根节点往下走,一直走到一个还没被完全探索过的边缘节点(Leaf Node)。
-
怎么走? 在已经探索过的区域,我们不能瞎走。我们需要一个“指南针”策略(我们会在第四讲详细学这个策略,叫 UCB)。
-
原则: 这个指南针非常聪明,它会权衡:
-
这步棋以前赢率很高,我要多走几次(利用)。
-
那步棋我还没怎么走过,虽然不知道好坏,但也得去看看(探索)。
-
在这个阶段,AI 就像一个熟练的向导,沿着树上已有的路径快速下潜,直到走到路的尽头。

2. 扩展 (Expansion):开疆拓土
当你通过“选择”阶段走到了路的尽头(比如节点 A),如果节点 A 代表的游戏还没结束,我们就要扩展它。
-
动作: 看看在节点 A 的状态下,下一步有哪些合法的走法?(比如可以向左走,也可以向右走)。
-
造树: 我们在节点 A 下面创建一个或多个新的子节点(比如节点 B 和 节点 C)。
-
注意: 通常我们在一次循环中只扩展一步(只加一个子节点),或者把所有子节点都加上但只选一个进入下一步。为了简单理解,你可以认为我们在树的边缘长出了一个新的树枝。

3. 模拟 (Simulation):快速推演
这是“蒙特卡洛”发挥作用的时刻。
现在我们停在刚刚长出的新节点(比如节点 B)上。从这一刻起,我们不再进行复杂的思考,而是开启快进模式。
-
怎么做? 让两个虚拟的玩家(或者是 AI 自己分饰两角)从节点 B 开始,随机地把这盘棋下完。
-
随机策略 (Rollout Policy): 这里的下棋通常是完全随机的(Random),或者只带一点点简单的启发式规则。目的是快。
-
结果: 游戏结束,分出胜负。比如:黑棋赢了。
这就像你在脑海里快速过电影:“如果我走到这一步,后面大家都乱下,最后谁会赢?”

4. 回溯 (Backpropagation):更新情报
模拟结束了,我们得到了一个结果(比如:+1 代表赢,-1 代表输,0 代表平局)。
现在,最关键的一步来了。我们不能只把结果记在刚才那个新节点(节点 B)上,我们要告诉它的祖宗们。
-
动作: 从刚才那个新节点 B 开始,沿着刚才“选择”阶段下来的路径,原路返回,一直退回到根节点。
-
更新: 路径上的每一个节点,都要更新它的统计数据:
-
访问次数 (N): 加 1。
-
累计分数 (W): 加上刚才模拟的结果(比如赢了就加分)。
-
为什么这很重要?
因为如果节点 B 赢了,那么它的父节点 A 也会觉得“选 B 是个好主意”,A 的父节点也会跟着沾光。这就是价值信息的反向传递。

第二讲总结
MCTS 不是一次成型的,它是通过成千上万次 选择 -> 扩展 -> 模拟 -> 回溯 的循环,让那棵树(记忆)越来越庞大,数据越来越精准。
一个核心疑问: 在第 1 步“选择”中,我提到了一个“指南针”策略,既要选胜率高的,又要选没尝试过的。这听起来很矛盾,到底怎么平衡?数学上怎么实现?
这个难题不仅仅存在于围棋里,也存在于你的人生中。这就是 “探索与利用” 的矛盾。
为了解决这个问题,我们需要引入一个著名的思想实验:多臂老虎机问题 。
第三讲:多臂老虎机问题 (MAB)
1. 什么是“多臂老虎机”?
想象一下,你站在赌场的一排老虎机面前。
-
单臂老虎机 (One-Armed Bandit): 老式老虎机有一个拉杆(手臂),拉一下,可能吐钱,也可能吃钱。
-
多臂 (Multi-Armed): 现在你面前有 K台老虎机。每一台的吐钱概率(中奖率)都不一样,而且你完全不知道哪台高、哪台低。
你的目标: 你只有 100 个硬币(代表有限的时间或计算资源),你想赢走最多的钱。
2. 那个永恒的矛盾
每当你投入一枚硬币时,你都面临灵魂拷问:
-
选择一:利用 —— “吃老本”
-
你刚才试了一下第 1 台机器,赢了 10 块钱。
-
想法: “这台机器好像很旺!为了稳赚,我应该把剩下的硬币全投给它。”
-
风险: 也许第 1 台机器平均回报只有 10 块,而第 2 台机器其实是“超级大奖机”,平均回报 100 块。如果你不试,你永远不知道自己错过了 100 块。这就叫陷入局部最优。
-
-
选择二:探索 —— “尝鲜”
-
你决定不管那台赢钱的机器,去试一试还没碰过的第 3 台、第 4 台机器。
-
想法: “万一旁边那台更好呢?”
-
风险: 也许第 3、4 台全是坏机器。你把宝贵的硬币浪费在了垃圾机器上,导致最后总收入很低。
-
这就是 MAB 问题:
我们如何分配有限的次数,既能充分利用已知的好机器赚钱,又能分出一部分精力去探索未知的机器,以免错过潜在的大奖?
3. MCTS 中的“老虎机”在哪里?
你可能会问:“这跟下围棋有什么关系?”
关系太大了!MCTS 的每一个节点,都是一个 MAB 问题。
想象我们在树的根节点,轮到黑棋走。
-
黑棋有 3 种可能的走法(A, B, C)。
-
这 3 种走法,就是 3 台老虎机。
-
我们进行一次“模拟”并得到输赢结果,就是拉了一下杆并获得了奖赏。
在“选择”阶段(Selection),AI 站在节点上,看着下面的子节点,它就在思考:
-
“走 A 这一步(第一台老虎机),之前的模拟显示胜率是 60%。”
-
“走 B 这一步(第二台老虎机),之前的模拟显示胜率是 55%。”
-
“走 C 这一步(第三台老虎机),我从来没走过,数据是 0。”
如果是你是 AI,你选谁?
-
选 A?也许 B 其实是 80% 胜率,只是刚才运气不好输了几次导致数据偏低?
-
选 C?虽然它是未知的,但也代表着无限可能(或者是个大坑)。
4. 解决思路:乐观面对未知
在这个领域,有一个非常迷人的解决哲学,叫做 “面对不确定性时的乐观主义” 。
它的核心逻辑是: 如果一台机器我玩得很少(不确定性高),我就假设它是一台绝世好机器(乐观),直到现实狠狠地打我的脸(随着尝试次数增加,发现它其实不咋地),我才降低对它的评价。
这不仅仅是心理学,这是可以被数学公式量化的。我们需要一个公式,给每个子节点打分。这个分数包含两部分:
![]()
如果你一直赢(胜率高),分就高。
如果你很久没人理(陌生度高),我也给你加分,强行把你选出来试一试。
第三讲总结
-
MAB 问题模拟了在有限尝试次数下,如何平衡收益和探索。
-
MCTS 的本质就是把一盘棋分解成无数个嵌套的 MAB 问题。
-
我们需要一种策略,能自动平衡已知胜率和未知潜力。
这就是著名的 UCB (Upper Confidence Bound) 算法。 它是 MCTS 的大脑,也是 AlphaGo 的核心组件之一。
第四讲:UCB 公式详解 —— MCTS 的数学大脑
1. 我们的目标
回顾上一讲:我们站在父节点上,面前有几个子节点(几台老虎机)。我们需要给每个子节点打一个分数 (UCB Value),然后选择分数最高的那个去探索。
这个分数必须体现我们在第三讲里说的哲学:
![]()
2. 那个著名的公式:UCB1
它是 MCTS 代码中最重要的一行:
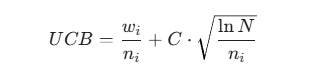
第一部分:利用项 (Exploitation Term)
-
:这个子节点赢了多少次 (Wins)。
-
:这个子节点被访问了多少次 (Visits)。
-
含义: 这就是平均胜率。
-
如果下这里赢得多,这一项就大。
-
这代表了“吃老本”,倾向于选最好的招。
-
第二部分:探索项 (Exploration Term)
这是最天才的设计。
-
:父节点(也就是当前局面的上一级)的总访问次数。
-
-
:自然对数(增长得很慢,但一直在增长)。
-
:探索参数 (Exploration Parameter)。这是一个常数,由你决定(通常设为
或 1.414,但在实际工程中需要调整)。
这一项是如何工作的?请看分母 :
-
如果你经常访问这个子节点,
-
因为
-
结论: 随着你对一个节点越来越熟悉,你的“好奇心加分”就会逐渐消失。
再看分子 :
-
只要模拟还在继续,父节点的访问次数
-
这意味着,所有子节点的“好奇心加分”都在微微上涨。
-
结论: 哪怕一个子节点之前被证明很烂(胜率低),只要过了很久没人理它,分子
变大,它的 UCB 分数也会慢慢回升,最终超过那个胜率高的节点,逼着 AI 哪怕是去“扫一眼”那个被冷落的节点。
3. 一个直观的数值演示
假设现在 C = 1.414。父节点总共被访问了 100 次 (N=100)。
有两个可选的动作:A 和 B。
-
动作 A(明星选手):
-
访问了 80 次,赢了 60 次。
-
胜率 = 60/80 = 0.75 (75%)
-
因为访问次数多 (n_i=80),探索项分母大,好奇心加分很少。
-
-
-
动作 B(冷门选手):
-
只访问了 20 次,赢了 10 次。
-
胜率 = 10/20 = 0.50 (50%)
-
胜率远不如 A。但是!因为它访问少 (n_i=20),探索项分母小,好奇心加分很高。
-
-
结果:
虽然 A 的胜率 (0.75) 远高于 B (0.50),但 UCB 算法算出 1.18 > 1.09。
决策: MCTS 这次会选择 动作 B!
为什么? 因为系统觉得:“动作 B 虽然看起来一般,但我们对它了解太少了(才20次),也许它是个潜力股?为了保险起见,再去测一次 B 吧!”
4. 探索参数 C 的玄学
公式里的 C 是唯一的调节旋钮:
-
如果 C 很大(比如 5): 探索项权重极大。AI 会像个好奇宝宝,不停地尝试那些没走过的冷门招数,哪怕胜率很低。这会导致搜索很广,但很难收敛到最优解。
-
如果 C 很小(比如 0.1): 探索项几乎无效。AI 会变得极其保守,稍微发现一步好棋就死盯着不放,完全忽略其他可能性。
-
最佳实践: 理论值为
第四讲总结
UCB 公式完美地解决了“该选谁”的问题。 它不是静态的,它是动态平衡的:
-
刚开始,大家都没被访问过,分母为 0(程序里通常设为无穷大),所以 MCTS 会把每一步都先尝试一遍。
-
接着,它会盯着胜率高的走。
-
一旦胜率高的那一步走得太多了,探索项变小,它就会转头去看看那些被冷落的分支。
有了这个公式,我们的选择 阶段就完成了。
但是,当我们选好了一个节点,并在后面扩展了新节点后,我们需要进行 模拟 。模拟是怎么进行的?是不是真的要瞎下棋?
第五讲:模拟 与 默认策略
经过前面几讲的铺垫,我们已经选好了一条路,并且迈出了探索性的一步(扩展了一个新节点)。现在,我们需要回答一个关键问题:这一步到底好不好?
在传统的国际象棋 AI(如 Deep Blue)中,我们需要写一个超级复杂的“评估函数”,通过分析兵力、位置、兵形来打分。 但在 MCTS 中,我们不需要懂围棋或象棋的深奥理论。我们要用最粗暴但也最有效的方法:实践出真知。
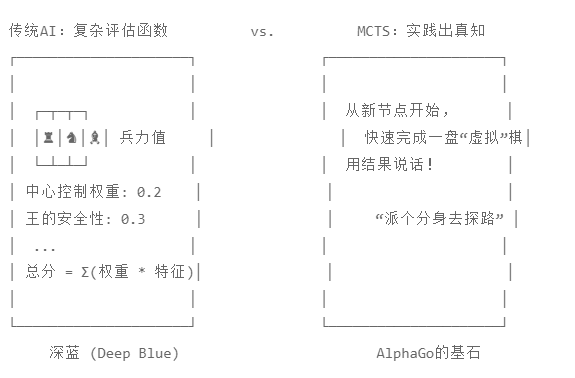
这就是 模拟 (Simulation),行话也叫 Rollout(滚落/推演)。
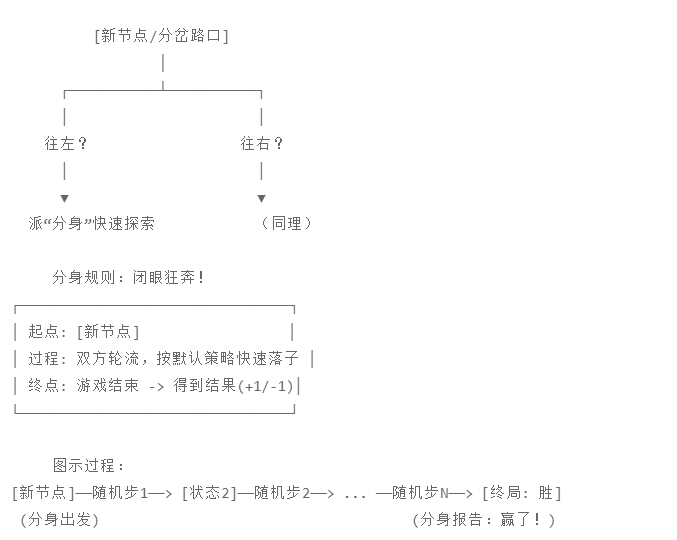
1. 什么是模拟?
想象你正在玩一个迷宫游戏,走到了一个分岔路口。你不知道往左走是不是死胡同。 MCTS 的做法是:派一个跑得极快的“分身”,闭着眼睛从左边这条路冲进去,一路狂奔,直到撞墙(输)或者找到出口(赢)。
-
起点: 刚刚扩展出来的那个新节点(叶子节点)。
-
过程: 双方(黑棋和白棋)轮流下子。
-
终点: 游戏结束(分出胜负,或平局)。
2. 默认策略 (Default Policy):分身怎么思考?
在这个快速奔跑的过程中,我们的分身怎么决定下一步走哪里?这就涉及到了 “策略” (Policy)。
在模拟阶段使用的策略,我们通常称为 默认策略 (Default Policy) 或 Rollout Policy。
A. 纯随机策略 (Pure Random) —— “乱拳打死老师傅”
这是最基础的 MCTS 版本。
-
规则:
next_move = random.choice(legal_moves) -
描述: 就像两个 2 岁的小孩在下围棋,完全不懂定式,随手乱放。
-
优点: 极快! 计算机每秒可以跑几万次。
-
缺点: 棋局质量极差。
-
为什么能行? 虽然单次模拟很蠢,但如果你跑了 1 万次,你会发现:那些会导致你瞬间被杀死的“臭棋”,胜率会自然地掉下去;而那些能让你活得久一点的棋,胜率会浮上来。大数定律在此显灵。

B. 启发式策略 (Heuristic / Heavy Playout) —— “带点脑子”
纯随机有时候太离谱了(比如在象棋里送帅给对面吃)。所以我们在工程实践中,通常会加一点点“常识”。
-
规则: 优先选吃子的步;优先抢占中心;如果你叫杀我,我必须防守。剩下的再随机。
-
优点: 模拟结果更接近人类高手的对局,评估更准。
-
缺点: 慢! 计算每一条规则都要花时间。这会减少每秒模拟的次数。

核心权衡 (Trade-off):
模拟数量 vs. 模拟质量 是要在 1 秒钟内跑 1000 次“垃圾”模拟,还是跑 100 次“高质量”模拟? 对于 MCTS 来说,通常数量更重要。不要让你的模拟策略太重,否则就失去了 MCTS 的灵活性。
3. 模拟什么时候结束?
通常有两种情况:
-
游戏终局 (Terminal State): 比如五子棋连成 5 子,围棋双方停手数子,象棋帅被吃。这是最理想的,因为胜负是确定的(Reward = +1 或 -1)。
-
步数限制 (Cutoff): 有些游戏太长了(比如 DOTA 2 或超长回合的策略游戏),跑到底太慢。我们可能会设定:只往后推演 50 步。如果还没分出胜负,就用一个简单的函数估算一下当前的优劣。

4. 这一步的关键直觉
初学者常有的疑惑:“如果后面都是乱下的,那最后的结果还有参考价值吗?”
答案是有。 想象一场足球赛。如果在第 80 分钟,你的队伍 3:0 领先。 虽然接下来的 10 分钟如果是“乱踢”(双方都瞎跑),你有可能会被追回一球,但大概率你还是会赢。 MCTS 的模拟就是在这个逻辑下运行的:如果当前的局势真的很好(稳健),那么即使后面在“乱玩”,获胜的概率依然很大。如果当前局势很险(摇摇欲坠),乱玩很容易导致崩盘。

第五讲总结
-
模拟就是不再造树,而是快速把游戏下到底。
-
默认策略决定了怎么下到底。通常是随机为主,规则为辅。
-
目的是为了获得一个信号 (Reward):从这一步开始,到底能不能赢?
现在,我们的分身跑到了终点,裁判举起了旗帜(比如:黑棋胜,+1 分)。 但是,这个“+1 分”现在还只停留在模拟结束的那个遥远的未来。 我们需要把这份喜悦(或悲伤),传达给刚才做决定的那个节点,以及它的所有祖先。
第六讲:反向传播
在上一讲中,我们的分身在“模拟”阶段一路狂奔,终于跑到了游戏的终点(例如:黑棋赢了,获得 +1 分)。
现在,最重要的一刻来了。这个好消息不能只留在终点,必须让当初做出决定的“老祖宗”节点们都知道。这就像是一个前线侦察兵发现了金矿,必须跑回指挥部汇报,这样指挥官下次才会派更多人往这个方向走。
这个过程叫 反向传播 (Backpropagation),或者叫 Backup。
1. 我们的任务:修路
还记得我们在第 1 步“选择”和第 2 步“扩展”时走过的那条路径吗?
反向传播就是沿着这条路径原路返回,直到根节点。
在这条路径上的每一个节点,都需要更新两个数值(还记得 UCB 公式里的那两个变量吗?):
-
N (Visits): 访问次数。
-
W (Win Score): 累计得分。
2. 更新逻辑:非常简单
假设刚才的模拟结果是:黑棋赢 (+1)。
我们从叶子节点开始,一步步往上爬:
-
对于路径上的每一个节点:
-
: 无论输赢,这个节点都被多“路过”了一次,所以访问次数必然 +1。
-
: 把刚才的模拟结果 v 加到累计得分里。
-
这就完了?
对于单人游戏(比如推箱子、魔方),这就完了。但对于双人博弈(围棋、象棋),这里有一个巨大的陷阱,也是初学者最容易写出 Bug 的地方。
3. 核心难点:视角的切换 (The Perspective Flip)
请集中注意力。
在双人对战中,黑棋的胜利 (+1),对白棋来说意味着什么?意味着失败 (-1)。
MCTS 的树结构中,层级通常是交替的:
-
根节点 (Root): 轮到黑棋走。
-
第一层 (Layer 1): 黑棋走了一步后,变成了轮到白棋走的局面。
-
第二层 (Layer 2): 白棋应了一步后,又变成了轮到黑棋走的局面。
当我们拿着“黑棋赢 (+1)”的结果往回跑时:
-
遇到“黑棋刚走完”产生的节点:
-
这个节点代表黑棋做了一个选择。
-
结果黑棋赢了。
-
评价: 好棋!W 增加 (+1)。
-
-
遇到“白棋刚走完”产生的节点:
-
这个节点代表白棋做了一个选择。
-
结果黑棋赢了(也就是白棋输了)。
-
评价: 臭棋!W 减少 (或者加 0,或者加 -1,看你怎么定义)。
-


两种常见的处理方式(代码实现时选其一):
-
方式 A(最直观 - 绝对坐标): 所有节点都只记录“黑棋赢了多少次”。
-
计算 UCB 时:如果是轮到黑棋走,就选胜率最高的;如果是轮到白棋走,就选胜率最低的(因为白棋想让黑棋输)。
-
-
方式 B(最通用 - 相对坐标): 每个节点记录的都是“当前刚走这一步的那个玩家”的胜率。
-
我们在回溯时,每往上一层,就把分数的符号翻转一次(Negate)。
-
黑棋赢了 (+1) -> 传给上一层白棋节点变成 (-1) -> 再传给上一层黑棋节点变成 (+1)。
-
好处: 计算 UCB 时不需要判断是谁的回合,永远选分数最高的。AlphaZero 用的就是类似的逻辑。
-
所以当我们评估一个节点时:
如果当前是黑棋走:选择子节点中胜率最高的
如果当前是白棋走:选择子节点中胜率最低的(对黑)
= 选择胜率最高的(对自己)
通过符号翻转,我们可以统一为:总是选择价值最高的节点
4. 为什么要更新 N 和 W?
回想一下第四讲的 UCB 公式:
-
当你更新了 W:节点的平均胜率 (W/N) 变了。如果赢了,分子变大,下次被选中的概率提高(利用)。
-
当你更新了 N:分母变大,平均胜率变得更“置信”了;同时,它的探索加分项会因为分母变大而减小。
这就是 MCTS “自我修正” 的机制。
一次模拟可能说明不了什么(运气成分),但随着反向传播成千上万次,N 越来越大,W/N 就会精准地逼近这步棋的真实胜率。
第六讲总结
至此,MCTS 的完整一圈生命周期我们都跑通了!
-
Selection: 用 UCB 挑一条路走到底。
-
Expansion: 在尽头长出一个新树枝。
-
Simulation: 乱跑一阵子直到分出胜负。
-
Backpropagation: 带着胜负结果原路返回,告诉沿途的所有节点“好评”或“差评”。
这四个步骤,在 AI 思考的 1 秒钟内,会疯狂循环几千次。
当时间到了,AI 只需要看一眼根节点下面的子节点:谁的 $N$(访问次数)最大,我就走谁。
(注意:最终决策通常看谁被访问最多次,而不是看谁胜率最高,因为访问次数多意味着最“经得起考验”)。
现在的你,已经掌握了 MCTS 的所有核心组件。
但是,你可能会问:“这东西真的比传统的 Alpha-Beta 剪枝搜索(Minimax)好吗?为什么围棋以前用 Minimax 怎么都赢不了,换了 MCTS 突然就神了?”
这涉及到了两者本质的思维差异。
第七讲:MCTS vs 传统搜索 (Minimax)
欢迎来到第七讲。
这一讲我们稍微停下代码实现的脚步,来聊聊历史与战略。
这非常重要。如果不理解 MCTS 到底革了谁的命,你就不知道为什么它如此伟大。
你可能听说过:
-
1997 年,IBM 的 Deep Blue(深蓝) 击败了国际象棋世界冠军卡斯帕罗夫。
-
但直到 2016 年,AlphaGo 才击败围棋世界冠军李世石。
中间这 19 年,人类在等什么?为什么深蓝那套算法对围棋没用? 答案就在于 Minimax(极小化极大算法) 与 MCTS 的本质区别。
1. 传统霸主:Minimax (极小化极大搜索)
在 MCTS 出现之前,所有的棋类 AI(象棋、跳棋、五子棋)几乎都用 Minimax。
它的逻辑是“全知全能的穷举”:
-
广度优先: 哪怕这步棋看起来很蠢,我也要算一下,万一它是妙手呢?
-
固定深度: 我算这盘棋未来的 10 步。
-
评估函数 (Evaluation Function): 到了第 10 步,游戏还没结束,我必须用一个数学公式给局面打分(比如:车=5分,马=3分,多一个子+2分)。
为什么它在围棋面前崩盘了?
致命伤一:树太宽了 (Branching Factor)
-
国际象棋: 平均每一步有 35 种走法。
-
围棋: 平均每一步有 250 种走法。
如果你想往后算 10 步:
-
象棋需要算
个节点。虽然很大,但在超级计算机能接受的范围内。
-
围棋需要算
个节点。这比地球上沙子的数量还多。算不完,根本算不完。这已经超出不知多少个数量级了。
致命伤二:无法写出“评估函数”
在国际象棋里,如果我吃你一个马,我大概率是赚的。 但在围棋里,“势” 怎么算?黑棋在这个角落虽然死了 3 个子,但它在外围形成了一堵“厚势”,这价值多少分? 在 AlphaGo 出现前,人类写了几十年代码,都写不出一个靠谱的围棋局面打分公式。
2.MCTS (蒙特卡洛树搜索)
MCTS 的出现,彻底绕过了上面两个死穴。
破解致命伤一:不对称生长 (Asymmetric Tree)
Minimax 像是一个强迫症,要把每一层都铺满才肯往下走。 MCTS 则是偏科生。 还记得 UCB 公式吗?它引导 MCTS 只盯着那些胜率高的分支疯狂往下钻,而那些一看就很蠢的分支,它只试探一两次就扔在一边了。
结果: MCTS 的搜索树长得非常**“畸形”**——在这个 19x19 的棋盘上,好的走法后面那根树枝长得非常深,而不好的走法后面几乎没有树枝。这让它能在有限的时间里算得更深。
破解致命伤二:无需评估函数
这是 MCTS 最性感的地方。 它不需要人类告诉它“提掉一子得 2 分”。它只关心一件事:赢了没? 通过 模拟 (Simulation) 把棋下到底,它直接拿到了最终结果。它把极其复杂的“局势判断”问题,转化成了简单的“统计学”问题。
| 特性 | Minimax (深蓝/传统象棋 AI) | MCTS (早期围棋 AI/AlphaGo) |
| 搜索方式 | 广度优先:每一层尽量铺开 | 最佳优先:盯着好棋往死里算 |
| 树的形状 | 胖而短(全面但浅) | 瘦而长(专注且深) |
| 如何判断局势 | 依赖专家知识 (硬编码的评估函数) | 依赖统计数据 (随机模拟的胜率) |
| 适用场景 | 状态空间小、易于量化优劣的游戏 (象棋) | 状态空间巨大、难以量化优劣的游戏 (围棋) |
| 直觉类比 | 计算器:严谨推导 | 人类直觉:我也说不清为什么,但感觉这步能赢 |
早期的 MCTS(2006年左右)虽然不需要评估函数,但它的“模拟”阶段是随机的(乱下)。这导致它的水平大概只有业余 5 段左右,依然打不过职业选手。
真正的奇点发生在科学家们开始思考:
-
“如果我们在 MCTS 的‘选择’和‘模拟’阶段,不再瞎蒙,而是用神经网络来指导它,会怎么样?”
这一思考,直接诞生了 AlphaGo。
AlphaGo 并不是抛弃了 MCTS,而是给 MCTS 装上了两只天眼(策略网络和价值网络)。
第七讲总结
-
Minimax 输在太“死板”,试图穷尽所有变化,且依赖人类经验。
-
MCTS 赢在“灵活”,利用概率论集中资源搜索重点,且不依赖人类定义的价值。
-
MCTS 实际上是一种更像人类思考的算法:我们会忽略那些显而易见的臭棋,专注于推演那几步关键的杀招。
下一讲,我们将进入理论篇的最高潮。我们将揭开 AlphaGo 的架构,看看它是如何把 深度学习 (Deep Learning) 和 MCTS 融合在一起的。
第八讲:迈向 AlphaGo —— MCTS 与神经网络的结合 (PUCT)
在前七讲中,你已经掌握了 MCTS 的完全体。但如果只用那个版本的 MCTS(称为“纯 MCTS”),你只能写出一个稍微厉害点的 AI,绝对打不过职业选手。
为什么?因为纯 MCTS 的模拟(Rollout)太随机了,且选择(Selection)太盲目了。
AlphaGo 的出现,就是为了解决这个问题。DeepMind 的工程师们想:
“如果我们给 MCTS 装上两个神经网络,一个告诉它‘哪步棋像高手下的’,一个告诉它‘这盘棋现在谁赢面大’,那岂不是无敌了?”
于是,PUCT (Predictor + UCB Applied to Trees) 诞生了。
1. 两个大脑:策略网络与价值网络
想象你在玩一个迷宫游戏。
-
传统 MCTS (前七讲) 就像是一个勤奋的盲人跑者。它不知道哪条路对,它只能这一趟跑左边,下一趟跑右边,全靠跑到底(模拟)来看看是不是死胡同。只要跑的次数够多,它也能找到路。
-
AlphaGo 就像给这个盲人配了一个导游(神经网络)。
-
导游看一眼迷宫,凭直觉说:“左边那条路看着像死路,别去了;右边这条路看着通透,先试这条。”
-
盲人(MCTS)听了导游的话,就会优先去跑右边,而不是在那条死胡同里浪费时间。
-
这就是第八讲的核心:利用神经网络的“直觉”,来指导 MCTS 集中精力搜索最有用的地方。
1. 策略网络 (Policy Network) —— P(s, a)
-
它的角色: 它是“直觉指路人”*。
-
输入: 当前的棋盘画面(比如黑白子的位置)。
-
输出: 所有合法走法的推荐概率。
-
比如现在有 A、B、C 三个点可以下。
-
策略网络看一眼棋盘,说:
-
“下 A 的概率建议是 70%(感觉是好棋)”
-
“下 B 的概率建议是 25%(凑合)”
-
“下 C 的概率建议是 5%(臭棋)”
-
-
-
关键点: 它不需要往下算,它完全凭看过几千万局棋谱的“经验”瞬间给出建议。
2. 价值网络 (Value Network) —— V(s)
-
它的角色: 它是局势判官。
-
输入: 当前的棋盘画面。
-
输出: 一个 0 到 +1之间的数字。
-
+1 代表当前执子方必胜。
-
0 代表当前执子方必输。
-
0.8 代表胜率很大。
-
-
关键点: 它替代了传统 MCTS 里的“随机模拟”。以前我们需要随机下到终局才知道输赢,现在问一下价值网络,它直接告诉你“这盘棋目前的胜率大概是多少”。
训练这两个神经网络(策略网络 P 和 价值网络 V)经历了两个阶段的进化:
-
早期版本(AlphaGo Lee): 先跟人类学(监督学习),再左右互搏(强化学习)。
-
终极版本(AlphaGo Zero): 完全不理人类,从零开始,纯靠左右互搏。
因为 AlphaGo Zero 的训练方法最优雅、最符合第一性原理,也是现在 DRL 的主流范式,所以我重点讲解这一种。它的训练核心就是一个完美的“自举”(Bootstrapping)闭环。
核心逻辑:MCTS 是老师,神经网络是学生
你可能会困惑:“如果神经网络一开始是小白(随机参数),MCTS 也是靠神经网络指导的,那这一堆瞎子怎么能进化出高手呢?”
秘密在于:MCTS 的搜索结果,永远比单纯的神经网络直觉要“聪明”一点点。
-
神经网络 (P) 说:“我觉得 A 这步棋只有 50% 胜率。”
-
MCTS 说:“等一下,我根据你的直觉,往下多推演了 100 步,发现 A 其实是步好棋,它的真实胜率应该有 60%!”
训练的目标就是: 让神经网络去模仿 MCTS 搜索出来的那个“更聪明的结果”。
具体的训练三步走
整个训练过程是一个不断循环的圆圈:
第一步:自对弈 (Self-Play) —— 制造数据
游戏开始了。不管是黑棋还是白棋,都是同一个 AI(AlphaGo Zero)在控制。
第 1 步: 此时轮到黑棋走。
-
记录状态 (
): 你拍了一张棋盘的照片。这时候棋盘是空的。
-
MCTS 思考: 神经网络给了一些建议,然后 MCTS 开始疯狂模拟(假设模拟了 1000 次)。
-
得到 MCTS 概率 (
): MCTS 模拟结束了,它告诉你:“经过深思熟虑,我觉得下在天元(中心)的次数最多,占比 60%;下在星位的次数占比 30%;其他地方 10%。”
-
重点: 我们要把这个 [0.6, 0.3, 0.1] 记下来!这是标准答案。
-
-
落子: AI 根据这个概率,真的下了一步棋(比如下了天元)。
第 2 步: 此时轮到白棋走。
-
记录状态 (
): 你拍了一张棋盘照片(有一个黑子)。
-
MCTS 思考: MCTS 又模拟了 1000 次。
-
得到 MCTS 概率 (
): MCTS 算出白棋应对的最好分布是 [0.5, 0.4, 0.1]。
-
重点: 记下这个概率分布。
-
-
落子: AI 落子。
...... (就这样一直下) ......
第 30 步: 游戏结束,裁判宣布:黑棋赢了 (+1)。

现在这盘棋下完了,你手里的笔记本记录了 30 页内容(每一步一张照片 ,一个 MCTS 算出的概率
)。
但是,每一页还缺一个最关键的数据:这步棋到底导致了赢还是输?
因为在第 1 步的时候,我们不知道未来会赢。但现在游戏结束了,我们知道黑棋赢了。所以,我们要倒回去,给每一页补上这个结果 。
-
看第 1 页(黑棋走的): 最后黑棋赢了吗?赢了。所以这一页的 z = +1。
-
看第 2 页(白棋走的): 最后白棋赢了吗?输了。所以这一页的 z = -1。
-
看第 3 页(黑棋走的): 最后黑棋赢了吗?赢了。所以这一页的 z = +1。
好了,现在你的笔记本里有 30 条完整的数据。这就是神经网络要吃的“饭”。
每一条数据长这个样子:
我们来看一条具体的(假设是第 10 步,黑棋走的):
-
输入 (
): [棋盘的图片矩阵] —— 喂给神经网络的眼睛。
-
目标策略 (
): [0.1, 0.8, 0.1, ...] —— 这是 MCTS 算出来的“更聪明的走法”。告诉策略网络:你刚才直觉不对,应该学学 MCTS,多往这里走。
-
目标价值 (
): +1 (赢) —— 这是最终结果。告诉价值网络:在这个局面下,最后是能赢的,所以你给这个局面的打分要尽量靠近 +1。
第二步:神经网络更新 (Training) —— 消化数据
现在拿着这一堆数据,去训练那两个网络(实际上通常是同一个网络,两个输出头)。
训练策略网络 ():
目标: 让神经网络原本的预测 ,去无限逼近 MCTS 算出来的概率
。
潜台词: “神经网络啊,你刚才直觉觉得这步棋一般,但经过深思熟虑(MCTS)后发现它是好棋。下次在遇到这个局面,你的直觉要直接把这步棋的概率调高!”
训练价值网络 (V):
-
目标: 让神经网络对当前局面的打分 v,去无限逼近最终的输赢结果 z。
-
潜台词: “神经网络啊,你在第 50 手的时候觉得我们要输了,但最后我们其实赢了。下次遇到这种局面,你要更有自信,打分要高一点!”
第三步:迭代 (Evaluation & Iteration) —— 更上一层楼
-
训练完一轮后,我们得到了一个新的、更强大的神经网络。
-
关键点: 用这个更强的网络,去指导下一轮的 MCTS。
-
因为导游(网络)变强了,MCTS 就能搜得更深、更准,产生质量更高的对局数据。
-
用更高质量的数据,又训练出更更强的网络。
这就是AlphaGo Zero 的“左脚踩右脚上天”
本质就是最小化下面这个损失函数 (Loss Function):
-
:价值损失。让网络的打分
尽可能接近真实胜负
。(均方误差)
-
:策略损失。让网络的预测
尽可能接近 MCTS 的搜索结果
。(交叉熵)
-
:正则化项,防止过拟合。

第二部分:PUCT 公式
MCTS 的生命周期中,什么时候调用网络?网络吐出的数字填进了公式的哪里?
依靠这个公式:
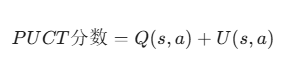
我们把这两项拆开:
1. Q(s, a):理性的数据
这和之前一样,代表平均胜率。
-
意思说:“在我(MCTS)实际搜索过的这几次里,走这一步最后赢了没?”
-
如果 MCTS 搜得越多,这个值越真实。
2. U(s, a):感性的直觉(策略网络的建议)
这是新增的,它负责把“导游”的意见加进去。
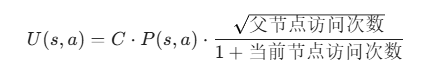
即:

你现在手里有了PUCT 公式(骨架),也有了神经网络(血肉),现在要把它们缝合在一起,变成一个会动的生命体。
结合点一:策略网络 (P) —— 决定“探索哪里”
发生阶段:扩展 (Expansion)
当 MCTS 走到一个叶子节点(以前没走过的局面)时,它非常迷茫。
这时候,我们调用 策略网络。
-
输入: 当前局面的图像
。
-
输出: 所有下一步可能的动作概率分布
。
-
例如:
{A: 0.7, B: 0.2, C: 0.1}
-
-
结合动作:
-
我们将这些概率值 直接赋值 给在这个节点下新长出的树枝。
-
从此以后,当 MCTS 下次来到这个节点,准备计算 PUCT 分数时,公式里的
就有了固定的值(就是 0.7, 0.2, 0.1)。
-
效果:
公式里的 P(s, a) 越大,PUCT 总分就越高。
这意味着:策略网络觉得好的点,MCTS 会优先去选它(哪怕还没开始搜)。
结合点二:价值网络 (V) —— 决定“这步好坏”
发生阶段:评估 (Evaluation) 与 回溯 (Backup)
同样是在那个叶子节点。以前我们要在里做随机模拟(Rollout),现在不用了。
这时候,我们调用 价值网络。
-
输入: 还是当前局面的图像
-
输出: 一个数值
-
结合动作:
-
我们拿着这个 +0.8,直接作为本次搜索的结果。
-
开始回溯 (Backup):沿着父节点一路往上跑。
-
沿途经过的所有节点,都要更新它们的累计分数 W 和访问次数 N。
-
关键点:
。
-
所以,这个 +0.8 最终改变了沿途所有节点的 Q 值。
-
效果:
公式里的 Q(s, a) 变了。
这意味着:价值网络觉得这个局面赢面大,那么通往这个局面的那步棋,Q 值就会变高,MCTS 下次就更倾向于走这里(利用)。
如何更新?
1. 纠正策略网络 (Policy Network)
-
发生情景:
-
面对一个局面,策略网络一开始凭直觉说:“我觉得下在 A 点的概率是 0.8,B 点是 0.2。” (P)
-
MCTS 说:“别急,我搜搜看。”
-
MCTS 经过 1000 次模拟,发现虽然 A 看起来好,但后面全是坑;反而是 B,虽然看着丑,但越搜越赢。
-
MCTS 最终统计出访问次数:“我搜了 A 点 100 次,搜了 B 点 900 次。所以正确的概率应该是 A=0.1, B=0.9。” (
-
-
纠正动作 (Training):
-
我们拿着 MCTS 算出的 [0.1, 0.9] 作为标准答案。
-
我们拿着神经网络算出的 [0.8, 0.2] 作为错误预测。
-
通过梯度下降 (Gradient Descent) 修改神经网络的参数,强迫它下次看到这个棋盘时,输出尽可能接近 [0.1, 0.9]。
-
2. 纠正价值网络 (Value Network)
-
发生情景:
-
策略网络说黑棋优势很大,给打分 +0.8。($v$)
-
但这盘棋下到最后,黑棋输了(结果是 -1)。($z$)
-
-
纠正动作 (Training):
-
事实胜于雄辩。现实结果 -1 是标准答案。
-
神经网络的预测 +0.8 是错误预测。
-
计算误差(Loss),修改参数,强迫神经网络下次看到类似的局面,把分打低一点(比如降到 -0.5)。
-
这个过程是不断循环的,这就是所谓的 “Policy Iteration” (策略迭代):
-
老师出题 (Self-Play): 当前的神经网络指导 MCTS 下棋,MCTS 费劲巴力地算出了每一步的“更优解”(
-
学生刷题 (Training): 神经网络拿着这些 MCTS 生产的数据进行训练,更新自己的大脑参数。
-
学生变老师 (Update): 训练后的神经网络变强了,直觉更准了。
-
下一轮 (Loop): 下一轮 MCTS 再搜索时,因为起点的“直觉”(
)变准了,它就能把计算资源花在更有意义的地方,从而搜出更更强的招数。
第九讲:代码实战 (架构篇)
我们将用 Python 从零开始构建 MCTS。为了让你专注于算法逻辑而不是被复杂的深度学习框架(PyTorch/TensorFlow)搞晕,我们将首先实现一个 “纯 MCTS” (Vanilla MCTS)。
只要这个骨架搭好了,未来要升级成 AlphaGo,只需要修改其中两行代码(一行把 UCB 改成 PUCT,一行把随机模拟改成网络预测)。
我们将代码分为三部分:
-
节点类 (
MCTSNode):树的细胞。 -
MCTS 主类 (
MCTS):树的大脑(包含 4 个生命周期)。 -
游戏接口 (Game State):为了测试,我们需要告诉 MCTS 怎么玩游戏(下一讲实现)。
今天我们先完成前两部分。打开你的 IDE(VS Code 或 PyCharm),新建一个文件 mcts_pure.py。
第一部分:设计节点类 (MCTSNode)
树是由节点组成的。每个节点代表棋局的一个状态。我们需要一个类来存储这个状态的统计数据(等)。
请看代码,每一行都有详细注释对应之前的理论:
import numpy as np
import math
class MCTSNode:
def __init__(self, parent=None, parent_action=None):
"""
初始化节点
:param parent: 父节点 (根节点的 parent 为 None)
:param parent_action: 是执行了哪个动作才来到这个节点的
"""
self.parent = parent
self.parent_action = parent_action
self.children = {} # 字典: {action: Node},存储子节点
# 核心统计数据
self._n_visits = 0 # N: 访问次数
self._q_value = 0 # Q: 平均价值 (W/N)
self._w_sum = 0 # W: 累计总分 (Win Score)
def is_fully_expanded(self):
"""是否所有合法的子节点都已经被扩展出来了?"""
# 这个逻辑稍后在 MCTS 类中结合 Game State 实现
# 这里先留个位置,或者直接判断 children 是否非空
return len(self.children) > 0
def best_child(self, c_param=1.414):
"""
【核心逻辑】选择阶段 (Selection)
根据 UCB 公式选择分数最高的子节点
:param c_param: 探索参数 C (通常取 sqrt(2))
"""
choices_weights = []
for action, child in self.children.items():
# 1. 计算 UCB 分数
# 如果该节点从未被访问过,我们需要优先尝试 (赋予无穷大)
if child._n_visits == 0:
score = float('inf')
else:
# Exploitation (利用): 平均胜率
exploit = child._q_value / child._n_visits
# Exploration (探索): 根号项
# math.log 是自然对数 ln
explore = math.sqrt(math.log(self._n_visits) / child._n_visits)
score = exploit + c_param * explore
choices_weights.append((score, child))
# 2. 返回分数最高的那个子节点
# max 的 key 设为 x[0] 即根据 score 排序
return max(choices_weights, key=lambda x: x[0])[1]
def expand(self, action):
"""
【核心逻辑】扩展阶段 (Expansion)
创建一个新的子节点
"""
# 创建新节点,父节点指向 self
new_node = MCTSNode(parent=self, parent_action=action)
self.children[action] = new_node
return new_node
def update(self, reward):
"""
【核心逻辑】回溯阶段 (Backpropagation)
更新当前节点的统计数据
:param reward: 这一轮模拟的结果 (+1, -1 或 0)
"""
self._n_visits += 1
self._w_sum += reward
self._q_value = self._w_sum / self._n_visits # 更新平均值第二部分:设计 MCTS 主流程类
有了细胞,现在我们来组装大脑。MCTS 类负责协调整个搜索过程。
我们需要一个通用的 search 函数,它会执行几千次循环,最后返回最好的那一步。
import copy
import random
class MCTS:
def __init__(self, root_state, c_param=1.414, num_simulations=1000):
"""
:param root_state: 初始的游戏状态 (Game State)
:param c_param: UCB 的探索常数
:param num_simulations: 每次思考要模拟多少次
"""
self.root = MCTSNode() # 创建根节点
self.root_state = root_state
self.c_param = c_param
self.num_simulations = num_simulations
def search(self):
"""
【主循环】执行 MCTS 搜索,返回最佳动作
"""
# 循环执行 num_simulations 次 (比如 1000 次)
for i in range(self.num_simulations):
# 1. Selection (选择)
# 从根节点出发,一直走到叶子节点
node = self.root
state = copy.deepcopy(self.root_state) # 复制一份状态用于模拟,不破坏真身
# 只要节点完全扩展了且不是终局,就一直往下走
while node.is_fully_expanded() and not state.is_terminal():
node = node.best_child(self.c_param)
state.do_move(node.parent_action) # 在模拟的状态上走一步
# 2. Expansion (扩展)
# 如果游戏没结束,且当前节点还没把所有孩子都生出来
if not state.is_terminal():
# 找出所有还没扩展的动作
# (这里假设 state 类有一个 get_legal_actions 方法)
legal_actions = state.get_legal_actions()
untried_actions = [a for a in legal_actions if a not in node.children]
if untried_actions:
action = random.choice(untried_actions) # 随机选一个去扩展
state.do_move(action)
node = node.expand(action) # 长出新树枝
# 3. Simulation (模拟/Rollout)
# 从当前状态开始,随机下到底
current_state = state # 此时 state 已经是扩展后的新状态了
while not current_state.is_terminal():
possible_moves = current_state.get_legal_actions()
action = random.choice(possible_moves) # 纯随机策略 (Default Policy)
current_state.do_move(action)
# 游戏结束,拿到结果 (比如 黑胜+1, 白胜-1)
# 注意:这里需要根据视角调整 reward (稍后解释)
reward = current_state.get_result()
# 4. Backpropagation (回溯)
# 沿着树往上爬,更新所有祖先
while node is not None:
# 关键点:视角的反转!
# 如果当前节点是“黑棋刚走完”,那它的价值应该是“黑棋的胜率”
# 我们稍后在 GameState 这一讲详细处理这个 +1/-1 的问题
# 现在先假设 update 接受绝对分数
node.update(reward)
node = node.parent
# 循环结束,选择访问次数最多的子节点作为下一步
# 注意:这里不看胜率,看访问次数 (最稳健)
return self.root.best_child(c_param=0).parent_action第九讲总结: 我们搭建了通用的 MCTS 框架。这个框架不知道自己在玩什么游戏,它只知道通过 state 接口来查询规则。这就是面向对象编程的魅力:解耦。
下一步: 我们要让这个引擎转起来。我们需要写一个简单的游戏(比如井字棋),填补上 state 的空缺,然后让两个 MCTS 互相对战,看看谁能赢。
第十讲:代码实战
这是第十讲。你已经有了 MCTS 的核心引擎(上一讲的 MCTS 类和 Node 类)。现在的它就像一台没有装轮子的法拉利引擎,空有马力却跑不起来。
这一讲,我们要给它装上轮子(接入井字棋游戏),然后亲眼看着它思考、下棋、并打败(或者打平)你。
我们将完成三个任务:
-
实现
TicTacToeState类: 告诉 MCTS 什么是“井字棋”。 -
微调 MCTS 逻辑: 解决双人博弈中“你的胜利就是我的失败”这个视角问题。
-
编写主程序: 让 AI 动起来。
第一步:定义井字棋 (TicTacToeState)
MCTS 并不关心它玩的是围棋还是井字棋,它只关心 state 对象能不能回答它的问题(有哪些动作?赢了吗?)。
我们需要实现一个类,满足上一讲代码中调用的那些接口。
新建文件 tictactoe.py(或者写在同一个文件里):
import copy
class TicTacToeState:
def __init__(self):
# 1. 棋盘:用一个长度为9的列表表示
# 0=空, 1=X(先手), -1=O(后手)
self.board = [0] * 9
self.current_player = 1 # 谁该下棋了?
def get_legal_actions(self):
"""返回当前所有空格子的索引 (0-8)"""
return [i for i, x in enumerate(self.board) if x == 0]
def is_terminal(self):
"""游戏结束了吗?(有人赢了 或 棋盘满了)"""
return self.get_result() is not None or 0 not in self.board
def get_result(self):
"""
判断胜负
:return: 1 (X赢), -1 (O赢), 0 (平局), None (没结束)
"""
# 定义所有获胜的连线组合
winning_lines = [
(0,1,2), (3,4,5), (6,7,8), # 横线
(0,3,6), (1,4,7), (2,5,8), # 竖线
(0,4,8), (2,4,6) # 对角线
]
for a, b, c in winning_lines:
if self.board[a] == self.board[b] == self.board[c] and self.board[a] != 0:
return self.board[a] # 返回赢家的标记 (1 或 -1)
if 0 not in self.board:
return 0 # 平局
return None # 没结束
def do_move(self, action):
"""执行一步动作,改变状态"""
self.board[action] = self.current_player
self.current_player *= -1 # 切换玩家 (1 -> -1, -1 -> 1)
def __repr__(self):
"""打印漂亮的棋盘"""
s = ""
chars = {0: ".", 1: "X", -1: "O"}
for i in range(3):
s += "".join([chars[self.board[i*3+j]] for j in range(3)]) + "\n"
return s第二步:修正 MCTS 的“反向传播”逻辑
在上一讲的 MCTS 类中,我在 Backpropagation 部分留了一个伏笔(关于视角反转)。现在我们需要补全它。
问题所在:
-
井字棋的结果是:+1(X赢),-1(O赢)。
-
但是 MCTS 树是分层的:
-
根节点(轮到 X 走)。
-
第一层子节点(轮到 O 走)。
-
-
如果模拟结果是 +1 (X赢):
-
对于根节点(X)来说,这是好事(Reward = +1)。
-
对于第一层子节点(O)来说,这是坏事(Reward = -1)。
-
修改代码: 我们需要修改第九讲 MCTSNode 的 expand 和 MCTS 的 search 方法。
1. 修改 MCTSNode (增加记录是谁走到了这一步):
class MCTSNode:
def __init__(self, parent=None, parent_action=None, player_just_moved=None):
# ... (之前的代码) ...
self.player_just_moved = player_just_moved # 新增:记录是谁下了这一步棋 (1 或 -1)
# ... (best_child 不变) ...
def expand(self, action, state): # 注意这里多传一个 state 参数
"""扩展时,记录是谁走了这一步"""
# 在 state.do_move 之前,state.current_player 就是即将走这一步的人
new_node = MCTSNode(
parent=self,
parent_action=action,
player_just_moved=state.current_player
)
self.children[action] = new_node
return new_node2. 修改 MCTS 类的主循环逻辑:
# ... 在 MCTS 类的 search 方法中 ...
# 2. Expansion 部分修改
if untried_actions:
action = random.choice(untried_actions)
# 注意:这里我们先 expand,记录是谁走的,然后再 do_move
# 或者把 state 传进去让 Node 自己判断
# 这里为了简单,我们传入当前玩家
player_who_is_moving = state.current_player
node = node.expand(action, state) # 传入 state
state.do_move(action)
# ... Simulation 部分不变 ...
# 4. Backpropagation 部分 (核心修改!)
reward = current_state.get_result() # 1, -1, 或 0
while node is not None:
# 关键逻辑:
# 如果赢家(reward) 等于 这个节点刚才下棋的人(player_just_moved)
# 那么对这个节点来说就是赢了 (+1)
# 否则就是输了 (-1)
if node.player_just_moved is not None: # 根节点没有 player_just_moved
if reward == node.player_just_moved:
node_reward = 1
elif reward == -node.player_just_moved:
node_reward = -1 # 输了
else:
node_reward = 0 # 平局
node.update(node_reward)
node = node.parent第三步:见证奇迹时刻 (Main.py)
把所有代码整合起来,我们要让 AI 和自己对战。
新建 run.py (或者在主文件底部):
if __name__ == "__main__":
# 初始化游戏状态
state = TicTacToeState()
# 初始化 MCTS 引擎
# 模拟次数越多,AI 越强。试试 100 和 10000 的区别。
mcts = MCTS(root_state=state, num_simulations=1000)
print("游戏开始!(X 是先手,O 是后手)")
print(state)
while not state.is_terminal():
print(f"当前轮到: {'X' if state.current_player == 1 else 'O'}")
# --- 这一步交给 MCTS 思考 ---
# 1. 把当前的局面告诉 MCTS
mcts.root_state = copy.deepcopy(state)
# 2. 因为棋局变了,我们要把树的根节点移动到当前局面
# (简单起见,我们这里每次都重置树,虽然有点浪费,但逻辑最简单)
mcts.root = MCTSNode()
# 3. 开始搜索
best_action = mcts.search()
# 4. 执行这一步
print(f"AI 决定下在位置: {best_action}")
state.do_move(best_action)
print(state)
print("-" * 20)
# 宣布结果
result = state.get_result()
if result == 1:
print("X 赢了!")
elif result == -1:
print("O 赢了!")
else:
print("平局!")运行结果预期
当你运行这段代码时,你会看到两个 AI 在互殴。
-
因为井字棋是一个必平游戏(如果双方都完美发挥),所以如果你的 MCTS 模拟次数够多(比如 >500 次),结果几乎永远是平局。
-
如果你把
num_simulations设为 10(让 AI 变傻),你会发现它们开始乱下,偶尔会有人赢。 -
你可以试着修改代码,把其中一方改成
input()输入,亲自挑战 AI! 你会发现你很难赢它。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
 19
19 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)