InternVL系列论文笔记
InternVL系列论文笔记摘要:InternVL系列是上海AILab推出的开源多模态大语言模型(MLLM),旨在缩小与商业模型的差距。该系列采用"ViT-MLP-LLM"三段式架构,核心创新在于系统性的工程优化和训练策略。
InternVL系列论文笔记
引言
在多模态大语言模型(MLLM)领域,开源模型与闭源商业模型之间仍存在显著差距。为缩小这一差距,上海人工智能实验室(Shanghai AI Lab)推出了 InternVL系列模型 —— 在通用性、推理能力、推理效率三大维度全面进化的开源 MLLM 系列。
本文为笔者阅读 InternVL2.5-3.5 文献后整理的模型架构设计与核心训练技巧,希望和相关专业的朋友一起交流分享。
InternVL 2.5
一、网络架构设计
InternVL 2.5 沿用了与 InternVL 1.5/2.0 相同的整体架构范式,即主流的 “ViT-MLP-LLM” 三段式结构,但对各组件进行了升级。
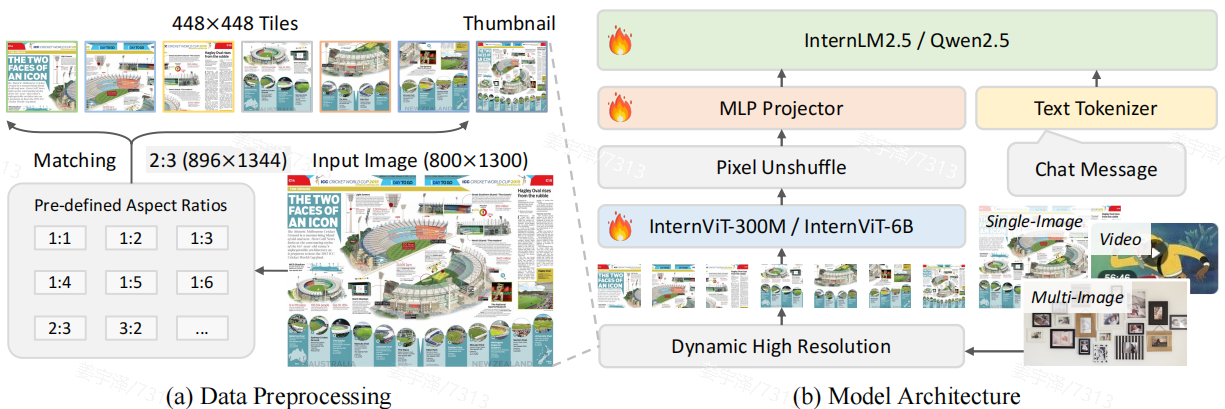
1. 整体架构(Overall Architecture)
- 范式:
视觉编码器 (Vision Encoder) → 投影层 (MLP Projector) → 大语言模型 (Large Language Model) - 输入处理:采用类似 InternVL 1.5 的 动态高分辨率(Dynamic High Resolution) 策略,将图像按预定义的宽高比划分为多个
448×448的图块(tiles),并可选地添加一个缩略图(thumbnail)以保留全局信息。 - 多模态支持:从 InternVL 2.0 起,架构扩展支持 单图、多图、视频 三种数据类型,每种类型有特定的预处理和标记方式(如
Image-1: <img>...</img>)。
2. 视觉编码器(Vision Encoder):InternViT
提供了两个版本:
- InternViT-6B
- 结构:基于标准 ViT,45 层(原为 48 层,移除了最后 3 层以保留局部信息,因为后面 3 层更多为了适配 CLIP),隐藏层维度 3200,25 个注意力头。
- 改进:引入 QK-Norm 和 RMSNorm。
- 训练演进:从最初使用 CLIP 对比损失,到后续版本通过 Next Token Prediction (NTP) 损失进行端到端联合训练,提升视觉特征提取能力。
- InternViT-300M
由 InternViT-6B 蒸馏 得到(使用 Cosine Distillation Loss)。共24 层,隐藏层维度 1024,16 个注意力头。其中的normalization层使用标准 LayerNorm,无 QK-Norm。
3. 投影层(Projector)
一个随机初始化的 2 层 MLP,用于将 ViT 输出的视觉 token 映射到 LLM 的词嵌入空间。
4. 大语言模型(LLM)
全面采用 SOTA 的开源 LLM,包括 InternLM 2.5 和 Qwen 2.5 系列。
5. 视觉 Token 压缩
在每个 448×448 图块经过 ViT 编码后,应用 Pixel Unshuffle 操作。Pixel Unshuffle 是 InternVL 2 中提出的减少 vision token 数的方法,类似于 SwinUNet 结构中的 PatchMerging 模块,将相邻像素重排到通道维度,再进行 patch encoding。这样可以不损失信息的前提下降低空间分辨率,减少encoder处理的序列长度。在实际模型中,原始的 1024 个视觉 token 被压缩为 256 个,显著降低计算开销,同时保持信息密度。
二、算法与训练策略创新
1. 多模态数据的动态高分辨率策略
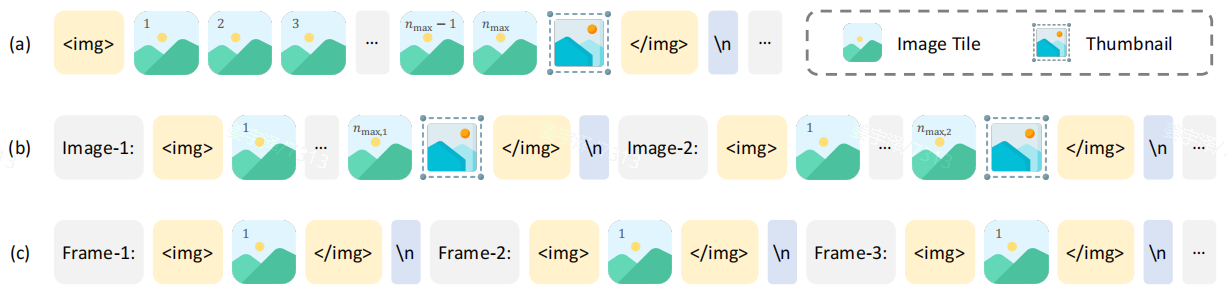
对于单张高精度图像输入,给定patch的数目限制 n m a x n_{max} nmax,将图像 resize 到 ( w × 448 , h × 448 ) (w\times 448, h\times 448) (w×448,h×448), w w w和 h h h的值在 1 n m a x 1~n_{max} 1 nmax中遍历,使得图片宽高比的变化最小。图像 token 会用 标签包含。
当输入单张高精度图片且 n m a x > 1 n_{max}>1 nmax>1的时候,图像会直接 resize 为 448 × 448 448×448 448×448,作为缩略图输入 encoder。
对于多张图片输入, n m a x n_{max} nmax会被平均分给各个图片,计算其 tile 拆分。各张图片的 token 除了i狼段的标签外,还会在标签前加上 “Image-1” 这样的辅助标签。
对于视频输入,提取的每一帧都被 resize 到 448 × 448 448\times 448 448×448,使用 标签包含,并在前面加上 "Frame-1"标记。
2. 训练策略
![[训练策略 图4]](https://i-blog.csdnimg.cn/direct/099ca46716934ce6b7ef862c1c0bab69.png)
(1) Single Model Training Pipeline
整个训练过程分为三个精心设计的阶段,以确保稳定性和高效性:
-
Stage 1: MLP Warmup
- 目标:快速对齐视觉和语言表示。
- 操作:仅训练 MLP 投影层,冻结 ViT 和 LLM。
- 策略:使用高学习率(2e-4)和动态高分辨率训练。
-
Stage 1.5: ViT 增量学习(Optional)
- 目标:增强 ViT 提取复杂领域(如 OCR、数学图表)特征的能力。
- 操作:联合训练 ViT + MLP,使用 NTP 损失。
- 优势:训练后的 ViT 可复用于不同规模的 LLM,无需重复训练(见下文“渐进式扩展策略”)。
-
Stage 2: Full Model Instruction Tuning
- 目标:使模型具备强大的指令遵循和对话能力。
- 操作:解冻全部参数,在高质量、严格过滤的指令数据上进行微调。
- 关键:强调数据质量,少量噪声数据即可导致模型行为异常(如重复输出)。
(2) Progressive Scaling Strategy
- 核心思想:先用小规模 LLM(如 20B)训练好 ViT(即上面的 Stage 1.5),再将该 ViT 直接迁移到大规模 LLM(如 72B)上。
- 优势:
- 极大节省了训练成本。例如,InternVL2.5-78B 仅使用 ~120B tokens,而 Qwen2-VL-72B 使用了 1.4T tokens。
- 实现了高效的模块化扩展,ViT 成为可复用的通用视觉感知模块。
3. 多模态数据打包策略(Multimodal Data Packing)
为提升 GPU 利用率,减少 padding 浪费,文章提出一种数据打包策略。给定总文本 token 数的限制 l m a x l_max lmax以及总图像 tile 数限制 t m a x t_max tmax,通过组合不足长度的短 sample,实现packing。
流程:
Select:将长句切分为 token 数和 tile 数符合限制的 sample,拆分后视作独立的 sample,放入 buffer list;Search:在 buffer list 中使用二分查找实施最优匹配Pack:将匹配的短句拼接成长句。这里有一个关键细节,打包后的样本内部,不同子样本的 token 不能互相 attention,且各自维护独立的位置编码。Maintain:当有拼接 sample 超过长度限制,则产出用于 training;或 buffer list 随着新 sample 添加而超容量,当前的最长序列及 tile 数最多的序列也会产出用于 training
4. Training Enhancements
- 随机 JPEG 压缩:
在训练时对图像应用质量因子 75-100 的 JPEG 压缩。目的是模拟真实网络图片的退化,提升模型对低质量图像的鲁棒性。 - 损失重加权(Loss Reweighting):
loss reweighting 策略,是针对 next token prediction 损失中不同句子的 token 数不一致的问题,一般采取 按 sample 数平均和按 token 数平均两种方式。而 InternVL2.5 居于两者之中,提出 “平方平均(Square Averaging)” 策略,权重w_i = 1 / sqrt(x),其中x是 sample 中的 token 数。
5. Data Filtering Pipeline
实验发现 LLM 对数据质量更加敏感,且模型在 CoT 推理中容易陷入重复循环这个错误模式,根源是训练数据中的“重复模式”。因此,文章执行了更加精细的数据清洗。
对于纯文本数据,执行基于 LLM 的打分,其次做基于阈值的重复检测,最后做基于其它规则的过滤(过滤异常长句、大量零值、重复行等)。对于多模态数据,执行重复检测和规则规律。
总结
InternVL 2.5 的核心创新并非来自颠覆性的网络架构,而是体现在系统性的工程优化和训练策略上。它通过:
- 模块化、可复用的视觉编码器,
- 精心设计的分阶段训练和渐进式扩展策略,
- 高效的多模态数据打包和训练增强技术,
- 极其严格的数据质量控制,
成功地在极低的训练成本(约 1/10 的 token 量)下,实现了与顶尖商业模型(如 GPT-4o)相媲美的性能,尤其是在 MMMU 等复杂推理任务上取得了突破。
InternVL 3
一、网络架构(Model Architecture)
1. 整体架构范式
遵循 “ViT–MLP–LLM” 架构范式。Vision Encoder 部分与 InternVL 2.5一样,有InternVit-300M 和 InternViT-6B 两个规模版本.MLP也沿用了2层随机初始化的MLP。LLM 采用 Qwen 2.5 和 InternLM3-8B 模型,并且都使用未经指令微调的原始模型,(以保留完整的语言能力)。对于高分辨率图片,InternVL3 沿用了 2.5 的 pixel unshuffle 操作,可以将 448 × 448 448\times 448 448×448的图片表示为256个vision tokens。
2. V2PE组件:Variable Visual Position Encoding
对视觉 token 使用更小的位置增量 δ(δ ∈ {1, 1/2, 1/4, …, 1/256}),而非传统统一 +1,可以在不扩展原有位置编码长度限度的情况下处理更长的多模态序列。 p i = p i − 1 + { 1 , if x i is a textual token , δ , if x i is a visual token , p_i = p_{i-1} + \begin{cases} 1, & \text{if } x_i \text{ is a textual token}, \\ \delta, & \text{if } x_i \text{ is a visual token}, \end{cases} pi=pi−1+{1,δ,if xi is a textual token,if xi is a visual token,当 δ = 1 \delta=1 δ=1的时候,就变回了之前版本的传统位置编码。实际推理的时候, δ \delta δ根据输入序列的长度动态选取,已平衡模型的表现和编码长度。
二、算法与训练策略更新
原生多模态训练
与之前的训练策略不同,InternVL3采用 native multimodal pre-training 的训练策略。不像以往模型先训练一个纯语言的预训练和后训练的LLM再对齐多模态。InternVL3直接将多模态数据插入文本语料,进行整体训练。当 text-only 和 multimodal 训练素材混合在一起进行参数优化,多模态对齐的效果会变得更好。并且,训练过程也取消了“先训练MLP再逐步解冻ViT、LLM的渐进方式,而是所有参数在混合数据预料上整体训练。这种训练模式在优化多模态对齐性能的同时,也提高了训练数据的利用率。
损失函数设置
L text-only ( θ ) = − ∑ i = 2 L w i ⋅ log p θ ( x i ∣ x < i ) , 其中 x i ∈ Text \mathcal{L}_{\text{text-only}}(\theta) = -\sum_{i=2}^{L} w_i \cdot \log p_\theta(x_i | x_{<i}), \quad \text{其中 } x_i \in \text{Text} Ltext-only(θ)=−i=2∑Lwi⋅logpθ(xi∣x<i),其中 xi∈Text通过将损失函数限制在 text token 上,visual token 被视作条件背景,不直接参与预测。 w i w_i wi采取和InternVL 2.5 一样的square averaging。
数据情况
预训练阶段的数据比例为150B 多模态 tokens + 50B 纯文本 tokens(3:1)。
后训练策略
从InternVL3开始加入了后训练相关的内容,分为“监督微调”和“偏好优化”2个阶段。SFT阶段,训练使用InternVL 2.5版本提到的JPEG增强、数据打包策略,使模型能够在正向监督下模拟高质量回复。MPO阶段结合 preference (即 DPO)、absolute quality 和 generation process 3个角度计算损失。
三、总结:核心创新点
| 类别 | 创新点 |
|---|---|
| 架构 | ViT–MLP–LLM + Pixel Unshuffle + V2PE |
| 训练范式 | 原生多模态预训练(单阶段、全参数联合优化) |
| 算法 | 平方平均损失权重、MPO、VisualPRM 评测 |
| 工程 | InternEVO 高效训练框架、动态负载均衡 |
这些创新共同使 InternVL3 在多项多模态基准(如 MMMU 72.2 分)上达到开源 SOTA,并接近 GPT-4o、Claude 3.5 Sonnet 等闭源模型水平。
InternVL 3.5
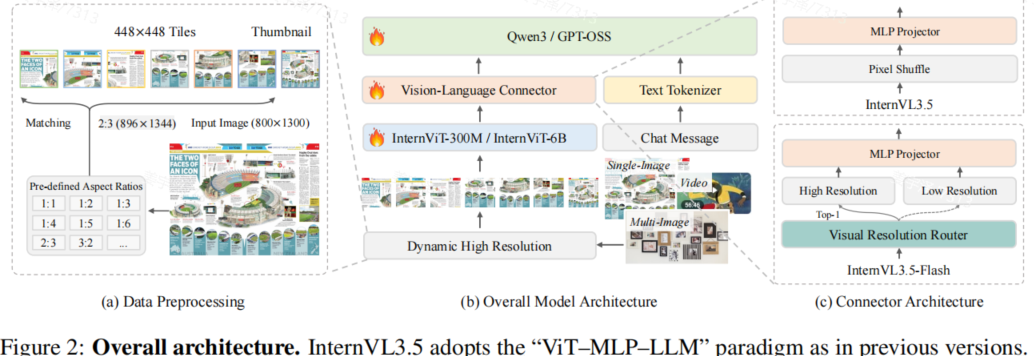
一、模型架构:经典“ViT–MLP–LLM”范式升级
InternVL3.5 沿用了 InternVL 系列经典的三段式架构:
图像 → [InternViT] → [MLP Projector (+ ViR)] → [Qwen3 / GPT-OSS LLM] → 文本输出
1. 视觉编码器(Vision Encoder)
小模型(≤30B):使用 InternViT-300M;大模型(如 38B、241B):使用 InternViT-6B。支持 动态高分辨率(Dynamic High Resolution)——将输入图像按预定义宽高比(如 2:3)切分为多个 448×448 的 tile,提升细节感知能力。
2. 视觉-语言连接器(Connector)
核心是一个 MLP 投影层,将 ViT 输出的视觉 token 映射到 LLM 的嵌入空间。图片最初以 1024 个 token 输入 encoder,但在输入 decoder 之前,被压缩至 256 个 token。对于 InternVL3.5-Flash(高效版本),模型引入 视觉分辨率路由器(Visual Resolution Router, ViR),进一步根据图片的语义丰富程度自适应的调整 token 数至 64/256 个 token。
预训练方案
预训练过程沿用之前的策略————直接使用文本+多模态组合预料进行从头训练,只包含文本 token loss,按 square 对不同长度的 sample 加权。
- 数据规模:约 250B tokens(图文比例 1:2.5);并施加随机 JPEG 压缩以提高真实情况的性能。
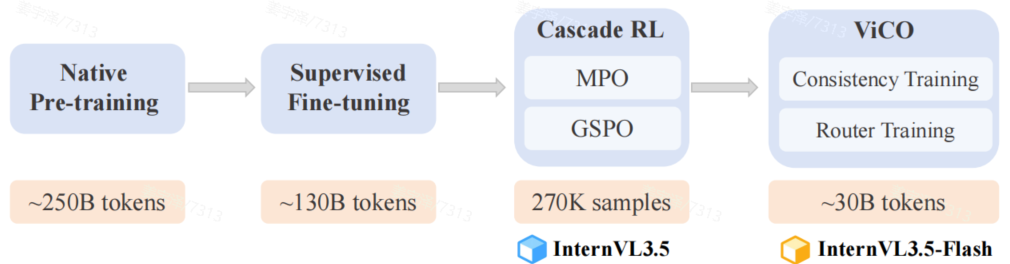
后训练流程:三阶段进阶式训练
InternVL3.5 的训练分为三个阶段,层层递进:
阶段 1:SFT
数据包括:
- 复用 InternVL3 的高质量指令数据
- 新增 CoT 数据,注入深度推理能力,不仅验证答案正确性,还评估推理过程的清晰度与逻辑性
- 引入 GUI 交互、SVG 理解、具身智能等新能力数据
阶段 2:Cascade RL
使用 Offline RL -> Online RL 的方式,以综合两者的优势,既能提高效率、避免奖励黑客,又提高模型表现、更快的达到更好的表现。Offline RL 作为 warm-up,沿用 InternVL3 的 MPO(DPO Preference loss, BCO quality loss, LM generation loss),快速启动,达到高质量的初始策略。Online 阶段,使用 GSPO 算法,根据自身 rollout 进行精确对齐
阶段 3:Visual Consistency Learning (ViCO)
这一阶段针对 InternVL3.5Flash,为确保不同压缩倍数得到的结果间一致。方案首先进行consistency training训练1/16压缩情况下的模型,然后做 router training,训练模型根据1/16压缩比的loss相比1/4压缩时增长的倍数选定实际压缩倍率。结果显示,flash 版本能够减少 50% 视觉 token,而性能损失几乎可忽略
部署策略
除了使用XTuner之外进行大规模并行训练之外,策略还采用Decoupled Vision-Language Deployment(DvD)加速推理。DvD 是针对 ViT(并行)与 LLM(自回归)计算模式不同的问题,串行执行造成 GPU 阻塞。因此,DvD 将 ViT + MLP (+ ViR) 和 LLM 分别部署在2个server上。于是,推理阶段可以拆分为“视觉处理”“特征单向传输”“语言处理” 3个异步过程。这种方案在高分辨率/多图场景收益更大。
未来方向
进一步优化幻觉控制、扩展视频/3D 理解、支持端侧部署。
Reference
[1]Chen, Z., “Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling”, arXiv e-prints, Art. no. arXiv:2412.05271, 2024. doi:10.48550/arXiv.2412.05271.
[2]Zhu, J., “InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models”, arXiv e-prints, Art. no. arXiv:2504.10479, 2025. doi:10.48550/arXiv.2504.10479.
[3]Wang, W., “InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency”, arXiv e-prints, Art. no. arXiv:2508.18265, 2025. doi:10.48550/arXiv.2508.18265.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)