[todo]transform|attention
Transformer之所以强大,核心在于自注意力机制(Self-Attention Mechanism) 与并行计算的突破,叠加多头注意力、残差连接+层归一化、编码器-解码器架构、可扩展性等设计,彻底解决传统序列模型痛点,成为大模型基础。# 2. 缩放点积注意力 (B,nh,L,dk) @ (B,nh,dk,L) -> (B,nh,L,L)# 3. 注意力加权+多头拼接 (B,nh,L,L) @
之后有时间 会给attention is all you need 这篇论文做一个pr,应该还会结合hug_face的一些最近的其他热门论文 看之后的灵感吧 想到了就做🤔
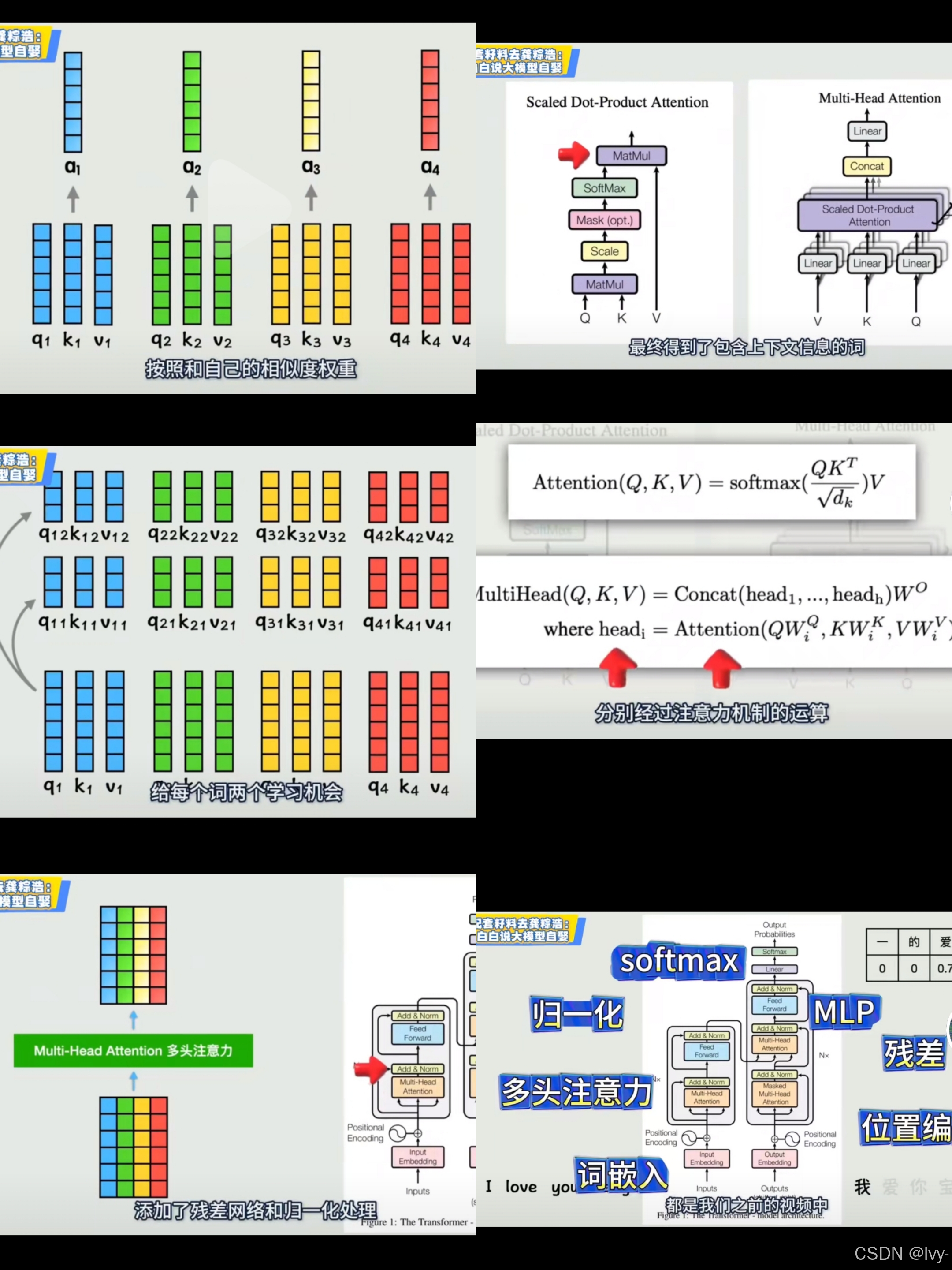
Transformer之所以强大,核心在于自注意力机制(Self-Attention Mechanism) 与并行计算的突破,叠加多头注意力、残差连接+层归一化、编码器-解码器架构、可扩展性等设计,彻底解决传统序列模型痛点,成为大模型基础
1. 全局依赖捕捉:自注意力机制让每个token直接关联序列中所有token,无距离衰减,轻松捕捉长距离语义依赖,解决RNN/LSTM长序列信息丢失问题。
2. 极致并行计算:摒弃循环结构,通过矩阵运算并行处理所有token,充分利用GPU算力,训练与推理速度大幅提升,突破RNN串行瓶颈。
3. 多维度特征提取:多头注意力(Multi-Head Attention)并行捕捉语法、语义、逻辑等不同维度关联,拼接后生成更丰富的特征表示。
4. 深度堆叠能力:残差连接(Residual Connection)缓解深层网络梯度消失,层归一化(Layer Normalization)稳定训练,支撑数百层网络与千亿级参数规模。
5. 强扩展性与多模态适配:编码器-解码器架构适配理解与生成任务,支持大规模预训练+微调范式,可迁移至文本、图像、语音等多模态场景。
一句话总结:Transformer以自注意力为核心,用并行计算提速、多头机制增维、残差+LN稳训、预训练提能,奠定大模型时代的技术根基。
手写一个极简版Transformer的自注意力代码(含QKV计算、多头拼接、残差+LN)
Transformer自注意力实现(PyTorch)
包含QKV计算、多头拆分/拼接、残差连接+层归一化核心逻辑,无冗余代码,变量命名极简,适配PyTorch常规使用场景
import torch
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super().__init__()
self.nh = n_head
self.dk = d_model // n_head
# 单线性层实现QKV并行计算,避免三次重复定义
self.qkv = nn.Linear(d_model, 3 * d_model)
# 输出投影+层归一化+残差适配
self.proj = nn.Linear(d_model, d_model)
self.ln = nn.LayerNorm(d_model)
def forward(self, x):
B, L, D = x.shape # 批次/序列长度/模型维度
# 1. 计算QKV并拆分 (B,L,3D) -> (3,B,nh,L,dk)
qkv = self.qkv(x).reshape(B, L, 3, self.nh, self.dk).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
# 2. 缩放点积注意力 (B,nh,L,dk) @ (B,nh,dk,L) -> (B,nh,L,L)
attn = (q @ k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.dk, dtype=torch.float32))
attn = F.softmax(attn, dim=-1)
# 3. 注意力加权+多头拼接 (B,nh,L,L) @ (B,nh,L,dk) -> (B,L,D)
out = (attn @ v).transpose(1, 2).reshape(B, L, D)
out = self.proj(out)
# 4. 残差连接 + 层归一化(Pre-LN风格,Transformer标准)
return self.ln(x + out)
# 测试:批次2,序列长10,模型维度512,8头注意力
if __name__ == '__main__':
mha = MultiHeadAttention(d_model=512, n_head=8)
x = torch.randn(2, 10, 512)
out = mha(x)
print(out.shape) # 输出: torch.Size([2, 10, 512])
核心设计点
1. QKV并行计算:单 nn.Linear(3*d_model) 替代3个线性层,减少代码/参数冗余
2. 张量维度极简操作:一次 reshape+permute 完成QKV拆分,避免多次循环/切片
3. 多头拼接无冗余: transpose+reshape 直接还原模型维度,无需额外拼接操作
4. Pre-LN残差:Transformer官方标准的层归一化在前+残差连接,一行实现核心范式
5. 变量极简: nh(n_head) / dk(d_k) / B/L/D 等缩写,保持代码紧凑且易读

代码可直接作为Transformer编码器/解码器的自注意力模块,无额外修改即可嵌入整体网络。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 8
8 0
0- 0



 已为社区贡献92条内容
已为社区贡献92条内容

所有评论(0)