kubernetes学习(九)kubernetes-存储
这时候引出了配置中心ConfigMap(如果不能满足需求可以开发自定义配置中心),首先会在每个节点上安装一个agent端,agent端的作用就是监控配置中心的资源是否发生更新动作,如果有agent端就会去配置中心下载最新的配置文件来替换当前的,然后出发nginx重载,使配置生效。但是它会使用其本地缓存的数值作为secret的当前值。所以当第一次注入的时候第一个文件产生了一个链接(有且只会有这一个链
1、ConfigMap(配置信息存储)
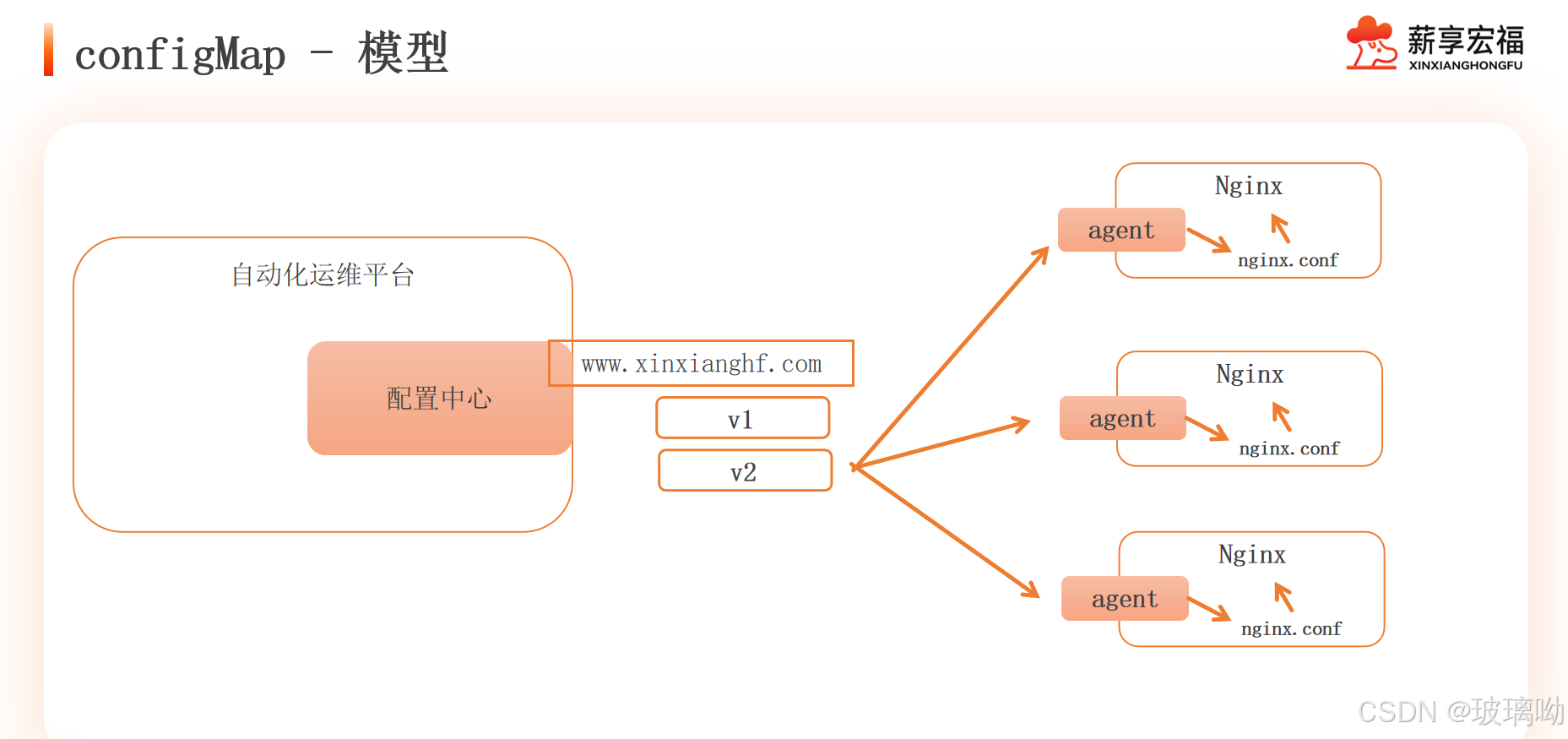
图中有三台nginx服务器,他们在同一业务、环境下,配置信息也应该一样。某天需要修改nginx配置,假设nginx有300台,难道要一台一台修改吗?这时候引出了配置中心ConfigMap(如果不能满足需求可以开发自定义配置中心)
首先在每个节点上安装一个agent端,agent端的作用就是监控配置中心的资源是否发生更新动作,如果有agent端就会去配置中心下载最新的配置文件来替换当前的,然后出发nginx重载,使配置生效。如果配置更新了新版本的话比如v3,还可以经agent端指向到新版本上进行更新与重载
ConfigMap功能在k8s 1.2版本中引入,许多应用程序会从配置文件、命令行参数或环境变量中读取配置信息。ConfigMap API给我们提供了向容器中注入配置信息的机制,ConfigMap可以被用来保存单个属性,也可以用来保存整个配置文件或者JSON二进制等对象
ConfigMap创建的方式
第一种
kubectl create configmap cmName --from-file=fileName
这种方式要求文件内部必须是一行一对的key=values,可以在使用的时候注入至pod内部变成环境变量
1.txt
name=zhangsan
password=123
还有一张情况是文件内容不是一行一对的key=values,这种情况的话文件名会变成key,内容会变成values,没办法变成环境变量,只能还原成文件去使用
2.txt
今天天气不错,适合爬山(可以理解文件内容为配置文件)
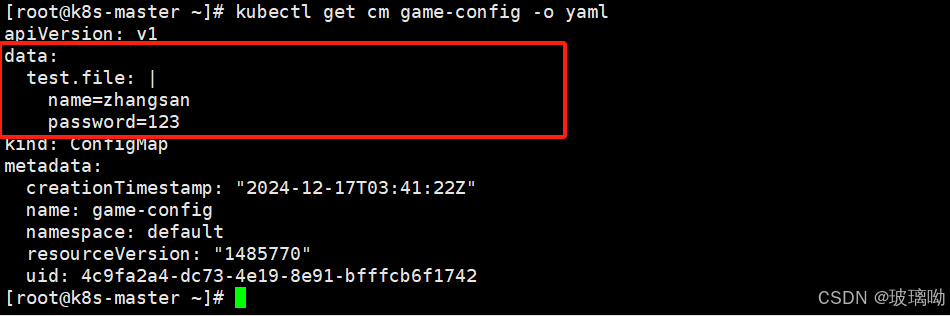
针对上面的方式做个实验,先将键值对name=zhangsan,password=123写入到文件,用命令启动cm对象

查看一下对象内容可以用kubectl get cm game-config -o yaml
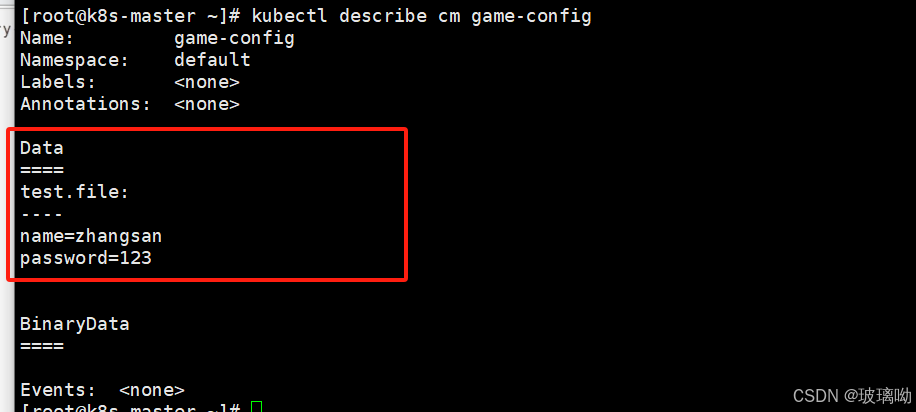
也可以用kubectl describe cm game-config
ConfigMap创建的第二种方式
kubectl create configmap cmName --from-literal=name=tom --from-literal=password=pass
这种方式适合简短的key=values,在创建cm时候直接将key values写在了选项中,不用在单独写文件了,如果有几十上百组key values还是用第一种比较好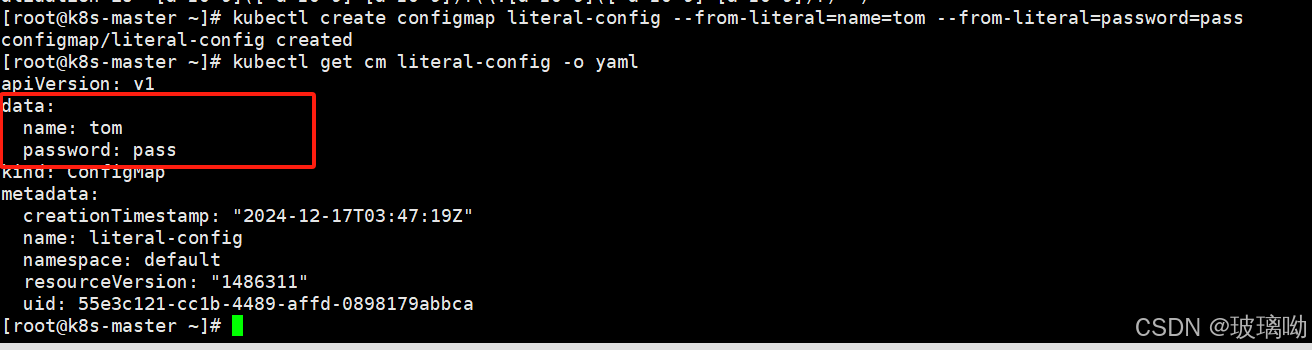
ConfigMap注入机制
注入机制是k8s提供的一种将配置信息注入容器应用的机制。它支持以下几种常见的方式
使用cm作为环境变量
将 ConfigMap 中的配置信息注入为环境变量。
# 定义第一个 ConfigMap,包含应用的基本配置信息
apiVersion: v1
kind: ConfigMap
metadata:
name: literal-config # ConfigMap 名称
namespace: default # ConfigMap 所在的命名空间
data:
name: jim # 配置项 "name" 的值是 "jim"
password: pass # 配置项 "password" 的值是 "pass"
---
# 定义第二个 ConfigMap,包含日志级别的配置
apiVersion: v1
kind: ConfigMap
metadata:
name: env-config # ConfigMap 名称
namespace: default # ConfigMap 所在的命名空间
data:
logs_level: INFO # 配置项 "logs_level" 的值是 "INFO"
---
# 定义一个 Pod,包含一个容器,利用 ConfigMap 配置环境变量
apiVersion: v1
kind: Pod
metadata:
name: cm-env-test-pod # Pod 名称
namespace: default # Pod 所在的命名空间
spec:
containers:
- name: test-container # 容器名称
image: nginx:v1 # 使用的镜像是 nginx:v1
imagePullPolicy: IfNotPresent # 镜像拉取策略:如果镜像本地已经存在,则不拉取
command: # 容器启动时执行的命令
- "/bin/bash" # 启动 bash
- "-c" # 以 -c 选项执行后面的命令
- "env" # 执行 "env" 命令,打印当前环境变量
env: # 定义容器的环境变量
- name: USERNAME # 环境变量 "USERNAME"
valueFrom: # 环境变量的值来自 ConfigMap
configMapKeyRef: # 从 ConfigMap 中引用
name: literal-config # 指定使用的 ConfigMap 名称
key: name # 指定使用 ConfigMap 中的 "name" 键的值
- name: PASSWORD # 环境变量 "PASSWORD"
valueFrom: # 环境变量的值来自 ConfigMap
configMapKeyRef: # 从 ConfigMap 中引用
name: literal-config # 指定使用的 ConfigMap 名称
key: password # 指定使用 ConfigMap 中的 "password" 键的值
envFrom: # 使用 ConfigMap 将多个键值对作为环境变量传递
- configMapRef: # 引用 ConfigMap 来获取键值对
name: env-config # 指定 ConfigMap 名称为 "env-config"
restartPolicy: Never # Pod 的重启策略:如果容器崩溃,Pod 不会自动重启
pod中引用环境变量的方式有两种,
env:更灵活,将值取出,给我们要赋予的变量
envFrom:直接引入cm,key和values直接注入到pod内,无法替换了
两种方式按需选择直接启动资源对象,可以看到两个cm被创建了出来,pod执行完env命令后变成了完成状态,pod日志可以发现容器执行env命令的打印结果,变量都已经添加进去了
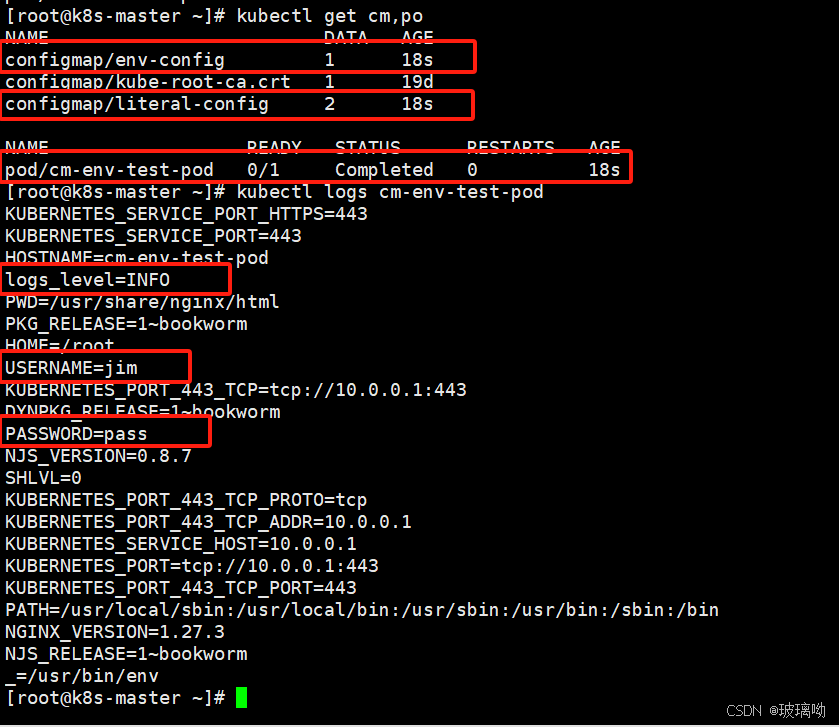
使用cm作为命令行参数
将 ConfigMap 中的配置数据传递给容器的启动命令
apiVersion: v1
kind: ConfigMap
metadata:
name: literal-config
namespace: default
data:
name: tom
password: pass
---
apiVersion: v1
kind: Pod
metadata:
name: cm-command-pod
namespace: default
spec:
containers:
- name: myapp-container
image: nginx:v1
imagePullPolicy: IfNotPresent
command:
- "/bin/bash"
- "-c"
- "echo $(USERNAME) $(PASSWORF)"
env:
- name: USERNAME
valueFrom:
configMapKeyRef:
name: literal-config
key: name
- name: PASSWORD
valueFrom:
configMapKeyRef:
name: literal-config
key: password
restartPolicy: Never直接启动资源对象,pod执行完启动命令后变成了完成状态,pod日志可以发现容器执行命令的打印结果
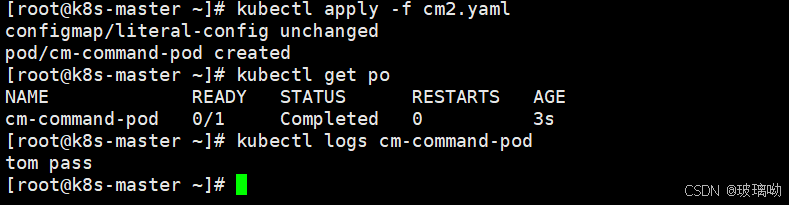
使用cm作为挂载卷
将 ConfigMap 中的文件挂载到容器的文件系统中。
上面说过--from-file创建时候分为两种情况,一种是一行一对;另一种是文件内容很多,无法一行一对,在这种情况下文件名会变成key,文件内容会变成values。
在基于上面描述的情况下,key会变成文件名,values会变成文件内容。做个实验
# 定义第一个 ConfigMap,包含配置信息
apiVersion: v1
kind: ConfigMap
metadata:
name: literal-config # ConfigMap 的名称为 "literal-config"
namespace: default # ConfigMap 所在的命名空间为 "default"
data:
name: tom # 配置项 "name" 的值为 "tom"
password: pass # 配置项 "password" 的值为 "pass"
---
# 定义一个 Pod,挂载 ConfigMap 作为卷
apiVersion: v1
kind: Pod
metadata:
name: cm-volume-pod # Pod 的名称为 "cm-volume-pod"
namespace: default # Pod 所在的命名空间为 "default"
spec:
containers:
- name: myapp-container # 容器的名称为 "myapp-container"
image: nginx:v1 # 容器使用的镜像是 "nginx:v1"
imagePullPolicy: IfNotPresent # 镜像拉取策略:如果镜像本地已有,则不拉取
volumeMounts: # 定义容器中的卷挂载
- name: config-volume # 卷的名称为 "config-volume"
mountPath: /etc/config # 将卷挂载到容器的路径 /etc/config
volumes: # 定义 Pod 中使用的所有卷
- name: config-volume # 卷的名称为 "config-volume"
configMap: # 卷的数据来源是 ConfigMap
name: literal-config # 从名为 "literal-config" 的 ConfigMap 获取数据
restartPolicy: Never # Pod 的重启策略为 "Never",即容器崩溃后不会自动重启
启动资源对象后进入pod,cd /etc/config会有两个文件,key就是文件名,values就是文件内容
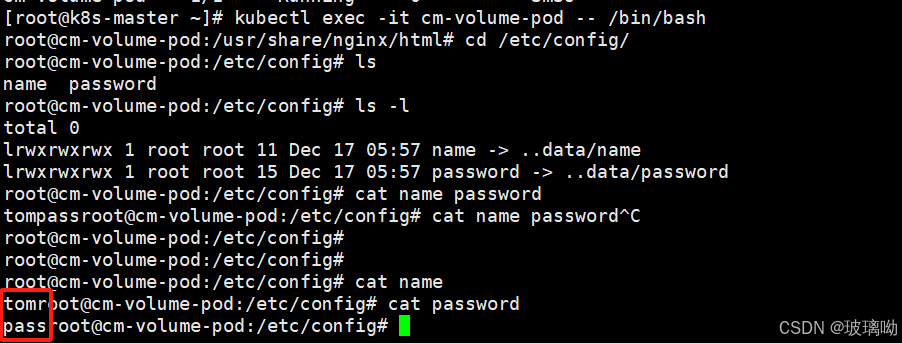
cm作为挂载卷的热更新
还是这张图,图中可以看到cm作为卷挂载的时候,用ls -l查看了文件的详细信息。发现这两个文件是以软连接的方式存在的,为什么会这样?
在一开始描述了一个场景,后端服务的配置随着配置中心的文件的改变而改变,并且这种改变是注入的方式(类似重定向追加),而不是共享。假设我正在使用这个软连接文件,配置中心产生了改变或者删除,会直接覆盖掉旧的配置。在注入的刹那间我们读取软连接文件,可能会发生损坏。
所以当第一次注入的时候第一个文件产生了一个链接(有且只会有这一个链接),这时候要进行热更新了,会将更新的内容注入到另个新文件中,再将之前的链接转移到第二个文件上,清除旧链接。这就是做链接的原因
做个实验,将nginx配置导入到一个文件中
server {
listen 80 default_server;
server_name example.com www.example.com;
location / {
root /usr/share/nginx/html;
index index.html index.htm;
}
}然后转换成cm对象,查看一下
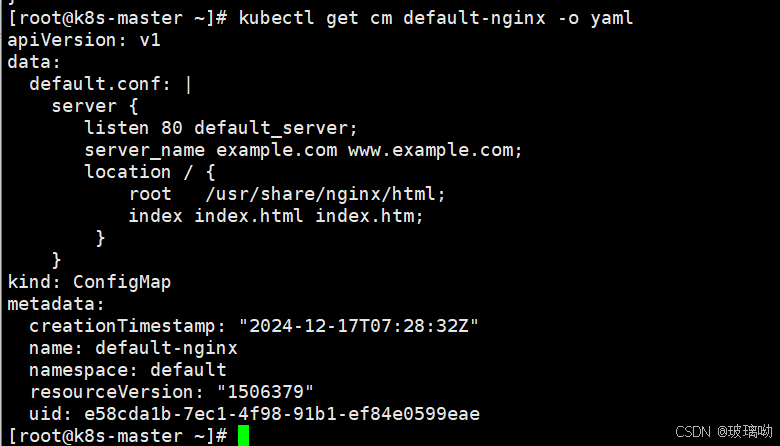
再创建一个deployment控制器,调用cm
apiVersion: apps/v1 # 指定API版本为 apps/v1,表示此资源属于 Kubernetes 的应用程序管理 API 组。
kind: Deployment # 资源类型为 Deployment,表示这是一个部署对象,用于管理应用程序副本的生命周期。
metadata: # 元数据部分,包含关于此资源的元信息。
name: hotupdate-deploy # 部署的名称为 hotupdate-deploy。
labels: # 为资源定义标签,这有助于管理和选择资源。
app: hotupdate-deploy # 标签 app 设置为 hotupdate-deploy,便于识别和管理此资源。
spec: # 规格部分,定义期望的部署状态。
replicas: 5 # 设置部署的副本数量为 5,表示需要 5 个相同的 pod 实例。
selector: # 定义用于选择匹配的 Pod 的标签。
matchLabels: # 标签匹配规则,必须满足这些标签才能选择到对应的 Pods。
hotupdate-deploy # 使用 hotupdate-deploy 标签来选择匹配的 Pods。
template: # Pod 模板定义,用来创建 Pod 的规范。
metadata: # Pod 的元数据。
labels: # 为 Pod 指定标签,这些标签会与 selector 匹配。
app: hotupdate-deploy # 给 Pod 添加 app 标签,值为 hotupdate-deploy。
spec: # Pod 内部容器的规格定义。
containers: # Pod 中的容器定义部分。
- name: nginx # 容器名称为 nginx。
image: nginx:v1 # 使用 nginx:v1 镜像。
imagePullPolicy: IfNotPresent # 如果本地已有该镜像则不会重新拉取,只有当本地没有时才会拉取。
volumeMounts: # 定义容器的挂载卷。
- name: config-volume # 挂载的卷名称为 config-volume。
mountPath: /etc/nginx/conf.d/ # 将配置文件挂载到容器的 /etc/nginx/conf.d/ 目录。
volumes: # 定义 Pod 中使用的所有卷。
- name: config-volume # 卷的名称为 config-volume。
configMap: # 配置卷使用一个 ConfigMap 作为数据来源。
name: default-nginx # 指定使用的 ConfigMap 名称为 default-nginx,用于提供 Nginx 配置。
进入pod内查看默认文件,可以看到调用是成功的
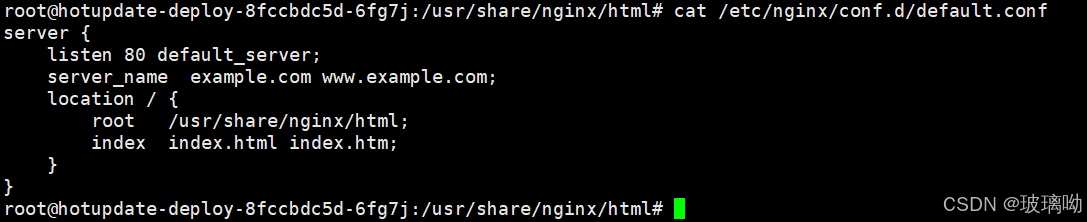
修改cm,观察pod内部是否能够热更新成功。写个死循环cat默认文件 while true ;do cat /etc/nginx/conf.d/default.conf ;sleep 2 ;done
将cm监听端口改为8080试试看,需要一点时间来进行更新,并不是瞬时操作,他需要自己去安排。比如有1000个pod,配置一旦改变了这1000个pod都需要改变,此刻服务器io压力是巨大的
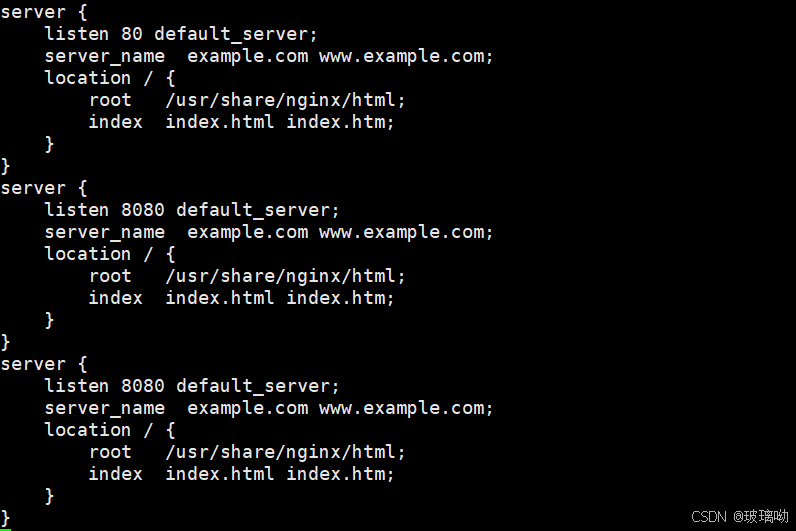
访问一个pod测试下是可以访问成功的,但是8080访问失败,因为pod内的nginx容器没有重启,新配置未应用,访问的还是80端口。nginx不支持这种监控文件变化重启自身的操作,所以k8s给了一个接口

cm作为挂载卷热更新接口
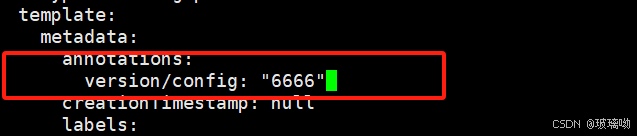
deployment.sepc.template.annotations
更新cm目前并不会触发相关pod的滚动更新,可以通过修改pod annotations的方式强制触发滚动更新,任意值即可
修改方式随便把 看自己哪个方便用哪个
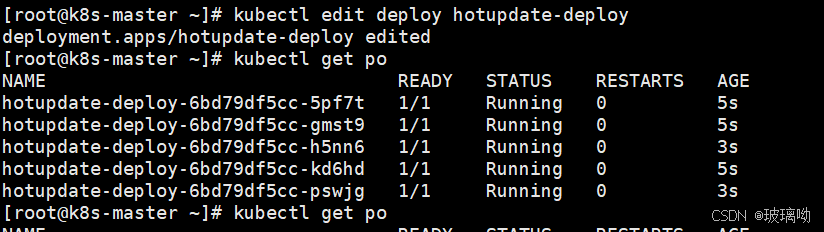
修改之后立马pod立马进行了重启,再次访问8080试下(每次修改完配置后都要改一下这个参数,感觉不是很好用)

cm作为挂载卷禁止修改
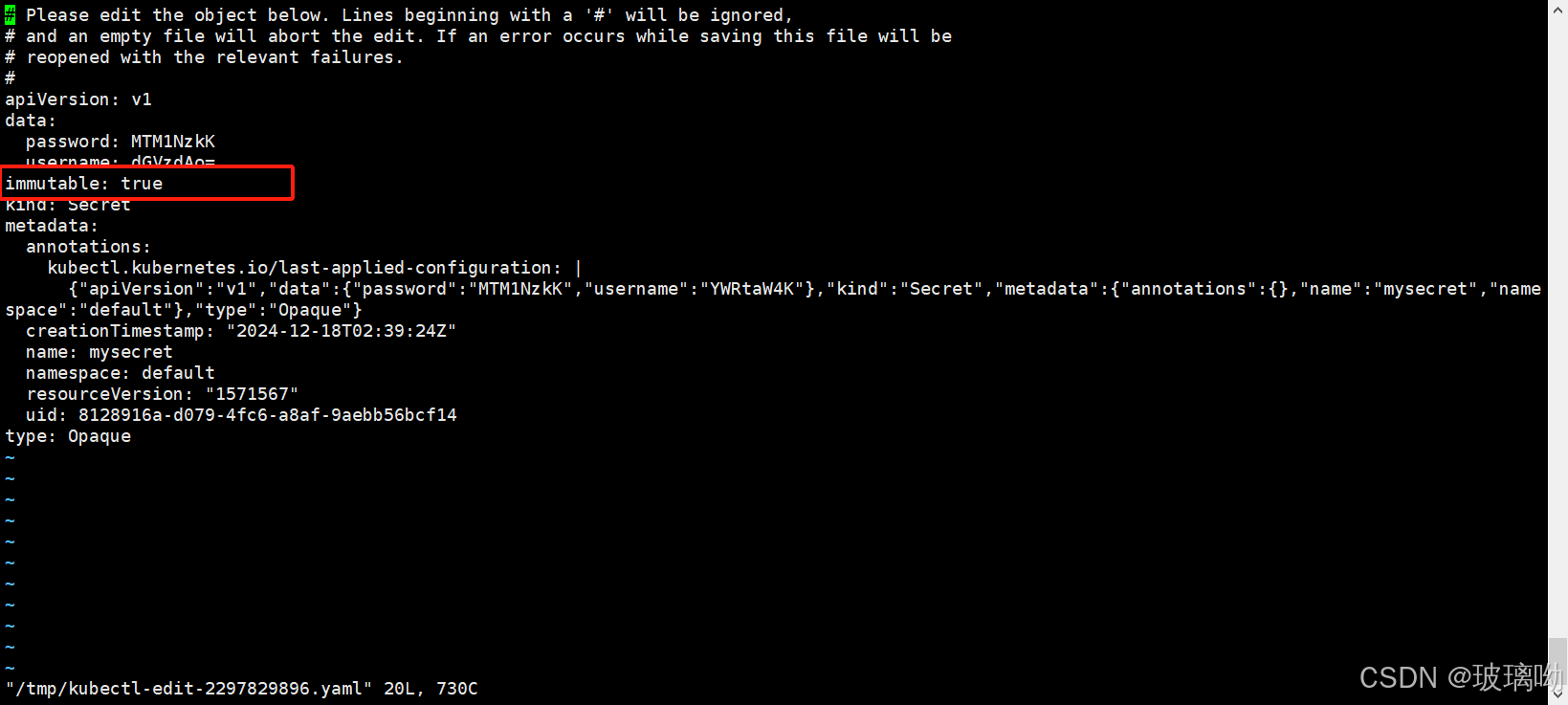
configmap.immutable
k8s给不可改变的cm和secret提供了一个可选配置,可以设置各个secret和cm为禁止修改。对于大量使用cm的集群(至少成千上万各不相同的cm供pod挂载),禁止修改他们的数据有以下好处
- 防止意外(或非预期的)更新导致应用程序中断
- 通过将cm标记为禁止修改来关闭kube-apiserver对其的监视,从而显著降低kube-apiserver的负载提升集群性能
做个实验如下:这个选项是不可逆的,添加这个参数之后cm资源对象无法做任何修改,删除这个参数也做不到,只能删除cm对象,重新建立
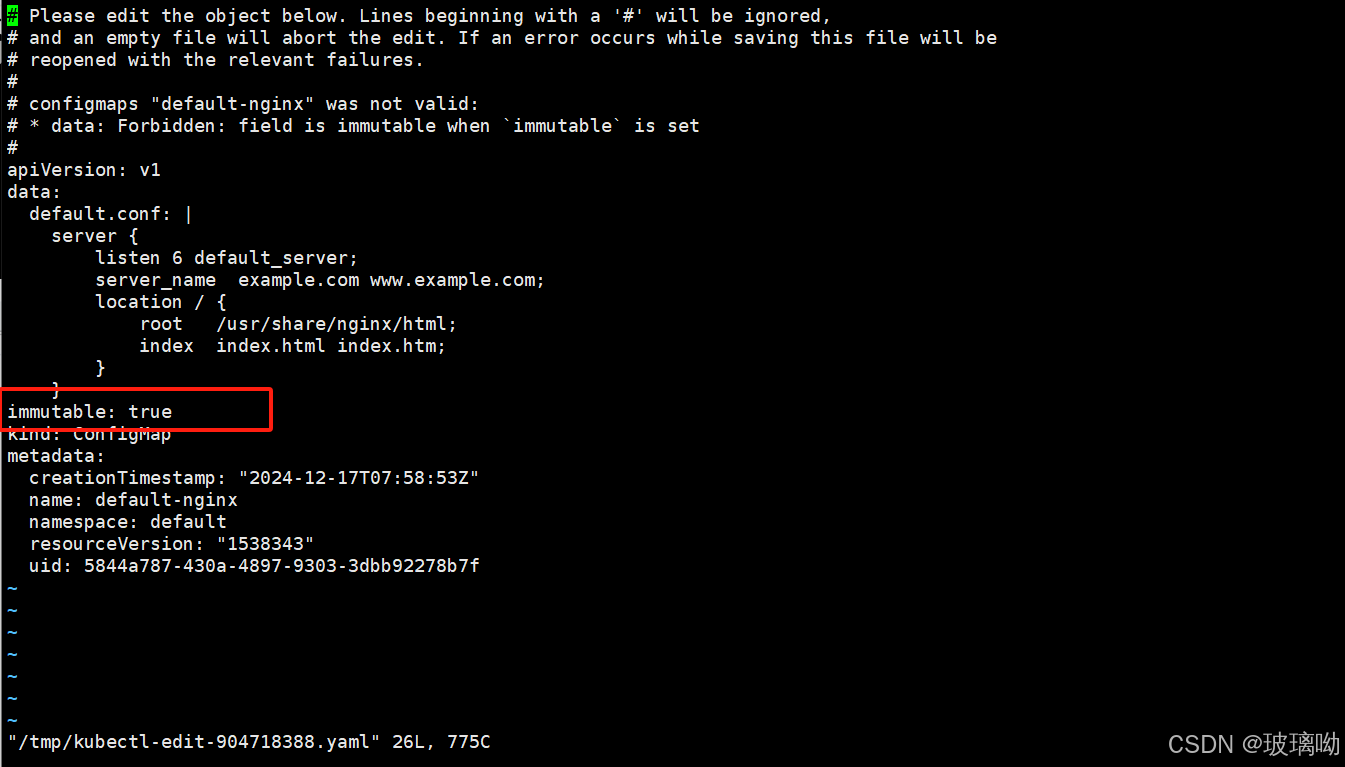
2、Secret(敏感信息存储)
secret对象类型以编码的方式用来保存敏感信息,例如密码、OAuth令牌和SSH密钥。将这些信息放在secret中比放在pod的定义或者容器镜像中来说更加安全和灵活,是编码不是加密
secret特性有三个
- k8s通过仅仅将secret分发到需要访问secret的pod所在机器节点来保障器其安全性
- secret只会存储在节点的内存中,永不写入物理存储,这样从节点删除secret时就不需要擦擦除磁盘数据
- 从k8s 1.7开始,etcd会以加密形式存储secret,一定程度保证了secret安全性
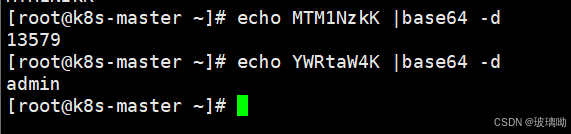
演示下编码
[root@k8s-master ~]# echo test |base64
dGVzdAo=
[root@k8s-master ~]# echo dGVzdAo= |base64 -d
test
[root@k8s-master ~]#
如果解码没有编码过的数据会报错
[root@k8s-master ~]# echo 666 |base64 -d
뭢ase64: 输入无效
[root@k8s-master ~]# Secret的类型
创建 Secret 时,你可以使用 Secret 资源的 type 字段,或者与其等价的 kubectl 命令行参数(如果有的话)为其设置类型。 Secret 类型有助于对 Secret 数据进行编程处理。
Kubernetes 提供若干种内置的类型,用于一些常见的使用场景。 针对这些类型,Kubernetes 所执行的合法性检查操作以及对其所实施的限制各不相同
Opaque |
用户定义的任意数据,默认 |
kubernetes.io/service-account-token |
服务账号令牌 |
kubernetes.io/dockercfg |
~/.dockercfg 文件的序列化形式 |
kubernetes.io/dockerconfigjson |
~/.docker/config.json 文件的序列化形式 |
kubernetes.io/basic-auth |
用于基本身份认证的凭据 |
kubernetes.io/ssh-auth |
用于 SSH 身份认证的凭据 |
kubernetes.io/tls |
用于 TLS 客户端或者服务器端的数据 |
bootstrap.kubernetes.io/token |
启动引导令牌数据 |
Opaque
做个实验
[root@k8s-master ~]# echo admin |base64
YWRtaW4K
[root@k8s-master ~]# echo 13579 |base64
MTM1NzkK
[root@k8s-master ~]#
#用户和密码先进行编码
apiVersion: v1
kind: Secret
metadata:
name: mysecret
type: Opaque
data:
username: YWRtaW4K
password: MTM1NzkK
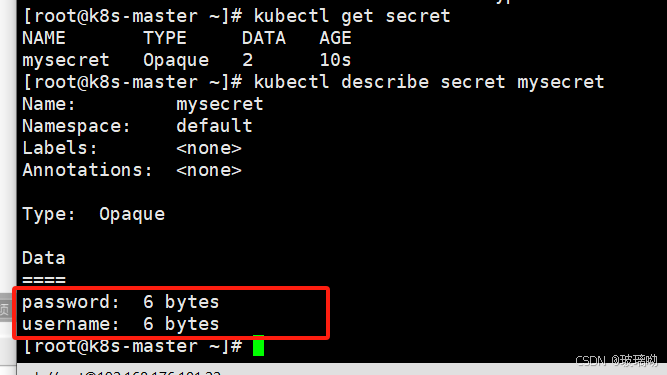
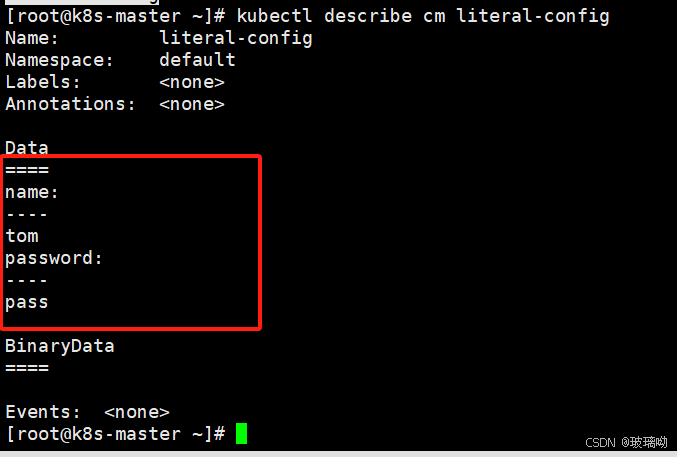
secret中,values会自动进行解码,所以一旦使用Opaque类型切记要先进行数据编码,不然解码会出错查一下,可以看到secret(下1)和cm(下2)是不同的,secret的数据段看不到
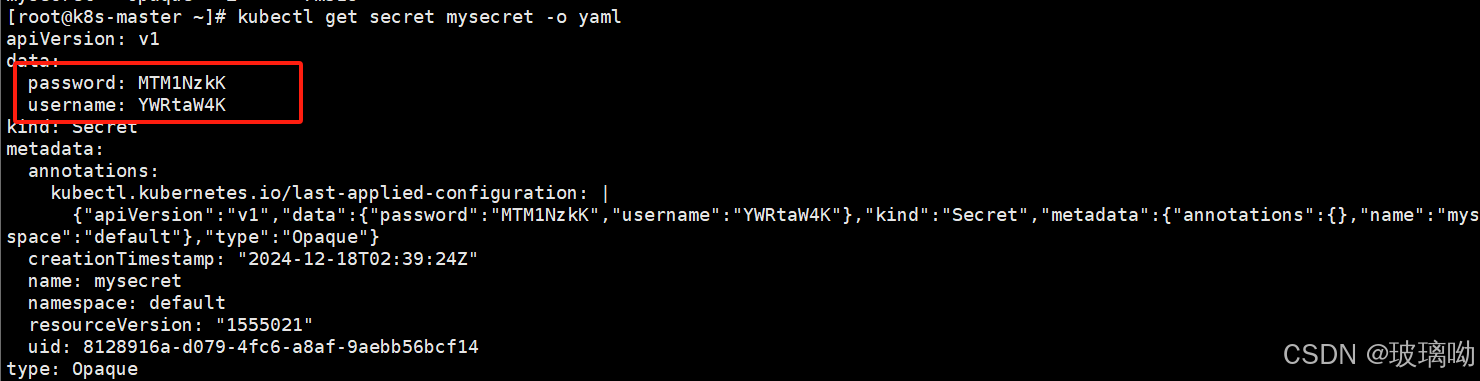
想要获取数据段用-o yaml方式,可以看到是编码形式显示的,然后使用base64解码就得到了想要的结果
作为容器环境变量使用
apiVersion: apps/v1 # 指定 API 版本,表示使用的是 Kubernetes 中的 apps/v1 版本
kind: Deployment # 指定资源类型为 Deployment,这意味着是一个应用部署
metadata:
name: opaque-secret-env-deploy # Deployment 的名称,这里是 'opaque-secret-env-deploy'
labels: # 给 Deployment 添加标签,方便后续查询或选择
app: opaque-secret-env # 标签 'opaque-secret-env'
spec:
replicas: 5 # 设置该 Deployment 创建 5 个副本(Pod)
selector: # 定义 Deployment 用于选择 Pod 的标签
matchLabels:
app: op-se-env-pod # 选择标签为 app=op-se-env-pod 的 Pod
template: # 定义 Pod 模板,Deployment 会基于该模板创建 Pod
metadata:
labels:
app: op-se-env-pod # Pod 的标签,确保 Pod 与 Deployment 匹配
spec:
containers: # Pod 中的容器定义部分
- name: myapp-container # 容器名称,给容器起名为 'myapp-container'
image: nginx:v1 # 容器使用的镜像是 'nginx:v1'
imagePullPolicy: IfNotPresent # 如果本地镜像不存在,才从镜像仓库拉取
ports:
- containerPort: 80 # 容器暴露端口 80
env: # 定义环境变量部分
- name: TEST_USER # 环境变量名称为 TEST_USER
valueFrom: # 环境变量值通过引用 Secret 获取
secretKeyRef: # 引用 Kubernetes Secret
name: mysecret # Secret 名称为 'mysecret'
key: username # Secret 中的 key 是 'username',它将作为 TEST_USER 环境变量的值
- name: TEST_PASSWORD # 环境变量名称为 TEST_PASSWORD
valueFrom: # 环境变量值通过引用 Secret 获取
secretKeyRef: # 引用 Kubernetes Secret
name: mysecret # Secret 名称为 'mysecret'
key: password # Secret 中的 key 是 'password',它将作为 TEST_PASSWORD 环境变量的值
随便进入一个pod可以看到容器内环境变量已经添加了代码中引入的变量,并且都已经进行了解码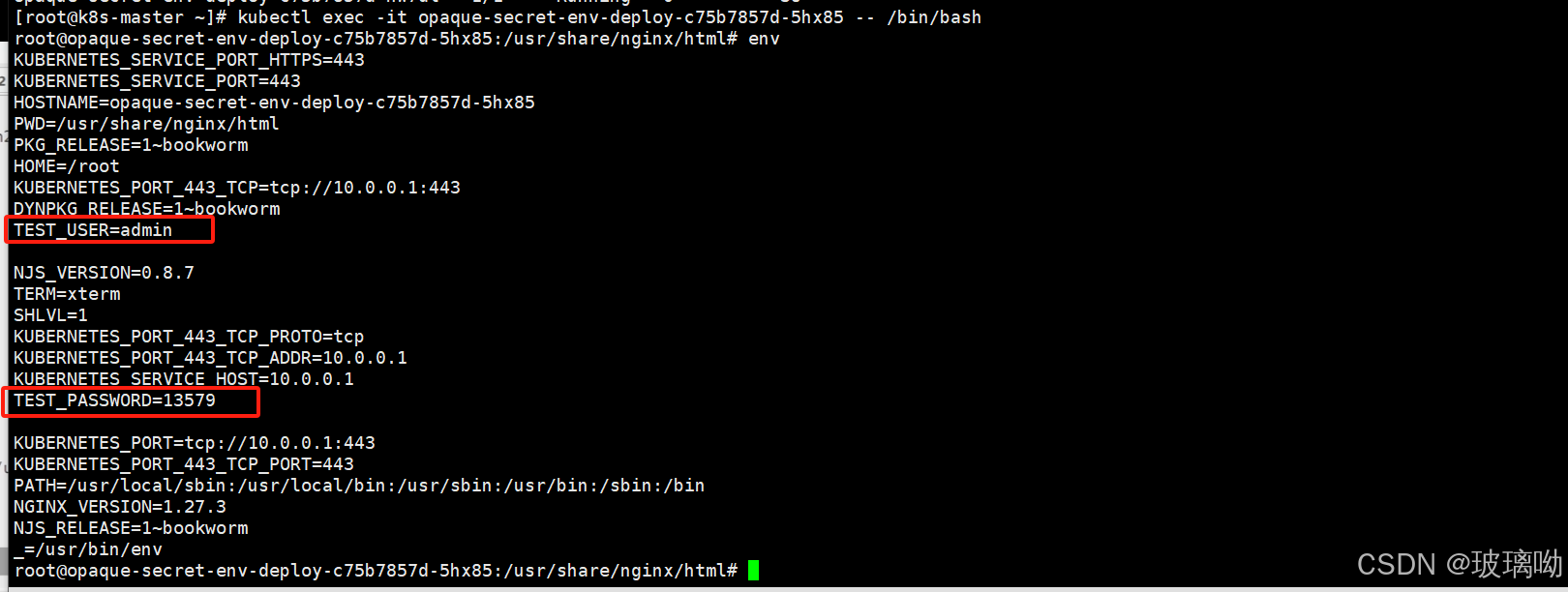
作为volume挂载
apiVersion: v1 # API 版本,v1 是 Kubernetes 中最基础的 API 版本
kind: Pod # 资源类型为 Pod,表示这是一个 Pod 配置
metadata:
name: secret-volume-pod # Pod 的名称为 'secret-volume-pod'
labels:
name: secret-volume # 给 Pod 添加标签,标签 'name' 的值为 'secret-volume'
spec:
volumes: # 定义 Pod 使用的所有卷(Volumes)
- name: volumes12 # 卷的名称为 'volumes12'
secret: # 使用 Kubernetes Secret 类型的卷
secretName: mysecret # 引用名为 'mysecret' 的 Secret 作为卷的内容
containers: # Pod 中定义的容器部分
- name: myapp-contaienr # 容器的名称,注意:'container' 拼写错误,正确应为 'container'
image: nginx:v1 # 容器使用的镜像是 'nginx:v1'
imagePullPolicy: IfNotPresent # 如果本地没有镜像,则从仓库拉取镜像
volumeMounts: # 定义容器内的卷挂载部分
- name: volumes12 # 挂载名为 'volumes12' 的卷(此卷是 Secret 类型的)
mountPath: "/data" # 将卷挂载到容器内的 '/data' 路径
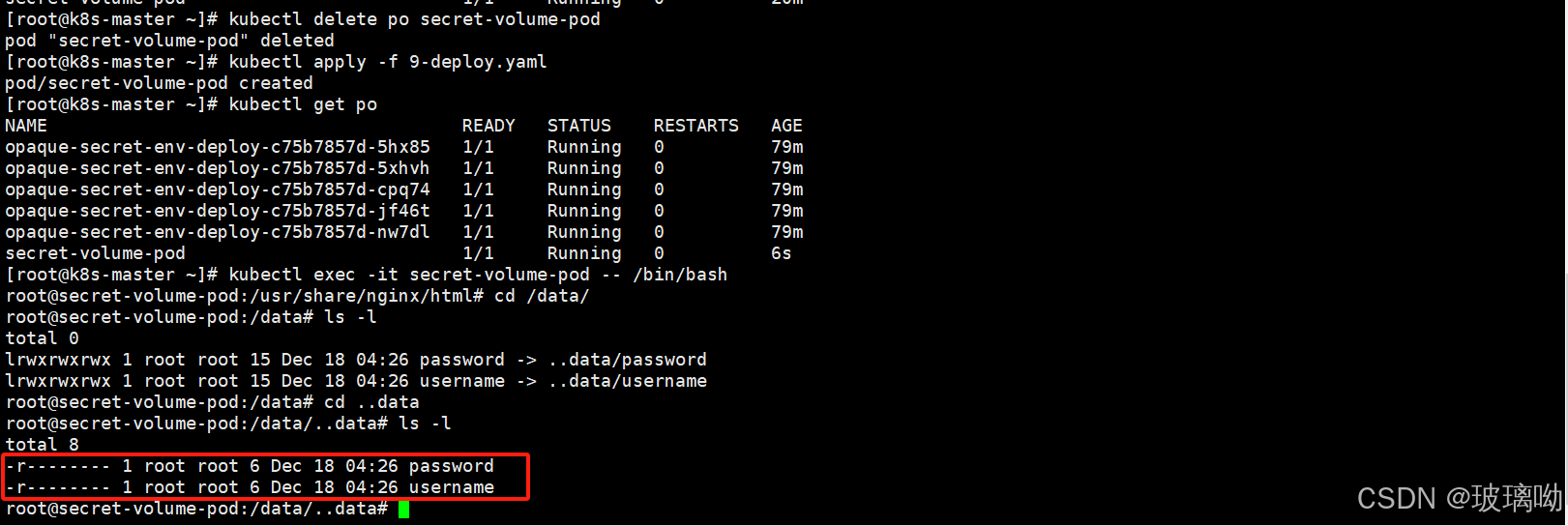
进入pod容器内部,查看/data,ls -l看下源文件,然后进入目录发现源文件是一个644权限,既然是安全的话将它修改下权限


修改挂载卷的权限,加一个defaultMode参数 ,而且要删除原先的pod,再次进行创建。因为k8s中对 Pod.Spec 的更新做了一些限制,防止某些字段被修改,所以不允许在 Pod 已经运行后修改。defaultMode 是与卷权限相关的配置,属于卷配置的一部分,因此一旦 Pod 创建后,卷相关的设置不允许更新
apiVersion: v1
kind: Pod
metadata:
name: secret-volume-pod
labels:
name: secret-volume
spec:
volumes:
- name: volumes12
secret:
secretName: mysecret
defaultMode: 256 #用的是十进制数字,会转换为对应的一个权限因为权限代表的数字就是八进制的,会变成400
containers:
- name: myapp-contaienr
image: nginx:v1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: volumes12
mountPath: "/data"
可以看到挂载卷权限已被修改
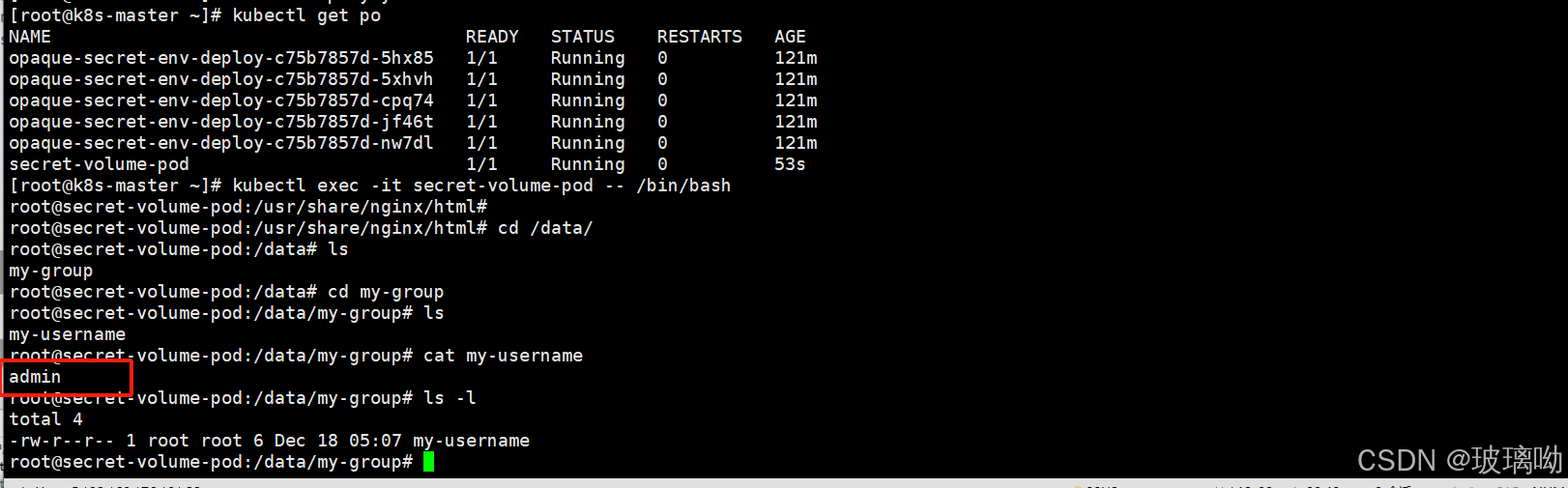
指定某个键进行挂载
apiVersion: v1 # 指定使用 Kubernetes API 版本 v1
kind: Pod # 资源类型为 Pod,表示创建一个 Pod
metadata:
name: secret-volume-pod # Pod 的名称为 'secret-volume-pod'
labels:
name: secret-volume # 给 Pod 添加标签,标签 'name' 的值为 'secret-volume'
spec:
volumes: # 定义 Pod 中的所有卷
- name: volumes12 # 卷的名称为 'volumes12'
secret: # 使用 Kubernetes Secret 类型的卷
secretName: mysecret # 引用名为 'mysecret' 的 Secret
items: # 通过 items 字段指定哪些 Secret 键应该被挂载
- key: username # 选择 Secret 中的键 'username'
path: my-group/my-username # 将 Secret 中 'username' 键的值挂载到容器内的 '/data/my-group/my-username'
containers: # 定义容器部分,Pod 中运行的应用容器
- name: myapp-contaienr # 容器名称,注意:'container' 拼写错误,应该是 'myapp-container'
image: nginx:v1 # 容器使用的镜像是 'nginx:v1'
imagePullPolicy: IfNotPresent # 如果本地镜像不存在,则从镜像仓库拉取镜像
volumeMounts: # 定义容器内的卷挂载
- name: volumes12 # 挂载名为 'volumes12' 的卷(该卷来源于 Secret)
mountPath: "/data" # 将卷挂载到容器内的 '/data' 路径
可以看到挂载单独键的时候,文件名都被修改了,并且这个文件是一个标准的文件类型而不是一个链接文件,这就意味着它不支持热更新。当已经存储与卷中被使用的secret被更新时,被映射的键也终将被更新。组件kubelet在周期性同步时检查被挂载的secret是不是最新的。但是它会使用其本地缓存的数值作为secret的当前值。使用secret作为子路径卷挂载的容器不会收到secret更新
Opaque作为卷挂载热更新
还是这个代码,没有用到子路径用它进行热更新测试
apiVersion: v1
kind: Pod
metadata:
name: secret-volume-pod
labels:
name: secret-volume
spec:
volumes:
- name: volumes12
secret:
secretName: mysecret
containers:
- name: myapp-contaienr
image: nginx:v1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: volumes12
mountPath: "/data"依旧是这两个值
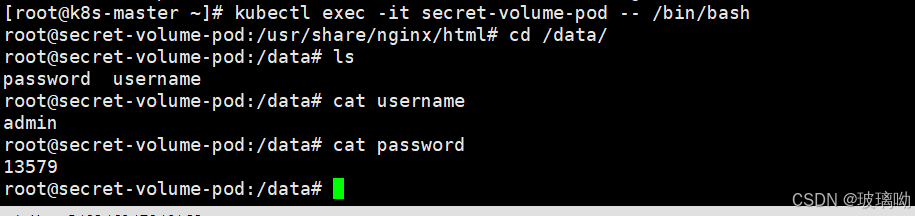
对secret做改变,将admin改成test,改之前切记要先对test进行编码

更新成功,更新过程比较久,不到一分钟
Opaque作为卷挂载禁止更新
它和cm一样有禁止更新的操作,此操作不可逆!
剩下的类型在后续实验中会陆续登场
3、Downward API(集群信息存储)
它是k8s中的一个功能,它允许容器在运行时从kubernetes API服务器获取有关它们自身的信息。这戏信息可以作为容器内部的环境变量或文件注入到容器中,以便容器可以获取有关其运行环境的各种信息,如pod名称、命名空间、标签等
说白了就是将pod的信息字段暴露给容器使用,一共两种方式
作为环境变量使用
做个实验
apiVersion: v1 # Kubernetes API 版本,v1 是基础版本,用于创建 Pod 等资源
kind: Pod # 资源类型为 Pod,表示创建一个 Pod 资源
metadata:
name: downward-api-env-example # Pod 的名称为 'downward-api-env-example'
namespace: default # 指定 Pod 所在的命名空间为 'default'
spec:
containers: # 定义 Pod 中的容器
- name: my-container # 容器的名称为 'my-container'
image: nginx:v1 # 使用 nginx:v1 作为容器的镜像
imagePullPolicy: IfNotPresent # 如果本地没有该镜像,则从仓库拉取
env: # 定义容器的环境变量
- name: POD_NAME # 环境变量 'POD_NAME' 将存储 Pod 的名称
valueFrom:
fieldRef:
fieldPath: metadata.name # 通过 Downward API 获取 Pod 的名称
- name: POD_NAMESPACE # 环境变量 'POD_NAMESPACE' 将存储 Pod 所在的命名空间
valueFrom:
fieldRef:
fieldPath: metadata.namespace # 通过 Downward API 获取 Pod 的命名空间
- name: POD_IP # 环境变量 'POD_IP' 将存储 Pod 的 IP 地址
valueFrom:
fieldRef:
fieldPath: status.podIP # 通过 Downward API 获取 Pod 的 IP 地址,注意字段大小写应为 'status.podIP'
- name: CPU_REQUEST # 环境变量 'CPU_REQUEST' 将存储 Pod 的 CPU 请求值
valueFrom:
resourceFieldRef: # 使用 resourceFieldRef 获取资源请求的值
resource: requests.cpu # 获取 CPU 请求值
- name: CPU_LIMIT # 环境变量 'CPU_LIMIT' 将存储 Pod 的 CPU 限制值
valueFrom:
resourceFieldRef: # 使用 resourceFieldRef 获取资源限制的值
resource: limits.cpu # 获取 CPU 限制值
- name: MEMORY_REQUEST # 环境变量 'MEMORY_REQUEST' 将存储 Pod 的内存请求值
valueFrom:
resourceFieldRef: # 使用 resourceFieldRef 获取资源请求的值
resource: requests.memory # 获取内存请求值
- name: MEMORY_LIMIT # 环境变量 'MEMORY_LIMIT' 将存储 Pod 的内存限制值
valueFrom:
resourceFieldRef: # 使用 resourceFieldRef 获取资源限制的值
resource: limits.memory # 获取内存限制值
restartPolicy: Never # 设置 Pod 的重启策略为 'Never',表示 Pod 不会在终止后自动重启
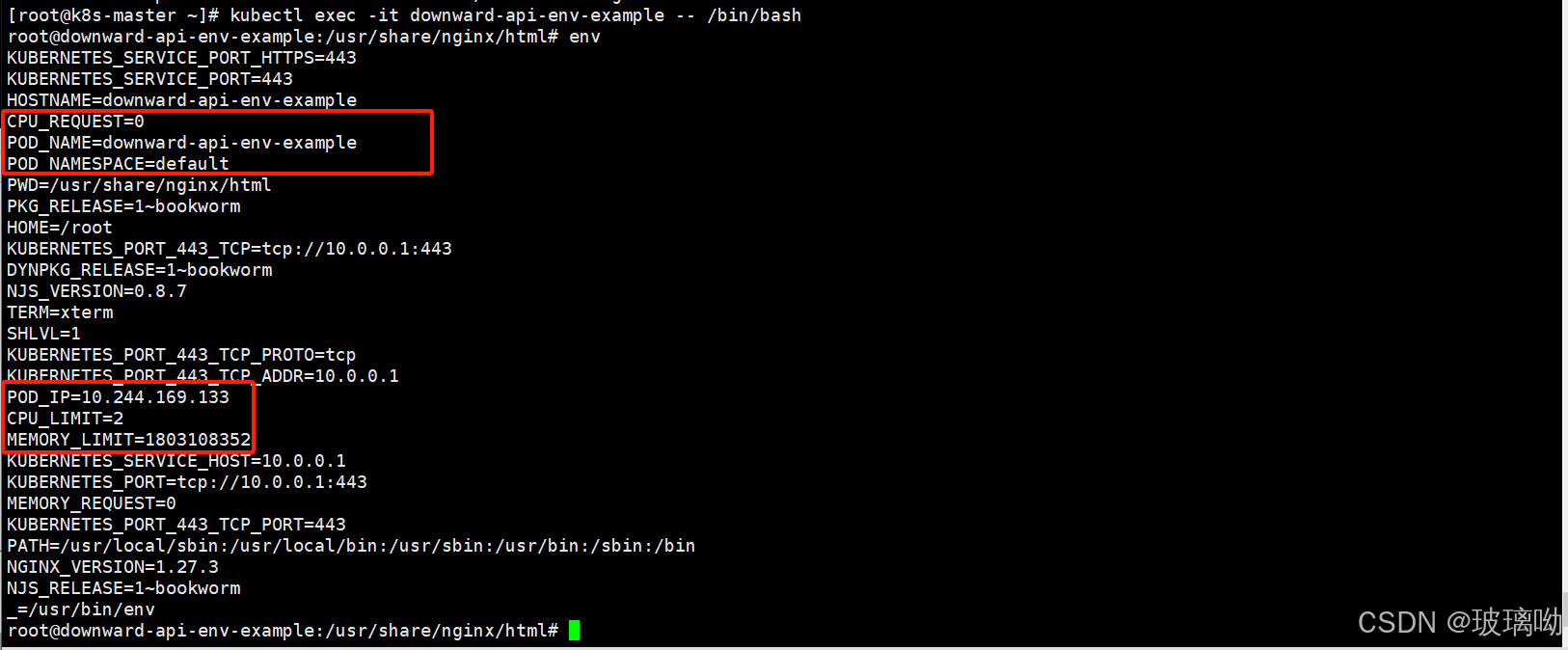
图中可以看到将pod的信息都暴露给了容器运行,只关注命名空间,podIP和pod名称就行,剩下的后面才会学到
作为卷使用
实验开始
apiVersion: v1 # API版本,指定Pod对象使用的API版本
kind: Pod # 资源类型为 Pod
metadata:
name: downward-api-volume-example # Pod 的名称
spec:
containers: # 定义 Pod 中的容器
- name: my-container # 容器名称
image: nginx:v1 # 使用的镜像,指定了 nginx:v1
imagePullPolicy: IfNotPresent # 镜像拉取策略:如果本地已有镜像则不拉取
resources: # 设置容器的资源请求和限制
limits:
cpu: "1" # 限制容器最多使用 1 核 CPU
memory: "512Mi" # 限制容器最多使用 512Mi 内存
requests:
cpu: "0.5" # 请求容器 0.5 核 CPU
memory: "256Mi" # 请求容器 256Mi 内存
volumeMounts: # 将卷挂载到容器中
- name: downward-api-volume # 卷的名称,匹配 volumes 部分的名称
mountPath: /etc/podinfo # 将卷挂载到容器的 /etc/podinfo 目录
volumes: # 定义 Pod 中的卷
- name: downward-api-volume # 卷的名称,匹配 volumeMounts 部分的名称
downwardAPI: # 使用 Downward API 卷类型
items: # 通过 Downward API 获取并挂载 Pod 的字段
- path: "annotations" # 将 Pod 的注解挂载到名为 annotations 的文件
fieldRef:
fieldPath: metadata.annotations # 引用 Pod 的 metadata.annotations 字段
- path: "labels" # 将 Pod 的标签挂载到名为 labels 的文件
fieldRef:
fieldPath: metadata.labels # 引用 Pod 的 metadata.labels 字段
- path: "name" # 将 Pod 的名称挂载到名为 name 的文件
fieldRef:
fieldPath: metadata.name # 引用 Pod 的 metadata.name 字段
- path: "namespace" # 将 Pod 的命名空间挂载到名为 namespace 的文件
fieldRef:
fieldPath: metadata.namespace # 引用 Pod 的 metadata.namespace 字段
- path: "uid" # 将 Pod 的 UID 挂载到名为 uid 的文件
fieldRef:
fieldPath: metadata.uid # 引用 Pod 的 metadata.uid 字段
- path: "cpuRequest" # 将容器的 CPU 请求值挂载到名为 cpuRequest 的文件
resourceFieldRef:
containerName: my-container # 指定容器名称为 my-container
resource: requests.cpu # 获取容器的 requests.cpu 资源字段
- path: "memoryRequest" # 将容器的内存请求值挂载到名为 memoryRequest 的文件
resourceFieldRef:
containerName: my-container # 指定容器名称为 my-container
resource: requests.memory # 获取容器的 requests.memory 资源字段
- path: "cpuLimit" # 将容器的 CPU 限制值挂载到名为 cpuLimit 的文件
resourceFieldRef:
containerName: my-container # 指定容器名称为 my-container
resource: limits.cpu # 获取容器的 limits.cpu 资源字段
- path: "memoryLimit" # 将容器的内存限制值挂载到名为 memoryLimit 的文件
resourceFieldRef:
containerName: my-container # 指定容器名称为 my-container
resource: limits.memory # 获取容器的 limits.memory 资源字段
restartPolicy: Never # 设置 Pod 的重启策略为 Never,表示该 Pod 不会自动重启
进入pod内查看,可以看到相关信息都以卷的形式挂载到了/etc/podinfo下面变成了文件。

标签忘了加,用kubectl edit在pod里加一下

DownwardAPI 扩展(失败,后续补充)
上面的实验案例是将pod和容器的元数据传递给了他们内部运行的进程。但是这种方式仅仅只暴露自身pod的元数据给容器,且只有部分元数据可以暴露,也无法做到跨pod引用数据
所以基于官方的apiserver接口就登场了,直接从接口拿数据,而不是通过官方提供的机制取数据
这个实验暂时不要理解,照做就行,后面学到安全再回来看
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: test-api-cluster-admin-binding
subjects:
- kind: ServiceAccount
name: test-api
namespace: default
roleRef:
kind: ClusterRole
name: Cluster-admin
apiGroup: rbac.authorization.k8s.iokubectl create sa test-api实验失败。。。下机,后面学了安全再来
4、volume(数据持久化)
数据的持久化方案。容器磁盘上的文件声明周期是短暂的,这就使得在容器中运行重要应用时会出现一些问题。首先当容器崩溃时,kublet会重启它,但是容器中的文件将丢失——容器以干净的状态(镜像最初的状态)重新启动。其次在pod中同时运行多个容器时,这些容器之间通常需要共享文件,k8s中的volume就很好的解决了这些问题
kubernetes官方提供了很多类型的卷,并且很多卷类型在新版本中已经被弃用或者移除了。这里只演示几种常用的卷
emptyDir
对于定义了 emptyDir 卷的 Pod,在 Pod 被指派到某节点时此卷会被创建。 就像其名称所表示的那样,emptyDir 卷最初是空的。尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,但这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
# apiVersion表示使用的Kubernetes API的版本,v1是比较常用的版本之一
apiVersion: v1
# kind用于指定当前配置的资源类型,这里是Pod,表示要创建一个Pod资源
kind: Pod
# metadata部分用于定义该Pod的元数据信息,比如名称、所属命名空间等
metadata:
# name字段指定Pod的名称,这里取名为volume-emptydir-disk-pod
name: volume-emptydir-disk-pod
# namespace字段指定Pod所属的命名空间,这里是default命名空间
namespace: default
# spec部分用于定义Pod的规格,也就是详细的配置内容
spec:
# containers字段用于定义Pod中包含的容器列表,这里可以包含一个或多个容器
containers:
# 开始定义第一个容器,名称为myapp
- name: myapp
# image字段指定容器要使用的镜像,这里使用的是nginx镜像,版本为v1
image: nginx:v1
# imagePullPolicy用于指定镜像拉取策略,IfNotPresent表示如果本地不存在该镜像才去拉取
imagePullPolicy: IfNotPresent
# ports字段用于定义容器要暴露的端口信息
ports:
# 定义容器内的端口80将被暴露,可用于对外提供服务等情况
- containerPort: 80
# volumeMounts字段用于定义容器内挂载存储卷的相关配置
volumeMounts:
# 定义挂载的存储卷名称为logs-volume
- name: logs-volume
# 指定在容器内的挂载路径为/var/log/nginx/,这样容器内对应路径下的数据可以存储到挂载的存储卷中
mountPath: /var/log/nginx/
# 开始定义第二个容器,名称为busybox
- name: busybox
# 指定该容器使用的镜像为busybox镜像
image: busybox
# 同样设置镜像拉取策略为IfNotPresent
imagePullPolicy: IfNotPresent
# command字段用于定义容器启动时要执行的命令
command:
# 这是具体的命令内容,整体命令是先创建一个名为access.log的文件,然后持续跟踪该文件的变化(通常用于查看日志等情况)
- "/bin/sh"
- "-c"
- "touch /logs/access.log && tail -f /logs/access.log"
# 定义该容器内挂载存储卷的配置
volumeMounts:
# 挂载的存储卷名称同样为logs-volume
- name: logs-volume
# 指定在容器内挂载的路径为/logs,用于和上面的命令配合,对该路径下的日志文件进行操作等
mountPath: /logs
# volumes字段用于定义Pod使用的存储卷列表
volumes:
# 定义一个名为logs-volume的存储卷
- name: logs-volume
# 这里指定存储卷类型为emptyDir,即一个临时的、基于节点本地存储的空目录存储卷,常用于容器间共享数据等场景
emptyDir: {}查询pod的ip进行访问,然后查看busybox日志
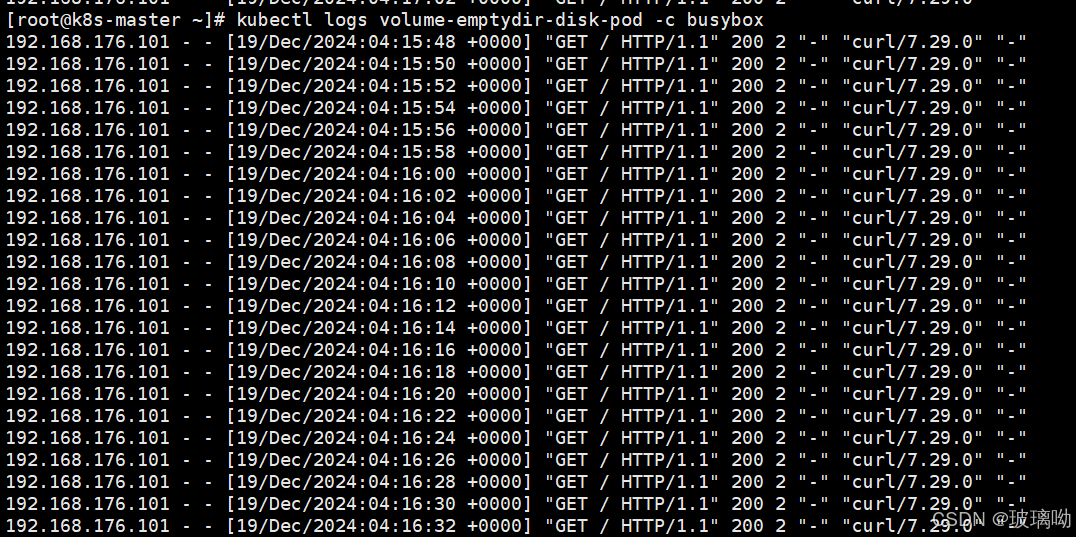
在kubelet的工作目录(root-dir参数控制)默认为/var/lib/kubelet,会为每个使用了emptyDir:{}的pod创建一个目录,
格式为/var/lib/kubelet/pods/{podid}/volumes/kubernetes.io~empty-dir/所有放在emptyDir的数据,最终都是落在了node的上述路径中,可以看下文件内容或在文件中添加一些字符,再去pod查看日志确定准确性

使用内存作为介质的 emptyDir 卷
没实际演示过,代码放这里后续明白了在补充
apiVersion: v1
kind: Pod
metadata:
name: test-pd
spec:
containers:
- image: registry.k8s.io/test-webserver
name: test-container
volumeMounts:
- mountPath: /cache
name: cache-volume
volumes:
- name: cache-volume
emptyDir:
sizeLimit: 500Mi
medium: MemoryhostPath(常用)
hostPathc卷将主机节点的文件系统中的文件或目录挂载在集群中,hostPath用途如下
- 运行一个需要访问节点级系统组件的容器 (例如一个将系统日志传输到集中位置的容器,使用只读挂载
/var/log来访问这些日志) - 让存储在主机系统上的配置文件可以被静态pod以只读方式访问;与普通 Pod 不同,静态 Pod 无法访问 ConfigMap。
除了所需的path属性之外,用户还可以为hostPath卷指定type
|
空字符串(默认)用于向后兼容,这意味着在安装 hostPath 卷之前不会执行任何检查。 |
DirectoryOrCreate |
如果在给定路径上什么都不存在,那么将根据需要创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息。 |
Directory |
在给定路径上必须存在的目录。 |
FileOrCreate |
如果在给定路径上什么都不存在,那么将在那里根据需要创建空文件,权限设置为 0644,具有与 kubelet 相同的组和所有权。 |
File |
在给定路径上必须存在的文件。 |
Socket |
在给定路径上必须存在的 UNIX 套接字。 |
CharDevice |
(仅 Linux 节点) 在给定路径上必须存在的字符设备。 |
BlockDevice |
(仅 Linux 节点) 在给定路径上必须存在的块设备。 |
使用hostPath有几点需要注意
- 由于每个节点上的文件都不同,具有相同配置(例如从podTemplate创建的)的pod在不同节点上的行为可能会有所不同
- 当k8s按照计划添加资源感知调度是,将无法考虑hostPath使用的资源
- 在底层主机上创建的文件或目录只能由root写入。需要在特权容器中以root身份运行进程,或修改主机上的文件权限以便写入hostPath卷
apiVersion: v1
kind: Pod
metadata:
name: hostpath-pod
spec:
containers:
- name: myapp
image: nginx:v1
imagePullPolicy: IfNotPresent
volumeMounts:
- name: test-volume
mountPath: /test-pd
volumes:
- name: test-volume
hostPath:
path: /data #注意这个/data是最后pod分配节点的/data,不是master的/data
type: Directory启动资源对象发现过了很久还没有创建好
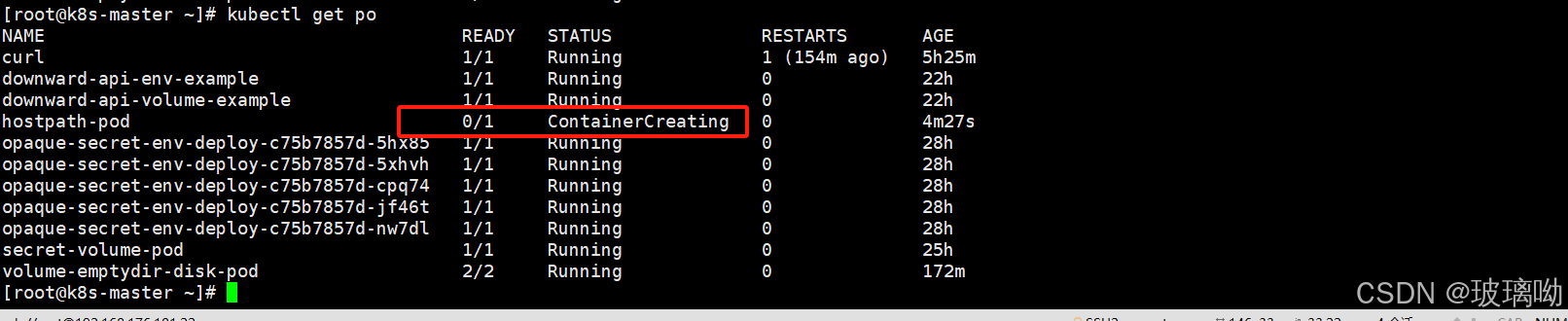
describe看下pod创建过程,看到报错说/data不是一个目录,为什么?因为directory类型要求挂载的目录必须存在!而我没有创建

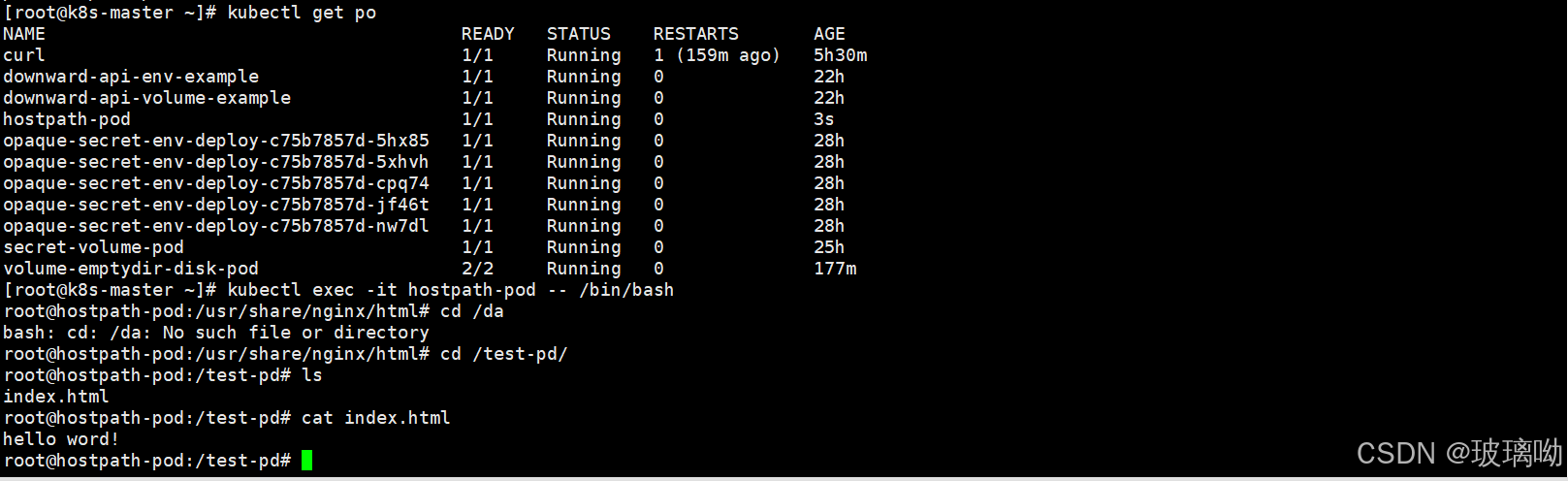
在所有节点都创建一个/data目录,并且里面加了个文件,删除pod再次创建
可以看到成功了,或者用DirectoryOrCreate类型都可以,前提是没有这么个目录
5、PV/PVC
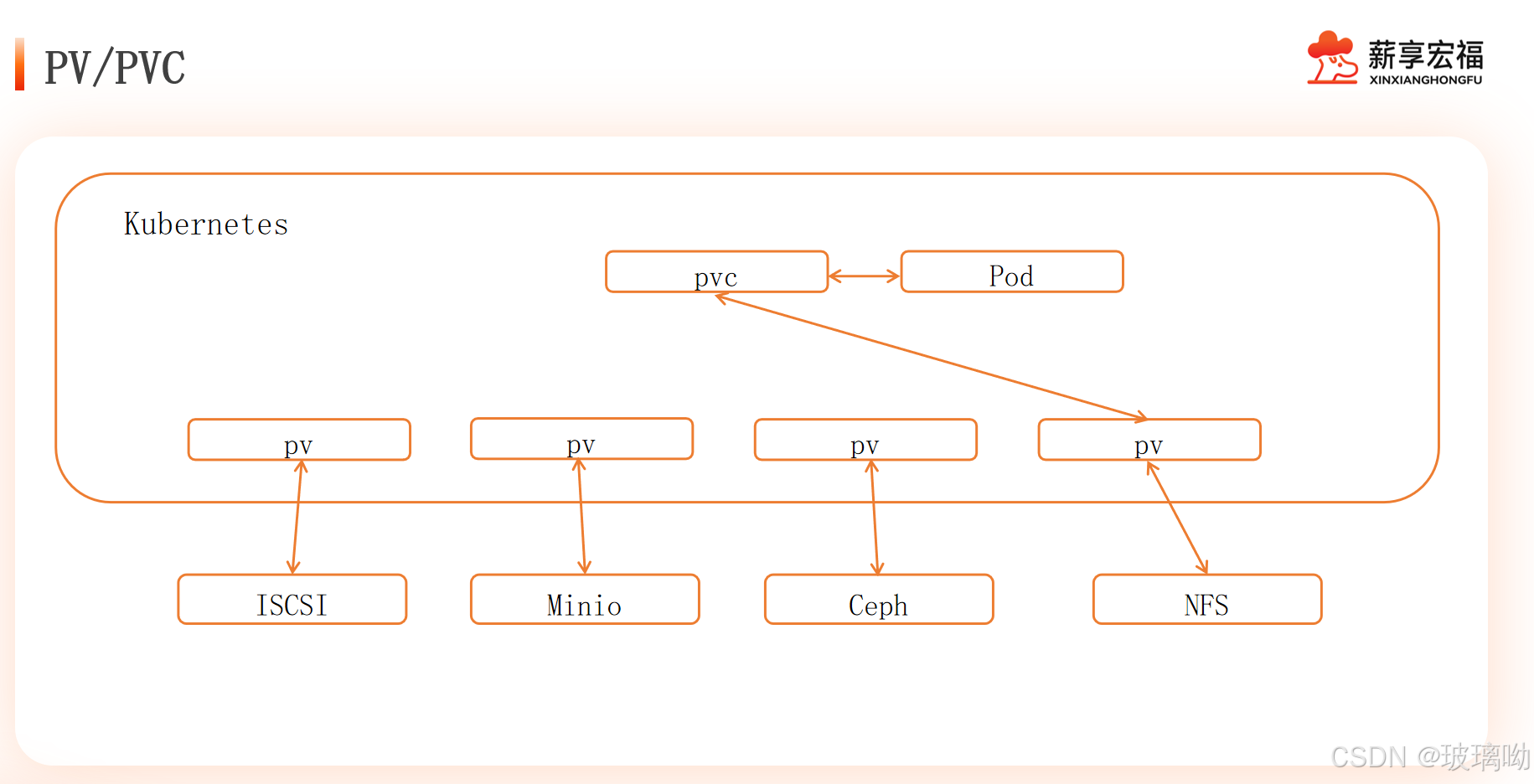
- PV(Persistent Volume):持久化卷,是集群中的一块存储,可以由管理员事先供应,或者使用存储类(Storage Class)来动态供应。它是一种抽象的存储资源,独立于使用它的 Pod。例如,它可以是一块网络存储(如 NFS、Ceph 等)或者云存储(如 AWS EBS、Azure Disk 等)在 Kubernetes 集群中的抽象表示。
- PVC(Persistent Volume Claim):持久化卷声明,是用户对于存储的请求。它类似于用户向存储系统 “申请” 一定量的存储资源,比如指定存储的大小、访问模式(如只读、读写)等要求。
关系阐述
- PVC 是对 PV 的请求:用户通过创建 PVC 来请求存储资源,PVC 定义了所需要的存储资源的规格和特性。例如,一个 PVC 可能会声明需要 10Gi 大小的存储,并且是读写模式(ReadWriteOnce)。Kubernetes 会根据这个请求在已有的 PV 中查找或者动态创建符合要求的 PV 来绑定这个 PVC。
- PV 和 PVC 的绑定关系:当 PVC 的请求与 PV 的属性相匹配时(如存储大小、访问模式等条件满足),它们就会绑定在一起。这种绑定是一对一的关系,一个 PVC 只能绑定一个 PV,一个 PV 也只能被一个 PVC 绑定。绑定之后,Pod 就可以通过 PVC 来使用对应的 PV 所提供的存储资源。例如,一个运行数据库的 Pod 可以通过挂载一个绑定了合适 PV 的 PVC 来将数据持久化存储到对应的存储介质中。
- 生命周期的关联:PVC 的生命周期通常会受到与其绑定的 PV 的影响。如果 PV 被删除或者不可用,与之绑定的 PVC 的状态也会受到影响。例如,如果 PV 对应的存储设备出现故障,PVC 所代表的存储请求就无法正常满足,可能会导致使用该 PVC 的 Pod 出现存储相关的问题。同时,当 PVC 被删除时,与之绑定的 PV 可能会根据其回收策略(如保留、删除、回收)来进行相应的处理
所以这个逻辑是pv持久卷的背后是实体存储,pvc和pod是进行绑定的,而pvc和pv进行了匹配,所以等于pod使用了背后的存储,如下图
关联条件
- 容量:PV的值不小于PVC要求,可以大于最好一致
- 读写策略:完全匹配
- 单节点读写--ReadWriteOnce--RWO
- 多节点只读--ReadOnlyMany--ROX
- 多节点读写--ReadWriteMany--RWX
- 存储类:PV的类与PVC的类必须一直,不存在包容降级关系(包容降级这个指的是公司中自定义的存储等级。比如公司有3个等级的存储,pvc写了匹配1级的,就不会降级匹配)
存储类型不一定都支持三种读写策略,比如iscsi不支持RWX
PV回收策略
假设现在需要杀死一个pod,pvc就成为了孤立的存在,并且pvc不死的话pv不会被释放。在这种情况下数据真的不想保留,就可以将pvc杀死。pvc死掉之后相应的pv没有人去关联它了,这时需要它自己处理自己,分为三种情况
- Retain(保留): 手动回收。就是pv处于未就绪状态,现在一个pvc要来进行关联(符合条件情况下),pv不允许绑定,因为pv内部很可能存在高价值的数据,允许绑定会将高价值数据覆盖掉。这时要由运维人员将数据备份,在手动恢复它为可用状态
- Recycle(回收):简单擦除(
rm -rf /thevolume/*)。当pod和pvc被杀死且pv没有被关联,它会在pv内部自动执行rm -rf /thevolume/*删除上一个留下的数据,完全清理掉 - Delete(删除): 删除存储卷。pod和pvc被杀起且pv没有被关联,就会把自己清理掉,这个pv就不存在了
当前只有 nfs 和 hostPath 卷类型支持回收(Recycle),但是nfs不支持delet策略
PV状态
- Avaliable(可用):空闲资源还没有被任何声明(PVC)所绑定
- Bound(已绑定):卷已经被PVC绑定
- Relaeased(已释放):PVC被删除,但是资源还未被集群重新声明
- Failed(失败):该卷的自动回收失败
命令行会显示绑定到PV的PVC的名称
PV/PVC实验
理论结束,开始实践。此次实验用nfs当作pv,可以新开一个虚拟机或者在master节点安装
#搭建nfs服务器,每个节点都安装
yum -y install nfs-utils rpcbind
systemctl start rpcbind
systemctl start nfs
回到master节点
mkdir /nfsdata
chmod 666 /nfsdata
chown nfsnobody /nfsdata
cd /nfsdata
#为了更好呈现pvc效果,多建几个目录进行pv制作,并且每个目录下都有内容
for i in {1..10} ;do mkdir $i ;echo $i > $i/index.html ;done
vim /etc/exports
/nfsdata/1 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/2 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/3 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/4 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/5 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/6 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/7 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/8 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/9 *(rw,no_root_squash,no_all_squash,sync)
/nfsdata/10 *(rw,no_root_squash,no_all_squash,sync)
exportfs -r
showmount -e hostIP查看共享
可以在集群中其他节点测试挂载nfs目录
mount -t nfs nfsServerIP:/Path localPath
这样就模拟了十个nfs的共享存储,并且将目录 /nfsdata/10 以读写权限共享给所有客户端,保留客户端 root 权限(无映射限制),并确保数据同步写入磁盘将nfs抽象为PV
apiVersion: v1 # API版本,Kubernetes核心API v1版本
kind: PersistentVolume # 资源类型,定义一个持久化存储卷
metadata:
name: nfsv1 # 存储卷的名称,必须唯一
spec:
capacity:
storage: 1Gi # 存储容量,大小为1Gi
accessModes:
- ReadWriteOnce # 访问模式,仅允许单个节点读写
persistentVolumeReclaimPolicy: Recycle # 回收策略,删除时清理数据
storageClassName: nfs # 存储类名称,指向NFS存储
nfs: # 定义NFS的相关配置
path: /nfsdata/1 # NFS共享目录路径
server: 192.168.176.101 # NFS服务器的IP地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfsv2 # 第二个存储卷
spec:
capacity:
storage: 1Gi # 存储容量为1Gi
accessModes:
- ReadWriteMany # 访问模式,多个节点可同时读写
persistentVolumeReclaimPolicy: Recycle # 回收策略,删除时清理数据
storageClassName: nfs # NFS存储类
nfs:
path: /nfsdata/2 # NFS共享目录路径
server: 192.168.176.101 # NFS服务器的IP地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfsv3 # 第三个存储卷
spec:
capacity:
storage: 1Gi # 存储容量为1Gi
accessModes:
- ReadOnlyMany # 访问模式,多个节点只读访问
persistentVolumeReclaimPolicy: Recycle # 回收策略,删除时清理数据
storageClassName: nfs # NFS存储类
nfs:
path: /nfsdata/3 # NFS共享目录路径
server: 192.168.176.101 # NFS服务器的IP地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfsv4 # 第四个存储卷
spec:
capacity:
storage: 1Gi # 存储容量为1Gi
accessModes:
- ReadWriteOnce # 访问模式,仅单节点读写
persistentVolumeReclaimPolicy: Retain # 回收策略,删除后保留数据
storageClassName: nfs # NFS存储类
nfs:
path: /nfsdata/4 # NFS共享目录路径
server: 192.168.176.101 # NFS服务器的IP地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfsv5 # 第五个存储卷
spec:
capacity:
storage: 3Gi # 存储容量为3Gi
accessModes:
- ReadWriteOnce # 访问模式,仅单节点读写
persistentVolumeReclaimPolicy: Recycle # 回收策略,删除时清理数据
storageClassName: nfs # NFS存储类
nfs:
path: /nfsdata/5 # NFS共享目录路径
server: 192.168.176.101 # NFS服务器的IP地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfsv6 # 第六个存储卷
spec:
capacity:
storage: 1.2Gi # 存储容量为1.2Gi(建议调整为整数值)
accessModes:
- ReadWriteOnce # 访问模式,仅单节点读写
persistentVolumeReclaimPolicy: Delete # 回收策略,删除时销毁数据
storageClassName: nfs # NFS存储类
nfs:
path: /nfsdata/6 # NFS共享目录路径
server: 192.168.176.101 # NFS服务器的IP地址
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfsv7 # 第七个存储卷
spec:
capacity:
storage: 0.9Gi # 存储容量为0.9Gi(建议调整为有效单位如900Mi)
accessModes:
- ReadWriteOnce # 访问模式,仅单节点读写
persistentVolumeReclaimPolicy: Recycle # 回收策略,删除时清理数据
storageClassName: nfs # NFS存储类
nfs:
path: /nfsdata/7 # NFS共享目录路径
server: 192.168.176.101 # NFS服务器的IP地址
创建资源对象后如下图

继续创建服务并使用PVC
apiVersion: v1
kind: Service
metadata:
name: nginx # 定义 Service 的名称
labels:
app: nginx # 为 Service 添加标签
spec:
clusterIP: None # 配置为无头服务(Headless Service),允许直接访问 Pod
ports:
- name: web # 定义端口名称
port: 80 # Service 暴露的端口
selector:
app: nginx # 选择标签为 app=nginx 的 Pod
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: web # StatefulSet 名称,用于唯一标识 StatefulSet
spec:
replicas: 3 # 副本数量,表示创建 3 个 Pod
selector:
matchLabels:
app: nginx # 定义 Pod 的匹配标签,确保正确匹配模板中的 Pod
serviceName: nginx # 关联的 Service 名称,必须是 Headless Service
template:
metadata:
labels:
app: nginx # Pod 模板的标签,需与 selector 匹配
spec:
containers:
- name: nginx-container # 容器名称
image: nginx:one # 使用的 Nginx 镜像版本
imagePullPolicy: IfNotPresent # 如果本地没有镜像,则从镜像仓库拉取
ports:
- name: nginxweb # 容器端口名称
containerPort: 80 # 容器内部服务暴露的端口
volumeMounts:
- name: www # 卷挂载名称,对应 volumeClaimTemplates
mountPath: /usr/share/nginx/html # 挂载到容器的路径
volumeClaimTemplates: # 定义持久化卷模板
- metadata:
name: www # PVC 名称,需与 volumeMounts 一致
spec:
accessModes:
- ReadWriteOnce # 定义卷访问模式,单节点可读写
storageClassName: nfs # 使用的存储类
resources:
requests:
storage: 1Gi # 请求的存储大小为 1Gi
代码中要求控制器创建三个Pod,三个Po都需要挂载存储卷,所以它会根据清单创建三个PVC,按照PVC声明自动匹配满足条件的PV,这就是整个清单的逻辑了。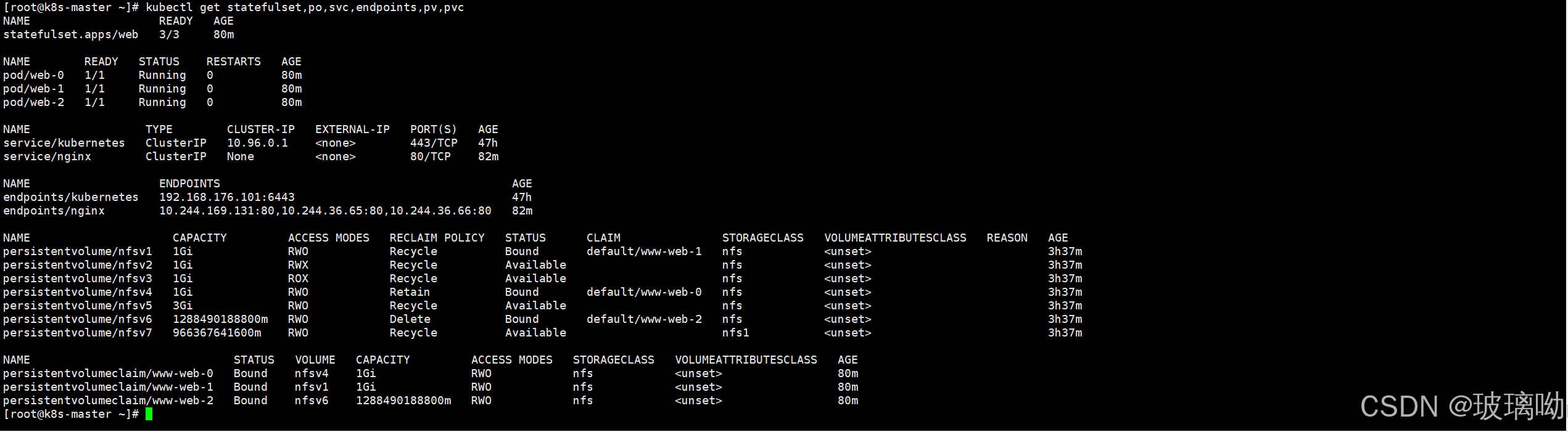
从上图的的查询信息可以非常清晰的看到Pod的PV的状态,绑定情况。
稍微提一句,pod和PV的绑定并不是pod1绑定PV1这种按顺序来的这里涉及到了预选和优选算法(不重要,无所谓)
- 预算算法:必须满足我的最低要求,有多个预选的情况下在预选的基础上优选
- 优选算法:就是打分,海选之后晋级。如果预选全部一样,那就随机选择
Pod控制器-StatefulSet
在上面的代码中,看到了没有出现过的控制器:StatefulSet,和Service的无头服务。这两个功能没做实验是因为要结合其他功能使用才能更直观的体现出作用,下面具体展开介绍
前面说了pod控制器,pod控制器分为两种类型
- 批处理任务:Job、CronJob
- 守护进程:ReplicationController、RepolicaSet、Deployment、DaemonSet、StatefulSet
守护进程类型控制器还分为两种:
- 控制无状态服务:ReplicationController、RepolicaSet、Deployment、DaemonSet
- nginx就是典型的无状态应用。比如三个nginx组成负载均衡集群,将其中一个拿走,过了一段时间在放回集群内还能继续组成集群对外服务,因为nginx没有需要数据同步的操作。这就是无状态服务。所以对于无状态服务不用去做数据的持久化
- 控制有状态服务:StatefulSet
- 而mysql就是典型的有状态应用。比如mysql集群,从两个高可用的mysql拿走一个,过段时间在放回进群内,它肯定不能使用了,因为数据没有同步。StatefulSet 提供了对有状态应用所需的特性支持,例如持久存储、固定网络标识和有序部署/删除等。
StatefulSet的特性
- 有序创建:上一个pod没有RUNNING,下一个pod不允许被创建;有序回收:倒序,先发给最后一个,以此类推
- 数据持久化Pod级别
- 稳定的网络访问方式
有序创建
做个实验
kubectl scale statefulset web --replicas=10
#调整控制器副本数量为10个
从上图看,pod名字很奇怪哈,不像其他控制器一样后面跟的是哈希值,而是从0开始按序往下。到了web-4这个个pod停了,不在继续创建了,这就是有序创建的特性。
再来看pod,出现了Pending待处理的这么一个状态,describe看下pod创建过程
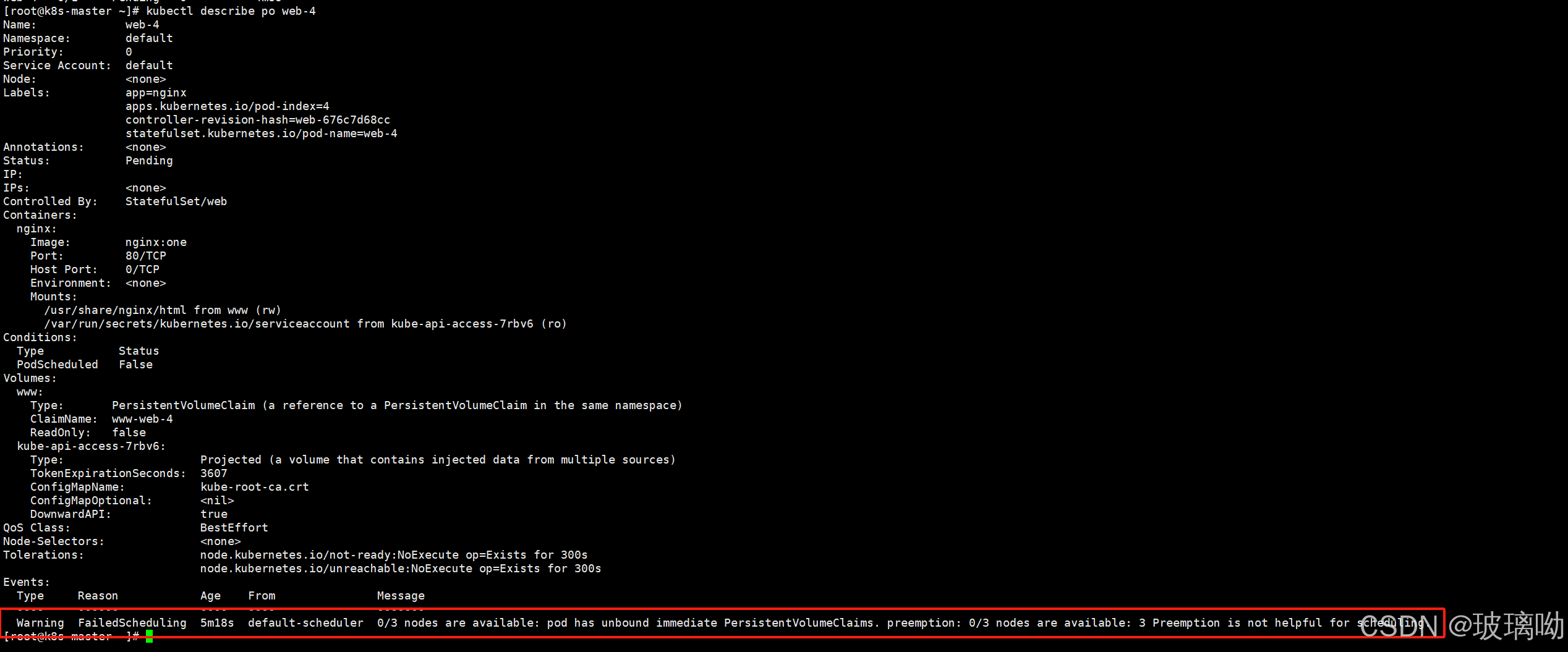
从上图来看,有个告警报错,这个报错的来源是默认调度器,说的是有三个节点可用,但是pod没有办法调度到任何节点。无法调度的原因是unbound immediate PersistentVolumeClaims这个错误,pod的PVC没有绑定到任何一个PV
为什么PVC无法绑定到PV了?看下代码,PVC要求有三点,类型要是nfs、大小1GB、单节点读写

再看创建好的7个PV情况,剩下的三个不符合要求。所以web-4这个pod没有创建结束,是不会继续创建下一个pod的。这就是StatefulSet创建pod的有序性

数据持久化Pod级别
做个实验
随便访问一个pod,访问web-0好了,可以看到主页内容是4

进入容器内给主页添加一些内容然后删除pod,如下图

这时候再去访问web-0Pod看结果,就会发现访问内容还是一样的。通过ip和创建时间就知道这是完全的重建的新的pod

实现过程来分析下:pod绑定pvc,pvc绑定pv,pv绑定nfs实体存储。
虽然pod被删除了,但是pvc和pv的绑定是没有变化的,当同样一个pod出现,绑定同样一个pvc,那后端的数据肯定是一致的
从实验可以看出来这个数据的持久化是pod级别的,将pod杀死在创建一个新的数据也一致
稳定的网络访问方式
删除pod测试pod级别的数据持久化的实验会发现,虽然数据一致了,但是IP进行了变更。通过IP访问Pod很显然这不是一个稳定的方式。但是有另个方式:域名(比如www.baidu.com)
做个实验,随便写个pod。
apiVersion: v1
kind: Pod
metadata:
name: busybos-demo
spec:
containers:
- name: busybox-container
image: busybox
command:
- "/bin/sh"
- "-c"
- "sleep 3600"启动pod资源对象,进入pod内部
wget http://web-0.nginx.default.svc.cluster.local./index.html && cat index.html && rm -fr index.html
#之前访问域名都是从svc的名字开始,但这样不能准确访问到web-0的内容,因为svc会轮训负载。所以最前面加了web-0,用域名精准访问 ok没问题,访问的是同一个主页,现在还不能说明问题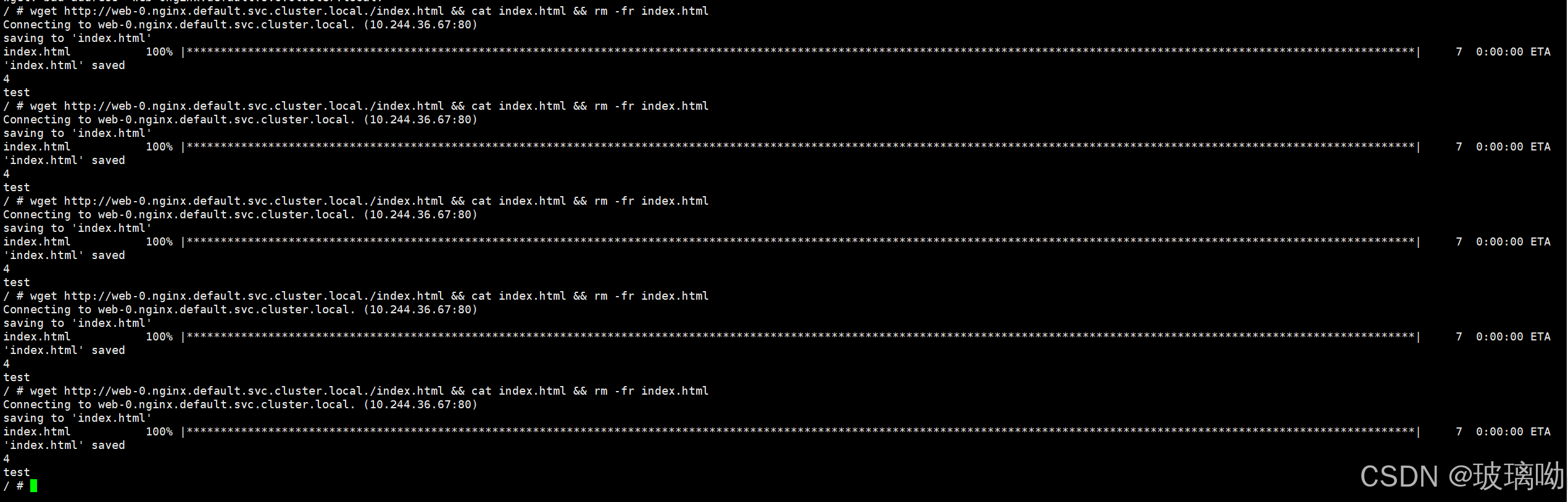
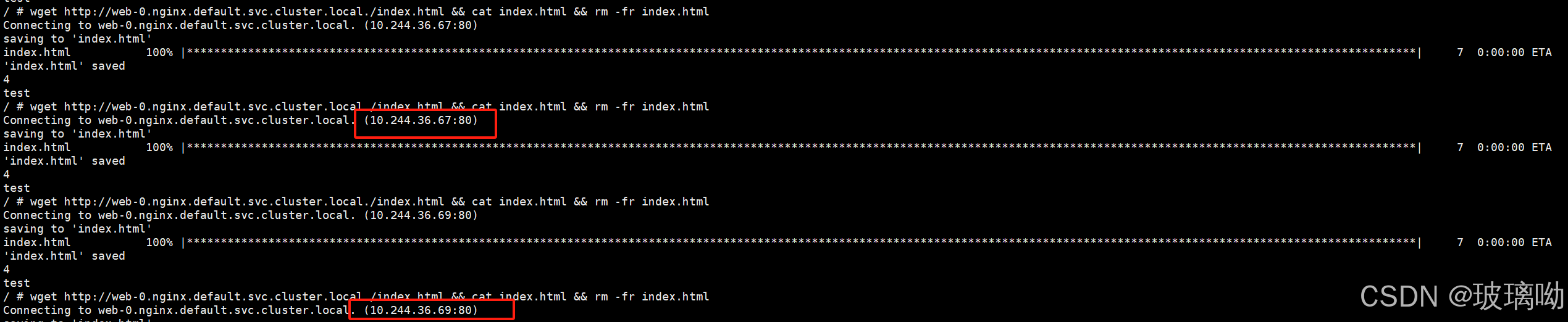
删除pod web-0后在访问看看,如下图所示,访问的是同个域名但是可以发现pod的ip是变了的,佐证了域名的稳定性访问
Service-无头服务(Headless Services)
生产环境中有时并不需要负载均衡,也不需要单独的 ServiceIP。遇到这种情况,可以通过显式设置 集群 IP(spec.clusterIP)的值为 "None" 来创建无头服务(Headless Service)。可以使用无头 Service 与其他服务发现机制交互,而不必绑定到 Kubernetes 的实现。
无头 Service 不会获得集群 IP,kube-proxy 不会处理这类 Service, 而且平台也不会为它们提供负载均衡或路由支持。见下图

但是和svc同名的endpoint却是有记录的

前面提到过SVC底层实现是将SVC的标签选择器匹配到的podIP记录到端点中,再由kube-proxy将规则维护至ipvs中,由每个节点的kube-proxy进程为SVC实现VIP的效果。
但是现在clusterIP为空,没了VIP,endpoint还记录端点信息有什么用呢?
写DNS记录
之前说到过SVC的默认域名为svcName.namespace.svc.cluster.local.从这个规则的域名可以解析出svc的clusterIP,但是现在svc是无头服务,没有了clusterIP解析他有什么意义呢?
先来尝试解析试验下,看看结果
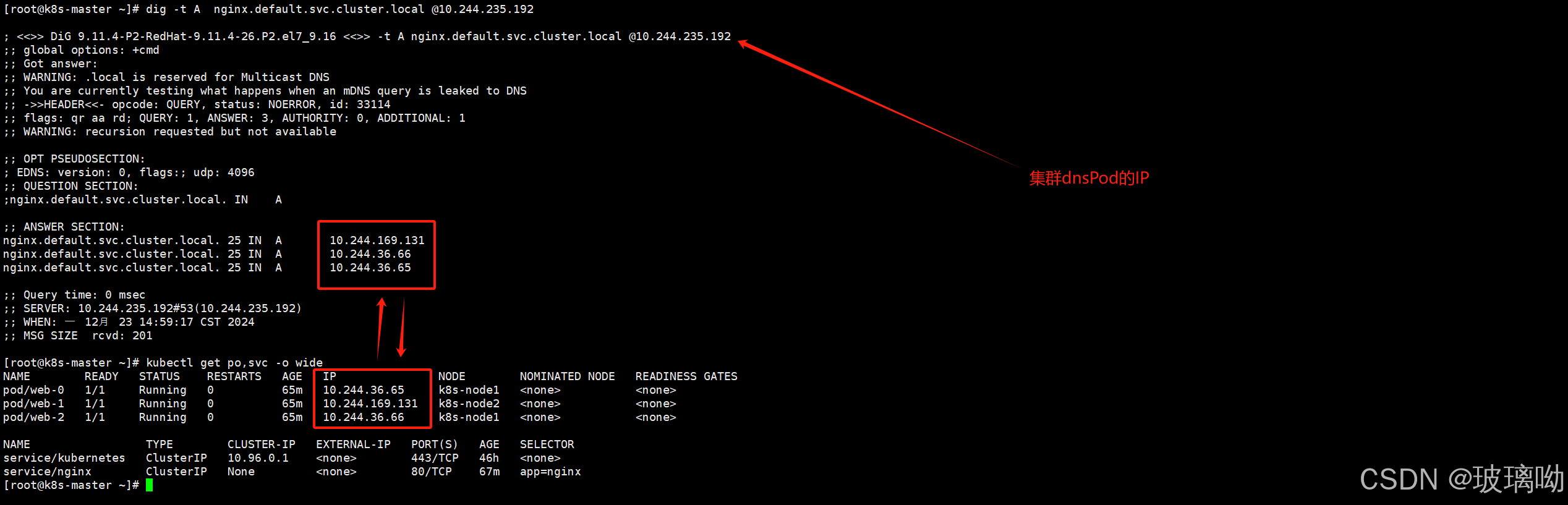
从上图解析结果来看,没有clusterIP的情况下解析出了三个IP,并且这三个IP是StatefulSet控制器所创建出来的pod。由此可以得出结论:无头服务会将SVC标签选择器所匹配到的Pod,添加到当前SVC的DNS解析结果中
PV的回收
实验做完之后删除控制器,可以看到控制器和pod已经被删除了,但是pvc和pv还是有绑定关系的。因为它害怕当前的StatefulSet控制器运行出来的pod的持久化文件被自动抹除,所以PVC不会进行自动删除。

看上图,前面提过pod死亡后pvc成为了孤立状态,并且和pv是绑定的。所以pvc是需要手动进行删除来释放PV的
而且当再次根据同一个资源清单创建这个StatefulSet的资源对象的时候,会出现一种情况,试一下

看上图,再次创建控制器时,然后访问web-0还是之前的页面,这说明pod又自动挂载了pvc。因为控制器名字没变,其次pv模板的名字没变,所以pvc会复用之前的配置
所以工作中如果不确定数据后期会不会再次使用的话,只删除StatefulSet控制器即可,保留pvc
继续PV的回收,删除PVC,如下图,删除了web-0的PVC后PV立即被释放恢复了Avaliable可用状态

在继续删除web-1的PVC。如下图,删除的web-1的PVC后PV却没有被释放,处于一个Relaeased已释放,但是数据仍然保留,PV 尚未被重新分配或清理的这么一个情况。如果想清理数据的话就需要手动删除nfs共享目录的数据

这里只演示解除与PVC的绑定关系,命令如下
kubectl edit resourceKind resourceName
#修改资源信息,修改PV和PVC的绑定关系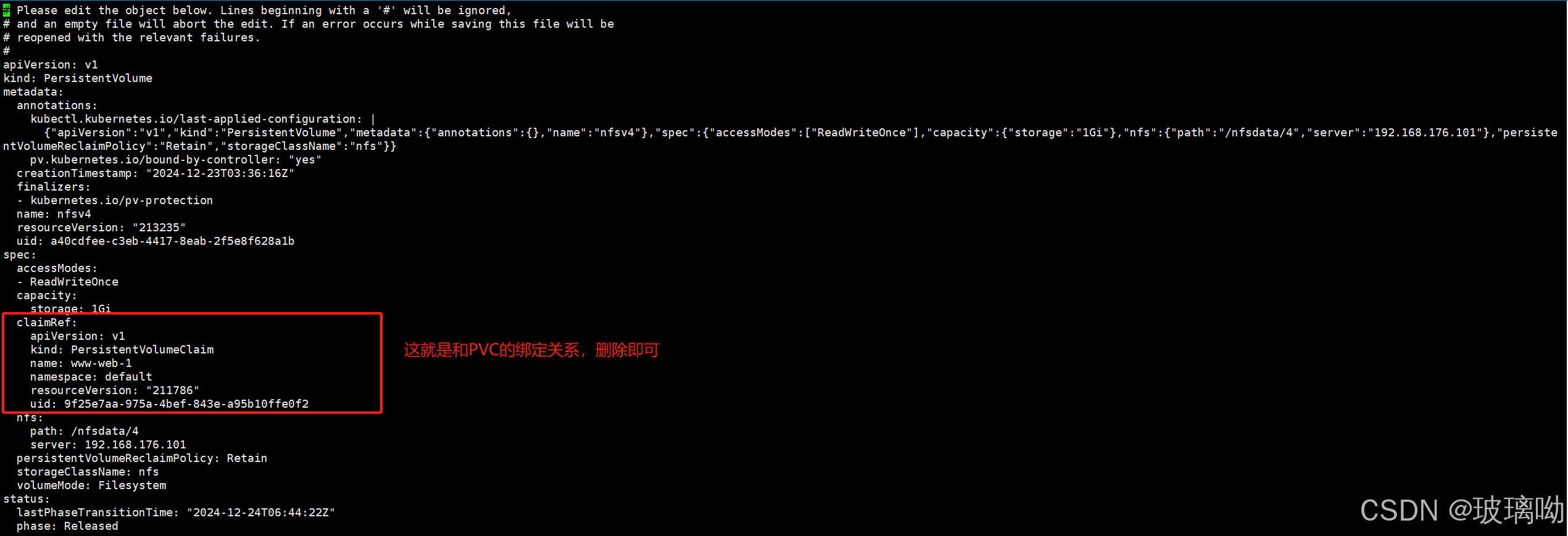
再查看PV,如下图,PV已经被释放

再删除web-2,看下图,PV状态是回收失败。因为前面提到过nfs不支持delete策略

继续用kubectl edit删除PV的绑定信息即可,看下图,释放成功

storageClass(存储类)
它实现动态申请存储的机制
StorageClass是一种资源对象,用于定义持久卷(PersistentVolume)的动态供给(DynamicProvisioning)策略。StorageClass允许管理员定义不同类型的存储,并指定如何动态创建持久卷以供应用程序使用。这使得k8s集群中的存储管理更加灵活和自动化.
- 静态PV:静态 PV 是由集群管理员提前创建的,通常用于某些需要明确控制存储资源的场景。需要管理员手动创建 PV 资源,并指定存储细节(如存储大小、存储类型、访问模式等。虽然满足要求,但并不是最好的。假设申请1.98T的PV。存储部门不可能这样划分的,它会给你2T,这样就造成了资源的浪费
- 动态PV:云存储服务会直接将他的服务抽象到集群内部形成一个PV,这个PV可以理解为一个通道。然后直接写PVC,在通过PVC清单要求的容量大小、类型自动划分
从分类介绍可以看出两者区别在于:静态先创建PV,PVC根据PV的情况走。动态是先写PVC,PV按照PVC的要求自动划分,更加灵活
所以StorageClass更多是配合云厂商实现,毕竟只有大厂才有专业的存储部门。存储类就是指不同厂商的存储服务
开始实验,这个实验要用到nfs-client-provisioner它是一个k8s的动态存储分配器,它为nfs存储提供支持。这个镜像是开源的,用它来模拟一个云厂商的StaaS(存储即服务)
搭建nfs服务器,配置远程挂载路径。步骤按照上面进行,在/nfsdata下创建share

在创建命名空间
kubectl create ns nfs-storageclass在创建控制器,模拟k8s的动态存储分配器nfs-client-provisioner,创建一个存储类
apiVersion: apps/v1 # 指定 API 版本为 apps/v1,用于部署 Deployment 资源
kind: Deployment # 定义资源类型为 Deployment
metadata: # 元数据部分
name: nfs-client-provisioner # Deployment 的名称
namespace: nfs-storageclass # 所属的命名空间
spec: # Deployment 的具体规格
replicas: 1 # 定义副本数为 1,只有一个 Pod 实例
selector: # 定义 Pod 的选择器,用于匹配 Pod 的标签
matchLabels:
app: nfs-client-provisioner # 匹配标签为 app=nfs-client-provisioner
strategy:
type: Recreate # 策略为 Recreate,每次更新会重建 Pod
template: # Pod 模板
metadata:
labels:
app: nfs-client-provisioner # 定义 Pod 的标签
spec:
serviceAccountName: nfs-client-provisioner # 指定 ServiceAccount,用于访问 Kubernetes API
containers: # 定义容器列表
- name: nfs-client-provisioner # 容器名称
image: registry.cn-beijing.aliyuncs.com/mydlq/nfs-subdir-external-provisioner:v4.0.0 # 使用的容器镜像
volumeMounts: # 定义挂载的存储卷
- name: nfs-client-root # 存储卷名称
mountPath: /persistentvolumes # 容器内的挂载路径
env: # 定义环境变量
- name: PROVISIONER_NAME # 动态存储供应器的名称
value: k8s-sigs.io/nfs-subdir-external-provisioner
- name: NFS_SERVER # 指定 NFS 服务器的地址
value: 192.168.176.101
- name: NFS_PATH # 指定 NFS 服务器共享的路径
value: /nfsdata/share
volumes: # 定义存储卷
- name: nfs-client-root # 存储卷名称
nfs: # 使用 NFS 类型的存储卷
server: 192.168.176.101 # 指定 NFS 服务器的地址
path: /nfsdata/share # 指定 NFS 服务器共享的路径
创建sa,这个后面安全的章节会学到,照着做就行现在看不懂的
apiVersion: v1 # 定义 API 版本
kind: ServiceAccount # 定义资源类型为 ServiceAccount
metadata:
name: nfs-client-provisioner # ServiceAccount 名称
namespace: nfs-storageclass # 所在命名空间
---
kind: ClusterRole # 定义资源类型为 ClusterRole
apiVersion: rbac.authorization.k8s.io/v1 # 使用 RBAC API 版本
metadata:
name: nfs-client-provisioner-runner # ClusterRole 名称
rules:
- apiGroups: [""] # 空字符串表示核心 API 组
resources: ["nodes"] # 允许操作的资源类型
verbs: ["get", "list", "watch"] # 授权的操作
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"] # 非核心 API 组
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding # 定义资源类型为 ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-client-provisioner # ClusterRoleBinding 名称
subjects:
- kind: ServiceAccount # 绑定到的资源类型
name: nfs-client-provisioner # ServiceAccount 名称
namespace: nfs-storageclass # ServiceAccount 所在命名空间
roleRef: # 绑定到的 ClusterRole
kind: ClusterRole
name: nfs-client-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role # 定义资源类型为 Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner # Role 名称
namespace: nfs-storageclass # Role 所在命名空间
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding # 定义资源类型为 RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-client-provisioner # RoleBinding 名称
namespace: nfs-storageclass # RoleBinding 所在命名空间
subjects:
- kind: ServiceAccount
name: nfs-client-provisioner
namespace: nfs-storageclass
roleRef:
kind: Role
name: leader-locking-nfs-client-provisioner
apiGroup: rbac.authorization.k8s.io
---
apiVersion: storage.k8s.io/v1 # 定义 API 版本
kind: StorageClass # 定义资源类型为 StorageClass
metadata:
name: nfs-client # StorageClass 名称
provisioner: k8s-sigs.io/nfs-subdir-external-provisioner # 定义动态存储分配的 Provisioner
parameters: # 自定义参数
pathPattern: ${.PVC.namespace}/${.PVC.name} # NFS 路径模板
onDelete: delete # 删除 PV 时也删除对应的 NFS 子目录创建测试pod和PVC
apiVersion: v1 # 定义 API 版本,v1 是 PersistentVolumeClaim 的稳定版本
kind: PersistentVolumeClaim # 定义资源类型为 PersistentVolumeClaim
metadata:
name: test-claim # PVC 的名称,用于后续绑定
annotations: # 此处为空,可以省略
spec:
accessModes:
- ReadWriteMany # 定义访问模式,此模式支持多个节点同时读写
resources:
requests:
storage: 1Mi # 申请的存储大小为 1Mi
storageClassName: nfs-client # 指定 StorageClass 名称,需与实际配置的匹配
---
apiVersion: v1 # 定义 API 版本,v1 是 Pod 的稳定版本
kind: Pod # 定义资源类型为 Pod
metadata:
name: test-pod # Pod 的名称
spec:
containers:
- name: test-container # 容器名称
image: nginx:one # 容器使用的镜像,需确保镜像有效
imagePullPolicy: IfNotPresent # 镜像拉取策略,若本地已存在镜像则不重新拉取
volumeMounts:
- name: nfs-pvc # 挂载的存储卷名称,需与 volumes 中定义一致
mountPath: /usr/share/nginx/html # 容器内挂载路径
restartPolicy: Never # Pod 的重启策略,Never 表示任务运行一次后不重启
volumes:
- name: nfs-pvc # 定义存储卷名称
persistentVolumeClaim:
claimName: test-claim # 绑定的 PersistentVolumeClaim 名称
成功了。。。安全部分我看着也懵先不讲解了,学了安全再回来看 
然后访问pod被拒绝,因为原本的index.html文件被挂载的存储覆盖了,重新写一个就行。

我就在nfs共享中写了
 删除pod后PV/PVC都会消失
删除pod后PV/PVC都会消失

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)