垂直SFT如何解决灾难性遗忘、过拟合?
内容提要:本文系统分析垂直领域指令微调(SFT)中的核心痛点,深入解析Y-Trainer框架中的NLIRG算法原理与实践应用。通过真实案例与可复现代码,展示如何在不依赖通用语料的情况下,有效解决模型复读、能力退化与输出不稳定问题。文末提供完整的训练流程、验证方法与性能优化技巧,助你高效构建专业领域大模型。
一、困局:垂直微调中的"能力跷跷板"现象
在垂直领域大模型应用开发中,我们常陷入一种尴尬境地:模型专业能力与通用能力如同跷跷板的两端,此消彼长。当我们在医疗、法律或金融等专业领域进行微调后,模型常出现令人头疼的问题组合:
-
专业与基础的失衡:能精准回答"心肌梗死的临床诊断标准",却无法正常回应"你好"这样的基础问候
-
表达僵化:面对相似问题,反复使用相同句式与结构,像被设定好程序的机器
-
格式飘忽:训练数据中结构严谨,上线后JSON格式错误频发,字段丢失或错位
传统的应对策略往往效果有限:
-
调整学习率?→ 专业能力与基础能力双双受限
-
混合通用语料?→ 训练成本翻倍,专业性被稀释
-
增加数据量?→ 优质垂直数据难以获取,清洗标注成本高昂
这引出了一个关键问题:是否有可能在保持基础能力的同时,提升垂直领域专业性? 本文将通过Y-Trainer框架及其核心NLIRG算法,探索这一问题的系统性解决方案。

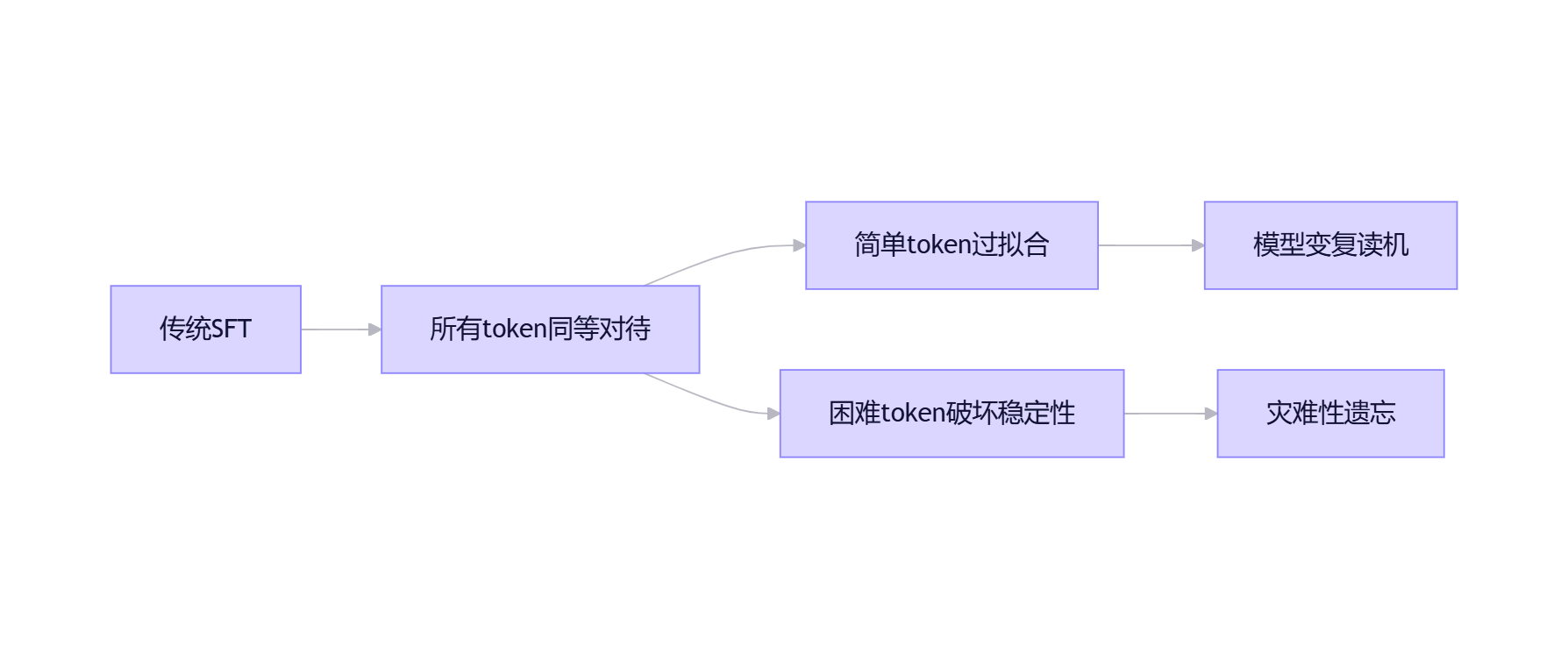
二、溯源:SFT训练中的梯度分配失衡
2.1 重新认识SFT:token级梯度才是关键
在指令微调过程中,一个核心但常被忽视的事实是:真正驱动模型学习的是每个token产生的梯度,而非样本整体。每个训练样本中的不同token对模型更新的贡献差异巨大,这直接影响最终模型的行为特性。
2.2 两大失衡现象及其连锁反应
极端1:简单token过度训练
垂直领域数据包含大量固定模式:法律文书中的"依据《XX法》第X条"、医疗记录中的"主诉:..."、客服对话中的固定开场白。这些token在训练早期就达到低loss状态,但持续接受高强度训练,导致:
-
模型过度依赖固定表达模式
-
稍微变化的输入导致输出不稳定
-
生成内容冗余度高,信息密度低
极端2:困难token引发过度调整
垂直数据中不可避免存在噪声:专业术语拼写错误、标注不一致、截断不完整等问题。这些样本产生高loss token,引发强烈梯度更新,导致:
-
模型为适应少数困难样本,大幅调整参数
-
原有通用知识结构被破坏
-
训练过程不稳定,loss曲线剧烈波动
正如Y-Trainer技术文档指出:
"在训练过程中,简单样本和困难样本需要不同的学习强度。简单样本过度学习会导致过拟合;困难样本过度学习会导致灾难性遗忘。"
三、传统方法的局限:治标不治本
解决垂直SFT问题的常见策略及其局限:
|
方法 |
机制 |
局限性 |
实际痛点 |
|
混合通用语料 |
通过通用数据维持基础能力 |
数据获取/清洗成本高;比例难以确定 |
合规限制下无法使用外部数据 |
|
降低学习率 |
减缓参数更新速度 |
专业能力提升不足;训练效率低下 |
项目时间压力下难以接受 |
|
增加正则化 |
限制模型复杂度 |
无法区分有价值/无价值的学习信号 |
专业细节能力建设受阻 |
这些方法本质是"数据层面"的修补,未能解决"训练信号分配"这一根本问题。就像给不同学习能力的学生布置相同的作业,而不考虑个体差异。
四、NLIRG:基于梯度的非线性学习强度调节
4.1 核心思想:让学习强度与难度匹配
NLIRG (Nonlinear Learning Intensity Regulation) 算法通过分析每个token的loss值,动态计算梯度权重,实现训练强度的智能分配:
def dynamic_sigmoid_batch(losses, max_lr=1.0, x0=1.2, min_lr=5e-8,
k=1.7, loss_threshold=3.0, loss_deadline=15.0):
"""
基于损失值的动态权重计算
参数说明:
- losses: 损失值张量,形状为[batch_size, seq_len]
- max_lr: 最大梯度权重(默认1.0),控制增强上限
- x0: 低loss区间分界点(默认1.2)
- min_lr: 最小梯度权重(默认5e-8),防止梯度完全消失
- k: sigmoid曲线斜率(默认1.7)
- loss_threshold: 中高loss分界(默认3.0)
- loss_deadline: 梯度归零阈值(默认15.0)
返回:与losses相同形状的权重张量
"""
# 实际实现包含多个sigmoid函数的组合
# 完整代码请参考官方GitHub仓库这一设计代表了训练理念的转变:从"所有token同等重要"到"精准分配学习资源"。
4.2 四区间梯度分配策略
NLIRG将token loss分为四个区间,应用不同梯度策略:
|
loss区间 |
梯度处理 |
作用机制 |
实际收益 |
|
loss ≤ 1.45 |
梯度削减 |
降低已掌握知识的学习强度 |
减少模板化输出,提升表达多样性 |
|
1.45 < loss < 6.6 |
梯度增强 |
集中资源攻克有价值内容 |
加速专业能力提升,提高学习效率 |
|
6.6 < loss < 15 |
梯度削减 |
限制困难样本的影响范围 |
保持训练稳定性,防止参数大幅波动 |
|
loss ≥ 15.0 |
梯度归零 |
隔离明显异常的训练信号 |
避免噪声数据污染模型,提升鲁棒性 |
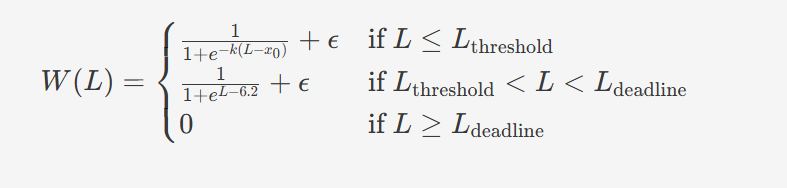
NLIRG权重计算公式,L为损失值,W(L)为对应权重
本质洞察:最有效的学习发生在"适度挑战区"(1.45 < loss < 6.6)。这与教育心理学中的"最近发展区"理论一致——学习材料应当略高于当前能力水平,但又不至于遥不可及。
五、实战部署:从零搭建NLIRG训练流程
5.1 环境配置指南
# 获取源代码
git clone https://github.com/yafo-ai/y-trainer.git
cd y-trainer
# 安装基础依赖
# 注意:确保peft包名完整,无断行
pip install torch peft>=0.10.0 tensorboard matplotlib
pip install -r requirements.txt
# 验证环境
python -c "import torch; print(f'PyTorch版本: {torch.__version__}, CUDA可用: {torch.cuda.is_available()}')"配置建议:
-
单卡训练:跳过deepspeed安装,简化依赖
-
低显存环境(<24GB):必须启用LoRA与梯度检查点
-
Windows用户:建议使用WSL2环境,避免路径兼容性问题
5.2 垂直领域SFT训练配置
# 单卡LoRA训练配置
python -m training_code.start_training \
--model_path_to_load Qwen/Qwen3-1.5B \
--training_type 'sft' \
--use_NLIRG 'true' \ # 启用核心算法
--use_lora 'true' \ # 启用LoRA
--lora_rank 8 \ # LoRA秩,垂直领域建议8-16
--lora_alpha 32 \ # LoRA缩放因子
--lora_target_modules "q_proj,k_proj,v_proj,o_proj,gate_proj,up_proj,down_proj" \
--batch_size 1 \ # 单卡典型值
--token_batch 10 \ # 控制每次反向传播的token数量
--learning_rate 2e-5 \ # 垂直SFT推荐学习率
--epoch 3 \ # 训练轮次
--data_path domain_data.json \
--output_dir nlirg_sft_results \
--save_strategy "epoch" # 保存策略关键参数解读:
-
--token_batch:SFT训练的核心参数,控制每次反向传播的token数量。值越小,NLIRG效果越精确,但训练速度越慢。根据Y-Trainer文档,SFT训练必须设置此参数 -
--use_NLIRG:默认开启,做对比实验时务必显式关闭 -
--lora_rank:垂直领域建议8-16,高于通用场景的4-8,以捕捉更细粒度的专业知识
5.3 继续预训练(CPT)多卡配置
# 4卡DeepSpeed训练配置
deepspeed --master_port 29555 --include localhost:0,1,2,3 \
--module training_code.start_training \
--model_path_to_load Qwen/Qwen3-8B \
--training_type 'cpt' \
--use_NLIRG 'true' \
--use_deepspeed 'true' \
--deepspeed_config_path "configs/deepspeed/ds_config_zero3.json" \
--pack_length 2048 \ # 短文本打包长度
--batch_size 2 \ # 每卡batch size
--gradient_accumulation_steps 4 \ # 梯度累积步数
--learning_rate 1e-5 \
--epoch 1 \
--data_path large_corpus.json \
--output_dir cpt_results六、效果验证:超越loss的多维评估体系
6.1 科学对照实验设计
# 对照组(无NLIRG)
python -m training_code.start_training \
--use_NLIRG 'false' \ # 显式关闭
--model_path_to_load Qwen/Qwen3-1.5B \
--training_type 'sft' \
--use_lora 'true' \
--batch_size 1 \
--token_batch 10 \
--data_path medical_data.json \
--output_dir baseline_run
# 实验组(启用NLIRG)
python -m training_code.start_training \
--use_NLIRG 'true' \ # 显式开启
--model_path_to_load Qwen/Qwen3-1.5B \
--training_type 'sft' \
--use_lora 'true' \
--batch_size 1 \
--token_batch 10 \
--data_path medical_data.json \
--output_dir nlirg_run实验设计原则:
-
除
--use_NLIRG参数外,其他配置必须完全一致 -
使用相同随机种子,确保可复现性
-
至少重复3次实验,减少随机波动影响
6.2 多维度评估框架
构建三层次评估体系,避免单一指标误导:
|
评估层面 |
评估项目 |
评估方法 |
合格标准 |
|
专业能力 |
领域问题准确率 |
专业测试集(200+样本) |
>85% |
|
专业术语使用准确率 |
人工评估(3位专家) |
>90% |
|
|
基础能力 |
指令遵循率 |
通用指令测试集(100+样本) |
>80% |
|
常识问答准确率 |
常识QA基准测试 |
与基线模型差距<10% |
|
|
输出质量 |
文本重复率(3-gram) |
自动化脚本计算 |
<25% |
|
格式符合率 |
正则表达式验证 |
>90% |
评估工具推荐:
# 简易重复率计算工具
def calculate_repetition(text, n=3):
"""计算n-gram重复率"""
words = text.split()
ngrams = [' '.join(words[i:i+n]) for i in range(len(words)-n+1)]
return 1 - len(set(ngrams)) / max(1, len(ngrams))
# 格式验证示例(JSON)
import json
def validate_json_format(output):
try:
json.loads(output)
return True
except json.JSONDecodeError:
return False6.3 训练过程监控
# 启用TensorBoard日志
python -m training_code.start_training \
--use_tensorboard 'true' \
--tensorboard_path ./tb_logs \
# 其他参数...
# 启动TensorBoard
tensorboard --logdir=./tb_logs --port=6060
关键监控指标:
-
梯度分布热力图:观察NLIRG是否按预期调整不同loss区间的梯度
-
验证集性能曲线:及时发现过拟合迹象
-
token级loss分布:评估数据质量与模型适应性
七、进阶技巧:提升训练效率与效果
7.1 语料质量预评估
训练前使用Y-Trainer内置工具评估数据质量:
python -m training_code.utils.schedule.sort \
--data_path raw_corpus.json \
--output_path evaluated_corpus.json \
--model_path Qwen/Qwen3-8B \
--mode "similarity_rank" \
--batch_size 4评估指标解读:
-
高分语料(>0.8):高质量,优先训练
-
中分语料(0.5-0.8):有价值,正常训练
-
低分语料(<0.3):可能存在错误,建议人工审核
实际案例:在某金融客服数据集中,语料评估发现17%的样本存在格式错误或内容矛盾,修复后模型专业问题准确率提升6.2%。
7.2 资源受限环境优化策略
不同硬件配置的参数建议:
|
硬件配置 |
关键参数组合 |
预期效果 |
|
24GB显存单卡 |
|
平衡速度与效果 |
|
16GB显存单卡 |
|
保证可训练性 |
|
4x A100集群 |
|
最大化吞吐量 |
经验法则:
-
优先保证
token_batch不低于5,再考虑其他参数调整 -
显存紧张时,梯度检查点比降低batch_size更有效
-
LoRA秩(rank)设置:垂直领域专业模型建议8-16,通用能力增强建议4-8
八、应用场景决策指南
8.1 推荐使用场景
核心价值场景:
-
合规限制环境:无法获取或使用通用语料的金融、医疗场景
-
数据质量不稳定:众包标注或爬取的垂直数据,存在噪声
-
训练资源受限:单卡或小集群环境,需要高效训练
-
快速迭代需求:产品需要频繁更新模型,无法承受长时间调参
效果预期(基于多个垂直领域测试):
-
通用能力保持率提升:15-25%
-
专业问题准确率提升:3-8%
-
重复内容减少:40-60%
-
训练稳定性提升:loss波动减少50%+
8.2 谨慎使用场景
-
通用对话系统:本身需要混合语料训练,NLIRG优势不明显
-
超大规模训练:超过64卡的集群,可能需要定制分布式策略
-
数据已高度优化:经过严格清洗和平衡的数据集,收益可能有限
总结:回归训练本质,做模型的"智能教练"
垂直领域SFT训练的核心挑战,本质是训练信号的精准分配问题。NLIRG算法通过token级梯度调控,实现了从"粗放式训练"到"精准化教学"的转变,就像一位懂得因材施教的老师,知道何时该重点讲解,何时该略过不提。
实践建议路径:
-
小规模验证:选取100-200条代表性数据,进行NLIRG开启/关闭对照
-
建立评估基准:构建包含专业能力、通用能力和输出质量的测试集
-
渐进式应用:从核心算法NLIRG开始,逐步尝试语料评估、资源优化等进阶功能
-
持续监控:部署后持续收集bad case,反向优化训练策略
"无需依赖通用语料,即可卓越地保留模型的泛化能力,守住核心能力的同时实现专项提升。通过模型内部信号,可以对语料进行质量评分,提早排查错误。"
在这个大模型应用爆发的时代,训练方法的创新比算力堆砌更能带来突破。NLIRG算法提供了一种新思路:不靠更多数据,而靠更聪明的训练。当你面对垂直领域微调困境时,不妨尝试这一方法,或许能带来意想不到的突破。
资源汇总
你在垂直领域模型训练中遇到过哪些挑战?NLIRG算法对你有哪些启发?欢迎在评论区分享你的实践经验,一起探讨大模型训练的最佳实践!
#大模型 #AI训练 #垂直领域 #算法优化

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)