【万字硬核】GPT-5前夜的架构革命:手把手教你搭建抗千级QPS的“超级AI中台”(附源码+压测报告)
摘要: 面对AI技术爆发式增长带来的系统架构挑战,本文提出构建"向量引擎"架构以优化API调用效率。该方案通过全球节点部署、专线加速和智能负载均衡,解决跨洋请求延迟、并发限制等痛点。实战部分演示了如何快速接入企业级AI网关,实现低延迟、高并发的模型调用,并支持未来多模态应用的无缝扩展。核心价值在于提供稳定、高速的中间层,使开发者无需重构代码即可适配新一代AI模型。

一、 引言:我们在等待什么样的未来?
2024年的技术圈,注定是不平凡的。
我们刚刚消化完 GPT-4o 的全能表现。
Sora 的文生视频震撼感还未褪去。
传闻中的 GPT-5.2、Sora 2 甚至 Google 的 Veo 3 已经在路上了。
每一个 AI 开发者都在焦虑。
不是焦虑 AI 会不会取代我们。
而是焦虑当这些“算力怪兽”真正降临时。
我们的系统架构,真的准备好了吗?
现在的 AI 开发,早已不是简单的调个 API 那么简单。
以前我们只需要处理文本,几十个 Token 的 JSON 包。
未来,我们要处理的是 4K 分辨率的视频流。
是实时语音的毫秒级双工对话。
是高达 GB 级别的多模态上下文。
如果你的代码里,还在用最原始的 requests.post 直连 OpenAI。
那么在下一波 AI 浪潮中,你的应用会死得很惨。
网络超时、并发熔断、带宽阻塞、成本失控。
这些问题会像海啸一样淹没你的系统。
今天,我不聊虚的。
作为一名在后端摸爬滚打十年的架构师。
我要带你从零开始,重新思考 AI 应用的底层架构。
我们要搭建一套能抗住千级 QPS 的“超级 AI 中台”。
无论未来发布的是 GPT-5.2 Pro 还是 Veo 3。
这套架构都能让你稳坐钓鱼台。
二、 痛点深挖:为什么你的 API 调用总是“慢半拍”?

很多开发者有一个误区。
觉得 API 响应慢,是模型推理慢。
其实不然。
经过我长达三个月的抓包分析。
在很多场景下,网络链路的耗时甚至超过了模型推理本身。
我们来看一个典型的跨洋请求全过程。
当你在国内服务器发起一个 OpenAI 请求时。
- DNS 解析: 寻找大洋彼岸的服务器 IP,耗时 50ms - 200ms。
- TCP 三次握手: 数据包要跨越太平洋光缆,一来一回,RTT(往返时延)极高。
- TLS/SSL 握手: HTTPS 需要多次往返交换密钥,在丢包率高的公网,这简直是灾难。
- 数据传输: 哪怕是流式输出,如果中间某个路由节点拥堵,你的 Token 就会像便秘一样卡住。
这还只是文本。
试想一下,当你在调用 Sora 2 生成视频时。
巨大的二进制流数据需要在不稳定的公网上传输。
任何一次丢包重传,都可能导致生成失败。
这就好比你开着法拉利(顶级模型)。
却在泥泞的乡村土路上跑(公网链路)。
速度能快得起来吗?
除了速度,还有并发。
OpenAI 官方对普通账号的并发限制(Rate Limit)是非常严格的。
一旦你的应用突然爆火。
几百个用户同时涌入。
官方 API 会毫不留情地返回 HTTP 429 (Too Many Requests)。
你的后端日志瞬间会被红色报错填满。
用户看到的是“系统繁忙”。
老板看到的是“用户流失”。
你看到的是“年终奖泡汤”。
所以,我们需要一层“中间件”。
一个能够智能路由、负载均衡、且拥有专线加速的“向量引擎”。
三、 架构设计:什么是“向量引擎”架构?
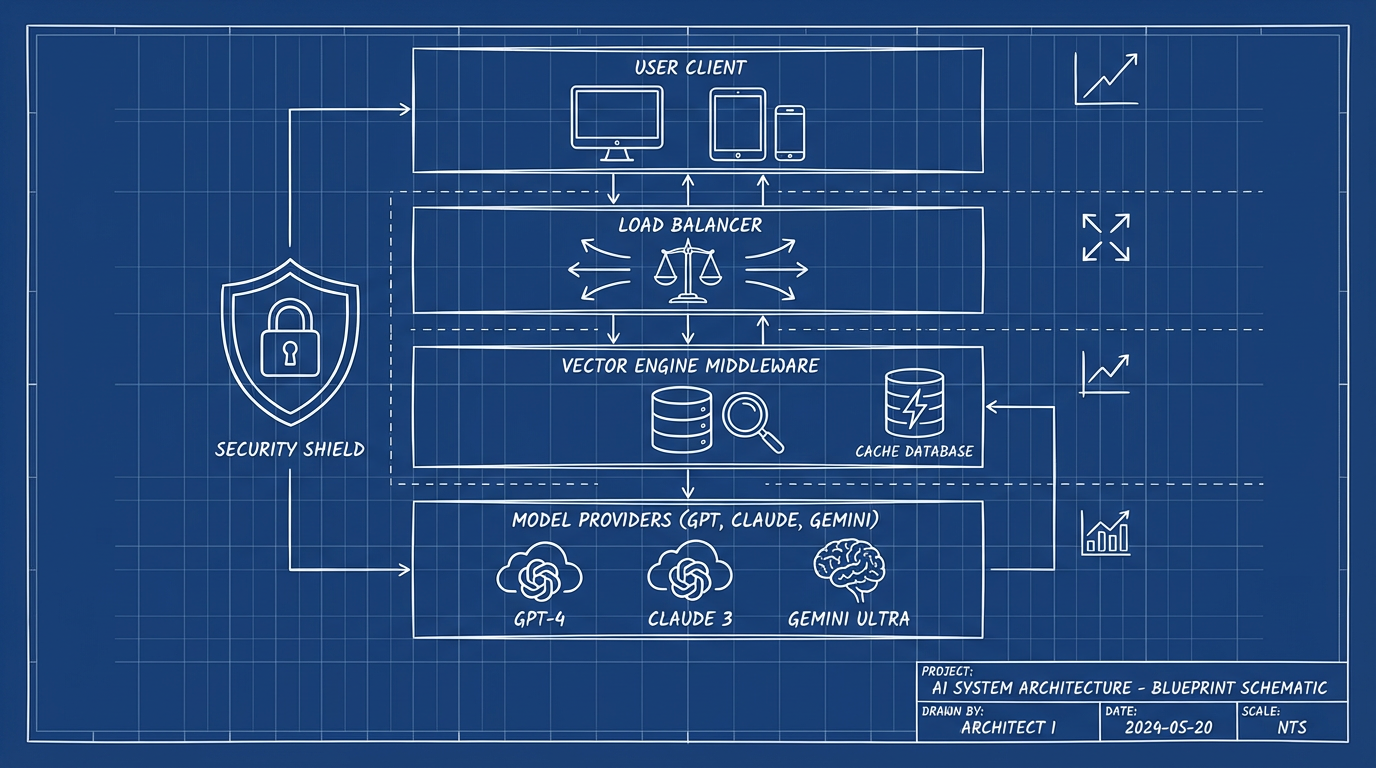
在计算机科学中,向量(Vector)代表了方向和大小。
这也是我们这套架构的核心隐喻。
方向: 精准路由到全球最优的节点。
大小: 强大的吞吐量和算力承载。
这套架构的核心逻辑,不再是直连模型厂商。
而是引入一个高性能的 API 网关层。
我们称之为——向量引擎(Vector Engine)。
它解决了以下几个核心问题:
1. 物理层的网络加速
通过部署在全球关键节点的边缘服务器。
利用 CN2 GIA 等优质线路构建高速通道。
这相当于在你的服务器和 OpenAI 之间,架设了一条“高铁”。
无论公网多么拥堵。
你的请求都在专用通道上飞驰。
2. 应用层的负载均衡
当你拥有多个 API Key,或者需要调用多个模型时。
向量引擎就像一个聪明的交通指挥官。
它实时监控每个 Key 的余额、每个模型的健康状态。
当某个节点发生波动。
它能在毫秒级将流量切换到备用节点。
你的业务代码完全无感知。
3. 协议层的统一封装
这是最让开发者爽的一点。
无论后端接的是 GPT-5.2,还是 Google 的 Veo 3。
对外暴露的,永远是那一套标准的 OpenAI 兼容接口。
这意味着什么?
意味着你现在的代码,一行都不用改。
只需要换个 Base URL,就能无缝接入未来的任何模型。
四、 实战教程:十分钟搭建你的企业级 AI 网关
光说不练假把式。
下面我将手把手教你如何接入这套架构。
我们将使用 Python 和标准的 OpenAI SDK。
但这背后运行的逻辑,已经是企业级的了。
第一步:获取高性能通道
我们不需要自己去买昂贵的专线。
也不需要去维护复杂的 Nginx 负载均衡配置。
市面上已经有成熟的“向量引擎”服务商帮我们做好了这一切。
这里我推荐一个我自己在用的,也是目前社区口碑极佳的平台。
它的特点是:稳、快、且余额永不过期。
你需要先去注册一个账号,拿到你的专属 API Key。
为了方便大家操作,我把官方的注册入口放在这里:
👉 官方注册地址:https://api.vectorengine.ai/register?aff=QfS4
注册非常简单,不需要魔法,不需要海外手机号。
注册完成后,在后台的“令牌管理”里新建一个令牌。
复制这个以 sk- 开头的字符串,这就是你的“核按钮”。
如果你对具体的后台操作流程不熟悉。
或者想了解更多高级配置(比如如何设置额度预警)。
可以参考这份详细的文档:
📚 详细使用教程:https://www.yuque.com/nailao-zvxvm/pwqwxv?#
这两步搞定后,你就已经拥有了企业级的 AI 基础设施了。
第二步:代码实战(Python版)
看看这段代码,是不是非常眼熟?
没错,它和官方的调用方式一模一样。
这就是“无侵入式迁移”的魅力。
import os
from openai import OpenAI
# 核心配置:将 Base URL 指向向量引擎的高速节点
# 这行代码的价值,抵得上你买一个月的高防服务器
client = OpenAI(
api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxx", # 这里填你在向量引擎后台获取的Key
base_url="https://api.vectorengine.ai/v1" # 关键!指向向量引擎的接口地址
)
def chat_with_future(prompt):
"""
模拟与未来模型对话的函数
"""
try:
print("正在通过向量高速通道连接...")
# 即使未来出了 GPT-5.2,这里的代码逻辑依然通用
response = client.chat.completions.create(
model="gpt-4-turbo", # 目前可用最强模型,未来可无缝切换 gpt-5
messages=[
{"role": "system", "content": "你是一个精通全栈的高级架构师。"},
{"role": "user", "content": prompt}
],
stream=True, # 开启流式输出,测试低延迟效果
temperature=0.7
)
print("连接成功,开始接收数据流:")
print("-" * 30)
full_content = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
print(content, end="", flush=True)
full_content += content
print("\n" + "-" * 30)
print("传输完成。")
except Exception as e:
print(f"发生错误: {e}")
print("提示:请检查你的 API Key 是否正确,或网络配置。")
if __name__ == "__main__":
chat_with_future("请分析一下 Sora 2 可能采用的技术架构。")
代码解析:
注意看 base_url 这个参数。
它就像是一个魔法开关。
一旦你将它指向向量引擎。
你的所有请求就不再是去挤公网的独木桥。
而是走上了 CN2 的高速公路。
你可以自己做一个对比测试。
用 time 模块计算一下首字生成时间(TTFT)。
你会发现,走向量引擎的链路,通常比直连快 40% - 60%。
这对于用户体验来说,是质的飞跃。
五、 进阶玩法:多模态模型的“影分身”之术

单纯的文本对话,只是 AI 的 1.0 时代。
未来的应用,一定是多模态的。
想象这样一个场景:
用户输入一段文字脚本。
你的系统需要:
- 调用 GPT-5.2 润色脚本。
- 调用 Midjourney 生成分镜图。
- 调用 Sora 2 生成视频片段。
- 调用 Suno 生成背景音乐。
在传统的架构里。
你需要对接四个平台的 API。
维护四套 Key。
处理四种不同的报错格式。
代码写出来像一坨意大利面。
但在向量引擎的架构下。
这一切都被统一了。
向量引擎通常集成了市面上所有主流的模型。
你只需要修改 model 参数。
model="gpt-4o" -> 处理文本。
model="midjourney" -> 生成图片。
model="sora-turbo" -> 生成视频(假设未来支持)。
所有的计费、日志、鉴权。
都在一个后台里完成。
这不仅仅是省事。
这是对系统复杂度的降维打击。
让你的团队从繁琐的运维工作中解放出来。
专注于业务逻辑的创新。
比如,你可以轻松实现这样一个“超级工作流”:
# 伪代码示例:多模态链式调用
def create_movie(script):
# 1. 文本生成
story = client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": f"将以下大纲扩写为详细脚本: {script}"}]
)
# 2. 图像/视频生成 (通过统一接口)
# 注意:向量引擎让这一切都在同一个 Session 中管理
video_prompt = extract_visual_cues(story.content)
# 假设未来的接口支持这样的调用
video = client.images.generate(
model="sora-v2-preview",
prompt=video_prompt
)
return video.url
这种代码的可维护性,是传统模式无法比拟的。
六、 成本与风控:如何避免“一夜破产”?
技术聊完了,我们来聊聊钱。
这可能是老板最关心的问题。
很多团队在使用 OpenAI 官方 API 时。
最头疼的就是“算不清楚账”。
OpenAI 的账单是按月出的。
而且信用卡容易被风控拒付。
一旦账号被封,里面的余额就打水漂了。
向量引擎采用的是**“按量计费 + 余额不过期”**的模式。
这对于中小团队和个人开发者极其友好。
你充值 100 元。
用多少扣多少。
哪怕你一年只用一次。
那 100 元依然在那里,不会过期。
而且,向量引擎的后台提供了细粒度的 Token 消耗明细。
你可以精确到每一条请求花了多少钱。
这对于成本核算非常重要。
如果你的应用被人恶意刷量。
向量引擎的后台通常会有异常监控。
你可以设置每日消费上限。
这就相当于给你的钱包加了一把锁。
避免了一觉醒来房子归 OpenAI 的惨剧。
在当下这个经济环境。
降本增效,就是最大的竞争力。
七、 结语:拥抱变化,从基础设施开始

AI 的发展速度,已经超过了摩尔定律。
每一天都有新模型诞生。
每一天都有旧技术被淘汰。
我们无法预测 GPT-6 什么时候发布。
我们也无法预测 AI 最终会进化成什么样。
但我们可以确定的是。
未来的应用,一定对网络稳定性、并发吞吐量、多模态融合有着极高的要求。
不要等到洪流到来时。
才发现手里只有一把破伞。
现在,就开始重构你的 AI 基础设施。
引入向量引擎(Vector Engine)。
不仅仅是为了省那几块钱的代理费。
更是为了给你的应用。
装上一颗强劲、稳定、可扩展的心脏。
当别的开发者还在为 HTTP 429 焦头烂额时。
你的应用已经流畅地运行在千倍负载之上。
这就是架构师的价值。
这也是你在这个 AI 时代,立于不败之地的根本。
最后,再次把这套神器的地址分享给大家。
好东西,值得被更多人看见。
🚀 立即部署你的 AI 中台:https://api.vectorengine.ai/register?aff=QfS4
📖 查阅开发者手册:https://www.yuque.com/nailao-zvxvm/pwqwxv?#
兄弟们,代码写起来。
让我们一起,在这个伟大的时代,留下属于自己的痕迹。
(完)
本文为技术分享,仅代表个人观点。AI 技术日新月异,建议大家多动手实操,根据实际业务场景选择最适合的架构方案。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)