大模型Token开销大?掌握这些实用技巧,轻松省下大笔预算!
文章介绍了大模型(LLM)Token成本的优化策略。Token是模型处理文本的基本单位,成本由输入和输出Token数量决定。通过四大策略可显著降低成本:精炼提示词、压缩与筛选上下文、控制模型输出以及优化系统架构。这些策略组合使用,能在不牺牲应用效果的前提下,降低高达80%的LLM使用成本,为开发者和企业提供实用的"省钱"方案。
一、前言
在人工智能大模型(LLM)如火如荼的今天,无论是开发者、创业者还是企业,都或多或少地感受到了模型调用成本的“甜蜜负担”。每次对话、每次API调用,背后都是按Token计费的“真金白银”。你是否曾看着账单心疼,感觉钱像流水一样花出去,却不知如何有效控制?
好消息是,优化Token使用并非高深莫测的黑科技。通过一系列清晰、实用的策略,你完全可以在不牺牲应用效果的前提下,大幅降低LLM使用成本。本文将为你拆解LLM Token的构成,并手把手教你从多个维度进行优化,目标直指节省80%的开销。无论你是技术开发者还是产品经理,这篇文章都将为你提供一套立即可行的“省钱”方案。
二、理解Token:成本的核心计量单位
在开始优化之前,我们必须先搞清楚我们花钱买的到底是什么。对于大多数LLM(如GPT系列、Claude等)而言,Token是计算使用量和成本的基本单位。
2.1 什么是Token?
简单来说,Token是模型处理文本的基本单元。它不等同于一个单词或一个汉字。在英文中,一个单词可能被拆分成多个Token(例如,“unbelievable”可能被拆成“un”、“believe”、“able”)。在中文里,通常一个汉字或一个常见的词语会被视为一个Token。
理解这一点至关重要,因为你的输入和输出文本长度,直接决定了Token的消耗数量。一个常见的误区是以为按“字”或“词”收费,实际上模型内部是按Token处理的。
2.2 Token成本如何计算?
调用LLM API的成本通常由两部分组成: - 输入Token(Prompt Tokens):你发送给模型的指令、上下文和问题。 - 输出Token(Completion Tokens):模型生成的回答。
总成本 = (输入Token数 + 输出Token数) * 每千Token单价。
例如,你发送了一段500 Token的提示词,模型生成了300 Token的回答,那么本次调用就消耗了800 Token。如果你的单价是$0.002 / 1K tokens,那么这次调用成本就是0.0016美元。
核心优化思路也就非常明确了:在保证任务完成质量的前提下,尽可能减少输入和输出的Token数量。
三、四大实战策略,手把手优化Token开销
掌握了基本原理后,我们进入实战环节。以下四个策略由浅入深,结合使用效果更佳。
3.1 策略一:精炼你的提示词(Prompt Engineering)
这是最直接、最有效的优化起点。冗长、模糊的提示词不仅效果差,还浪费Token。
优化技巧: - 明确指令,避免废话:直接告诉模型你需要它做什么。对比以下两种写法: - 低效:“你好,我这边有一个问题想请教一下,可能有点复杂,就是关于如何学习Python编程,你能给我一些比较全面和详细的建议吗?最好从基础开始。” - 高效:“为编程零基础的成年人,制定一个为期3个月的Python入门学习路径,包含每周主题和推荐资源。” 后者指令清晰,目的明确,使用的Token更少,模型反而更能理解你的意图。 - 使用系统消息(System Message)设定角色:在对话开始时,通过系统消息一次性定义模型的角色和行为准则,这比在每次用户消息中重复说明要节省得多。 - 结构化输入:对于复杂任务,使用清晰的标记如“###”、“—”或JSON格式来组织输入,帮助模型快速解析,有时能减少不必要的“思考”Token。
3.2 策略二:压缩与筛选上下文(Context Management)*
当你的应用需要向模型提供大量背景信息(如长文档、历史对话)时,上下文管理是节省开销的重中之重。
优化技巧: - 摘要而非全文投喂:不要将整篇文档都塞进Prompt。可以先让模型(或用更便宜的模型)对文档核心内容进行摘要,然后将摘要作为上下文。 - 向量检索(RAG)的精髓:在检索增强生成(RAG)系统中,不要返回所有相关的文档片段。设定一个相关性阈值,只返回最相关的1-3个片段。通常,最相关的一小部分信息足以支撑模型生成优质回答。 - 动态上下文窗口:不要总是携带完整的对话历史。可以设计逻辑,仅保留最近几轮对话和最关键的历史信息,将更早的对话进行摘要或直接丢弃。
3.3 策略三:控制模型输出(Output Control)
你不能控制模型想什么,但你可以引导它怎么说,说多少。
优化技巧: - 设定最大生成长度(max_tokens):始终为API调用设置一个合理的 max_tokens 参数。这不仅能防止生成过长(且昂贵)的无关内容,还能避免因超出上下文限制而导致的错误。 - 要求简洁回复:在提示词中直接加入“请用尽可能简洁的语言回答”、“请总结成三点”、“请用一句话概括”等指令。 - 指定输出格式:要求模型以列表、JSON、特定关键词等形式输出。结构化的输出通常比散漫的散文更精炼,也便于你的程序后续处理。
3.4 策略四:架构与模型选择(Architectural Optimization)
这是从系统设计层面进行的降本增效。
优化技巧: - 任务分流,善用“小模型”:并非所有任务都需要最强的GPT-4。你可以构建一个决策层:先用一个快速、廉价的模型(如GPT-3.5-Turbo)判断用户意图。如果是简单问答,直接用它回答;如果是复杂分析,再调用GPT-4。这样大部分简单请求的成本会大幅降低。 - 缓存重复结果:对于常见、答案固定的问题(如产品FAQ),可以将模型的回答缓存起来。下次遇到相同或高度相似的问题时,直接返回缓存结果,无需再次调用API。 - 微调(Fine-tuning)的长期价值:对于你有大量数据且任务固定的场景,考虑对较小模型(如Llama 3、Qwen等开源模型)进行微调。虽然初期有训练成本,但微调后的模型在特定任务上表现会非常精准,且每次推理的Token成本远低于调用GPT-4 API,长期来看性价比极高。
为了更直观地展示不同策略的效果,我们来看一个对比表格:
| 优化维度 | 具体措施 | 预期节省效果 | 实施难度 |
|---|---|---|---|
| 提示词精炼 | 指令清晰、使用系统消息、结构化 | 可节省10%-30%的输入Token | 低 |
| 上下文管理 | 摘要、向量检索精筛、动态上下文 | 在处理长文本场景下,可节省50%+的输入Token | 中 |
| 输出控制 | 设置max_tokens、要求简洁、指定格式 |
可节省20%-50%的输出Token | 低 |
| 架构优化 | 任务分流、缓存、微调小模型 | 整体成本可降低60%-90% | 高 |
四、总结
优化LLM的Token开销,本质上是一场关于“效率”的修行。它要求我们从“无脑调用API”转向“精心设计每一次交互”。
我们来回顾一下今天的核心内容: - 理解成本源头:Token是计费单元,优化就是减少不必要的输入和输出Token。 - 精炼提示词:用最清晰、最直接的语言与模型沟通,这是性价比最高的优化。 - 智能管理上下文:只给模型它“必须知道”的信息,而不是“可能有用”的所有信息。 - 驾驭模型输出:通过参数和指令,让模型的回答在满足需求的前提下尽可能简短。 - 优化系统架构:通过混合模型、缓存、微调等工程手段,从系统层面实现降本增效。
将这些策略组合运用,你完全有可能将LLM的应用成本降低80%甚至更多。省下来的每一分钱,都可以投入到更重要的产品迭代和创新中去。
希望这篇手把手的指南能为你打开思路,助你在AI应用的道路上行稳致远。从今天开始,就尝试优化你的下一个Prompt吧!
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
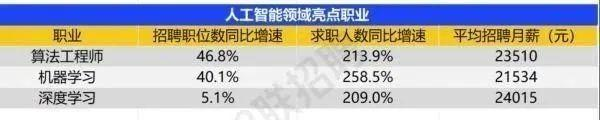
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 1
1- 0



 已为社区贡献498条内容
已为社区贡献498条内容

所有评论(0)