Java——集合进阶
本文系统介绍了Java集合框架的核心内容,主要包括:1. 集合与数组的对比,集合具有可变长度、只能存储引用类型等特点;2. Collection集合的常用操作方法(add/remove/contains等)及三种遍历方式(迭代器、增强for、普通for);3. List集合(有序可重复)的特有方法和两种实现类ArrayList(数组结构)与LinkedList(链表结构);4. Set集合(无序不
!!!文章篇幅较长,建议配合目录享用
一、集合与数组的对比
- 数组的长度是不可变的,集合的长度是可变的。
- 数组可以存基本数据类型和引用数组类型;集合只能存引用数据类型,如果要存基本数据类型,需要存对应的包装类。
二、集合类体系结构
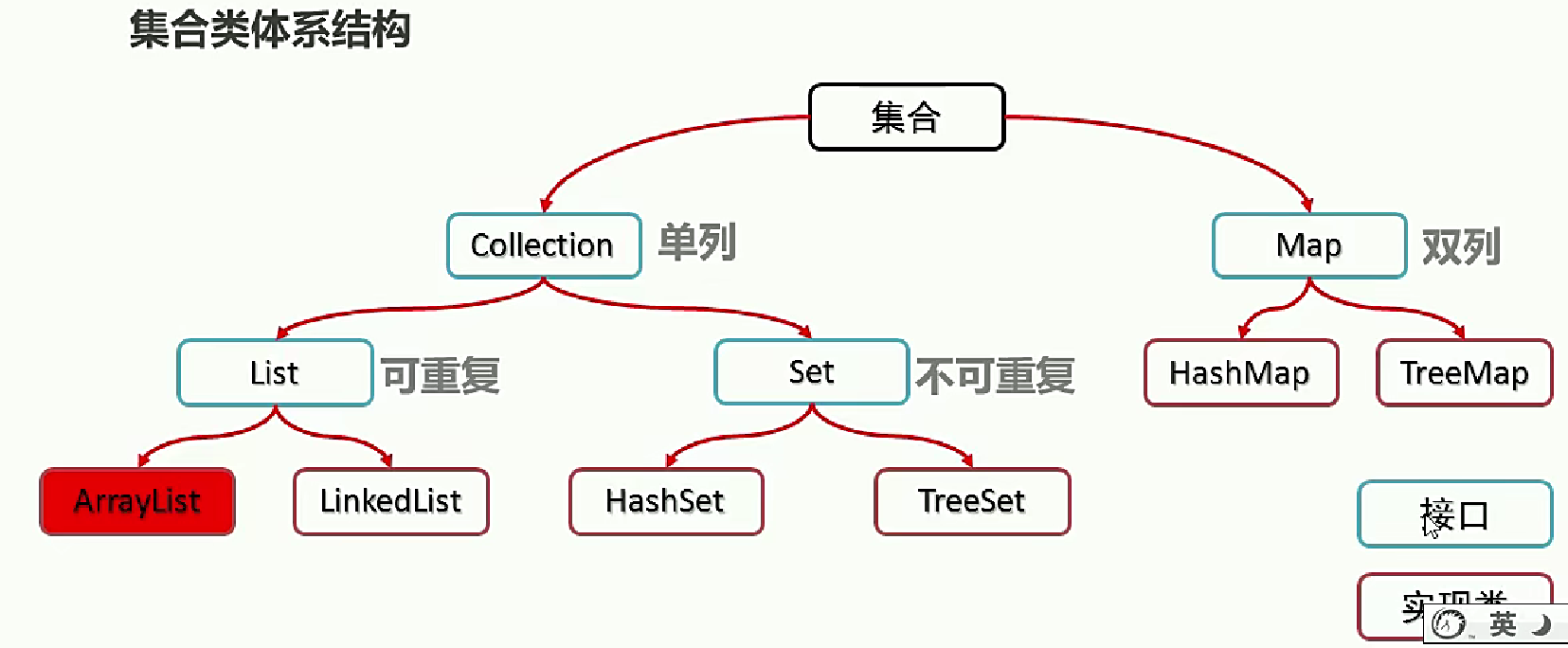
三、Collection集合(单列集合)
(一)概述
- 是单列集合的顶层接口,它表示一组对象,这些对象也称为Collection的元素
- JDK不提供此接口的任何实现,它提供更具体的子接口(如Set和List)实现
(二)常用方法
1.boolean add ( E e ) —— 添加元素
①格式
数组名 . add (元素 );
②举例
import java.util.ArrayList;
import java.util.Collection;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
System.out.println(collection);
}
}
//结果
//[aaa, bbb, ccc]2.boolean remove ( Object o ) —— 从集合中移除指定的元素
①格式
boolean 变量名 = 数组名 . remove ( 元素 );
②举例
import java.util.ArrayList;
import java.util.Collection;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
boolean result1 = collection.remove("aaa");
boolean result2 = collection.remove("ddd");
System.out.println(result1);
System.out.println(result2);
System.out.println(collection);
}
}
//结果
//true
//false
//[bbb, ccc]③注意
删除成功返回“true”,失败则返回“false”,不会报错。
3.boolean removeIf ( Object o ) —— 根据条件进行删除
①格式
数组名 . removeIf (
( 数组内元素的类型 变量名(给元素取的变量名))->{
return 条件 ;
}
);
②举例
import java.util.ArrayList;
import java.util.Collection;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
collection.add("oooooo");
collection.removeIf(
(String s)->{
return s.length()==3;
}
);
System.out.println(collection);
}
}
//结果
//[oooooo]③注意
removeIf 底层会遍历集合,得到集合每一个元素,将每个元素放到lambda表达式里判断,返回true则删除,返回false则不删除。
4.void clear ( ) —— 清空集合
①格式
数组名 . clear ( );
②举例
import java.util.ArrayList;
import java.util.Collection;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
collection.add("oooooo");
collection.clear();
System.out.println(collection);
}
}
//结果
//[]5.boolean contains ( Object o ) —— 判断集合中是否存在指定的元素
①格式
boolean 变量名 = 数组名 . contains (元素);
②举例
import java.util.ArrayList;
import java.util.Collection;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
collection.add("oooooo");
boolean result = collection.contains("aaa");
System.out.println(result);
}
}
//结果
//true6.boolean isEmpty ( ) —— 判断集合是否为空
①格式
boolean 变量名 = 数组名 . isEmpty ( );
②举例
import java.util.ArrayList;
import java.util.Collection;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
collection.add("oooooo");
boolean result = collection.isEmpty();
System.out.println(result);
}
}
//结果
//false7.int size ( ) —— 集合的长度,也就是集合中元素的个数
①格式
int 变量名 = 数组名 . size( );
②举例
import java.util.ArrayList;
import java.util.Collection;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
collection.add("oooooo");
int size = collection.size();
System.out.println(size);
}
}
//结果
//4(三)Collection集合的遍历
1.Iterator ——迭代器 (集合的专用遍历方式)#单列集合可直接使用,双列集合不行
2.创建迭代器的格式
Itreator<数组元素的类型> 迭代器名 = 数组名 . iterator ( );
#此时创建的迭代器默认指向数组索引为0的位置
3.Iterator中常用方法
①boolean hasNext ( ) —— 判断当前位置是否有元素可以被取出
格式:
boolean 变量名 = 迭代器名 . hasNext ( );
#返回true或者false
举例
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
Iterator<String> it1 = collection.iterator();
System.out.println(it1.hasNext());
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
Iterator<String> it2 = collection.iterator();
System.out.println(it2.hasNext());
}
}
//结果
//false
//true②E next ( ) —— 获取当前位置的元素,并将迭代器对象移到下一个索引位置
格式:
元素的类型 变量名 = 迭代器名 . next ( );
举例
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class text2 {
public static void main(String[] args) {
Collection<String> collection = new ArrayList<>();
collection.add("aaa");
collection.add("bbb");
collection.add("ccc");
Iterator<String> it = collection.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}
//结果
//aaa
//bbb
//ccc4.迭代器删除
①利用数组删除元素的方法(先 i++ 后 i-- )
import java.util.ArrayList;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
for (int i =0 ; i<list.size();i++){
String s = list.get(i);
if ("b" .equals(s)) {
list.remove(i);
// 必须要用i--,否则相邻相同的元素无法删除
i--;
}
}
System.out.println(list);
}
}
//结果
//[a, c, d, e]②使用迭代器的删除元素方法
格式:迭代器名 . remove( );#迭代器此时指向谁,就删除谁
import java.util.ArrayList;
import java.util.Iterator;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
Iterator<String> it = list.iterator();
while (it.hasNext()){
String s = it.next();
if ("b".equals(s)) {
// 迭代器指向谁,那么此时就删除谁
it.remove();
}
}
System.out.println(list);
}
}
//结果
//[a, c, d, e]5.增强for循环 #单列集合与数组可直接使用,双列集合不行
①概念
增强for:简化数组和Collection集合的遍历
- 它是JDK5之后出现的,其内部原理是一个Iteration迭代器
- 实现Iterable接口的类才可以使用迭代器和增强for
②格式
for ( 元素数据类型 元素变量名:数组或者Collection集合){
//在此处使用元素变量即可,该变量就是元素
}
!!!!!!!!!!!!快捷键:" 数组名或者集合名 . for "
③举例
import java.util.ArrayList;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
for (String s : list){
System.out.println(s);
}
}
}
//结果
//a
//b
//c
//d
//e④注意
元素变量名为第三方变量,修改第三方变量的值不会影响到集合中的元素
import java.util.ArrayList;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("a");
list.add("b");
list.add("c");
list.add("d");
list.add("e");
for (String s : list){
s="false";
System.out.println(s);
}
System.out.println(list);
}
}
//结果
//false
//false
//false
//false
//false
//[a, b, c, d, e]6.三种循环使用
①普通循环fori:需要操作索引时
②迭代器循环:在遍历的过程需要删除元素
③增强for:仅仅想遍历元素
四、list集合(元素可重复)
(一)概念
- 有序集合,这里的有序指的是存取顺序
- 用户可以精确控制列表中每个元素的插入位置。用户可以通过整数索引访问元素,并搜索列表中的元素
- 与set集合不同,列表通常允许重复的元素
特点:
- 有序:存储和取出的元素顺序一致
- 有索引:可以通过索引操作元素
- 可重复:存储的元素可以重复
(二)特有方法(常用方法在Collection集合部分)
1.void add ( int index ,E element ) —— 在此集合中的指定位置插入指定的元素
①格式
集合名 . add ( index , 要添加的元素);
②举例
import java.util.ArrayList;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
list.add(0,"qqq");
System.out.println(list);
}
}
//结果
//[aaa, bbb, ccc]
//[qqq, aaa, bbb, ccc]2.E remove ( int index ) —— 删除指定索引处的元素,返回被删除的元素
①格式
被删除元素的类型 变量 = 集合名 . remove ( index );
②举例
import java.util.ArrayList;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
String s = list.remove(2);
System.out.println(s);
System.out.println(list);
}
}
//结果
//[aaa, bbb, ccc]
//ccc
//[aaa, bbb]③注意
list集合中有两个remove删除方法,一个删除指定元素,返回的是boolean值 ;另一个删除指定索引位置上的元素,返回删除的元素。
3.E set ( int index , E element ) —— 修改指定索引处的元素,返回被修改的元素
①格式
被修改的元素类型 变量名 = 集合名 . set ( index , 要修改成的值 );
②举例
import java.util.ArrayList;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
String s = list.set(0,"qqq");
System.out.println(s);
System.out.println(list);
}
}
//结果
//[aaa, bbb, ccc]
//aaa
//[qqq, bbb, ccc]4.E get ( int index ) —— 返回指定索引处的元素
①格式
集合元素的类型 变量名 = 集合名 . set ( index );
②举例
import java.util.ArrayList;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
String s = list.get(0);
System.out.println(s);
}
}
//结果
//[aaa, bbb, ccc]
//aaa③注意
!!!当集合索引处没有元素时,系统会报错。
(三)数据结构
Java集合类型(List、Set、Queue、Map)都基于特定的数据结构实现。
1.概念
数据结构是计算机存储、组织数据的方式,是指相互之间存在一种或多种特定关系的数据元素的集合。
2.栈
①数据进入栈模型的过程称为:压/进栈
②数据离开栈模型的过程称为:弹/出栈
③栈是一种数据先进后出的模型
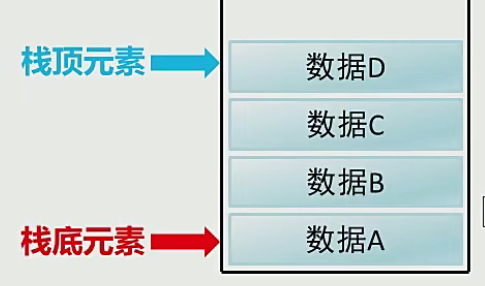
3.队列
①数据从后端进入队列模型的过程称为:入队列
②数据从前端离开队列模型的过程称为:出队列
③队列是一种数据先进先出的模型

4.数组
①查询数据通过地址值和索引定位,查询任意数据耗时相同,查询速度快
②删除数据时,要将原始数据删除,同时后面每个数据前移,删除效率低
③添加数据时,添加位置后的每个数据后移,再添加元素,添加效率极低
④数组是一种查询快,增删慢的模型
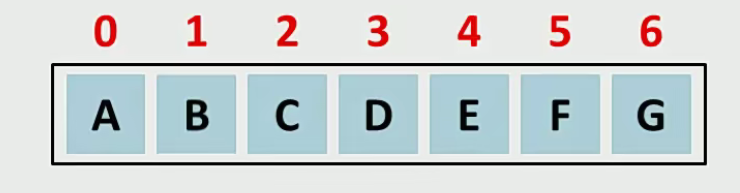
5.链表
①结点是用于存储数据和位置(地址)
②查询数据是否存在时,必须从头开始查询
③查询第N个数据,必须从头开始查询(双向链表则根据N是离头尾远近来查询)
④链表是一种增删快,查询慢的模型
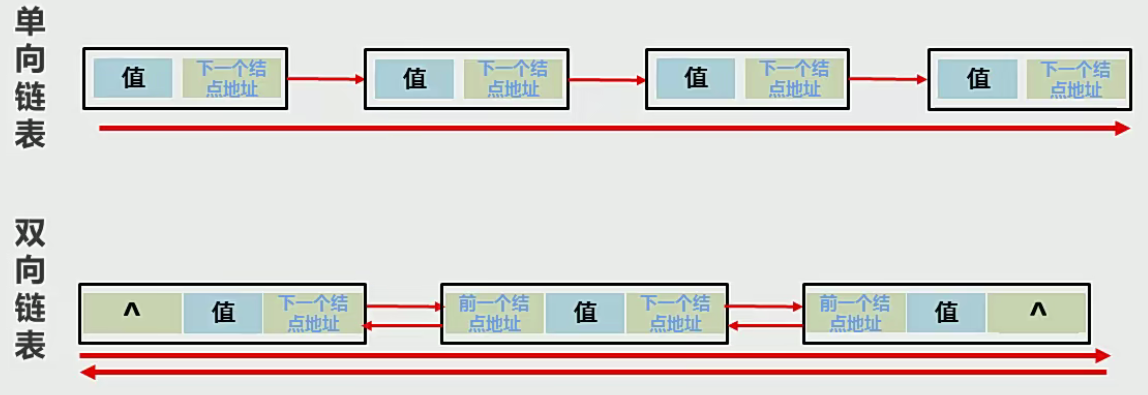
(四)Arraylist实现类(底层为数组,查询快,增删慢)
1.特有方法可查看基础集合文章
(五)Linkedlist实现类(底层为链表,增删快,查询慢)
特有方法
1.public void addFirst (E e ) —— 在该列表开头插入指定的元素
①格式
集合名 . addFirst (指定元素 );
②举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
list.addFirst("qqq");
System.out.println(list);
}
}
//结果
//[aaa, bbb, ccc]
//[qqq, aaa, bbb, ccc]2.public void addLast ( E e ) —— 将指定的元素追加到此列表的末尾
①格式
集合名 . addLast ( 指定元素 );
②举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
list.addLast("www");
System.out.println(list);
}
}
//结果
//[aaa, bbb, ccc]
//[aaa, bbb, ccc, www]3.public E getFirst ( ) —— 返回此列表中的第一个元素
①格式
元素类型 变量名 = 集合名 . getFirst ( );
②举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
String s = list.getFirst();
System.out.println(s);
}
}
//结果
//[aaa, bbb, ccc]
//aaa4.public E getLast ( ) —— 返回列表中的最后一个元素
①格式
元素类型 变量名 = 集合名 . getLast ( );
②举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
String s = list.getLast();
System.out.println(s);
}
}
//结果
//[aaa, bbb, ccc]
//ccc5.public E removeFirst ( ) —— 从此列表中删除并返回第一个元素
①格式
元素类型 变量名 = 集合名 . removeFirst ( );
②举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
String s = list.removeFirst();
System.out.println(s);
System.out.println(list);
}
}
//结果
//[aaa, bbb, ccc]
//aaa
//[bbb, ccc]6.public E removeLast ( ) —— 从此列表中删除并返回最后一个元素
①格式
元素类型 变量名 = 集合名 . removeLast ( );
②举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
LinkedList<String> list = new LinkedList<>();
list.add("aaa");
list.add("bbb");
list.add("ccc");
System.out.println(list);
String s = list.removeLast();
System.out.println(s);
System.out.println(list);
}
}
//结果
//[aaa, bbb, ccc]
//ccc
//[aaa, bbb]五、泛型
(一)概述
1.泛型:
是JDK5中引入的特性,它提供了编译时类型安全检测机制
2.好处:
- 把运行时期的问题提前到了编译期间
- 避免了强制类型转换
3.不使用泛型举例:
- 任何类型的数据都可以放入集合中
- 集合中的元素的类型均为Object类型,该类型没有任何方法可使用
import java.util.*;
public class text2 {
public static void main(String[] args) {
ArrayList list = new ArrayList<>();
list.add("aaa");
list.add("bbb");
list.add(123);
list.add(true);
Iterator it = list.iterator() ;
while (it.hasNext()){
Object s= it.next();
System.out.println(s);
}
}
}
//结果
//aaa
//bbb
//123
//true4.泛型的使用
①泛型类:在类后面
②泛型方法:方法申明上
③接口后面:泛型接口
5.泛型的定义格式
<类型>:指定一种类型的格式,尖括号里面可以任意书写,按照变量的定义规则即可,
一般只写一个字母
<类型1,类型2,...>:定义多个类型的格式,多种类型之间用逗号隔开。
(二)泛型类
1.描述
- 如果一个类的后面有<E>,表示这个类是一个泛型类
- 创建泛型类的对象时,必须要给这个泛型确定具体的数据类型
2.自定义泛型类格式
①格式
修饰符 class 类名 <类型>{ }
②举例
定义自定义泛型类
package domain;
public class Box<E>{
private E element;
public E getElement() {
return element;
}
public void setElement(E element) {
this.element = element;
}
}
使用自定义泛型类
import domain.Box;
public class text2 {
public static void main(String[] args) {
Box<String> list = new Box<>();
list.setElement("19岁的我给小丽的一封信。");
System.out.println(list.getElement());
}
}
//结果
//19岁的我给小丽的一封信。(三)泛型方法
1.定义格式
修饰符 <泛型的类型> void / 返回值类型 方法名(传递进来的类型 变量名){ }
2.举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
ArrayList<String> list = new ArrayList<>();
list=addElement(list,"aaa","bbb","ccc");
System.out.println(list);
}
public static <T> ArrayList<T> addElement(ArrayList<T> list,T t1,T t2,T t3){
list.add(t1);
list.add(t2);
list.add(t3);
return list;
}
}
//结果
//[aaa, bbb, ccc](四)泛型接口(暂时用不上)
1.泛型接口的使用方式
- 实现类也不给泛型
- 实现类确定具体的数据类型
2.泛型接口的定义格式
修饰符 interface 接口名 <类型> { }
(五)类型通配符<?>
1.ArrayLast<?>
①概念
表示元素类型未知的ArrayList,它的元素可以匹配任何的类型,但是并不能把元素添加到ArrayLast中了,获取出来的是父类类型
②举例
import java.util.*;
public class text2 {
public static void main(String[] args) {
ArrayList<Iterator> list1 = new ArrayList<>();
ArrayList<String> list2 = new ArrayList<>();
printlist(list1);
printlist(list2);
}
private static void printlist (ArrayList<?> list){
System.out.println(list);
}
}
//结果
//[]
//[]2.<? extends A>
①概念
类型通配符上限:表示传递进来集合的类型,可以是A类型,也可以是A所有的子类类型
②举例
Integer类的继承结构:
Object(是Number的父类)
Number(是Integer的父类)
Integer
import java.util.*;
public class text2 {
public static void main(String[] args) {
ArrayList<Object> list1 = new ArrayList<>();
ArrayList<Number> list2 = new ArrayList<>();
ArrayList<Integer> list3 = new ArrayList<>();
printlist(list2);
printlist(list3);
}
private static void printlist (ArrayList<? extends Number> list){
System.out.println(list);
}
}
//结果
//[]
//[]3.<? super 类型A>
①概念
类型通配符下限:表示传递进来集合的类型,可以是类型A,也可以是A所有的父类类型
②举例
Integer类的继承结构:
Object(是Number的父类)
Number(是Integer的父类)
Integer
import java.util.*;
public class text2 {
public static void main(String[] args) {
ArrayList<Object> list1 = new ArrayList<>();
ArrayList<Number> list2 = new ArrayList<>();
ArrayList<Integer> list3 = new ArrayList<>();
printlist(list1);
printlist(list2);
}
private static void printlist (ArrayList<? super Number> list){
System.out.println(list);
}
}
//结果
//[]
//[]六、set集合(元素不可重复)
(一)概念
- 可以去除重复
- 存取顺序不一致
- 没有带索引的方法,所以不能使用普通for循环遍历,也不能通过索引来获取,删除Set集合里面的元素
注意:可以使用迭代器和增强for来遍历集合元素
import java.util.*;
public class text2 {
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("ccc");
set.add("aaa");
set.add("aaa");
set.add("bbb");
// 增强for
for (String s : set) {
System.out.println(s);
}
System.out.println("----------------------------");
// 迭代器
Iterator<String> it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}
//结果
//aaa
//bbb
//ccc
//----------------------------
//aaa
//bbb
//ccc(二)基本使用方法
见本文章的第三部分——Collection集合(单列集合)的常用方法
(三)HashSet实现类
1.概念
- 底层数据结构是哈希表
- 不能保证存储和取出的顺序完全一致
- 没有带索引的方法,所以不能使用普通for循环遍历
- 由于是Set集合,所以元素唯一
2.哈希值
(四)TreeSet实现类
1.概念
- 不包含重复元素的集合
- 没有带索引的方法
- 可以将元素按照规则进行排序
2. 系统中给的类
元素会按照规则进行排序,无需自己指定排序规则
import java.util.*;
public class text2 {
public static void main(String[] args) {
Set<Integer> set = new TreeSet<>();
set.add(103);
set.add(90);
set.add(333);
// 迭代器
Iterator<Integer> it = set.iterator();
while (it.hasNext()){
System.out.println(it.next());
}
}
}
//结果
//90
//103
//3333.自定义类
需要指定排序规则 (有两种排序规则)
①自然排序Comparable的使用
实现方法:
- 使用空参构造创建TreeSet集合
- 自定义的Student类实现Comparable接口
- 重写里面的compareTo方法
举例
Student类
//自定义的Student类实现Comparable接口
public class Student implements Comparable<Student> {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public Student() {
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
// 重写里面的compareTo方法
@Override
public int compareTo(Student o) {
int result = this.age-o.age;
return result;
}
}TestStudent
import domain.Student;
import java.util.*;
public class text2 {
public static void main(String[] args) {
// 使用空参构造创建TreeSet集合
TreeSet<Student> ts = new TreeSet<>();
Student s1 = new Student("zhangsan",28);
Student s2 = new Student("wangwu",18);
Student s3 = new Student("laoliu",38);
ts.add(s1);
ts.add(s2);
ts.add(s3);
System.out.println(ts);
}
}
//结果
//[Student{name='wangwu', age=18}, Student{name='zhangsan', age=28}, Student{name='laoliu', age=38}]排序的简单原理图
this.age:正在存入集合的元素
o.age:已经存入集合的元素
返回值result = this.age - o.age;
- 如果返回值为负数,表示当前存入的元素是较小值,存左边
- 如果返回值为0,表示当前存入的元素跟集合中元素重复了,不存
- 如果返回值为正数,表示当前存入的元素是较大值,存右边
多次比较
(如果按照年龄排时相同,则按照姓名的拼音字母排,两次均相同时才认为是重复元素)
注意:String类型比较只能比较字母,不能比较中文
举例
(只举例了要修改的compareTo方法)
// 重写里面的compareTo方法
@Override
public int compareTo(Student o) {
int result = this.age-o.age;
// 三元表达式:result==0为条件,如果条件为真则运行this.name.compareTo(o.getName()),条件为假,则运行result。
// 理解this.name.compareTO(o.getName())):
// 将this.name(要存入集合的元素)与o.getName()(已存入集合的元素)比较
// 因为元素是String类型,所以逐一比较每个字母的码表值,得出返回值
// 返回值为0,则不存,为负数,则存左边,为正数,则存右边
result= result ==0 ? this.name.compareTo(o.getName()) : result;
return result;
}
}②比较器排序Comparator的使用
实现方法
- TreeSet的带参构造方法使用的是比较器排序对元素进行排序的
- 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(T o1,T o2)方法
- 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
举例
Student类(没有接收compare方法)
public class Student {
private String name;
private int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public Student() {
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"name='" + name + '\'' +
", age=" + age +
'}';
}
}TestStrdent类(在集合构造方法接收了compare方法)
import domain.Student;
import java.sql.Array;
import java.util.*;
public class text2 {
public static void main(String[] args) {
// 比较器排序,就是让集合构造方法接收Comparator的实现类对象,重写compare(T o1,T o2)方法
TreeSet<Student> ts = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student o1, Student o2) {
int result = o1.getAge() - o2.getAge();
// 重写方法时,一定要注意排序规则必须按照要求的主要条件和次要条件来写
result = result == 0 ? o1.getName().compareTo(o2.getName()) : result;
return result;
}
});
Student s1 = new Student("zhangsan", 28);
Student s2 = new Student("wangwu", 18);
Student s3 = new Student("laoliu", 38);
Student s4 = new Student("lisi", 38);
ts.add(s1);
ts.add(s2);
ts.add(s3);
ts.add(s4);
System.out.println(ts);
}
}
//结果
//[Student{name='wangwu', age=18}, Student{name='zhangsan', age=28}, Student{name='laoliu', age=38}, Student{name='lisi', age=38}]排序的简单原理图
o1:正在存入集合的元素
o2:已经存入集合的元素
返回值result = o1.getAge() - o2.getAge();
- 如果返回值为负数,表示当前存入的元素是较小值,存左边
- 如果返回值为0,表示当前存入的元素跟集合中元素重复了,不存
- 如果返回值为正数,表示当前存入的元素是较大值,存右边
③两种方法比较
- 自然排序:①自定义类实现Comparable接口,②重写compareTo方法,根据返回值进行排序
- 比较器排序:①创建TreeSet对象的时候传递Comparator的实现类对象,②重写compare方法
- 在使用的时候,默认使用自然排序,当自然排序不满足现在的需求时,使用比较器排序
- 两种方法的返回值规则相同
七、 树结构(数据结构)
(一)概述
1.类型
二叉树、二叉查找树、平衡二叉树、红黑树
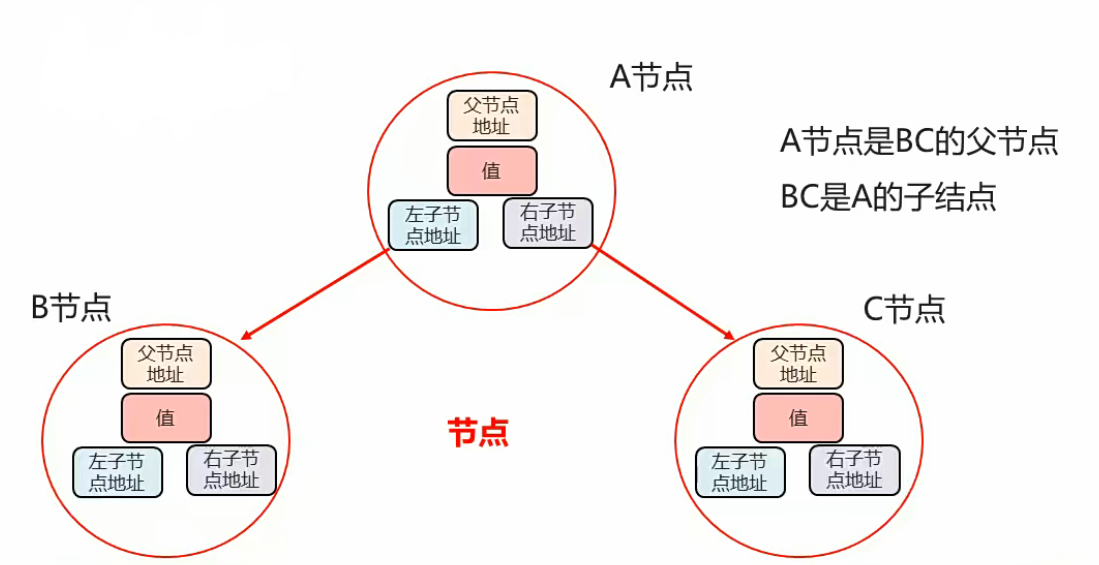
2.专有名词
节点:元素(对象)
度:每个节点的子节点数量
树的高度:层数
根节点:最顶层的节点
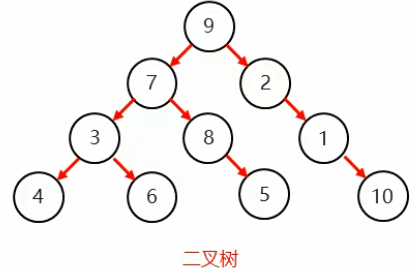
(二)二叉树(每个节点上最多有两个子节点 )
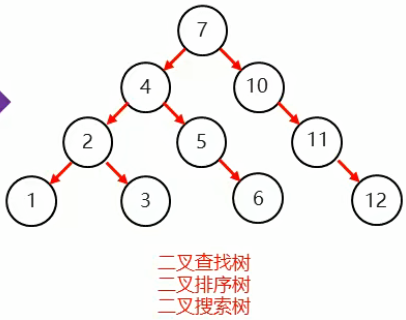
(三)二叉查找树(二叉排序树或者二叉搜索树)
1.特点
- 每个节点上最多有两个子节点
- 每个节点的左子节点都是小于自己的
- 每个节点的右子节点都是大于自己的
2.添加节点规律
从第一个元素开始排,将每个元素从根节点开始比较存入
(四)平衡二叉树
1. 特点
- 二叉树左右两个子树的高度差不超过1
- 任意节点的左右两个子树都是一棵平衡二叉树
2.旋转机制
①触发时机
当添加一个节点之后,该树不再是一棵平衡二叉树(旋转后再次平衡)
②左旋
就是将根节点的右侧往左拉,原先的右子节点变成新的父节点,并把多余的左子节点让出,给已经降级的根节点当右子节点
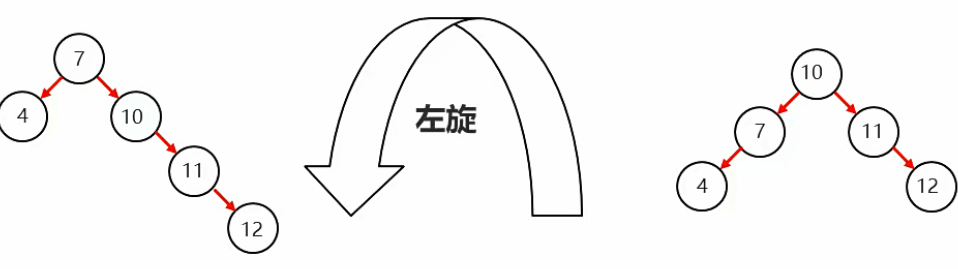
③右旋
将根节点的左侧往右拉,左子节点变成了新的父节点,并把多余的右子节点出让,给已经降级根节点当左子节点
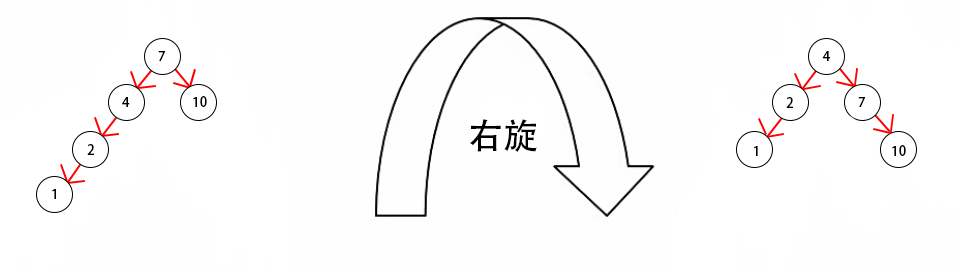
④旋转的四种情况
左左:当根节点左子树的左子树有节点插入,导致二叉树不平衡——右旋
左右:当根节点左子树的右子树有节点插入,导致二叉树不平衡——先左旋再右旋
右右:当根节点右子树的右子树有节点插入,导致二叉树不平衡——左旋
右左:当根节点右子树的左子树有节点插入,导致二叉树不平衡——向右旋再左旋
(五)红黑树
1.特点
- 是一种自平衡的二叉查找树,之前被称为平衡二叉B树
- 每个节点可以是红或者黑
- 红黑树不是高度平衡,它的平衡是通过“自己的红黑规则”进行实现的
- 红黑树的每个节点由父节点地址、值、左子节点地址、右子节点地址、颜色五部分组成
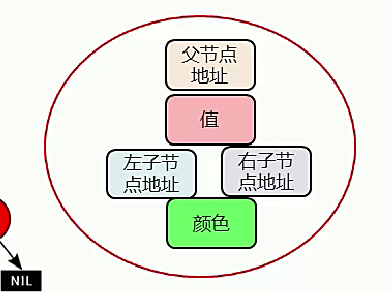
2.红黑规则
- 每一个节点或是红色的,或是黑色的
- 根节点必须是黑色(与第三点的一个节点没有父节点相对应)
- 如果一个节点没有子节点或者父节点,则该节点相应的指针属性值为Nil,这些Nil视为叶节点,每个叶节点(Nil)是黑色的
- 如果某个节点是红色,那么它的子节点必须是黑色(不能出现两个红色节点相连的情况)
- 对每一个节点,从该节点到其所有后代叶节点的简单路径上,均包含相同数目的黑色节点
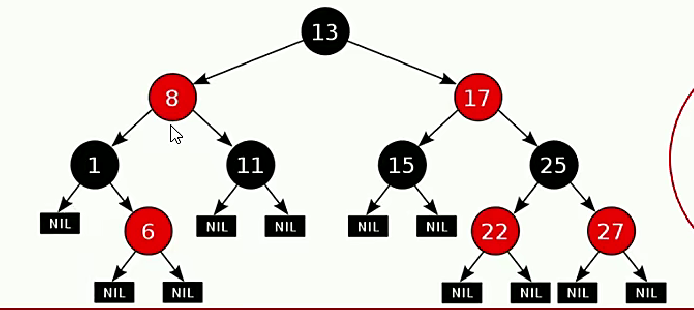
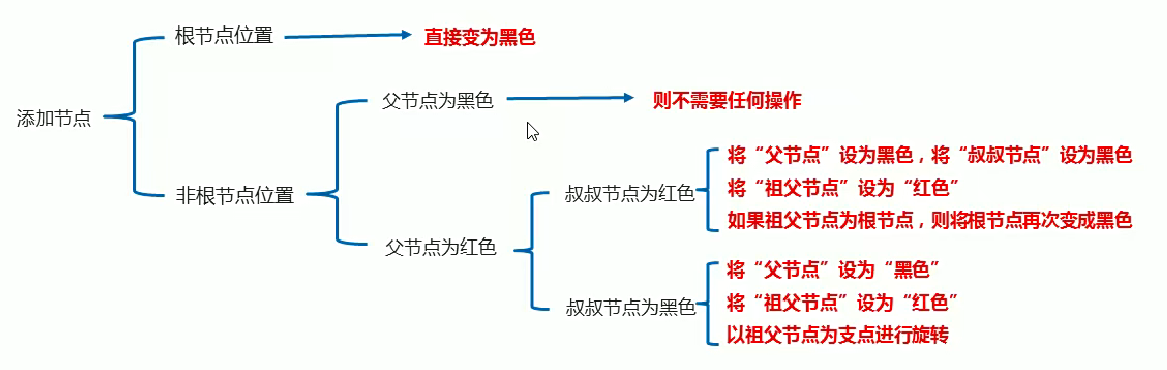
3.添加节点

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 33
33 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)