MCP凉凉?Skills崛起?别傻了!这才是大模型Agent开发的核心真相!
AI圈最近有个有趣现象:Skills被热捧,MCP被各种唱衰。社交媒体上到处是"MCP协议要凉了"的声音,开发者纷纷转向Skills。Skills怎么来的,有什么用,怎么开发,文中把MCP与Skills的恩怨讲的明明白白。但开发者Philipp Schmid直接撰文开怼:你们搞错了重点。并给出了构建MCP Server的最佳实践。
AI圈最近有个有趣现象:Skills被热捧,MCP被各种唱衰。社交媒体上到处是"MCP协议要凉了"的声音,开发者纷纷转向Skills。
Skills怎么来的,有什么用,怎么开发,文中把MCP与Skills的恩怨讲的明明白白。
但开发者Philipp Schmid直接撰文开怼:你们搞错了重点。并给出了构建MCP Server的最佳实践。

MCP背锅,Skills躺赢?
MCP协议发布一年来,企业级部署已经上线,集成在运行,但结果令人失望。这种对比让很多人得出结论:MCP设计有问题,Skills才是未来。
但作者的观点很犀利:协议没问题,是你的服务器设计烂。
大多数开发者把MCP服务器当成REST API的简单封装。这种思路的根本问题在于,REST API是为人类开发者设计的,而MCP是给Agent用的界面。两种用户,需要完全不同的设计原则,不要把REST API思维硬套MCP。
人类开发者 vs Agent:设计差异一目了然
| 设计原则 | 人类开发者 | Agent |
|---|---|---|
| 发现成本 | 便宜(读一次文档) | 昂贵(每次请求都要解析schema) |
| 组合能力 | 混合匹配小端点 | 多步工具调用,迭代缓慢 |
| 灵活性 | 更多选项=更灵活 | 复杂性导致幻觉 |
人类开发者可以一次性阅读文档,然后组合多个API端点完成复杂任务。但Agent每次调用都需要重新解析工具描述,多次往返通信会显著降低效率。
订单跟踪的实战对比
假设你在构建一个订单跟踪Agent。
糟糕的MCP设计会暴露三个工具:
get_user_by_email()list_orders(user_id)get_order_status(order_id)
这强制代理进行三次往返调用,在对话历史中存储所有中间结果。
优秀的MCP设计只暴露一个工具:track_latest_order(email)。在服务器端完成所有协调工作,返回"订单#12345已通过FedEx发货,周四到达"。同样结果,一次调用,面向结果。
图中对比显示:不良设计需要3次往返才能完成订单跟踪,而良好设计只需1次。这个差距在每天数千次调用的生产环境中会被放大。
六个实用设计原则
1. 结果导向,而非操作导向
别把底层API操作直接暴露为工具。设计时要思考:Agent想要达成什么目标?然后围绕这个目标设计工具。在服务器代码中完成编排,而不是在LLM的上下文窗口中。
2. 参数扁平化
避免复杂的嵌套字典或配置对象:
| ❌ 糟糕设计 | ✅ 优秀设计 |
|---|---|
def search_orders(filters: dict) |
def search_orders(email: str, status: Literal["pending", "shipped", "delivered"] = "pending", limit: int = 10) |
| 代理猜测结构 | 清晰、类型化、约束明确 |
| 幻觉键名,遗漏必填字段 | Literal约束选择,默认值减少决策 |
3. 文档即指令
工具的描述文档不是给人类看的注释,而是给Agent的操作指南。要明确说明:
- 何时使用该工具(“当用户询问订单状态时使用”)
- 如何格式化参数(“邮箱必须小写”)
- 期望返回什么(“返回订单ID和当前状态”)
错误信息也要设计成可操作的提示。不要抛出Python异常,而是返回有用的字符串:"未找到用户。请尝试用邮箱地址搜索。"Agent会将错误视为观察结果,并使用你的指令在下一轮中自我纠正。
4. 精心筛选工具
Agent在严格的上下文约束下运行。每个工具描述、每个响应负载、每个错误信息,都在上下文窗口中竞争空间。
- 每个服务器5-15个工具
- 一个服务器,一个职责
- 删除未使用的工具
- 按角色分割(管理员/用户)
5. 命名要有发现性
使用{服务}_{操作}_{资源}的命名模式,如slack_send_message、linear_list_issues、sentry_get_error_details。避免通用的create_issue或send_message这类容易冲突的名称。
你的MCP服务器会与其他服务器一起运行。如果GitHub和Jira都有create_issue,Agent只能猜测使用哪个。
6. 分页处理大数据
永远不要一次性返回数百条记录:
- 支持
limit参数(默认20-50条) - 返回
has_more、next_offset、total_count等元数据 - 永远不要将所有结果加载到内存中
Skills vs MCP:根本不是竞争关系
很多讨论把Skills和MCP放在对立面,但这完全是误解。
Skills解决的是"什么时候用什么工具"的问题:
- 渐进式加载(启动时只看元数据,触发时才读指令)
- 工作流指导(告诉Agent在特定场景下的操作步骤)
- 本地执行(通过bash等通用工具提供功能)
MCP解决的是"怎么可靠地调用工具"的问题:
- 标准化接口
- 参数验证
- 类型化响应
- 错误处理
| 能力 | Skills | MCP |
|---|---|---|
| 上下文管理 | 渐进式披露,token友好 | 所有工具schema都在上下文中 |
| 工具定义 | 通过通用执行工具实现 | 结构化的专用工具接口 |
| 工作流指导 | 内置指令和最佳实践 | 需要外部编排 |
| 企业集成 | 适合脚本和本地工具 | 适合服务化的API |
它们根本不冲突。在企业环境中,MCP服务器暴露各团队的服务能力,Skills教Agent如何组合这些能力完成具体工作流。
Gmail实战:两种设计的天壤之别
传统REST思维(糟糕):
# 读邮件要2个工具 + 理解复杂嵌套
def messages_list(query: str, max_results: int) -> dict
def messages_get(message_id: str, format: str) -> dict
# 发邮件要构造base64编码的MIME
def messages_send(message: {"raw": str}) -> dict
Agent优先设计:
# 简单直接
def gmail_search(query: str, limit: int = 10) -> list
def gmail_read(message_id: str) -> dict
def gmail_send(to: List[str], subject: str, body: str) -> dict
核心问题:你在为谁设计界面?
作者的核心观点很清楚:MCP是Agent的用户界面,不是基础设施。
当你构建MCP服务器时,问自己:
- 这个工具是为了完成什么目标?
- Agent能一次性获得所需信息吗?
- 参数设计是否清晰无歧义?
- 错误信息能帮助Agent自我纠正吗?
Skills热度高是因为它从一开始就是为Agent设计的。MCP被批评是因为大家把它当REST API包装器。
但如果你真正理解了用户是谁,MCP服务器一样可以设计得很优秀。问题不在协议,在设计思维。
企业级的认证、限流、重试、审计——这些生产环境的硬需求,最终还是要在服务器层面解决。协议只是载体,服务器设计才是关键。
写在最后
当前AI的火爆吸引了太多目光,任何一个新概念被提出,都会迎来大众的追捧和过度炒作。过去MCP如此,现在Skills也是如此。这种现象背后,反映的是行业对"银弹"的渴望,和对落地产生真实价值的焦虑。
但现实是,AI工程技术会随着模型性能的提升快速迭代,周边生态也在快速发展。每隔几个月就会有新的框架、新的协议、新的最佳实践出现。在这种快速变化的环境中,不关注实际成效,盲目追逐新概念往往得不偿失。
真正重要的是如何将每一个理念做扎实。无论是MCP还是Skills,核心都在于理解用户需求,设计合理的抽象,解决实际问题。如果只是浅尝辄止,跟风炒作,到最后都会沦为一个个鸡肋的概念。看起来很美,用起来很鸡肋,最终被下一波热潮淹没。
技术的价值不在于概念的新颖,而在于实现的质量。与其纠结要用哪个新出的技术,不如先把基础做好,从“第一性原理”出发,把握发展脉络:理解你的用户是谁,他们要解决什么问题,你的设计能否真正帮到他们。这个思路,适用于MCP,也适用于Skills,更适用于未来会出现的任何新技术。
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
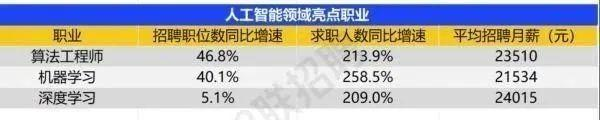
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 27
27 0
0- 0



 已为社区贡献517条内容
已为社区贡献517条内容

所有评论(0)