【ModelEngine实战】拒绝“人工智障”:基于可视化编排与RAG构建企业级“智能投研分析助手”
摘要:本文详细介绍了如何利用ModelEngine的可视化编排功能构建"智能投研助手"。通过RAG(检索增强生成)技术结合知识库与联网搜索,解决金融投研场景下的数据孤岛问题。文章从知识库构建、提示词优化到工作流编排,完整展示了开发流程,并对比了ModelEngine与Coze/Dify等平台的特点。ModelEngine在知识库自动摘要生成、可视化调试等企业级功能上表现突出,显
目录
3. 实战 Step 1:构建“最强大脑”——知识库与自动摘要
5. 实战 Step 3:可视化工作流编排——打造业务逻辑闭环
7. 深度横评:ModelEngine vs Coze vs Dify
摘要:
在大模型应用落地的过程中,单纯的“提示词工程”往往无法解决幻觉和实时性问题。如何利用 ModelEngine 的可视化编排能力,结合 RAG(检索增强生成)与外部工具,打造一个能读研报、能联网、能写分析报告的“超级员工”?本文将从 0 到 1 复盘“智能投研助手”的开发全流程,深度评测 ModelEngine 在知识库处理、工作流编排及调试方面的硬核能力,并附带与主流平台(Coze/Dify)的开发者视角对比。
1. 项目背景:为什么我们需要一个“编排型”智能体?
在金融投研、竞品分析等场景下,我们通常面临两个痛点:
-
私有数据孤岛:通用的 ChatGPT 或 DeepSeek 无法读取公司内部的历史研报和私有数据。
-
单一模型能力有限:复杂的分析任务不能只靠“问答”,需要“搜索信息 -> 阅读资料 -> 提取数据 -> 生成报告”的一系列严密逻辑。
ModelEngine 提供的可视化应用编排(Workflow)功能,恰好能解决这两个问题。它允许我们将大模型(LLM)、知识库、插件工具像搭积木一样串联起来。今天,我们就来实操构建一个“智能投研分析助手”。
2. 核心架构:RAG + 工作流 + 联网搜索
为了保证输出的专业性和准确性,我们的智能体设计逻辑如下:
-
用户输入:输入需要分析的公司或行业名称。
-
意图识别/分支判断:判断库内是否有相关资料。
-
核心路径 A(内源):调用 ModelEngine 知识库,检索内部研报。
-
核心路径 B(外源):若内部资料不足,调用联网搜索插件获取最新资讯。
-
LLM 综合分析:结合检索到的上下文,按照特定格式输出投资建议书。
3. 实战 Step 1:构建“最强大脑”——知识库与自动摘要
ModelEngine 的知识库功能是我体验下来的一大亮点,尤其是它的数据处理自动化程度。
3.1 知识库创建与上传
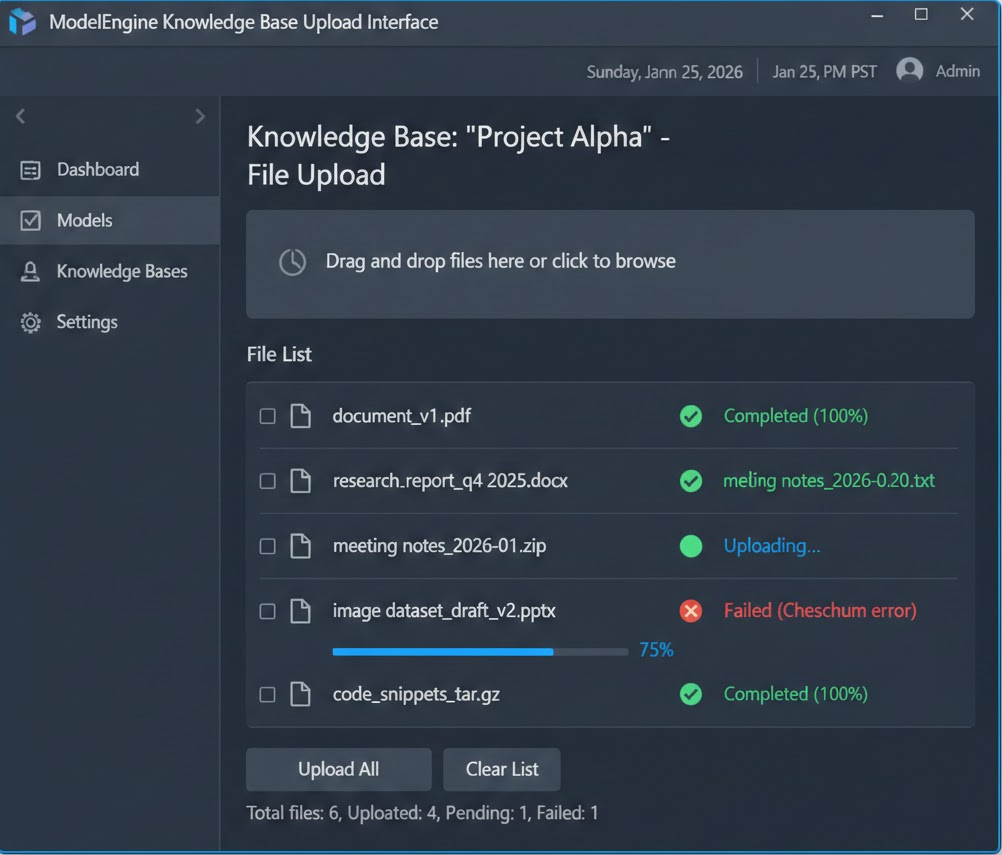
首先,进入 ModelEngine 控制台,创建知识库“Tech_Report_2025”。我上传了 5 份关于“人工智能产业链”的 PDF 研报(共计 200 页)。
3.2 自动分段与摘要生成(核心评测点)
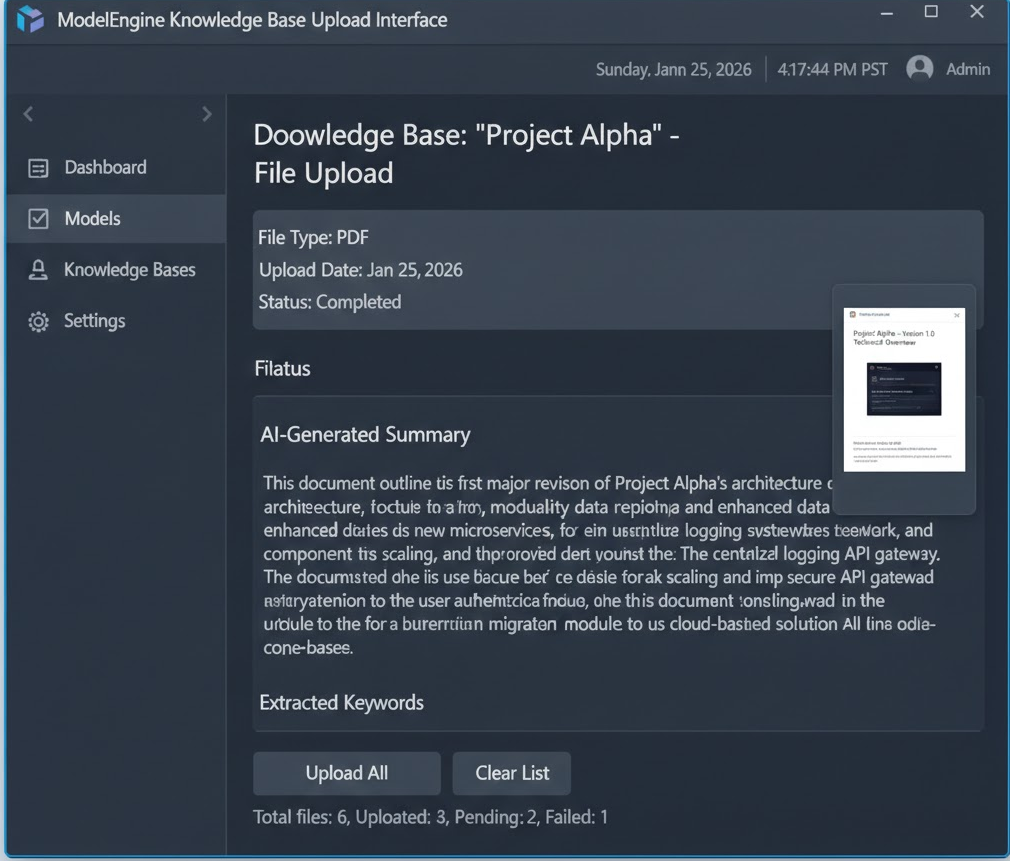
上传完成后,系统会自动进行分段清洗。这里必须点赞 ModelEngine 的**“自动摘要生成”**功能。
传统的 RAG 平台往往只是机械切片,而 ModelEngine 会为每个文档生成一段 Summary。这意味着在检索时,模型可以先通过摘要快速判断文档相关性,大大提高了召回的准确率。
-
体验反馈:在上传一份《2025算力趋势报告》后,系统自动生成的摘要准确提取了“GPU出货量”、“液冷技术”、“光模块”等核心关键词,无需人工干预。
4. 实战 Step 2:提示词调优——让 AI 听懂人话
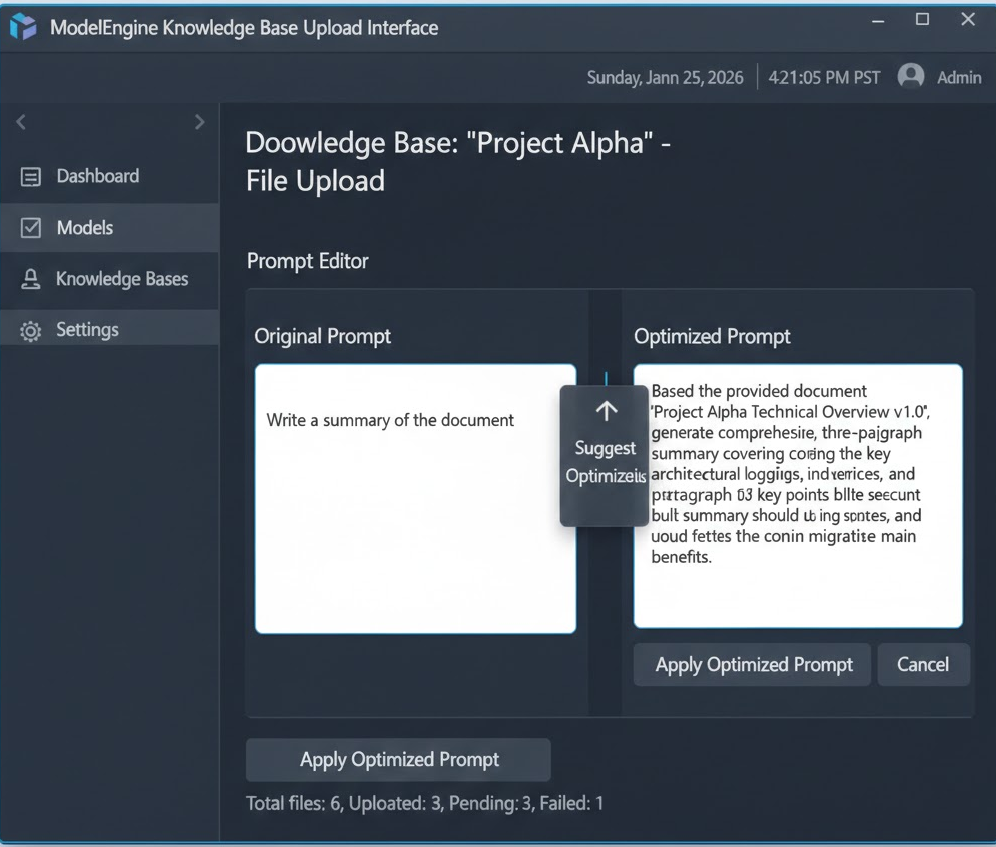
在进入工作流之前,我们需要先定义好 LLM 的“人设”。ModelEngine 提供了提示词自动生成与优化工具,这对不擅长写 Prompt 的开发者非常友好。
4.1 原始 Prompt
最开始,我只写了一句:
“你是一个金融分析师,根据资料帮我分析一下这家公司。”
4.2 使用自动优化功能
点击输入框下方的“自动优化”按钮,ModelEngine 结合我的简短描述,生成了如下结构化
# Role
资深金融投资研究员
# Profile
具备10年二级市场投研经验,擅长通过宏观政策、行业趋势及财务数据进行多维度分析。
# Goals
根据用户提供的上下文(Context)及查询意图,输出结构清晰、数据详实的投资价值分析报告。
# Constraints
- 必须基于提供的知识库内容回答,严禁编造数据。
- 若知识库中无相关信息,请明确告知。
- 输出格式需包含:【核心结论】、【风险提示】、【关键数据支撑】。
# Workflow
1. 分析用户查询的公司/行业。
2. 提取知识库中的关键财务指标和市场份额数据。
3. 结合行业趋势进行SWOT分析。
4. 输出最终报告。
这种结构化的 Prompt 直接将智能体的智商提升了一个台阶。
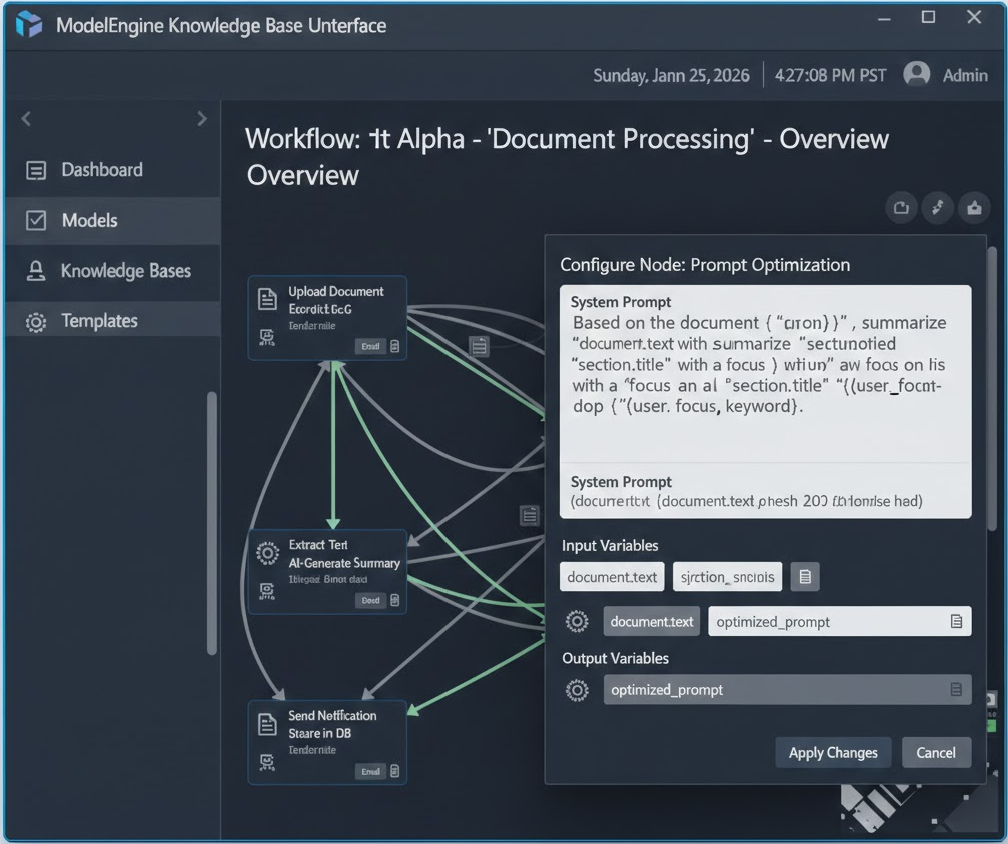
5. 实战 Step 3:可视化工作流编排——打造业务逻辑闭环
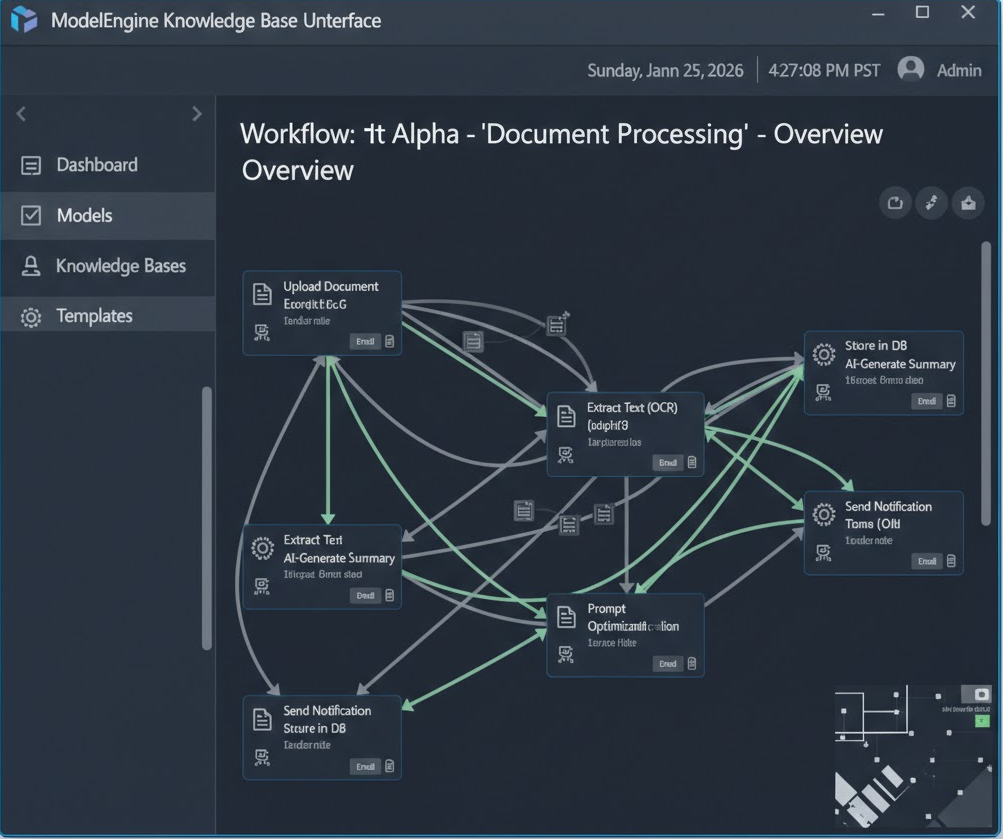
这是本次实战的最核心部分。相比于单一的 Chat 模式,应用编排(Workflow) 让我们能控制 AI 的思考过程。
5.1 画布布局
进入“应用编排”界面,我拖拽了以下核心节点:
-
开始节点:定义输入变量
company_name。 -
知识库检索节点:关联我们在 Step 1 创建的“Tech_Report_2025”,设置召回 Top 5 的片段。
-
大模型节点(LLM):作为“分析师大脑”。
5.2 节点配置详情
A. 知识库检索节点配置
在 Query 输入框中,我没有直接使用用户的原始输入,而是引用了开始节点的变量 {{start.company_name}}。同时开启了“混合检索”模式,以平衡语义匹配和关键词匹配。
B. 大模型节点配置
这是最关键的一步。我们需要将检索到的内容“喂”给大模型。
在 LLM 节点的 Prompt 输入框中,我引用了检索节点的输出变量 {{knowledge_retrieval.output}}:
请阅读以下参考资料:
{{knowledge_retrieval.output}}
针对目标公司 {{start.company_name}},请撰写一份分析报告。
5.3 进阶:引入 MCP 服务与多智能体协作
为了让分析更全面,我尝试在工作流中接入了一个**“网络搜索工具”**节点(模拟 MCP 服务接入)。逻辑是:如果知识库检索结果为空,则走另一条分支调用搜索工具。
虽然目前配置相对基础,但 ModelEngine 清晰的逻辑分支(Condition Node)让这种复杂的“多源工具集成”变得非常直观。
6. 开发与调试:从“跑通”到“好用”的避坑指南
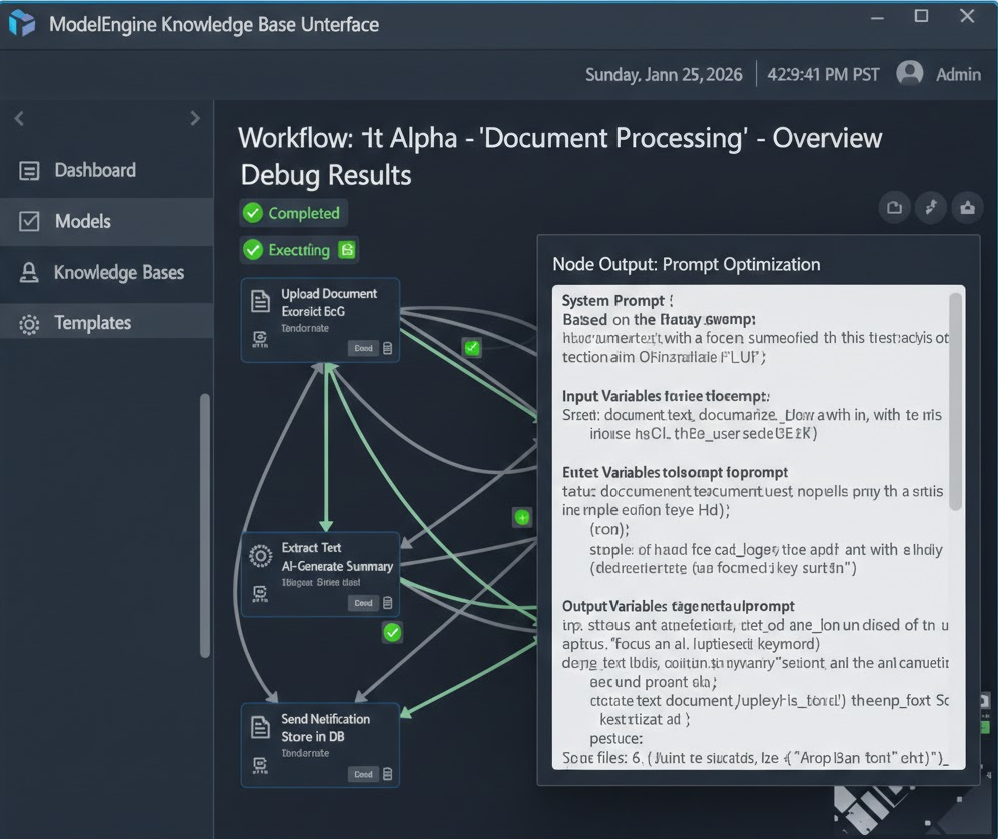
编排完成后,点击右上角的**“调试与预览”**。这里分享几个我在调试过程中遇到的坑及解决方法:
6.1 问题一:模型复读机
-
现象:模型不断重复“根据资料...根据资料...”。
-
解决:这是因为 Prompt 中限制过死。我在 ModelEngine 的调试窗口直接修改 Prompt,降低了 Temperature 参数(设为 0.3),让输出更稳定,并移除了 Prompt 中重复的指令。
6.2 问题二:引用变量失效
-
现象:LLM 节点报错,提示找不到上下文。
-
解决:检查连线。在可视化编排中,必须确保前置节点的输出端口与后置节点的输入端口有物理连线。ModelEngine 的连线高亮显示功能帮我快速定位到了断点。
6.3 调试体验
ModelEngine 的调试面板非常专业,它会显示每一个节点的耗时、输入数据和输出数据。这对于排查是“检索没查到”还是“模型没写好”至关重要。
7. 深度横评:ModelEngine vs Coze vs Dify
作为一个体验过市面上主流 AI 开发平台的开发者,以下是我对 ModelEngine 的客观评价:
| 维度 | ModelEngine | Coze (字节) | Dify (开源) |
| 知识库处理 |
★★★★★ 自动摘要生成非常惊艳,解析速度快,对中文文档友好。 |
★★★★ 切片能力强,但摘要生成的自动化程度略低。 |
★★★★ RAG配置项极多,适合极客,上手门槛高。 |
| 工作流编排 |
★★★★☆ 节点逻辑清晰,变量引用通过 |
★★★★★ 插件生态极丰富,C端娱乐性强。 |
★★★★ 强在逻辑分支和代码节点,UI 偏技术流。 |
| 调试体验 |
★★★★★ 节点级日志详尽,Debug 效率极高。 |
★★★★ 调试过程较快,但中间变量查看不够直观。 |
★★★★ 日志详细,但界面响应有时较慢。 |
| 企业级特性 |
★★★★★ 权限管理、MCP 接入等设计明显偏向B端落地。 |
★★★ 更偏向个人开发者和 C 端应用。 |
★★★★ 支持私有化部署是优势。 |
核心结论:ModelEngine 在**“知识库自动化”和“可视化调试”**这两个关乎开发效率的核心点上,做得非常扎实,非常适合构建严肃的、业务逻辑复杂的企业级应用。
8. 总结与展望
通过不到 1 小时的配置,我们成功在 ModelEngine 上搭建了一个具备RAG 能力 + 自动优化 Prompt + 可视化编排的智能投研助手。
这个过程让我深刻体会到,AI 应用开发的门槛正在通过“可视化编排”被大幅降低。ModelEngine 不仅是一个工具,更像是一个标准的 LLMOps(大模型运维) 平台。
未来展望:
希望 ModelEngine 未来能进一步增强**多智能体协作(Multi-Agent)**的交互体验,例如让“搜索智能体”和“写作智能体”能够通过以更动态的方式进行多轮辩论和自我修正,从而产出更完美的报告。
如果你也想从 0 到 1 体验大模型落地,ModelEngine 绝对是一个值得尝试的硬核平台。
文章声明:本文为 ModelEngine·创作计划征文活动原创投稿,内容基于真实开发实践。欢迎技术交流与指正!
标签:#ModelEngine #AI智能体 #低代码开发 #RAG #工作流编排

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)