ollama本地安装与大模型与DeepSeek模型调用
Ollama本地部署DeepSeek R1模型指南 Ollama是一个开源的大模型本地运行框架,支持主流LLaMA架构模型。本文介绍了如何在Linux系统安装Ollama,并部署DeepSeek R1模型(1.5B版本)。主要内容包括:Ollama的安装方法、DeepSeek模型下载和运行命令、多GPU负载均衡配置技巧,以及REST API服务的启动和调用方式。文章还提供了解决常见问题的实用技巧,
Ollama 本地部署 Deepseek R1 模型
概念
Ollama是在Github上的一个开源项目,其项目定位是:一个本地运行大模型的集成框架;- 目前主要针对主流的
LLaMA架构的开源大模型设计,通过将模型权重、配置文件和必要数据封装进由Modelfile定义的包中,从而实现大模型的下载、启动和本地运行的自动化部署及推理流程; - 此外,
Ollama内置了一系列针对大模型运行和推理的优化策略,目前作为一个非常热门的大模型托管平台,基本主流的大模型应用开发框架如LangChain、AutoGen、Microsoft GraphRAG及热门项目AnythingLLM、OpenWebUI等高度集成。
Ollama官方地址:https://ollama.com/
Ollama Github开源地址:https://github.com/ollama/ollama
Ollama项目本地安装
windows电脑直接点击ollama下载按钮就可以安装好一个命令行界面。
在这里我们不细讲,我们主要是看任何在linux系统中安装ollama。
我们可以执行以下命令来对ollama进行安装
curl -fsSL https://ollama.com/install.sh | sh
这个过程会比较慢,拉取的文件约2G左右,如果安装过程中未出现任何错误信息,通常情况下能够表明安装已成功。可以通过执行以下命令来检查Ollama服务的运行状态:
systemctl status ollama
我们可以使用以下命令来查看ollama的版本
sudo ollama -v
Ollama部署DeepSeek
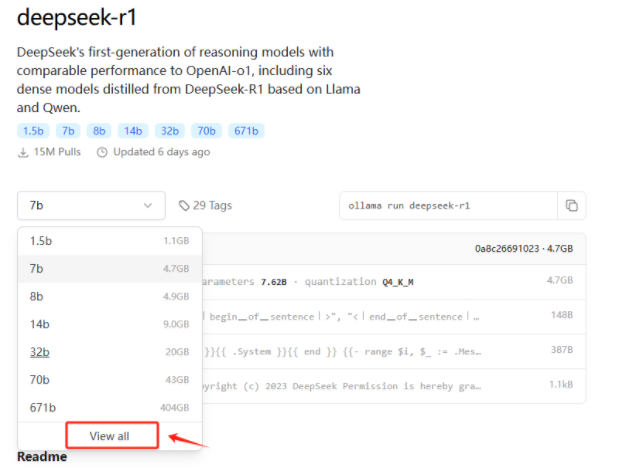
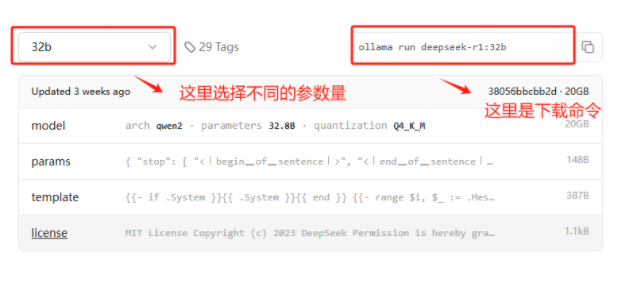
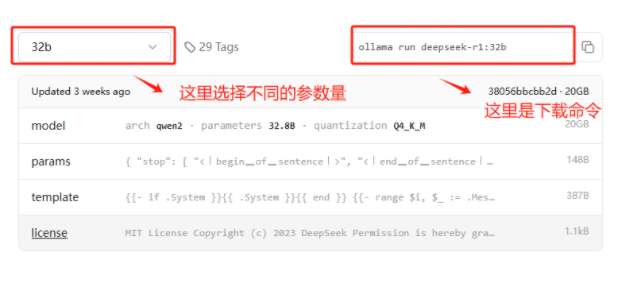
我们可以使用以下命令下载DeepSeek
ollama run deepseek-r1:1.5b
此外我们可以使用ollama list ,查看ollama的模型列表
使用DeepSeek
在 Ollama 的机制中,使用 run 命令时,系统会首先检查本地是否已经存在指定的模型,如果本地没有找到该模型,Ollama 会自动执行 ollama pull <model_name> 命令,从远程仓库下载该模型,下载完成后将模型存储为 GGUF 格式,供后续使用。最后,当成功下载后,Ollama 会继续执行 run 命令,启动模型并进行推理或生成任务。
这里要重点说明两点:其一是DeepSeek R1作为推理模型,其返回结果是包含的,里面包含的是思考推理的内容;其二也会存在中为空,这其实是因为DeepSeek-R1系列模型倾向于绕过思维模式(即输出” \ n \ n ”),因此一个使用的技巧是:每个输出的开头强制模型以 “\n” 开头。(此问题我们在代码环节在给大家讲解实现的方式)
多GPU部署级Server启动
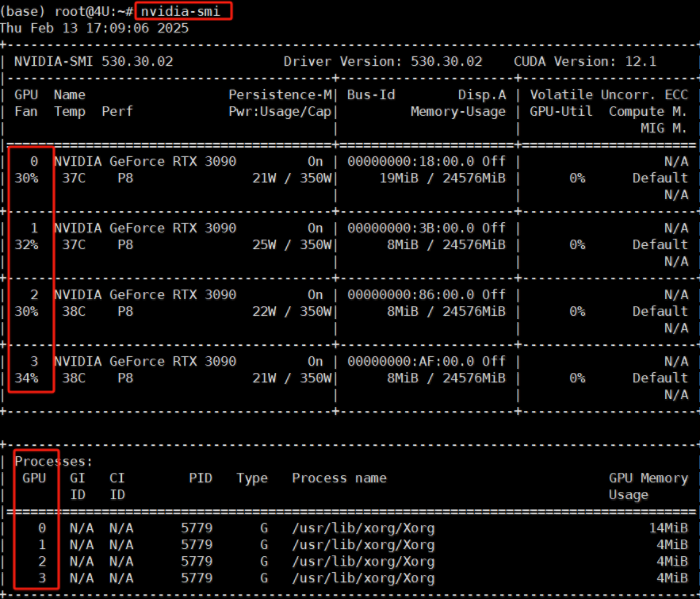
如果想加载多张显卡且做到负载均衡,可以去修改 ollama 的SystemD配置服务,首先找到当前服务器上GPU的 ID,执行命令如下:
nvidia-smi

如果想加载多张显卡且做到负载均衡,可以去修改 ollama 的SystemD配置服务,执行如下代码:
systemctl edit ollama.service
编辑并填写如下内容:
Environment="CUDA_VISIBLE_DEVICES=0,1,2,3" # 这里根据你自己实际的 GPU标号来进行修改
Environment="OLLAMA_SCHED_SPREAD=1" # 这个参数是做负载均衡
保存退出后,重新加载systemd并重新启动Ollama服务使其配置生效,执行如下命令:
systemctl daemon-reload
systemctl restart ollama
Ollama Rest Api 服务启动及其调用
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
api_key='ollama', # 这里随便写,但是api_key字段一定要有
)
chat_completion = client.chat.completions.create(
model='deepseek-r1:1.5b', # 这里要修改成 你 ollama 启动模型的名称
messages=[
{
'role': 'user',
'content': '你好,请你介绍一下你自己',
}
],
)
print(chat_completion)
这里需要注意的一点是:如果 Ollama 启动和执行调用的代码是同一台机器,上述代码是可以的跑通的。比如Ollama服务在云服务器、局域网的服务器上等情况,则无法通过http://localhost:11434/v1/ 来进行访问,因为网络不通。 正如上述的报错,我的Ollama模型服务是在局域网的服务器上,因此我需要修改Ollama REST API的请求地址,操作方法如下:
修改 ollama 的SystemD配置服务,执行如下代码:
systemctl edit ollama.service
编辑并填写如下内容:
Environment="OLLAMA_HOST=0.0.0.0:11434"
保存退出后,重新加载systemd并重新启动Ollama服务使其配置生效,执行如下命令:
systemctl daemon-reload
systemctl restart ollama
ollama基本命令
| 命令 | 描述 |
|---|---|
serve |
启动 Ollama 服务 |
create |
从 Modelfile 创建一个模型 |
show |
显示模型的信息 |
run |
运行一个模型 |
stop |
停止正在运行的模型 |
pull |
从注册表中拉取一个模型 |
push |
将一个模型推送到注册表 |
list |
列出所有模型 |
ps |
列出正在运行的模型 |
cp |
复制一个模型 |
rm |
删除一个模型 |
help |
显示关于任何命令的帮助信息 |
通过上述关于Ollama的安装、模型下载及启动推理的介绍和实践,我们可以感受到Ollama极大地简化了大模型部署的过程,也降低了大模型在使用上的技术门槛。然而,对大部分用户而言,命令行界面并不够友好。正如我们之前提到的,在大模型的应用开发框架下,使用到的往往是其API调用形式,为此,Ollama也是可以集成多个开源项目,包括Web界面、桌面应用和终端工具等方式提升使用体验,并满足满足不同用户的偏好和需求。
我们可以感受到Ollama极大地简化了大模型部署的过程,也降低了大模型在使用上的技术门槛。然而,对大部分用户而言,命令行界面并不够友好。正如我们之前提到的,在大模型的应用开发框架下,使用到的往往是其API调用形式,为此,Ollama也是可以集成多个开源项目,包括Web界面、桌面应用和终端工具等方式提升使用体验,并满足满足不同用户的偏好和需求。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)