AI-深度学习-循环神经网络RNN-编码器和解码器
·
目的
为避免一学就会、一用就废,这里做下笔记
说明
本文内容紧承前文-循环神经网络RNN,欲渐进,请循序
一、是什么?—— 定义与核心概念
编码器-解码器 是一种用于处理 序列到序列转换 的神经网络架构。它将一个领域的数据(如文本、图像)编码为中间表示,再解码为另一个领域的数据。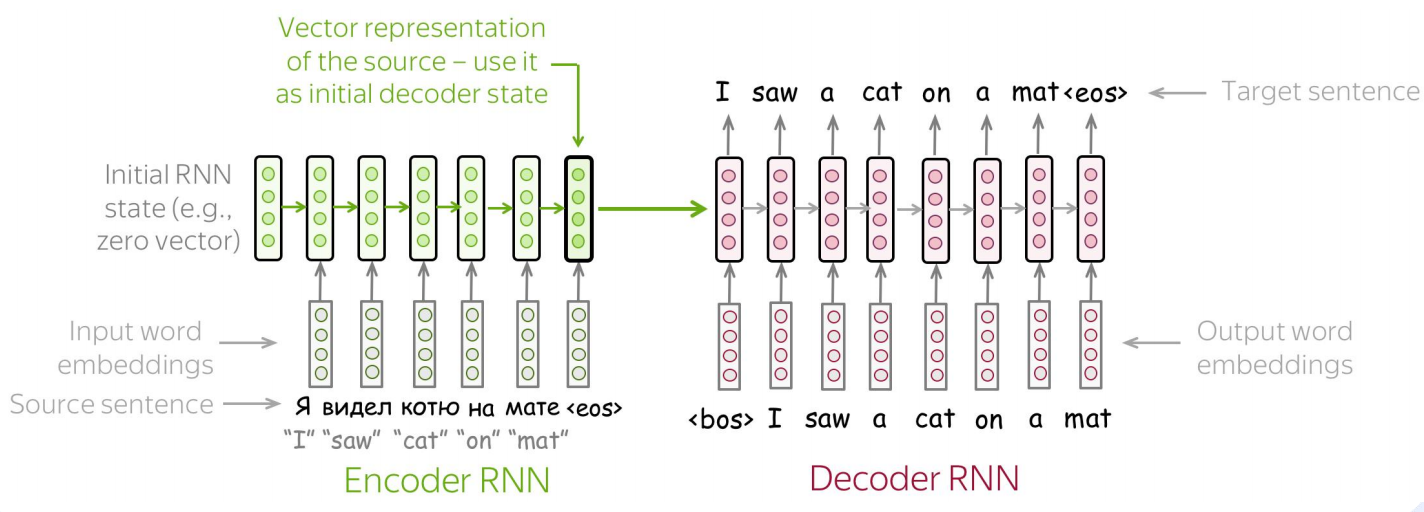
编码器(Encoder)
定义:将输入数据(通常是变长序列)压缩为一个固定维度的上下文向量。
作用:理解、概括、抽象输入内容。
输出:上下文向量 C(或隐藏状态序列)。
解码器(Decoder)
定义:将编码器生成的上下文向量 展开 为目标输出序列。
作用:根据编码的语义,生成对应的输出。
输出:目标序列 y 1 , y 2 , . . . , y t y_1, y_2, ..., y_t y1,y2,...,yt。
核心比喻:翻译官的工作流程
原始句子(中文) → 翻译官听并理解(编码器)
→ 翻译官在脑中形成意思(上下文向量)
→ 翻译官用英语说出来(解码器)
→ 目标句子(英文)
二、为什么?—— 解决的问题与动机
编码器-解码器架构主要是为了解决传统RNN无法处理的 序列到序列(Seq2Seq) 问题。
传统RNN的局限性:
- 输入输出长度必须一致:传统RNN要求输入和输出序列长度相同。
- 无法处理复杂映射:像机器翻译中,
"Bonjour"(法语,1个词)→ "Hello"(英语,1个词)可以,但"Comment allez-vous?"(3词)→ "How are you?"(3词)就很难保证对齐。 - 没有"完整理解"阶段:传统RNN边读边输出,无法先理解整个输入再生成输出。
编码器-解码器解决的三大问题:
-
变长输入输出问题:
输入: "我喜欢人工智能" (4个词) 输出: "I love artificial intelligence" (4个词但长度不同) -
语义抽象问题:
- 编码器从具体词句中提取抽象语义
- 解码器从抽象语义生成具体词句
-
跨模态转换问题:
图像 → 文字(图像描述) 文字 → 图像(文生图) 语音 → 文字(语音识别)
三、怎么办?—— 实现方式与演进
下图展示了编码器-解码器架构的核心思想、演进历程和不同变体的特点:
一、阶段1:基础RNN编码器-解码器(2014)
编码器(RNN):
class EncoderRNN(nn.Module):
def __init__(self, input_size, hidden_size):
super().__init__()
self.hidden_size = hidden_size
self.embedding = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
def forward(self, input, hidden):
embedded = self.embedding(input).view(1, 1, -1)
output, hidden = self.gru(embedded, hidden)
return output, hidden
def init_hidden(self):
return torch.zeros(1, 1, self.hidden_size)
解码器(RNN):
class DecoderRNN(nn.Module):
def __init__(self, hidden_size, output_size):
super().__init__()
self.embedding = nn.Embedding(output_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size)
self.out = nn.Linear(hidden_size, output_size)
self.softmax = nn.LogSoftmax(dim=1)
def forward(self, input, hidden):
output = self.embedding(input).view(1, 1, -1)
output = F.relu(output)
output, hidden = self.gru(output, hidden)
output = self.softmax(self.out(output[0]))
return output, hidden
局限性:信息瓶颈
编码器最后隐藏状态 = 上下文向量
必须将整个输入序列的信息压缩到一个固定向量中!
→ 长序列信息丢失严重
→ 性能受限
二、阶段2:加入注意力机制(2015年突破)
核心改进:动态上下文向量
不再用编码器最后一个隐藏状态,而是解码时动态计算上下文向量:
-
解码时刻 t 的上下文向量: c t = Σ i α t , i ∗ h i c_t = Σ_i α_{t,i} * h_i ct=Σiαt,i∗hi
-
α t , i α_{t,i} αt,i = 解码时刻t对编码时刻i的注意力权重
-
h i h_i hi = 编码器第i时刻的隐藏状态
-
注意力计算:
class Attention(nn.Module):
def __init__(self, hidden_size):
super().__init__()
self.attn = nn.Linear(hidden_size * 2, hidden_size)
self.v = nn.Parameter(torch.rand(hidden_size))
def forward(self, hidden, encoder_outputs):
# hidden: [1, batch, hidden_size] - 当前解码器状态
# encoder_outputs: [seq_len, batch, hidden_size]
seq_len = encoder_outputs.shape[0]
# 重复hidden以匹配序列长度
hidden_repeated = hidden.repeat(seq_len, 1, 1)
# 计算能量值
energy = torch.tanh(self.attn(
torch.cat((hidden_repeated, encoder_outputs), dim=2)))
# 计算注意力权重
energy = energy.permute(1, 2, 0) # [batch, hidden, seq_len]
v = self.v.repeat(encoder_outputs.size(1), 1).unsqueeze(1)
attention = torch.bmm(v, energy).squeeze(1) # [batch, seq_len]
return F.softmax(attention, dim=1)
带注意力的解码器:
class AttnDecoderRNN(nn.Module):
def forward(self, input, hidden, encoder_outputs):
embedded = self.embedding(input)
# 计算注意力权重
attn_weights = self.attention(hidden[-1], encoder_outputs)
# 计算上下文向量(加权和)
context = attn_weights.unsqueeze(1).bmm(
encoder_outputs.transpose(0, 1))
context = context.transpose(0, 1)
# 拼接输入和上下文
rnn_input = torch.cat((embedded, context), dim=2)
# GRU处理
output, hidden = self.gru(rnn_input, hidden)
# 最终输出
output = self.out(torch.cat((output, context), dim=2))
output = F.log_softmax(output, dim=2)
return output, hidden, attn_weights
三、阶段3:Transformer(完全基于注意力)
核心特点:完全并行,无RNN
class TransformerEncoderDecoder(nn.Module):
def __init__(self, src_vocab_size, tgt_vocab_size, d_model=512):
super().__init__()
# 编码器
self.encoder = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model, nhead=8),
num_layers=6
)
# 解码器
self.decoder = nn.TransformerDecoder(
nn.TransformerDecoderLayer(d_model, nhead=8),
num_layers=6
)
# 嵌入层和输出层
self.src_embedding = nn.Embedding(src_vocab_size, d_model)
self.tgt_embedding = nn.Embedding(tgt_vocab_size, d_model)
self.fc_out = nn.Linear(d_model, tgt_vocab_size)
def forward(self, src, tgt):
# 编码
src_embedded = self.src_embedding(src)
memory = self.encoder(src_embedded)
# 解码
tgt_embedded = self.tgt_embedding(tgt)
output = self.decoder(tgt_embedded, memory)
# 输出
return self.fc_out(output)
Transformer的并行性:
# 编码器:同时处理整个输入序列
# 解码器:训练时同时处理整个输出序列(用掩码防止看到未来)
# 推理时:自回归生成,但每个生成步骤内部并行
四、编码器-解码器的现代变体
1. 仅编码器架构(如BERT)
# 适用于:文本分类、命名实体识别、问答
# 特点:只有编码器,输出每个位置的表示
model = BertModel.from_pretrained('bert-base-uncased')
outputs = model(input_ids)
# outputs[0]: 每个token的编码 [batch, seq_len, hidden]
# outputs[1]: 整个序列的聚合表示 [batch, hidden]
2. 仅解码器架构(如GPT)
# 适用于:文本生成、代码生成
# 特点:只有解码器(带掩码自注意力)
model = GPT2LMHeadModel.from_pretrained('gpt2')
outputs = model(input_ids)
# 自回归生成文本
3. 编码器-解码器架构(如T5、BART)
# 适用于:翻译、摘要、风格转换
model = T5ForConditionalGeneration.from_pretrained('t5-base')
outputs = model.generate(input_ids=input_ids)
五、跨模态应用示例
图像描述生成(CNN编码器 + RNN解码器):
class ImageCaptioner(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size):
super().__init__()
# CNN编码器(处理图像)
self.encoder = models.resnet50(pretrained=True)
self.encoder.fc = nn.Linear(self.encoder.fc.in_features, embed_size)
# RNN解码器(生成文本)
self.decoder = DecoderRNN(embed_size, hidden_size, vocab_size)
def forward(self, images, captions):
# 编码图像
features = self.encoder(images) # [batch, embed_size]
# 解码生成描述
outputs = self.decoder(features, captions)
return outputs
语音识别(CNN+RNN编码器 + RNN解码器):
class SpeechRecognizer(nn.Module):
def __init__(self):
super().__init__()
# 编码器:CNN + RNN处理音频
self.encoder = nn.Sequential(
nn.Conv2d(1, 32, 3),
nn.ReLU(),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 3),
nn.ReLU(),
nn.MaxPool2d(2),
nn.LSTM(64*5*5, 256, bidirectional=True)
)
# 解码器:生成文本
self.decoder = AttnDecoderRNN(256*2, 512, vocab_size)
六、选择指南:何时用什么架构?
| 任务类型 | 推荐架构 | 理由 |
|---|---|---|
| 机器翻译 | Transformer编码器-解码器 | 性能最好,完全并行 |
| 文本摘要 | BART/T5(编码器-解码器) | 专为文本转换设计 |
| 文本分类 | BERT(仅编码器) | 理解任务不需要生成 |
| 文本生成 | GPT(仅解码器) | 生成任务不需要双向编码 |
| 图像描述 | CNN编码器 + Transformer解码器 | CNN处理图像,Transformer生成文本 |
| 语音识别 | CNN+RNN编码器 + RNN解码器(+注意力) | 音频时序性强 |
总结
是什么?
- 编码器:理解器,将输入压缩为抽象表示
- 解码器:生成器,将抽象表示展开为目标输出
- 核心:先理解,后生成的架构模式
为什么?
- 解决序列到序列的变长映射问题
- 分离理解和生成两个阶段
- 为注意力机制提供基础架构
怎么办?
- 基础版:RNN编码器 + RNN解码器(信息瓶颈)
- 改进版:+ 注意力机制(动态对齐)
- 现代版:Transformer(完全并行,多头注意力)
- 变体:仅编码器、仅解码器适应不同任务
编码器-解码器架构是深度学习中模块化思想的典范,通过分离输入理解和输出生成,实现了强大的序列转换能力,是自然语言处理、语音识别、计算机视觉等领域跨模态任务的基础架构。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 23
23 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)