第T1周:实现mnist手写数字识别
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
一. 前期工作
1. 设置GPU(如果使用的是CPU可以忽略这步)
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
gpu0 = gpus[0] #如果有多个GPU,仅使用第0个GPU
tf.config.experimental.set_memory_growth(gpu0, True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpu0],"GPU")
print(gpus)代码输出:
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]2. 导入数据
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
import matplotlib.pyplot as plt
# 导入mnist数据,依次分别为训练集图片、训练集标签、测试集图片、测试集标签
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()如果无法链接下载数据,可以把数据集放到代码文件同一个目录下,直接从本地加载数据集。
3. 归一化
# 将像素的值标准化至0到1的区间内。(对于灰度图片来说,每个像素最大值是255,每个像素最小值是0,也就是直接除以255就可以完成归一化。)
train_images, test_images = train_images / 255.0, test_images / 255.0
# 查看数据维数信息
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape(1) 归一化: 是机器学习中常见的预处理步骤,有助于模型训练,因为较小的输入值可以使优化过程更稳定。
-
将图像像素值从 0-255 的整数范围归一化到 0-1 的浮点数范围
-
归一化的原因:
-
使数据符合神经网络的激活函数输入范围要求
-
加速模型的收敛过程
-
提高模型的训练稳定性
-
防止数值溢出问题
-
(2) 查看数据形状: 这有助于我们理解数据集的规模,例如有多少训练样本和测试样本,每个样本的维度是多少。
注意:如果提供的代码是独立运行的,那么必须确保train_images和test_images是numpy数组(或类似数组,支持除以浮点数)。同样,train_labels和test_labels也应该是数组。
如果这些变量不存在,那么代码会抛出NameError。
另外,归一化操作不会改变数据的形状,只会改变数据的值。所以,归一化前后,train_images和test_images的形状不变。
代码输出:
输出:((60000, 28, 28), (10000, 28, 28), (60000,), (10000,))4. 可视化图片
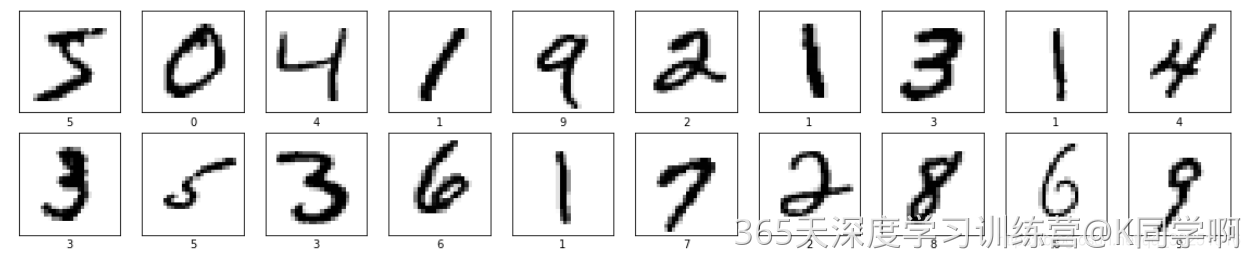
# 将数据集前20个图片数据可视化显示
# 进行图像大小为20宽、10长的绘图(单位为英寸inch)
plt.figure(figsize=(20,10))
# 遍历MNIST数据集下标数值0~49
for i in range(20):
# 将整个figure分成2行10列,绘制第i+1个子图。
plt.subplot(2,10,i+1)
# 设置不显示x轴刻度
plt.xticks([])
# 设置不显示y轴刻度
plt.yticks([])
# 设置不显示子图网格线
plt.grid(False)
# 图像展示,cmap为颜色图谱,"plt.cm.binary"为matplotlib.cm中的色表
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 设置x轴标签显示为图片对应的数字
plt.xlabel(train_labels[i])
# 显示图片
plt.show()代码可以帮助可视化MNIST数据集的前20张图片。
5. 调整图片格式
#调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
train_images.shape,test_images.shape,train_labels.shape,test_labels.shape
"""
输出:((60000, 28, 28, 1), (10000, 28, 28, 1), (60000,), (10000,))
"""主要是将MNIST数据集的图像数据进行维度重塑,以适应卷积神经网络(CNN)的输入要求。
原始MNIST数据集的形状可能是(60000, 28, 28)和(10000, 28, 28),分别代表训练集和测试集的图像数量、图像高度和图像宽度。
而卷积神经网络通常要求输入数据是四维的,即(样本数, 图像高度, 图像宽度, 通道数)。
对于灰度图像,通道数为1;对于彩色图像,通道数为3(RGB)。
因此,这里将训练集和测试集的图像数据重塑为(60000, 28, 28, 1)和(10000, 28, 28, 1)。
二. 训练模型
1. 构建CNN网络模型
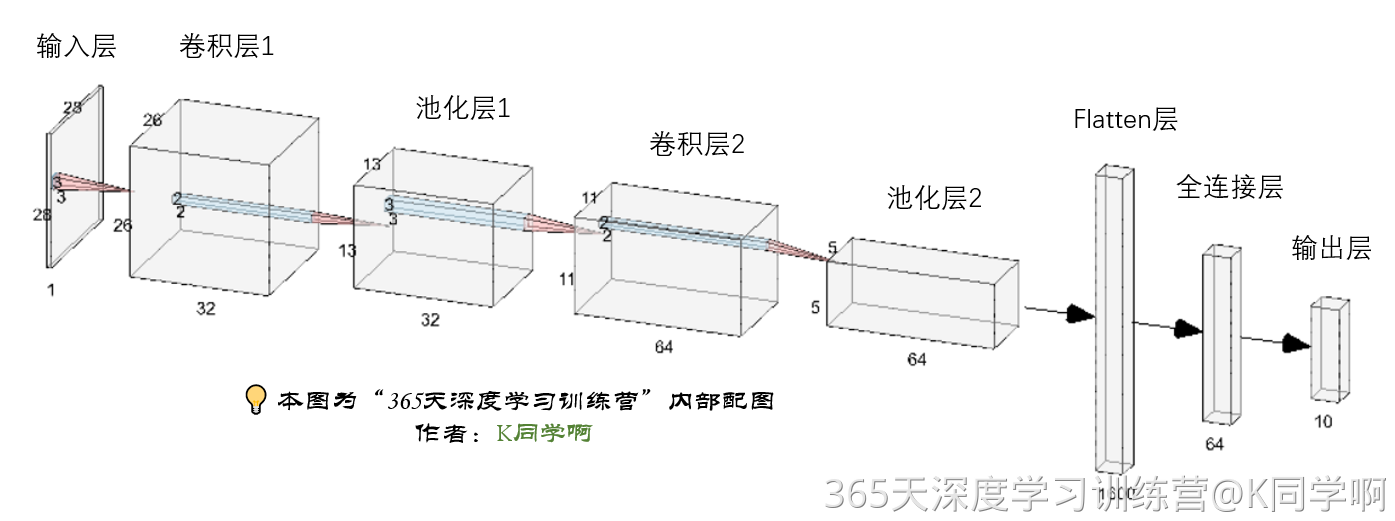
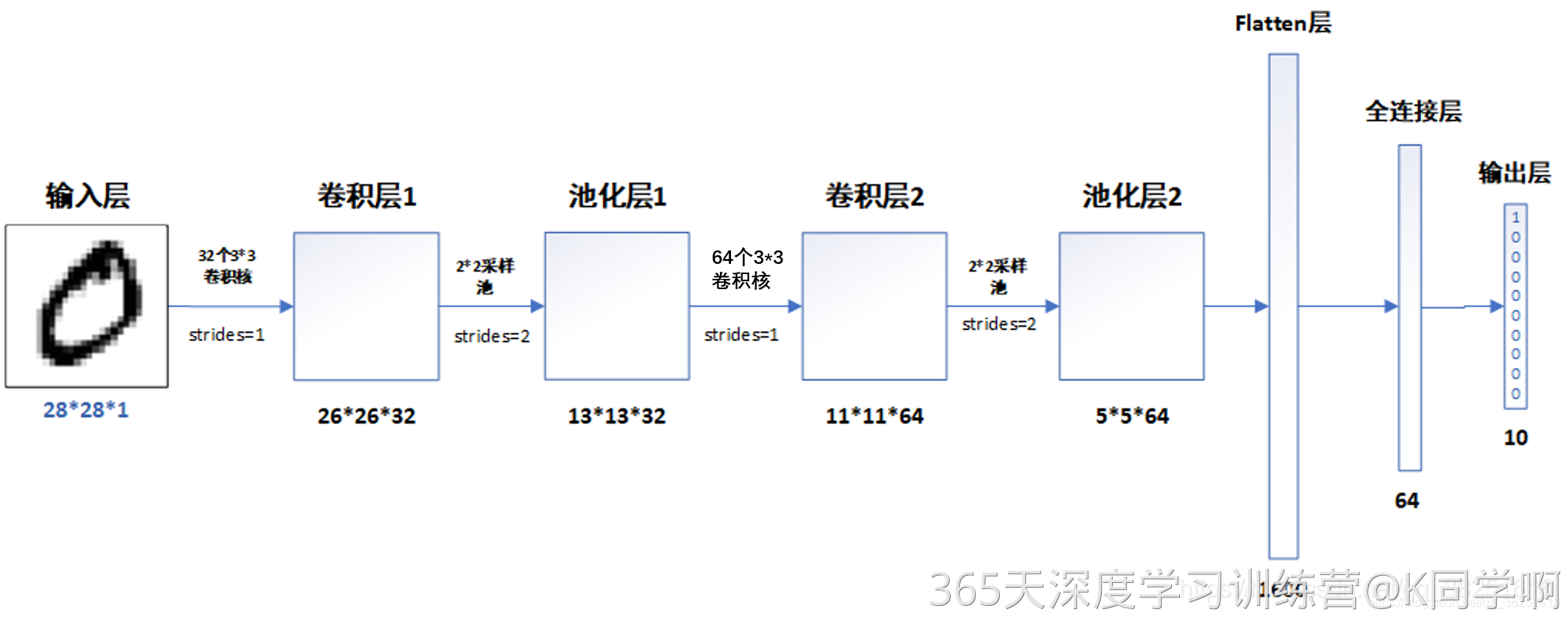
# 创建并设置卷积神经网络
# 卷积层:通过卷积操作对输入图像进行降维和特征抽取
# 池化层:是一种非线性形式的下采样。主要用于特征降维,压缩数据和参数的数量,减小过拟合,同时提高模型的鲁棒性。
# 全连接层:在经过几个卷积和池化层之后,神经网络中的高级推理通过全连接层来完成。
model = models.Sequential([
# 设置二维卷积层1,设置32个3*3卷积核,activation参数将激活函数设置为ReLu函数,input_shape参数将图层的输入形状设置为(28, 28, 1)
# ReLu函数作为激活励函数可以增强判定函数和整个神经网络的非线性特性,而本身并不会改变卷积层
# 相比其它函数来说,ReLU函数更受青睐,这是因为它可以将神经网络的训练速度提升数倍,而并不会对模型的泛化准确度造成显著影响。
layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)),
#池化层1,2*2采样
layers.MaxPooling2D((2, 2)),
# 设置二维卷积层2,设置64个3*3卷积核,activation参数将激活函数设置为ReLu函数
layers.Conv2D(64, (3, 3), activation='relu'),
#池化层2,2*2采样
layers.MaxPooling2D((2, 2)),
layers.Flatten(), #Flatten层,连接卷积层与全连接层
layers.Dense(64, activation='relu'), #全连接层,特征进一步提取,64为输出空间的维数,activation参数将激活函数设置为ReLu函数
layers.Dense(10) #输出层,输出预期结果,10为输出空间的维数
])
# 打印网络结构
model.summary()我们首先构建了一个Sequential模型,然后添加了卷积层、池化层、扁平层和全连接层。
模型结构如下:
-
第一层:Conv2D,32个3x3的卷积核,使用ReLU激活函数,输入形状为(28,28,1)
-
第二层:MaxPooling2D,2x2的池化窗口
-
第三层:Conv2D,64个3x3的卷积核,使用ReLU激活函数
-
第四层:MaxPooling2D,2x2的池化窗口
-
第五层:Flatten,将多维输入一维化,用于连接全连接层
-
第六层:Dense,64个神经元,使用ReLU激活函数
-
第七层:Dense,10个神经元(对应10个类别,不使用激活函数,因为后面会使用softmax)
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 5, 5, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1600) 0
_________________________________________________________________
dense (Dense) (None, 64) 102464
_________________________________________________________________
dense_1 (Dense) (None, 10) 650
=================================================================
Total params: 121,930
Trainable params: 121,930
Non-trainable params: 0
_________________________________________________________________2. 编译模型
"""
这里设置优化器、损失函数以及metrics
"""
# model.compile()方法用于在配置训练方法时,告知训练时用的优化器、损失函数和准确率评测标准
model.compile(
# 设置优化器为Adam优化器
optimizer='adam',
# 设置损失函数为交叉熵损失函数(tf.keras.losses.SparseCategoricalCrossentropy())
# from_logits为True时,会将y_pred转化为概率(用softmax),否则不进行转换,通常情况下用True结果更稳定
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# 设置性能指标列表,将在模型训练时监控列表中的指标
metrics=['accuracy'])使用TensorFlow的Keras API来编译之前构建的卷积神经网络模型。编译步骤是配置模型训练过程的重要一步,包括指定优化器、损失函数和评估指标。
-
优化器(optimizer):这里使用Adam优化器。Adam是一种自适应学习率的优化算法,结合了动量法和RMSprop的优点,通常能够快速且稳定地收敛。
-
损失函数(loss):使用SparseCategoricalCrossentropy损失函数,并且设置
from_logits=True。-
SparseCategoricalCrossentropy适用于多分类问题,且标签是整数形式(即0,1,2,...)的情况。MNIST的标签是0-9的整数,所以适用。
-
from_logits=True表示模型的输出层没有使用softmax激活函数(因为之前构建模型时输出层没有激活函数,即logits)。在计算损失时,会先将logits通过softmax函数转换为概率,再计算交叉熵损失。这样做的数值稳定性更好。
-
-
评估指标(metrics):设置为
['accuracy'],表示在训练和测试过程中会计算并输出准确率。
3. 训练模型
"""
这里设置输入训练数据集(图片及标签)、验证数据集(图片及标签)以及迭代次数epochs
关于model.fit()函数的具体介绍可参考我的博客:
https://blog.csdn.net/qq_38251616/article/details/122321757
"""
history = model.fit(
# 输入训练集图片
train_images,
# 输入训练集标签
train_labels,
# 设置10个epoch,每一个epoch都将会把所有的数据输入模型完成一次训练。
epochs=10,
# 设置验证集
validation_data=(test_images, test_labels))使用model.fit()方法训练模型
model.fit()方法功能
这是Keras/TensorFlow中训练模型的核心方法,执行以下操作:
-
将训练数据输入模型
-
计算损失并反向传播更新权重
-
监控训练和验证指标
-
记录训练历史
分析:
-
输入数据:
-
train_images: 训练集图像数据
-
train_labels: 训练集标签
-
-
训练轮数(epochs):
-
epochs=10:表示将整个训练集迭代10次。每次迭代都会更新模型权重。
-
-
验证数据:
-
validation_data=(test_images, test_labels):使用测试集作为验证数据,在每轮训练结束后评估模型性能。
-
-
返回值history:
-
是一个History对象,包含训练过程中损失和准确率等指标的历史记录。
-
三. 模型预测
输入一张图片,将会得到一组数,这组代表这张图片上的数字为0~9中每一个数字的几率(并非概率),out数字越大可能性越大。
plt.imshow(test_images[1])
可以输出测试集中第一张图片的预测结果。
pre = model.predict(test_images) # 对所有测试图片进行预测
pre[1] # 输出第一张图片的预测结果

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 14
14 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)