程序员必备:100行代码实现极简LLM框架,告别依赖地狱,轻松构建智能体应用
PocketFlow是一款革命性的极简LLM框架,仅用100行代码实现主流框架核心功能。它将LLM应用建模为"节点+流+共享存储"的有向图结构,支持智能体、工作流、RAG等所有AI设计模式。框架零依赖、无厂商锁定,解决了传统框架臃肿复杂、依赖冲突等问题。开发者可以像管理厨房工作流程一样直观地构建复杂AI应用,无需处理过度抽象带来的维护负担。这种"智能体化编程"
PocketFlow是一个仅用100行代码实现的极简LLM框架,解决了主流框架过于臃肿、依赖复杂的问题。它将LLM应用建模为简单的有向图结构(节点+流+共享存储),支持智能体、工作流、RAG等所有主流AI设计模式。框架零依赖、无厂商锁定,易于理解、调试和扩展,让开发者能够轻松构建复杂的大模型应用,代表了"智能体化编程"的未来开发范式。
Pocket Flow – 100 行代码的极简主义 LLM 框架
写在前面:一个关于"做减法"的故事
在智能体框架里,大家可能有个现象特别有意思:框架越做越大,文档越写越厚,依赖包动辄几百 MB,但真正用到的核心功能可能就那么几个。很多开发者盯着 LangChain 这类框架的代码库,心里嘀咕:“搞这么复杂,真的有必要吗?”
PocketFlow 的作者也有同样的困惑。在与臃肿框架斗争了整整一年后,这位开发者做了个大胆的决定:把所有不必要的东西统统砍掉。最终的成果令人惊艳——一个仅用 100 行代码实现的极简 LLM 框架,却能完成主流框架的所有核心功能。
主流框架到底哪里出了问题?
先来看看开发者们的真实吐槽。Octomind 工程团队在博客里直言不讳:“刚开始用 LangChain 时确实挺顺手,但这些高度抽象很快就让代码变得难以理解,维护起来简直是噩梦。”
Reddit 上的讨论更加热闹。有人调侃道:"就在你读完这句话的功夫,LangChain 已经废弃了 4 个类,而且文档还没更新。"另一位开发者的评价更直接:“极其不稳定,接口天天变,文档经常过时。”
这些问题归根结底就两个:过度抽象把简单功能埋在复杂性之下,实现混乱让开发者疲于应对依赖冲突和版本问题。
PocketFlow 的核心理念:LLM 应用本质就是有向图
在从零构建了多个 LLM 应用后,PocketFlow 的作者有了一个关键洞察:剥离所有花哨的外壳,LLM 系统的本质其实就是简单的有向图。基于这个发现,PocketFlow 应运而生——零臃肿、零依赖、无厂商锁定,核心代码仅 100 行。
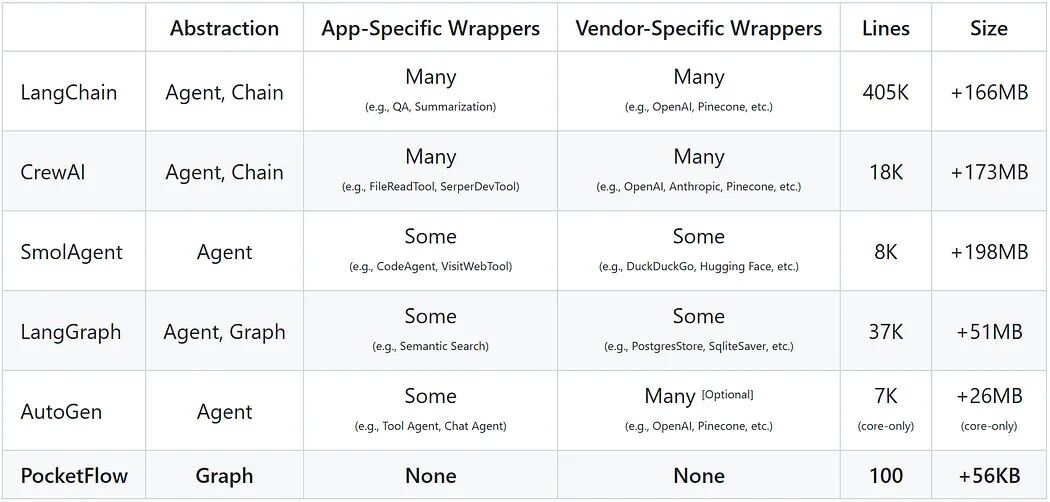
框架对比图
AI 框架在抽象层级、应用封装、厂商封装及代码量方面的对比
三个核心概念,像管理厨房一样简单
PocketFlow 把 LLM 工作流建模成图 + 共享存储的结构,可以用厨房来类比:
1. 节点(Node)—— 不同的料理台
每个节点就像厨房里的一个工作台,专门负责某项任务。节点只做三件事:
- Prep:从共享台拿取原料
- Exec:进行专业加工
- Post:把结果放回共享台,并决定下一步去哪
class BaseNode: def __init__(self): self.params, self.successors = {}, {} def prep(self, shared):pass # 准备工作 def exec(self, prep_res):pass # 执行任务 def post(self, shared, prep_res, exec_res):pass# 后处理 def run(self, shared): p = self.prep(shared) e = self.exec(p) return self.post(shared, p, e)
2. 流(Flow)—— 规定顺序的菜谱
Flow 决定了任务的执行顺序,就像菜谱规定先切菜、再烹饪、最后摆盘。
class Flow(BaseNode): def __init__(self, start): super().__init__() self.start = start def orch(self, shared, params=None): # 编排逻辑 curr = copy.copy(self.start) while curr: action = curr.run(shared) curr = copy.copy(curr.successors.get(action or "default"))
3. 共享存储(Shared Store)—— 厨房的备料台
所有料理台都能看到备料台上的食材,这就是共享存储的作用。通常就是一个内存中的字典:
load_data_node = LoadDataNode()summarize_node = SummarizeNode()load_data_node >> summarize_node # 定义流程flow = Flow(start=load_data_node)shared = {"file_name": "data.txt"}flow.run(shared)
在这个"智能厨房"里,菜谱(Flow)根据条件动态调度:“菜切好了就去烹饪台”,“饭煮好了就去摆盘台”。整个过程清晰透明,易于扩展。
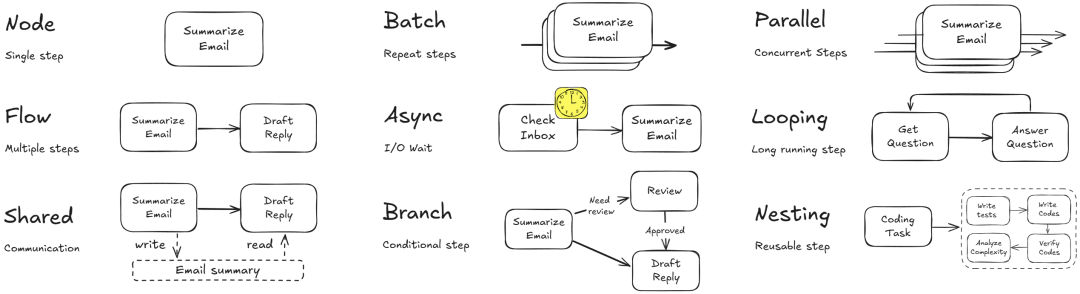
Pocket Flow – 核心抽象架构图
支持的设计模式:该有的都有
基于这套极简抽象,PocketFlow 能实现当前主流的所有 AI 设计模式:
- 智能体(Agent):具备自主决策能力
- 工作流(Workflow):将多个任务串联成流水线
- RAG(检索增强生成):数据检索与内容生成无缝集成
- MapReduce:大规模数据处理的经典范式
- 结构化输出:确保输出格式一致性
- 多智能体协作:协调多个智能体共同工作
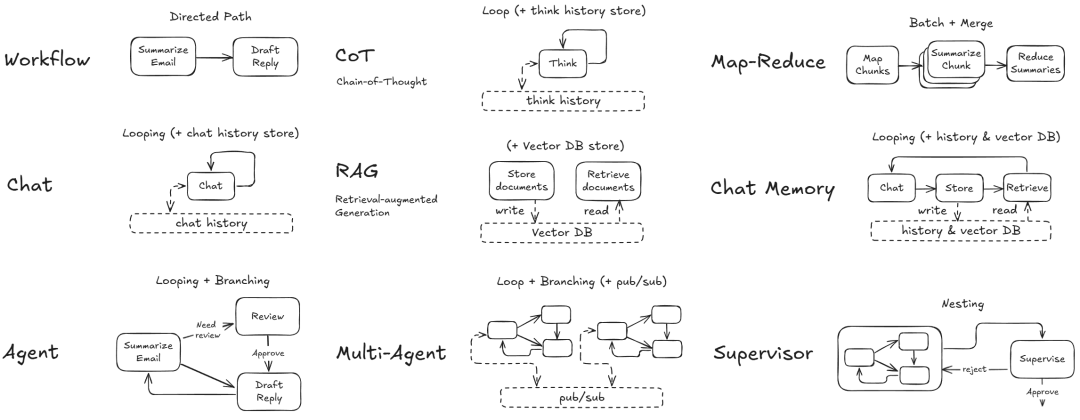
Pocket Flow – 设计模式示意图
所有这些模式都遵循同一套规则:在 100 行核心代码基础上,编写几百行业务逻辑就能实现。开发者不需要翻遍大型框架的成千上万个文件,而是从底层原理出发构建自己的理解。
实战案例:搭建一个网页搜索智能体
来看一个具体例子——搭建类似 Perplexity AI 的搜索智能体,能联网搜索并回答问题。
流程设计
整个智能体的行为可以建模为这样的图结构:
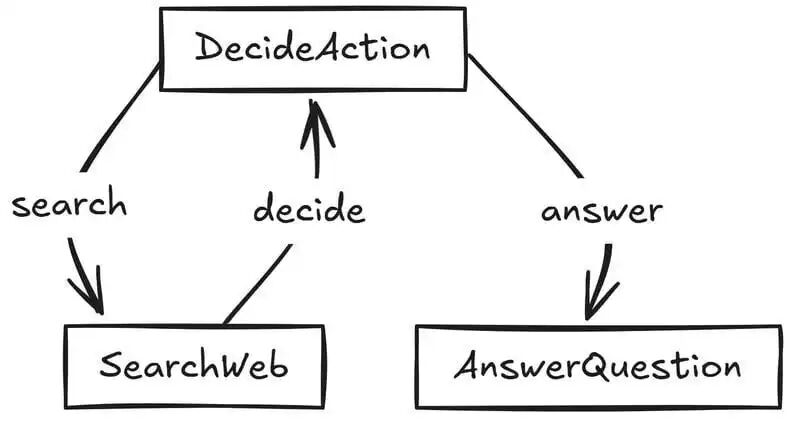
智能体流程图
# 初始化节点decide = DecideAction() # 决策节点search = SearchWeb() # 搜索节点answer = AnswerQuestion() # 回答节点# 定义连接逻辑decide - "search" >> searchdecide - "answer" >> answersearch - "decide" >> decide# 启动流程flow = Flow(start=decide)
节点职责分工
DecideAction(决策节点):判断当前应该去搜索网页,还是已有信息足够回答问题。
SearchWeb(搜索节点):调用搜索引擎 API 抓取信息,提炼关键内容后存入上下文。
AnswerQuestion(回答节点):汇总所有搜索信息,生成最终答案。
整个过程动态透明,随时可以更换 LLM 模型或搜索引擎,而无需改动核心逻辑。
RAG 系统实现示例
再看一个 RAG 系统的实现,代码结构同样清晰:
from pocketflow import Node, Flow, BatchNode# 离线流程:文档处理class ChunkDocumentsNode(BatchNode): def exec(self, text): """将单个文本切分成小块""" return fixed_size_chunk(text) def post(self, shared, prep_res, exec_res_list): """存储切分后的文本""" all_chunks = [chunk for chunks in exec_res_list for chunk in chunks] shared["texts"] = all_chunks print(f"✅ 从 {len(prep_res)} 个文档创建了 {len(all_chunks)} 个片段")class EmbedDocumentsNode(BatchNode): def exec(self, text): """对单个文本进行向量化""" return get_embedding(text)# 在线流程:查询处理class RetrieveDocumentNode(Node): def exec(self, inputs): """在索引中搜索相似文档""" query_embedding, index, texts = inputs distances, indices = index.search(query_embedding, k=1) best_idx = indices[0][0] return {"text": texts[best_idx], "index": best_idx}
为什么不内置 API 封装?刻意的设计选择
细心的开发者会发现,PocketFlow 刻意避开了绑定特定厂商的 API。这个决定背后有深思熟虑的考量:
摆脱依赖地狱:主流框架动辄几百 MB 的依赖包,PocketFlow 则是零依赖,让项目保持轻量灵活。
避免厂商锁定:可以自由使用任何模型,包括 OpenLLaMA 这样的本地模型,无需修改核心架构。
完全的自定义控制:想实现 Prompt 缓存、批处理或流式输出?直接根据需求构建,不受预设抽象的限制。
框架作者的观点很明确:API 易变、需求多样、性能优化各有侧重。如果需要 API 封装,完全可以让 ChatGPT 即时生成一个,通常也就 10 行代码。这比维护那些很快就会过时的内置库要灵活得多。
智能体化编程:未来的开发范式
PocketFlow 最具革命性的地方在于开启了**智能体化编程(Agentic Coding)**的可能。
这是一种由 AI 助手辅助构建和修改 AI 应用的新范式。打个比方:
- 开发者是建筑师,负责高层设计和战略决策
- AI 助手是施工队,处理细节实现
- 开发者通过评审和微调引导整个过程
这种模式能带来 10 倍的生产力提升,让开发者从枯燥的模板代码中解放出来。
文档即代码的理念
以往的框架试图为每类应用硬编码封装,结果让开发者和 AI 助手都感到困惑。PocketFlow 的解决方案是:把文档当作第二代码库。
框架提供极简的基础模块,辅以清晰的"教学文档",告诉 AI 如何组合这些模块。这些说明直接作为规则文件(如 Cursor 的 .cursorrules)喂给 AI 助手,使其具备灵活构建复杂系统的知识,而不是死记硬背框架接口。
能力边界:不仅仅是搜索智能体
PocketFlow 的潜力远不止于此。开发者可以用同样优雅简洁的方式构建:
- 多智能体协作系统:多个智能体分工合作解决复杂问题
- RAG 检索系统:结合知识库的智能问答
- MapReduce 计算:处理大规模数据任务
- 模型上下文协议(MCP):标准化的模型交互接口
更复杂的应用可能需要 5-15 个工具调用,结合 Web 搜索、内部工具(如 Google Drive、Gmail、Slack)来综合处理信息。PocketFlow 让开发者能够灵活编排这些工具,而不是被框架预设的模式所束缚。
开发者反馈:终于不用跳水了
从社区反馈来看,PocketFlow 戳中了很多开发者的痛点:
“终于有个框架不需要先读几天文档才能上手了。”
“100 行核心代码意味着出了问题能自己调试,不用在框架的黑盒里瞎猜。”
“最喜欢的是没有依赖冲突,项目部署简直太省心了。”
技术细节:支持批处理、异步和并行
虽然核心只有 100 行,但 PocketFlow 该有的高级特性一个不少:
批处理(Batch):支持节点或流处理大规模数据密集型任务。
异步(Async):支持节点或流等待异步任务执行。
并行(Parallel):专门优化 I/O 密集型任务的性能。
这些能力让 PocketFlow 能够应对从简单脚本到复杂生产环境的各种场景。
快速开始:三步上手
想要尝试 PocketFlow?过程非常简单:
- 克隆仓库:
git clone https://github.com/the-pocket/PocketFlow - 阅读文档:官方文档 提供了详细的教程和示例
- 开始构建:从示例代码开始,逐步构建自己的应用
还有 TypeScript 版本 可供选择,满足不同技术栈的需求。
写在最后:大道至简
PocketFlow 的出现提醒开发者:复杂的问题不一定需要复杂的解决方案。通过将 LLM 应用建模为简单的有向图,剔除所有冗余,PocketFlow 实现了透明的逻辑和完全的掌控。
如果已经厌倦了在复杂框架中"跳水",想从零开始真正掌握 AI 应用的构建,PocketFlow 的极简主义或许正是通往智能体革命的门票。
立即体验:
- GitHub 仓库 https://github.com/the-pocket/PocketFlow
- 官方文档 https://the-pocket.github.io/PocketFlow/
代码
PocketFlow核心代码:
import asyncio, warnings, copy, timeclass BaseNode: def __init__(self): self.params,self.successors={},{} def set_params(self,params): self.params=params def next(self,node,action="default"): if action in self.successors: warnings.warn(f"Overwriting successor for action '{action}'") self.successors[action]=node; return node def prep(self,shared): pass def exec(self,prep_res): pass def post(self,shared,prep_res,exec_res): pass def _exec(self,prep_res): return self.exec(prep_res) def _run(self,shared): p=self.prep(shared); e=self._exec(p); return self.post(shared,p,e) def run(self,shared): if self.successors: warnings.warn("Node won't run successors. Use Flow.") return self._run(shared) def __rshift__(self,other): return self.next(other) def __sub__(self,action): if isinstance(action,str): return _ConditionalTransition(self,action) raise TypeError("Action must be a string")class _ConditionalTransition: def __init__(self,src,action): self.src,self.action=src,action def __rshift__(self,tgt): return self.src.next(tgt,self.action)class Node(BaseNode): def __init__(self,max_retries=1,wait=0): super().__init__(); self.max_retries,self.wait=max_retries,wait def exec_fallback(self,prep_res,exc): raise exc def _exec(self,prep_res): for self.cur_retry in range(self.max_retries): try: return self.exec(prep_res) except Exception as e: if self.cur_retry==self.max_retries-1: return self.exec_fallback(prep_res,e) if self.wait>0: time.sleep(self.wait)class BatchNode(Node): def _exec(self,items): return [super(BatchNode,self)._exec(i) for i in (items or [])]class Flow(BaseNode): def __init__(self,start=None): super().__init__(); self.start_node=start def start(self,start): self.start_node=start; return start def get_next_node(self,curr,action): nxt=curr.successors.get(action or "default") if not nxt and curr.successors: warnings.warn(f"Flow ends: '{action}' not found in {list(curr.successors)}") return nxt def _orch(self,shared,params=None): curr,p,last_action =copy.copy(self.start_node),(params or {**self.params}),None while curr: curr.set_params(p); last_action=curr._run(shared); curr=copy.copy(self.get_next_node(curr,last_action)) return last_action def _run(self,shared): p=self.prep(shared); o=self._orch(shared); return self.post(shared,p,o) def post(self,shared,prep_res,exec_res): return exec_resclass BatchFlow(Flow): def _run(self,shared): pr=self.prep(shared) or [] for bp in pr: self._orch(shared,{**self.params,**bp}) return self.post(shared,pr,None)class AsyncNode(Node): async def prep_async(self,shared): pass async def exec_async(self,prep_res): pass async def exec_fallback_async(self,prep_res,exc): raise exc async def post_async(self,shared,prep_res,exec_res): pass async def _exec(self,prep_res): for self.cur_retry in range(self.max_retries): try: return await self.exec_async(prep_res) except Exception as e: if self.cur_retry==self.max_retries-1: return await self.exec_fallback_async(prep_res,e) if self.wait>0: await asyncio.sleep(self.wait) async def run_async(self,shared): if self.successors: warnings.warn("Node won't run successors. Use AsyncFlow.") return await self._run_async(shared) async def _run_async(self,shared): p=await self.prep_async(shared); e=await self._exec(p); return await self.post_async(shared,p,e) def _run(self,shared): raise RuntimeError("Use run_async.")class AsyncBatchNode(AsyncNode,BatchNode): async def _exec(self,items): return [await super(AsyncBatchNode,self)._exec(i) for i in items]class AsyncParallelBatchNode(AsyncNode,BatchNode): async def _exec(self,items): return await asyncio.gather(*(super(AsyncParallelBatchNode,self)._exec(i) for i in items))class AsyncFlow(Flow,AsyncNode): async def _orch_async(self,shared,params=None): curr,p,last_action =copy.copy(self.start_node),(params or {**self.params}),None while curr: curr.set_params(p); last_action=await curr._run_async(shared) if isinstance(curr,AsyncNode) else curr._run(shared); curr=copy.copy(self.get_next_node(curr,last_action)) return last_action async def _run_async(self,shared): p=await self.prep_async(shared); o=await self._orch_async(shared); return await self.post_async(shared,p,o) async def post_async(self,shared,prep_res,exec_res): return exec_resclass AsyncBatchFlow(AsyncFlow,BatchFlow): async def _run_async(self,shared): pr=await self.prep_async(shared) or [] for bp in pr: await self._orch_async(shared,{**self.params,**bp}) return await self.post_async(shared,pr,None)class AsyncParallelBatchFlow(AsyncFlow,BatchFlow): async def _run_async(self,shared): pr=await self.prep_async(shared) or [] await asyncio.gather(*(self._orch_async(shared,{**self.params,**bp}) for bp in pr)) return await self.post_async(shared,pr,None)
RAG示例完整代码如下:
from pocketflow import Node, Flow, BatchNodeimport numpy as npimport faissfrom utils import call_llm, get_embedding, fixed_size_chunk# Nodes for the offline flowclass ChunkDocumentsNode(BatchNode): def prep(self, shared): """Read texts from shared store""" return shared["texts"] def exec(self, text): """Chunk a single text into smaller pieces""" return fixed_size_chunk(text) def post(self, shared, prep_res, exec_res_list): """Store chunked texts in the shared store""" # Flatten the list of lists into a single list of chunks all_chunks = [] for chunks in exec_res_list: all_chunks.extend(chunks) # Replace the original texts with the flat list of chunks shared["texts"] = all_chunks print(f"✅ Created {len(all_chunks)} chunks from {len(prep_res)} documents") return"default" class EmbedDocumentsNode(BatchNode): def prep(self, shared): """Read texts from shared store and return as an iterable""" return shared["texts"] def exec(self, text): """Embed a single text""" return get_embedding(text) def post(self, shared, prep_res, exec_res_list): """Store embeddings in the shared store""" embeddings = np.array(exec_res_list, dtype=np.float32) shared["embeddings"] = embeddings print(f"✅ Created {len(embeddings)} document embeddings") return"default"class CreateIndexNode(Node): def prep(self, shared): """Get embeddings from shared store""" return shared["embeddings"] def exec(self, embeddings): """Create FAISS index and add embeddings""" print("🔍 Creating search index...") dimension = embeddings.shape[1] # Create a flat L2 index index = faiss.IndexFlatL2(dimension) # Add the embeddings to the index index.add(embeddings) return index def post(self, shared, prep_res, exec_res): """Store the index in shared store""" shared["index"] = exec_res print(f"✅ Index created with {exec_res.ntotal} vectors") return"default"# Nodes for the online flowclass EmbedQueryNode(Node): def prep(self, shared): """Get query from shared store""" return shared["query"] def exec(self, query): """Embed the query""" print(f"🔍 Embedding query: {query}") query_embedding = get_embedding(query) return np.array([query_embedding], dtype=np.float32) def post(self, shared, prep_res, exec_res): """Store query embedding in shared store""" shared["query_embedding"] = exec_res return"default"class RetrieveDocumentNode(Node): def prep(self, shared): """Get query embedding, index, and texts from shared store""" return shared["query_embedding"], shared["index"], shared["texts"] def exec(self, inputs): """Search the index for similar documents""" print("🔎 Searching for relevant documents...") query_embedding, index, texts = inputs # Search for the most similar document distances, indices = index.search(query_embedding, k=1) # Get the index of the most similar document best_idx = indices[0][0] distance = distances[0][0] # Get the corresponding text most_relevant_text = texts[best_idx] return { "text": most_relevant_text, "index": best_idx, "distance": distance } def post(self, shared, prep_res, exec_res): """Store retrieved document in shared store""" shared["retrieved_document"] = exec_res print(f"📄 Retrieved document (index: {exec_res['index']}, distance: {exec_res['distance']:.4f})") print(f"📄 Most relevant text: \"{exec_res['text']}\"") return"default" class GenerateAnswerNode(Node): def prep(self, shared): """Get query, retrieved document, and any other context needed""" return shared["query"], shared["retrieved_document"] def exec(self, inputs): """Generate an answer using the LLM""" query, retrieved_doc = inputs prompt = f"""Briefly answer the following question based on the context provided:Question: {query}Context: {retrieved_doc['text']}Answer:""" answer = call_llm(prompt) return answer def post(self, shared, prep_res, exec_res): """Store generated answer in shared store""" shared["generated_answer"] = exec_res print("\n🤖 Generated Answer:") print(exec_res) return"default"
AI大模型从0到精通全套学习大礼包
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
只要你是真心想学AI大模型,我这份资料就可以无偿共享给你学习。大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
如果你也想通过学大模型技术去帮助就业和转行,可以扫描下方链接👇👇
大模型重磅福利:入门进阶全套104G学习资源包免费分享!

01.从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点
02.AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线


03.学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的


04.大模型面试题目详解


05.这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 2
2 0
0- 0



 已为社区贡献714条内容
已为社区贡献714条内容

所有评论(0)