实战|用 AI 大模型 + Selenium 打造信息查询 RPA,自动识别验证码的那些坑与解法
本文记录了一个真实的企业级 RPA 项目开发过程——为某金融机构开发票据承兑人信用信息批量查询系统。项目核心难点在于**腾讯验证码的自动识别与点击**,我们通过引入**通义千问视觉大模型**实现了验证码的智能识别,并深入解决了 Mac Retina 屏幕下的**坐标转换**、**iframe 嵌套**、**持久化登录**等一系列工程难题。全文约 10800字,适合对 RPA、Selenium、LL
摘要:本文记录了一个真实的企业级 RPA 项目开发过程——信息批量查询系统。项目核心难点在于验证码的自动识别与点击,我们通过引入通义千问视觉大模型实现了验证码的智能识别,并深入解决了 Mac Retina 屏幕下的坐标转换、iframe 嵌套、持久化登录等一系列工程难题。全文约 10800 字,适合对 RPA、Selenium、LLM 视觉应用感兴趣的开发者。
一、需求背景:为什么要做这个 RPA?
1.1 业务痛点
某团队每天需要在某个专业网站上登录查询相关信息。
手工操作流程是这样的:
登录网站 → 输入查询信息 → 选择日期 → 点击查询 → 处理验证码 → 复制结果到Excel
痛点显而易见:
- 🕐 每条信息查询耗时约 2-3 分钟,100 条信息需要 4-5 小时
- 😵 验证码需要人工点击,极易疲劳出错
- 📱 登录需要手机短信验证,频繁登录可能触发风控
- 📊 数据手工复制容易遗漏字段
1.2 需求目标
开发一套 RPA 自动化系统,实现:
| 功能 | 描述 |
|---|---|
| 批量查询 | 一次性传入多个查询信息名称,自动依次查询 |
| 自动登录 | 支持 Cookie 持久化,避免频繁短信验证 |
| 验证码识别 | 自动识别并点击验证码 |
| 结果导出 | 查询结果自动保存为 CSV 文件 |
| 人机协作 | 机器识别失败时,支持人工介入 |
二、技术选型:为什么是这套方案?
2.1 整体架构
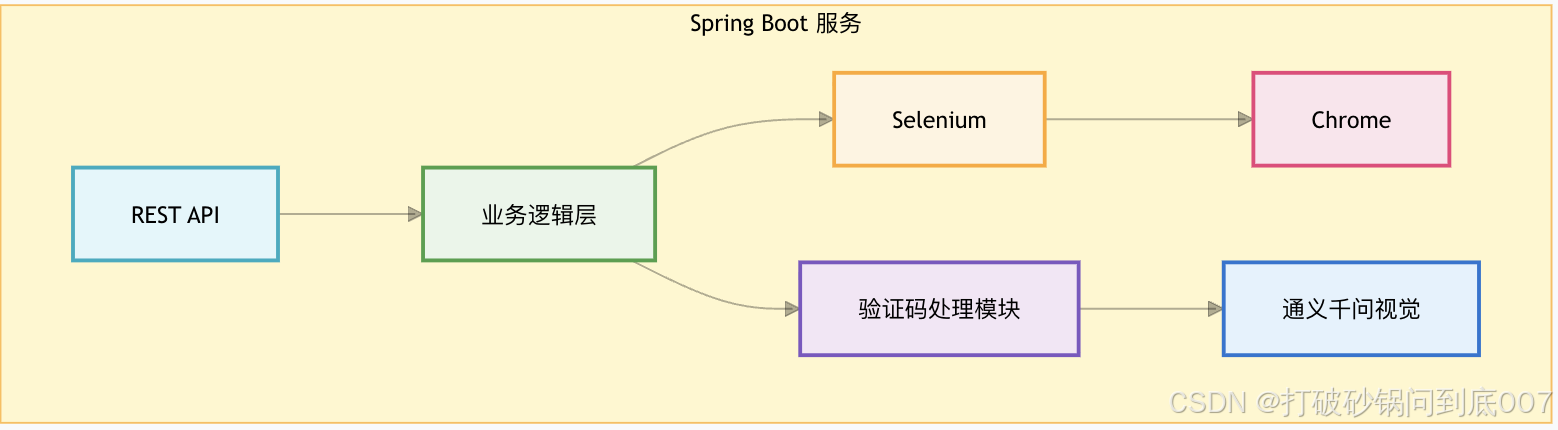
2.2 技术栈选择
| 技术 | 选择 | 理由 |
|---|---|---|
| 后端框架 | Spring Boot 2.7 | 企业级稳定,生态丰富 |
| 浏览器自动化 | Selenium 4.x | 行业标准,功能全面 |
| 验证码识别 | 通义千问 VL | 多模态理解能力强,支持中文 |
| 浏览器 | Chrome + ChromeDriver | 兼容性最好 |
| 数据存储 | CSV 文件 | 简单直接,Excel 友好 |
2.3 为什么选择通义千问做验证码识别?
传统验证码识别方案对比:
| 方案 | 优点 | 缺点 |
|---|---|---|
| OCR(Tesseract) | 开源免费 | 只能识别文字,无法理解语义 |
| 打码平台 | 准确率高 | 收费、有安全风险 |
| 自训练模型 | 可控性强 | 需要大量标注数据 |
| LLM 视觉 | 理解语义、零样本 | API 调用有延迟 |
该查询网站的验证码类型多样:
- 📝 依次点击:「请依次点击:7 [建筑] 4」
- 🔤 字母朝向:「请点击朝上的字母」
- 🎚️ 滑动拼图:拖动滑块到缺口位置
- 🔢 点击数字:「请点击圆柱体上面的数字」
这些验证码的共同特点是需要理解语义,LLM 视觉大模型是最佳选择。
三、核心难点与解决方案
3.1 难点一:验证码的多类型识别
问题描述
该网站验证码至少有 4 种类型,每种类型的处理逻辑完全不同: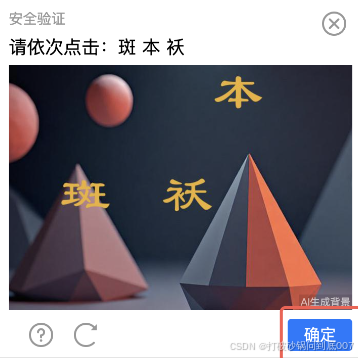
// 验证码类型判断
public String determineCaptchaType(String instruction) {
if (instruction.contains("依次点击") || instruction.contains("顺序点击")) {
return "click_text"; // 需要按顺序点击多个目标
}
if (instruction.contains("朝上") || instruction.contains("朝下") ||
instruction.contains("朝左") || instruction.contains("朝右")) {
return "click_letter"; // 点击特定朝向的字母
}
if (instruction.contains("滑动") || instruction.contains("拖动")) {
return "drag_slider"; // 滑动拼图
}
return "common"; // 通用点击类型
}
解决方案
Step 1:截图验证码弹窗
// 精确截取验证码区域,而不是全屏截图
WebElement captchaPopup = driver.findElement(
By.cssSelector("#tcaptcha_transform_dy, .tcaptcha-transform")
);
byte[] screenshotBytes = captchaPopup.getScreenshotAs(OutputType.BYTES);
Step 2:调用 LLM 提取验证码指令
// Prompt 设计很关键!
String prompt = """
请仔细观察这张验证码图片,提取验证码的提示文字。
如果提示中包含图形(如建筑、动物等),请用方括号描述,
例如:请依次点击:7 [建筑] 4
只返回提示文字,不要其他内容。
""";
String instruction = tongYiVisionService.extractCaptchaInstruction(screenshotBytes, prompt);
// 返回示例:"请依次点击:7 [建筑] 4"
Step 3:根据类型调用不同的识别逻辑
switch (captchaType) {
case "click_text":
// 让 LLM 返回每个目标的坐标
return handleClickTextCaptcha(captchaPopup, instruction);
case "click_letter":
return handleClickLetterCaptcha(captchaPopup, instruction);
case "drag_slider":
return handleDragSliderCaptcha(captchaPopup);
default:
return handleCommonCaptcha(captchaPopup, instruction);
}
3.2 难点二:坐标转换的「玄学」问题
这是整个项目最烧脑的部分,也是很多 RPA 项目失败的原因。
问题现象
LLM 返回了正确的坐标,比如「点击位置 (150, 200)」,但实际点击位置偏差很大,甚至点到了验证码区域外面!
根因分析
这里涉及到三个坐标系的转换: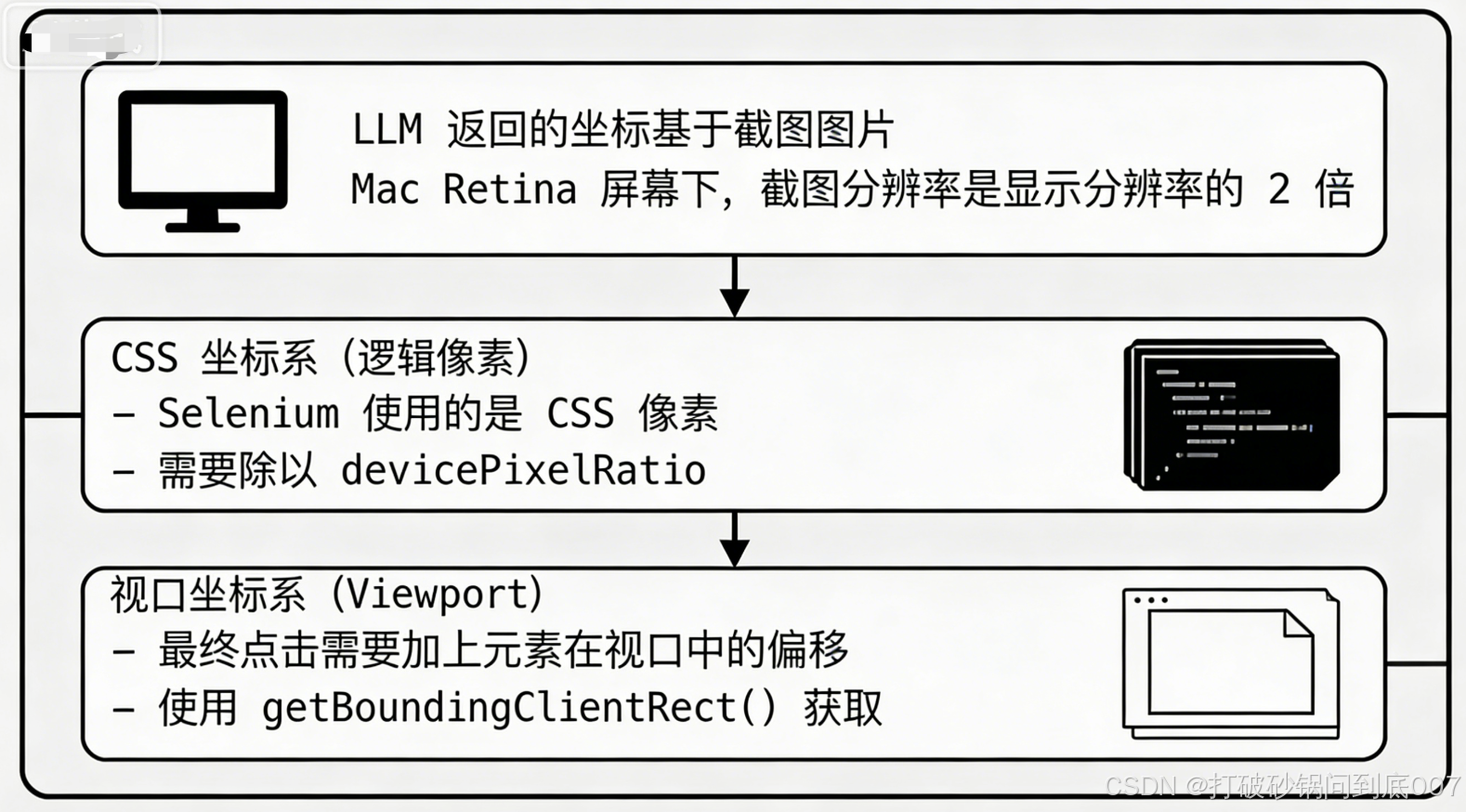
解决方案
public void clickAtImageCoordinate(WebElement element, int imageX, int imageY, byte[] screenshotBytes) {
JavascriptExecutor js = (JavascriptExecutor) driver;
// 1. 获取设备像素比(Mac Retina 通常是 2.0)
double devicePixelRatio = ((Number) js.executeScript(
"return window.devicePixelRatio || 1;"
)).doubleValue();
// 2. 获取元素在视口中的位置和大小
Map<String, Object> rect = (Map<String, Object>) js.executeScript(
"var r = arguments[0].getBoundingClientRect();" +
"return {left: r.left, top: r.top, width: r.width, height: r.height};",
element
);
double elemLeft = ((Number) rect.get("left")).doubleValue();
double elemTop = ((Number) rect.get("top")).doubleValue();
double elemWidth = ((Number) rect.get("width")).doubleValue();
double elemHeight = ((Number) rect.get("height")).doubleValue();
// 3. 获取截图的实际尺寸
int[] imgDimensions = getImageDimensions(screenshotBytes);
int imgWidth = imgDimensions[0];
int imgHeight = imgDimensions[1];
// 4. 计算缩放比例
double cssImgWidth = imgWidth / devicePixelRatio;
double cssImgHeight = imgHeight / devicePixelRatio;
double ratioX = elemWidth / cssImgWidth;
double ratioY = elemHeight / cssImgHeight;
// 5. 转换坐标
double cssX = imageX / devicePixelRatio;
double cssY = imageY / devicePixelRatio;
int viewportX = (int) (elemLeft + cssX * ratioX);
int viewportY = (int) (elemTop + cssY * ratioY);
// 6. 执行点击
Actions actions = new Actions(driver);
actions.moveByOffset(viewportX, viewportY).click().perform();
actions.moveByOffset(-viewportX, -viewportY).perform(); // 归位
}
调试技巧:添加可视化标记
为了验证坐标转换是否正确,我们在点击位置添加临时标记:
private void addClickMarker(int x, int y, String label) {
String script = String.format(
"var marker = document.createElement('div');" +
"marker.innerHTML = '%s';" +
"marker.style.cssText = 'position:fixed; left:%dpx; top:%dpx; " +
"width:20px; height:20px; background:red; color:white; " +
"border-radius:50%%; z-index:999999; text-align:center;';" +
"document.body.appendChild(marker);" +
"setTimeout(function() { marker.remove(); }, 10000);", // 10秒后消失
label, x - 10, y - 10
);
((JavascriptExecutor) driver).executeScript(script);
}
效果如下(标记准确覆盖在目标位置上):

3.3 难点三:滑动验证码藏在 iframe 里
问题现象
滑动拼图验证码死活找不到元素,findElement 一直报 NoSuchElementException。
根因分析
验证码把滑动组件放在了一个 iframe 里面!
<div id="tcaptcha_transform_dy">
<iframe id="tcaptcha_iframe_dy" src="...">
<!-- 滑动组件在这里面 -->
<div class="tc-drag-thumb"></div>
</iframe>
</div>
Selenium 默认只能操作主文档的元素,要操作 iframe 内的元素必须先切换上下文。
解决方案
public boolean handleDragSliderCaptcha(WebElement captchaPopup) {
try {
// 1. 切换到 iframe
WebElement iframe = driver.findElement(By.cssSelector("#tcaptcha_iframe_dy"));
driver.switchTo().frame(iframe);
log.info("✓ 已切换到验证码 iframe");
// 2. 在 iframe 内查找滑块
WebElement slider = wait.until(ExpectedConditions.elementToBeClickable(
By.cssSelector(".tc-drag-thumb, .tc-slider-normal")
));
// 3. 执行拖动
int distance = calculateSlideDistance(); // LLM 识别缺口位置
Actions actions = new Actions(driver);
actions.clickAndHold(slider)
.moveByOffset(distance, 0)
.release()
.perform();
return true;
} finally {
// 4. 一定要切回主文档!
driver.switchTo().defaultContent();
log.info("✓ 已切回主文档");
}
}
踩坑提醒:如果忘记 switchTo().defaultContent(),后续所有操作都会失败!
3.4 难点四:登录状态的持久化
问题描述
每次启动 RPA 都需要重新登录,触发短信验证码。频繁登录不仅麻烦,还可能被该信息查询系统标记为异常行为。
解决方案:持久化用户数据目录
private void initializeBrowser(Boolean forceHeadless) {
ChromeOptions options = new ChromeOptions();
// 关键配置:使用持久化的用户数据目录
String userDataDir = System.getProperty("user.home") + "/.data-rpa/chrome-profile";
options.addArguments("--user-data-dir=" + userDataDir);
options.addArguments("--profile-directory=Default");
// 其他配置
options.addArguments("--disable-blink-features=AutomationControlled");
options.addArguments("--no-sandbox");
options.setExperimentalOption("excludeSwitches", Arrays.asList("enable-automation"));
driver = new ChromeDriver(options);
}
原理:Chrome 的用户数据目录保存了 Cookie、LocalStorage、登录状态等信息。指定固定目录后,下次启动浏览器会自动恢复之前的登录状态。
登录状态检测优化
原本的检测逻辑用了多个 findElement,每个都可能触发超时等待,导致检测耗时 30 秒。
优化后改用 JavaScript 直接检查:
private boolean isLoggedInOnQueryPage() {
JavascriptExecutor js = (JavascriptExecutor) driver;
// 1. 快速检查脱敏手机号(已登录特征)
String phoneCheck = (String) js.executeScript(
"var body = document.body.innerText;" +
"var match = body.match(/\\d{3}\\*{2,5}\\d{4}/);" +
"return match ? match[0] : null;"
);
if (phoneCheck != null) {
log.info("✓ 已登录(手机号: {})", phoneCheck);
return true;
}
// 2. 检查未登录提示
Boolean hasLoginHint = (Boolean) js.executeScript(
"return document.body.innerText.includes('请登录');"
);
return !Boolean.TRUE.equals(hasLoginHint);
}
优化效果:30 秒 → 1 秒以内
3.5 难点五:API 数据拦截
问题描述
验证码通过后,页面会调用后端 API 获取查询结果。但如果我们等页面渲染完再解析 DOM,容易遗漏字段或解析错误。
最佳方案是直接拦截 API 响应,获取结构化的 JSON 数据。
解决方案:注入 XHR/Fetch 拦截器
private void injectApiInterceptor() {
String script = """
window.__capturedApiResponse = null;
// 拦截 fetch
const originalFetch = window.fetch;
window.fetch = async function(...args) {
const response = await originalFetch.apply(this, args);
const url = args[0];
if (url.includes('queryDataInfo')) {
const clone = response.clone();
clone.json().then(data => {
window.__capturedApiResponse = data;
console.log('✓ 已捕获 queryDataInfo 响应');
});
}
return response;
};
// 拦截 XMLHttpRequest
const originalOpen = XMLHttpRequest.prototype.open;
XMLHttpRequest.prototype.open = function(method, url) {
this._url = url;
return originalOpen.apply(this, arguments);
};
const originalSend = XMLHttpRequest.prototype.send;
XMLHttpRequest.prototype.send = function() {
this.addEventListener('load', function() {
if (this._url && this._url.includes('queryDataInfo')) {
try {
window.__capturedApiResponse = JSON.parse(this.responseText);
} catch (e) {}
}
});
return originalSend.apply(this, arguments);
};
""";
((JavascriptExecutor) driver).executeScript(script);
}
关键点:拦截器必须在点击查询按钮之前注入,否则 API 调用发生时拦截器还没生效。
获取拦截到的数据:
private Map<String, Object> waitForApiResponse() {
for (int i = 0; i < 30; i++) { // 最多等待 30 秒
Object result = ((JavascriptExecutor) driver).executeScript(
"return window.__capturedApiResponse;"
);
if (result != null) {
return (Map<String, Object>) result;
}
Thread.sleep(1000);
}
return null;
}
四、项目成果与数据
4.1 性能对比
| 指标 | 手工操作 | RPA 自动化 | 提升 |
|---|---|---|---|
| 单次查询耗时 | 2-3 分钟 | 15-30 秒 | 5-10x |
| 100 条信息 | 4-5 小时 | 30-50 分钟 | 6-8x |
| 验证码识别率 | 100%(人工) | 85%+ | - |
| 数据准确率 | 95%(手误) | 100% | - |
4.2 验证码识别率统计
| 验证码类型 | 识别率 | 说明 |
|---|---|---|
| 依次点击(数字+图形) | 80% | 图形描述有时不准 |
| 字母朝向 | 90% | 相对简单 |
| 滑动拼图 | 85% | 缺口位置识别 |
| 点击数字 | 95% | 最简单 |
未识别成功时:系统会等待 120 秒,允许人工介入处理。
五、经验总结与启发
5.1 LLM 视觉应用的 Prompt 工程
验证码识别的准确率很大程度取决于 Prompt 设计:
❌ 错误示范:
"识别这张验证码图片"
✅ 正确示范:
"请仔细观察这张验证码图片,提取验证码的提示文字。
如果提示中包含图形(如建筑、动物、植物等),请用方括号描述,
例如:请依次点击:7 [建筑] 4
只返回提示文字本身,不要任何解释或其他内容。"
5.2 Selenium 操作的可靠性原则
- 多策略点击:JavaScript click → Actions click → 原生 click,按优先级尝试
- 显式等待:
WebDriverWait替代Thread.sleep - 元素可见性:操作前检查
isDisplayed()和isEnabled() - 异常兜底:核心操作加 try-catch,记录日志便于排查
5.3 坐标转换的通用公式
视口坐标 = 元素位置 + (图片坐标 / DPR) × (元素尺寸 / CSS图片尺寸)
记住这个公式,可以应对绝大多数坐标转换场景。
5.4 人机协作是最佳实践
RPA 不是要完全取代人,而是人机协作:
- 机器处理重复性、规律性任务
- 人类处理异常情况、边界案例
- 系统提供明确的介入窗口(如 120 秒等待)
六、代码 API 示例
6.1 API 调用示例
curl -X POST http://localhost:8080/api/info/query \
-H "Content-Type: application/json" \
-d '{
"phoneNumber": "151****0973",
"date": "2025-11",
"dataList": ["查询条目01", "查询条目02", "查询条目03"],
"retryCaptchaOnFail": true,
"saveResultToFile": true
}'
6.2 响应示例
{
"success": true,
"message": "查询完成",
"results": [
{
"name": "查询条目01",
"detail": {
"item01":"666",
"item02":"888",
}
}
],
"csvFilePath": "~/.data-rpa/query-results/query_20260125.csv"
}
七、其他的一些点
-
Java与唤起浏览器的交互()
-
cursor中的Java代码的Debug 远程调试
-
与curosr的提示语交互,注意需求明确,提供图片以及询问其需要哪些其他的文字或者说明

-
【重点】Cursor中模型的选择
- 国内使用Claude和ChatGPT的模型,不但要科学上网,还要注意走 TUN模式,或者“全局模式”
- 国内使用Claude和ChatGPT的模型,不但要科学上网,还要注意走 TUN模式,或者“全局模式”
八、后续优化方向
- 验证码识别率提升:收集失败案例,fine-tune 专属模型
- 分布式部署:支持多浏览器实例并行查询
- 监控告警:识别率下降时自动告警
- 更多平台适配:其他信息查询平台的 RPA 支持
九、结语
这个项目最大的收获是:LLM 视觉能力在 RPA 场景有巨大潜力。
传统 RPA 依赖固定的选择器和坐标,一旦页面改版就可能失效。而 LLM 可以「理解」页面内容,像人一样去操作,天然具备更强的鲁棒性。
当然,LLM 也有局限性(延迟、成本、准确率波动),所以最佳实践是**「AI 主导 + 人工兜底」**的人机协作模式。
如果你也在做 RPA 项目,希望本文的经验能帮到你。有问题欢迎评论区交流!
关注我,获取更多 AI 实战干货 🚀
作者:打破砂锅问到底
日期:2026-01-25
标签:#RPA #Selenium #LLM #验证码识别 #通义千问 #Java #SpringBoot

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 8
8 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)