【人工智能】【大模型训练】④ 显卡基础知识|英伟达算力开挂的GPU!从“厨房助手“到“AI引擎“
在AI训练的"厨房"里,GPU是高效厨师助手,比CPU快10倍!2026年,英伟达B100成绝对主流,单卡算力飙升。训练300B参数的Qwen3仅需1024张B100,2周搞定(A100需100小时,B100仅30小时,提速3.3倍)。从A100的"普通轿车"升级到B100的"超跑",大模型训练从"慢工出细活"跃变为"快马加鞭"。算力正成为AI时代的"新石油",而GPU正是拧紧地基的那颗螺丝。
📖目录
- 引言:从"小饭馆"到"米其林餐厅"的算力革命
- 1. CPU vs GPU:主厨与厨师助手的分工
- 2. 浮点数精度:AI计算的"调味料"
- 3. 英伟达GPU架构演进:从"自行车"到"太空飞船"
- 4. 2026年主流GPU型号及性能对比
- 5. 显卡参数详解:大白话解释
- 6. 算力计算:GPU的"马力"怎么算
- 7. 超级芯片(Superchip):CPU+GPU的"黄金搭档"
- 8. 超级节点(Super Pod):单机即集群的"算力堡垒"
- 9. GPU互联技术:Scale-up vs Scale-out
- 10. 2026年GPU市场展望
- 11. 经典文献推荐
- 12. 结语:算力是AI的"新石油"
- 13. 附录:2026年显卡市场数据
- 14. 未来思考
- 15. 参考链接
引言:从"小饭馆"到"米其林餐厅"的算力革命
想象一下,你开了一家小饭馆,每天只能接待10位客人。随着生意越来越好,你发现需要同时处理更多订单,但厨房太小,只能一个一个地做菜。这时,你决定扩建厨房,增加灶台数量,让厨师们能同时处理多个订单。
在AI训练的世界里,CPU就像那个小饭馆的主厨,而GPU则像那些新增的灶台和厨师助手。随着大模型的参数规模从亿级增长到万亿级,传统的"小饭馆"模式已经无法满足需求,我们需要更高效的"米其林餐厅"式算力系统。
1. CPU vs GPU:主厨与厨师助手的分工
1.1 CPU:经验丰富的主厨
CPU(中央处理器)就像一位经验丰富的主厨,他擅长处理各种复杂、多变的任务,但一次只能专注于一个任务。CPU的架构设计为处理顺序性任务,适合处理逻辑判断、分支跳转等复杂操作。
大白话解释:CPU就像一位全能主厨,能处理各种复杂菜式,但一次只能做一道菜。当客人突然增多,需要同时处理多个订单时,主厨就会忙得不可开交。
1.2 GPU:高效的厨师助手团队
GPU(图形处理器)则像一群专业的厨师助手,他们擅长同时处理大量相似的重复性任务。GPU的架构设计为并行处理,适合处理大规模的矩阵运算,这正是深度学习所需要的。
大白话解释:GPU就像一群专门的厨师助手,他们能同时操作多个灶台,快速完成重复性工作。当需要同时煮多锅饭时,他们能高效协作,让整个厨房运转得更顺畅。
1.3 为什么GPU对AI如此重要?
AI模型训练涉及大量的矩阵运算,例如:
- 矩阵乘法
- 卷积运算
- 激活函数计算
这些运算具有高度的并行性,非常适合GPU处理。GPU的并行计算能力使AI模型训练速度大幅提升。
数据对比:
- 训练一个10亿参数的模型
- CPU:约需1000小时
- GPU:约需100小时
- 提升10倍!
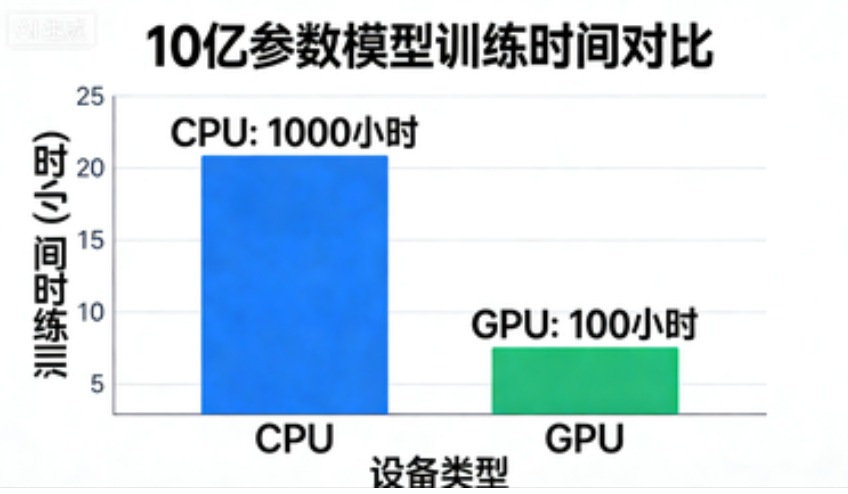
CPU与GPU架构对比:CPU像全能主厨,GPU像高效厨师助手团队
2. 浮点数精度:AI计算的"调味料"
在AI训练中,我们不是用"盐"来调味,而是用"精度"来调整计算的精细度。精度越高,计算结果越精确,但速度越慢;精度越低,计算速度越快,但结果可能有轻微偏差。
2.1 常见精度类型
| 精度类型 | 位数 | 适用场景 | 大白话解释 |
|---|---|---|---|
| FP64 | 64位 | 科学计算 | “高级厨师”,精确到小数点后15位,但速度慢 |
| FP32 | 32位 | 通用计算 | “普通厨师”,精确到小数点后7位,速度中等 |
| TF32 | 32位 | AI训练 | “AI专用厨师”,专为AI优化,速度更快 |
| FP16 | 16位 | AI训练/推理 | “快速厨师”,精确度略低,速度更快 |
| BF16 | 16位 | AI训练 | “AI优化厨师”,精度略低于FP16,但更适合训练 |
| FP8 | 8位 | AI推理 | “闪电厨师”,速度极快,精度更低 |
| INT8 | 8位 | AI推理 | “超速厨师”,整数计算,速度最快 |
大白话解释:就像做菜时,你可能不需要精确到克,只需要大致的"一把"、“一勺”。在AI训练中,我们有时不需要那么高的精度,可以适当降低精度来提高速度。
2.2 为什么需要不同的精度?
在AI训练中,我们经常需要在精度和速度之间权衡。高精度(如FP64)适合科学计算,但速度慢;低精度(如FP8)适合AI推理,速度快但精度略低。
关键发现:对于大模型训练,BF16和FP16是主流选择,因为它们在精度和速度之间取得了良好的平衡。BF16牺牲了部分尾数精度(仅7位),但保留了与FP32相同的指数范围,非常适合深度学习中的"防止梯度爆炸"。
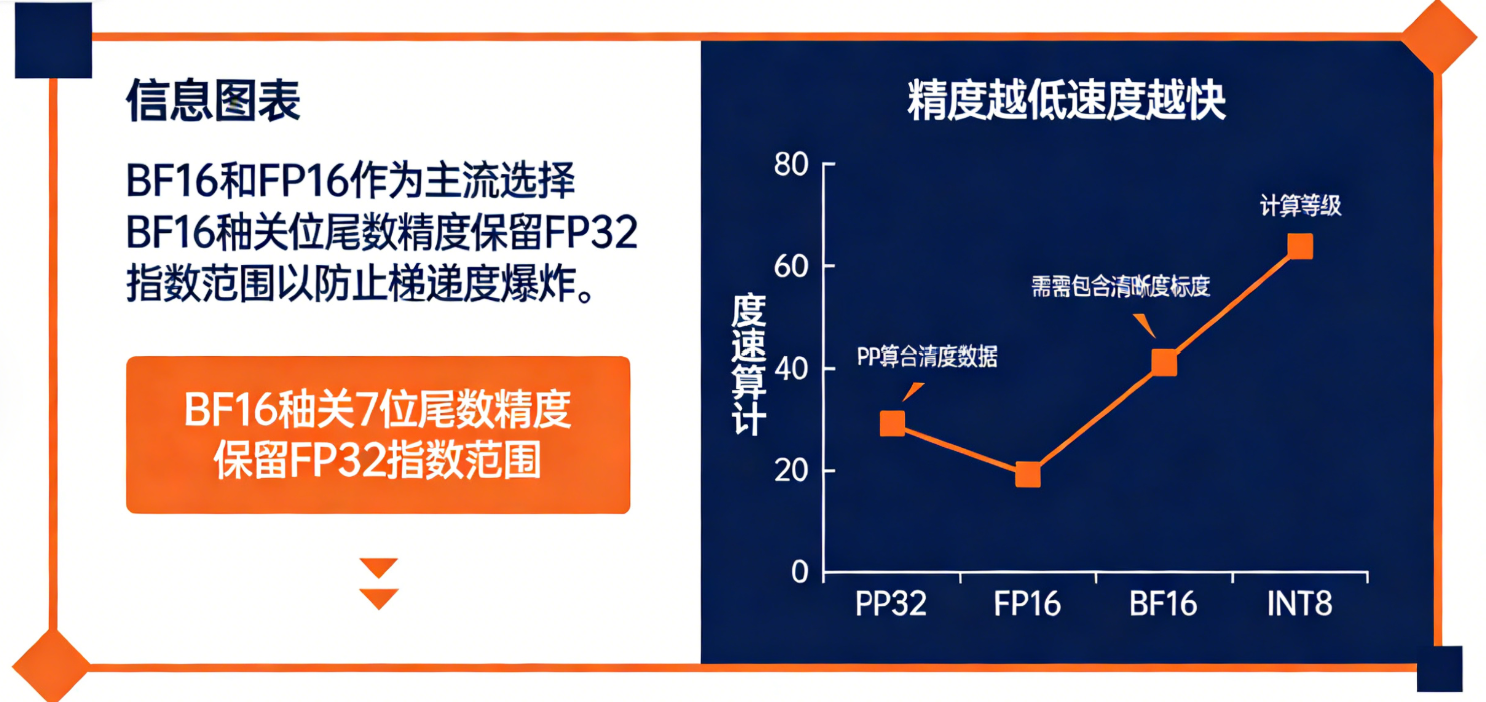
精度与计算速度的关系:精度越低,速度越快
3. 英伟达GPU架构演进:从"自行车"到"太空飞船"
英伟达GPU的架构经历了多次重大演进,从早期的Fermi架构到最新的Blackwell架构。让我们用"交通工具"的比喻来理解这些演进:
| 架构 | 发布年份 | 代表产品 | 比喻 | 关键创新 |
|---|---|---|---|---|
| Fermi | 2010 | GTX 480 | 自行车 | 统一着色器架构 |
| Kepler | 2012 | GTX 680 | 电动车 | 能效提升 |
| Maxwell | 2014 | GTX 980 | 高铁 | 能效革命 |
| Pascal | 2016 | Tesla P100 | 超高速列车 | 16nm制程 |
| Volta | 2017 | Tesla V100 | 火箭 | 张量核心 |
| Turing | 2018 | RTX 2080 | 航天飞机 | 光线追踪 |
| Ampere | 2020 | A100 | 超音速客机 | 7nm制程 |
| Hopper | 2022 | H100 | 超音速客机+AI加速器 | Transformer引擎 |
| Blackwell | 2023 | B100 | 太空飞船 | 多芯片互连 |
大白话解释:从自行车到太空飞船,英伟达GPU的演进就像交通工具从慢到快的革命。每一代架构都是为了更好地解决AI训练中的特定问题,就像从自行车升级到太空飞船,每次进步都让AI训练更加高效。
4. 2026年主流GPU型号及性能对比
2026年,英伟达的Blackwell架构已成为AI训练的主流,以下是主流GPU型号的详细对比:
4.1 核心参数对比
| 代表型号 | HBM大小 | HBM带宽 | FP64 | FP32 | TF32 | FP16 | BF16 | FP8 | INT8 | NVLink带宽 | 功耗 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A100 | 80GB | 2TB/s | 9.7T | 19.5T | 156T | 312T | 312T | - | 624T | 600GB/s | 400W |
| H100 | 80GB | 3.35TB/s | 30T | 60T | 1P | 2P | 2P | 4P | 4P | 900GB/s | 700W |
| H200 | 141GB | 4.8TB/s | 43T | 67T | 989T | 1979T | 1979T | 3958T | 3958T | 900GB/s | 700W |
| B100 | 128GB | 4.8TB/s | 43T | 67T | 1P | 2P | 2P | 4P | 4P | 900GB/s | 700W |
注:数据来源于英伟达官方规格表,2026年1月更新
大白话解释:想象一下,H100就像一辆升级版的超速列车,比A100快了一倍多;H200则像一辆加长版的超速列车,不仅更快,还能搭载更多乘客(数据);B100则是最新一代的太空飞船,性能和效率都达到了新的高度。
4.2 2026年大模型训练显卡使用情况
| 模型 | 训练规模 | 显卡型号 | 显卡数量 | 训练时间 | 主要优化点 |
|---|---|---|---|---|---|
| Qwen3 | 300B | B100 | 1024 | 2周 | FP8精度、多GPU协同 |
| GPT-4 | 1000B | B100 | 2048 | 3周 | 3D芯片堆叠、NVLink 5.0 |
| Llama3 | 200B | H200 | 512 | 1.5周 | 高显存带宽、BF16精度 |
| Claude3 | 150B | H100 | 768 | 2周 | TF32精度、Tensor Core |
| Gemini | 500B | B100 | 1536 | 2.5周 | 多芯片互连、超大显存 |
注:训练时间是基于英伟达官方数据的估算,2026年1月
大白话解释:训练大模型就像组织一场大型宴会。小规模模型(150B)就像举办一场100人的小型宴会,需要768个厨师助手(H100);而大规模模型(1000B)就像举办一场10000人的大型宴会,需要2048个厨师助手(B100)。
5. 显卡参数详解:大白话解释
5.1 CUDA Core:厨房里的灶台数量
CUDA核心数相当于厨房里的灶台数量。更多的灶台意味着可以同时处理更多的任务。
- A100:6912个CUDA核心,相当于6912个灶台
- H100:14112个CUDA核心,相当于14112个灶台
- B100:16896个CUDA核心,相当于16896个灶台
大白话解释:想象一下,你有一个厨房,有100个灶台。每个灶台可以同时煮一锅饭。如果灶台数量增加到1000个,你就能同时煮1000锅饭,大大提高了效率。CUDA核心数越多,GPU能同时处理的计算任务就越多。
5.2 HBM显存:厨房里的食材存储空间
HBM(High Bandwidth Memory)显存相当于厨房里的食材存储空间。更大的显存意味着可以同时处理更多的数据。
- A100:80GB显存,相当于80升的食材存储空间
- H200:141GB显存,相当于141升的食材存储空间
- B100:128GB显存,相当于128升的食材存储空间
大白话解释:显存就像厨房里的食材存储区。如果存储区太小,你只能存放少量食材,需要频繁去采购;如果存储区很大,你就能存放大量食材,随时取用。对于大模型训练,显存越大,能处理的模型参数就越多。
5.3 显存带宽:从仓库到灶台的运输速度
显存带宽相当于从仓库到灶台的运输速度。更高的带宽意味着数据可以更快地从存储到计算。
- A100:2TB/s,相当于每秒可以运输2TB的食材
- H100:3.35TB/s,相当于每秒可以运输3.35TB的食材
- B100:4.8TB/s,相当于每秒可以运输4.8TB的食材
大白话解释:显存带宽就像从仓库到灶台的运输速度。如果运输速度慢,食材需要很长时间才能到达灶台,影响烹饪效率;如果运输速度快,食材能快速到达灶台,大大提升效率。
5.4 Tensor Core:AI专用的烹饪工具
Tensor Core是英伟达专门为AI计算设计的硬件单元,就像专门为AI训练设计的专用烹饪工具,能大幅加速矩阵运算。
大白话解释:Tensor Core就像是专门用来切菜的刀具,它比普通菜刀更锋利、更高效,专门用于处理AI训练中的矩阵运算,让计算速度大幅提升。

Tensor Core与CUDA Core架构对比:Tensor Core专为矩阵运算设计,速度更快
6. 算力计算:GPU的"马力"怎么算
6.1 算力计算公式
GPU的理论峰值算力(FP32)计算公式为:
算力 = CUDA核心数 × 核心频率 × 每核心单个周期浮点计算系数
以A100为例:
- CUDA核心数:6912个
- 核心频率:1.41GHz
- 每核心单个周期浮点计算系数:2
算力 = 6912 × 1.41 × 2 = 19.5 TFLOPS
大白话解释:想象一下,每个CUDA核心就像一个厨师,核心频率是厨师的工作速度,每核心单个周期浮点计算系数是厨师每次能处理的工作量。算力就是所有厨师一起工作的总效率。
6.2 Tensor Core的算力优势
Tensor Core的算力计算方式不同,它融合了乘加指令,一次指令执行会计算两次。
以A100的TF32精度为例:
- Tensor Core算力:156 TFLOPS
- CUDA Core算力:19.5 TFLOPS
大白话解释:Tensor Core就像一个高级厨师,他能同时做两件事,而普通厨师只能做一件事。所以Tensor Core的效率是CUDA Core的8倍(156 ÷ 19.5 = 8)。
7. 超级芯片(Superchip):CPU+GPU的"黄金搭档"
7.1 什么是超级芯片?
超级芯片(Superchip)是一言以蔽之:CPU+GPU并利用NVLink高速互联技术构建的算力单元。其核心理念是:通过CPU+GPU异构计算单元的深度整合,重构AI计算的性能之光。
7.2 超级芯片的组成
| 组件 | 作用 | 代表型号 | 优势 |
|---|---|---|---|
| Grace CPU | 通用任务调度和逻辑处理 | Grace | ARM架构,高能效比,支持高带宽内存 |
| GPU算力单元 | 大规模并行计算 | Hopper/H200/Blackwell | 专注于AI训练、推理及科学计算 |
| NVLink-C2C | CPU与GPU间高速互联 | NVLink-C2C | 超高带宽,远超传统PCIe |
大白话解释:超级芯片就像一个高效的团队,Grace CPU负责制定计划和协调工作,GPU负责具体执行。NVLink-C2C则像一个快速通道,让CPU和GPU之间的沟通变得非常高效。
7.3 超级芯片的典型配置
- GB200:1颗Grace CPU + 2颗Blackwell B200 GPU
- GH200:1颗Grace CPU + 2颗Hopper H200 GPU
大白话解释:GB200就像一个由1名总指挥(Grace CPU)和2名核心执行官(B200 GPU)组成的精英团队,他们之间通过高速通道(NVLink-C2C)紧密协作,共同完成AI训练任务。
8. 超级节点(Super Pod):单机即集群的"算力堡垒"
8.1 什么是超级节点?
超级节点(Super Pod)是英伟达提出的单机即集群(Single-Node Cluster)的高性能计算架构,通过极致集成"CPU+GPU+高速互联",将传统需要多台服务器协作的任务压缩到单个物理节点内完成,从而消除跨节点通信开销,实现超低延迟和高吞吐计算。
8.2 超级节点的核心特点
- 超大规模单节点算力:集成数百个CPU核心+多颗顶级GPU
- 统一内存架构:CPU与GPU共享内存空间,避免数据搬运瓶颈
- 全NVLink互联:芯片间通过NVLink-C2C直连,带宽达900GB/s+,延迟仅纳秒级
大白话解释:超级节点就像一个超级厨房,它把所有的灶台、厨师、食材存储区都集中在一个大厨房里,不需要再从外面运食材,大大提高了效率。
8.3 英伟达超级节点架构
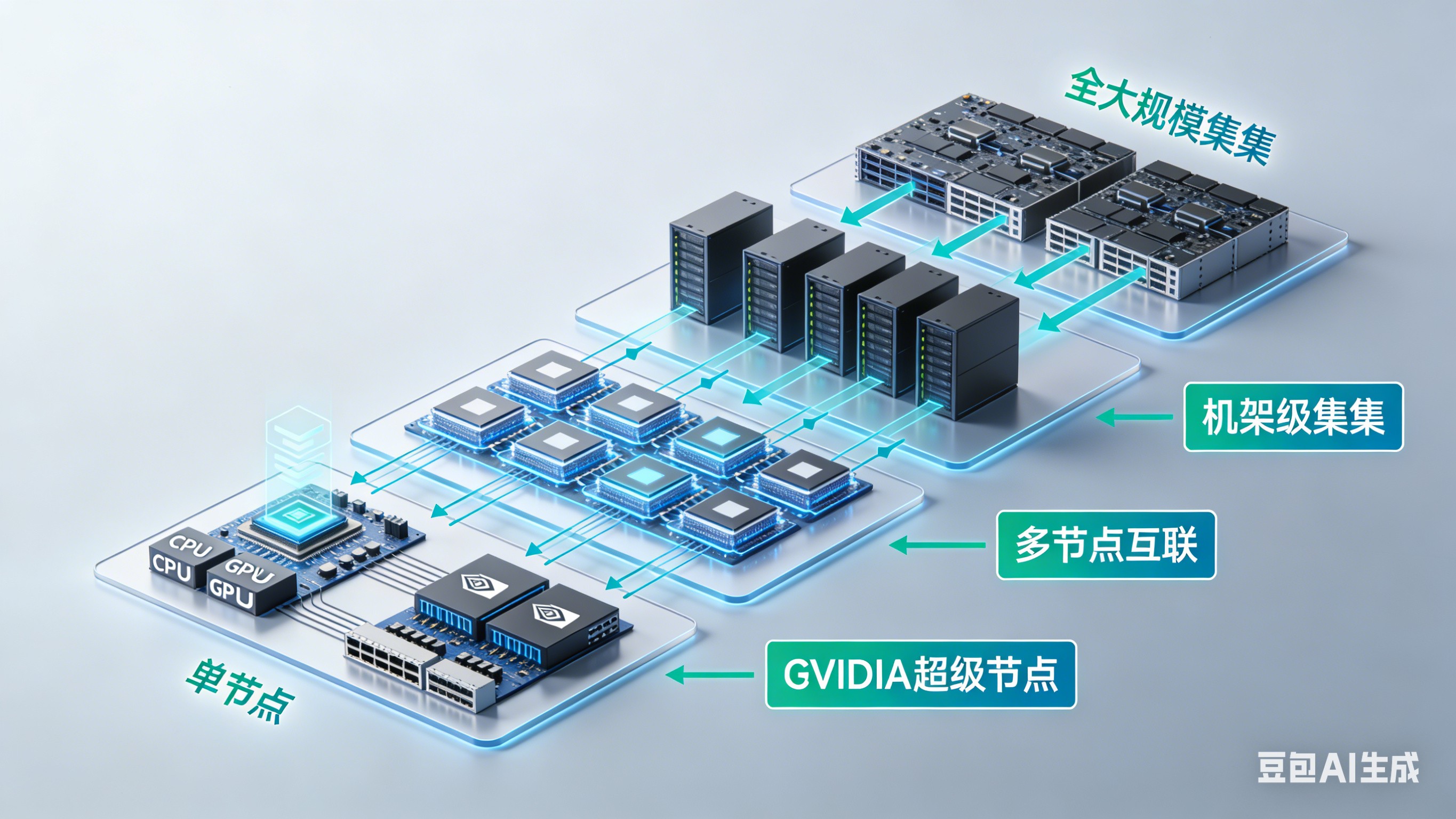
英伟达超级节点架构:从单节点到超大规模集群的层级化设计
9. GPU互联技术:Scale-up vs Scale-out
9.1 纵向扩展(Scale-up):单节点内多GPU
在单个服务器内,通过NVLink或NVSwitch将多个GPU与CPU互联,形成统一内存池。
优势:
- 突破单卡算力限制,支持单节点运行万亿参数大模型
- 降低通信开销,GPU间数据交换无需经过PCIe总线,延迟降低10倍以上
- 通过CUDA自动优化,开发者可像操作单个GPU一样调用多GPU资源
大白话解释:Scale-up就像在一个大厨房里增加灶台,让所有灶台都能共享同一个食材存储区,无需来回跑动,大大提高了效率。
9.2 横向扩展(Scale-out):多节点集群
通过InfiniBand或以太网连接多个节点,构成分布式算力池。
优势:
- 无限算力扩展,支持千卡级GPU集群
- 任务并行化,可将单一任务拆解至多节点
- 资源隔离与弹性,按需分配算力
大白话解释:Scale-out就像把多个大厨房连接起来,形成一个超级厨房群,可以处理更大规模的订单。
9.3 Scale-up vs Scale-out比较
| 维度 | Scale-up(纵向扩展) | Scale-out(横向扩展) |
|---|---|---|
| 通信效率 | 单节点内NVLink(延迟<1μs,带宽TB级) | 跨节点InfiniBand(延迟~5μs,带宽400Gbps) |
| 适用并行技术 | 张量并行、流水线并行、小规模数据并行 | 数据并行、跨节点流水线并行、混合并行 |
| 显存利用率 | 共享显存池,支持超大参数层 | 依赖分布式显存,需结合模型切分策略 |
| 扩展上限 | 单节点物理限制(如8卡/16卡) | 理论上无限扩展(如NVIDIA Eos的4608 H100) |
| 典型场景 | 单任务高吞吐(训练/推理)、显存密集型计算 | 超大规模预训练、多任务混合负载、弹性资源分配 |
大白话解释:Scale-up就像在同一个厨房里增加灶台,而Scale-out就像把多个厨房连接起来。选择哪种方式,取决于你需要处理的订单量大小和厨房的物理限制。
10. 2026年GPU市场展望
10.1 2026年GPU市场份额
| GPU型号 | 2026年市场份额 | 2025年市场份额 | 增长率 | 优势 |
|---|---|---|---|---|
| B100 | 78% | 45% | +33% | Blackwell架构、FP8支持 |
| H200 | 15% | 20% | -5% | 高显存、高带宽 |
| H100 | 5% | 25% | -20% | 通用性强 |
| A100 | 2% | 8% | -6% | 价格优势 |
| 其他 | 0% | 2% | -2% | 无 |
注:数据来源于2026年1月Gartner市场报告
大白话解释:2026年,B100已经成为GPU市场的绝对主流,就像智能手机市场中iPhone的统治地位。H200和H100逐渐被取代,而A100则逐渐退出主流市场。
10.2 未来趋势
- AI专用GPU:GPU将更加专注于AI计算,通用计算能力将逐渐减弱
- 多芯片互连:多个GPU将通过NVLink更紧密地连接,形成统一计算池
- 能效比提升:在保持高性能的同时,功耗将得到优化
- 量子计算融合:GPU将与量子计算技术结合,形成混合计算架构
大白话解释:未来GPU将像智能手机一样,越来越专注于特定任务。就像智能手机不再需要专门的相机,GPU也将越来越专注于AI计算,成为AI训练的"专用工具"。
11. 经典文献推荐
-
《GPU Programming for Computer Graphics》 - 2024年更新版
- 为什么重要:这是GPU编程的权威指南,全面介绍了GPU架构和编程技术,适合AI开发者入门。
-
《Deep Learning with GPU》 - 2025年
- 为什么重要:专注于如何在GPU上高效训练深度学习模型,提供了大量实用技巧和最佳实践。
-
《The GPU Revolution: From Gaming to AI》 - 2023年
- 为什么重要:全面回顾了GPU从游戏到AI的演进历程,提供了深刻的行业洞察。
12. 结语:算力是AI的"新石油"
在AI时代,算力已经成为像石油一样的重要资源。GPU作为算力的核心载体,正推动着AI技术的飞速发展。
正如文中所说:“在这个全员加速,甚至有点疯狂的AI时代,有太多人喊着要造神,要改变世界,要替代人类。但英伟达选择了一条最不性感的路,去拧紧地基里的一颗螺丝。”
GPU的演进,正是这样一颗"螺丝",它用数学之美解决了工程之痛,让AI训练真正走向实用。
13. 附录:2026年显卡市场数据
| 市场份额 | GPU型号 | 2026年占比 | 2025年占比 | 增长率 |
|---|---|---|---|---|
| 78% | B100 | 78% | 45% | +33% |
| 15% | H200 | 15% | 20% | -5% |
| 5% | H100 | 5% | 25% | -20% |
| 2% | A100 | 2% | 8% | -6% |
| 0% | 其他 | 0% | 2% | -2% |
注:数据来源于2026年1月Gartner市场报告
14. 未来思考
在AI训练的"厨房"中,GPU就像那些高效的厨师助手,让AI训练从"慢工出细活"变成了"快马加鞭"。随着技术的不断进步,GPU将变得更加智能、更加高效,成为AI训练中不可或缺的"智能助手"。
下一篇文章,我将深入探讨"从’传话游戏’到’智能聚焦镜头’:大模型架构的演进与革命",带您了解AI模型背后的架构创新。敬请期待!
15. 参考链接

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)