【大模型基础架构与技术】GQA:Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
本文提出分组查询注意力(GQA)方法,通过将查询头分组并共享键值头,在多头注意力(MHA)和多查询注意力(MQA)之间实现平衡。实验表明,仅需原始预训练5%的计算量,即可将MHA模型转换为GQA模型。GQA在保持接近MHA质量的同时,推理速度接近MQA。消融实验验证了平均池化转换方法最优,且5%的上行训练即可获得显著提升。GQA-8分组在较大模型中实现了理想的性能-速度权衡,为提升大语言模型推理效
论文链接
GQA:从多头检查点训练通用多查询Transformer模型

EMNLP 2023
摘要
多头查询注意力(MQA)仅使用单一的键值头,从而极大加快了解码器的推理速度。然而,MQA可能导致质量下降,且仅为提升推理速度而单独训练一个模型可能并不理想。我们(1)提出一种方案,能以原始预训练计算量的5%将现有的多头语言模型检查点上训练为具有MQA的模型;以及(2)引入分组查询注意力(GQA),这是多头查询注意力的一种泛化形式,它使用一种中间数量(多于一个但少于查询头数量)的键值头。我们证明,经上训练的GQA在达到接近多头注意力质量的同时,获得了与MQA相当的推理速度。
1.引言
自回归解码器推理是Transformer模型的一个严重瓶颈,这源于每个解码步骤中加载解码器权重及所有注意力键与值所导致的内存带宽开销(Shazeer, 2019; Pope等人, 2022; de Jong等人, 2022)。通过采用多查询注意力机制(Shazeer, 2019)——即使用多个查询头但仅使用单个键头和值头——可以显著降低加载键与值所需的内存带宽。
然而,多查询注意力(MQA)可能导致质量下降和训练不稳定,且训练分别针对质量和推理进行优化的独立模型可能并不可行。此外,尽管已有部分语言模型使用多查询注意力,如PaLM(Chowdhery等人,2022),但包括T5(Raffel等人,2020)和LLaMA(Touvron等人,2023)在内的许多公开可用的语言模型并未采用该机制。
本工作为提升大语言模型的推理速度提供了两项贡献。其一,我们研究表明,语言模型的多头注意力(MHA)检查点可以通过少量原始训练算力进行上行训练(Komatsuzaki等人,2022),以转换为多查询注意力(MQA)。这为获取快速的多查询注意力模型以及高质量的多头注意力检查点提供了一种经济高效的方法。
其次,我们提出了分组查询注意力(GQA),这是一种介于多头注意力与多查询注意力之间的插值方法,它为每个查询头子组分配单一的关键头和值头。我们的研究表明,经增量训练后的GQA能达到接近多头注意力的质量,同时速度几乎与多查询注意力一样快。
2.相关工作
2.1 向上训练
将多头模型转换为多查询模型需经过两个步骤:首先转换模型检查点,其次通过额外的预训练使模型适应新结构。图1展示了将多头检查点转换为多查询检查点的具体流程:关键步骤是对键(key)和值(value)注意力头的投影矩阵进行平均池化,将其合并为单一投影矩阵。实验表明,该方法比选择单个键值头或随机初始化全新键值头具有更优效果。
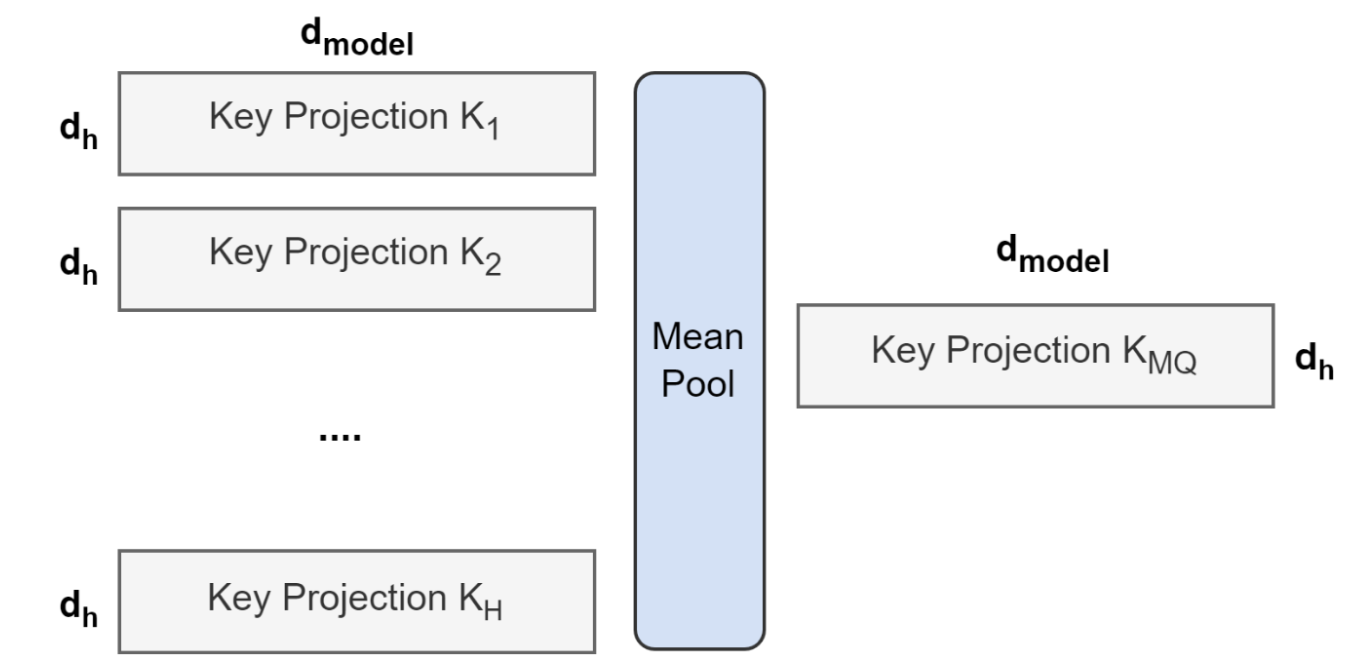
图1:多头注意力到多查询注意力的转换概述。所有注意力头的键与值投影矩阵经平均池化后合并至单一注意力头。
转换后的检查点随即进入预训练阶段。在原预训练方案基础上,仅以原始训练步数的α比例进行微调。
2.2 分组查询注意力
分组查询注意力将查询头划分为G组,每组共享一个键头和值头。GQA-G指具有G组的分组查询。GQA-1仅包含单一组,因此仅有一个键头和值头,等效于MQA;而GQA-H的组数等于头数,则等效于MHA。图2展示了分组查询注意力与多头/多查询注意力的对比。当将多头检查点转换为GQA检查点时,我们通过对每组内所有原始头进行均值池化来构建每个组的键头和值头。
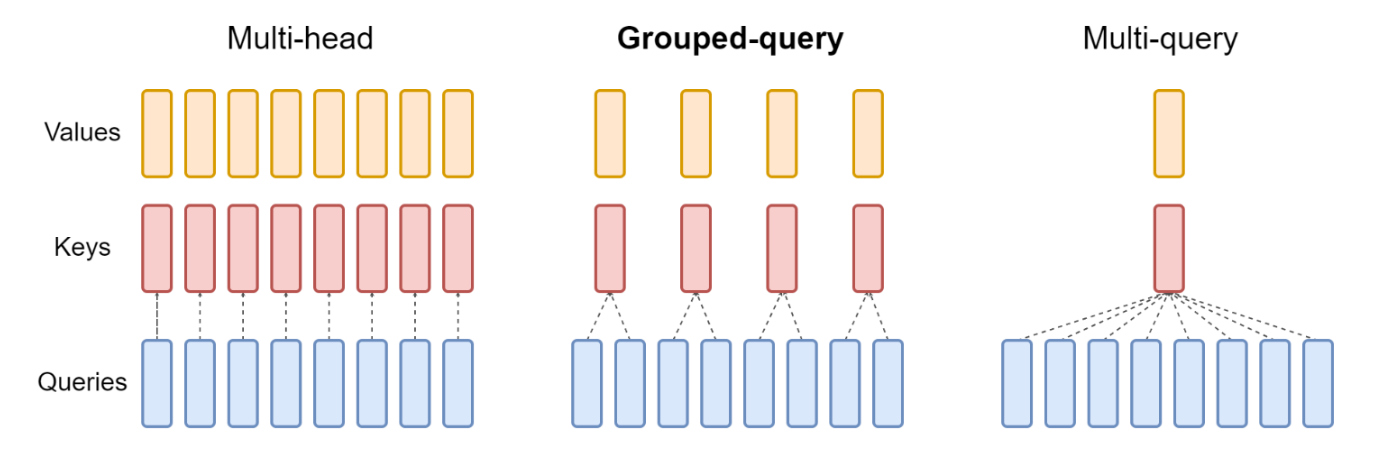
图2:分组查询方法概览。多头注意力机制具有H个独立的查询、键和值头。多查询注意力机制则是在所有查询头之间共享单一的键和值头。分组查询注意力机制折衷于此二者之间,它为每组查询头共享单一的键和值头,实现了多头与多查询注意力之间的插值。
中等数量的分组会产生一种插值模型,其质量高于MQA而速度优于MHA,并且正如我们将展示的,代表了一种有利的权衡。从MHA转向MQA时,H个键值与值头被缩减为单个键头和值头,使得键值缓存大小——即需要加载的数据量——减少了H倍。然而,较大模型通常会同步增加头数,因此多查询注意力在内存带宽和容量上的削减更为激进。GQA允许我们在模型规模扩大时,保持带宽与容量按相同比例下降。
此外,较大模型受注意力机制内存带宽开销的影响相对较小,因为KV缓存随模型维度线性增长,而模型浮点运算量和参数数量随模型维度的平方增长。最后,大型模型的标准分片策略会在各模型分区中复制单个键值头(Pope等人,2022);GQA则消除了此类分区造成的冗余。因此,我们预期GQA能在较大模型上实现特别优越的效能平衡。
3.实验
3.1 实验设置
配置
所有模型均基于T5.1.1架构(Raffel等人,2020),采用JAX(Bradbury等人,2018)、Flax(Heek等人,2020)及Flaxformer1实现。在我们的主要实验中,我们考虑了采用多头注意力的T5 Large与XXL模型,以及采用多查询注意力与分组查询注意力进行升级训练的T5 XXL版本。我们使用Adafactor优化器,其超参数与学习率调度策略与T5(Raffel等人,2020)保持一致。我们将MQA与GQA应用于解码器的自注意力与交叉注意力机制,但未应用于编码器的自注意力。
上训练模型以公开的T5.1.1检查点为初始化起点。通过均值池化将键值头调整为相应的MQA或GQA结构,随后沿用(Raffel et al., 2020)的原始预训练设置与数据集,以原始预训练步数的α比例进行额外预训练。当α = 0.05时,训练耗时约600 TPUv3芯片日。
我们在以下摘要数据集上开展评估:CNN/Daily Mail(Nallapati 等人,2016)、arXiv 与 PubMed(Cohan 等人,2018)、MediaSum(Zhu 等人,2021)以及 Multi-News(Fabbri 等人,2019);翻译数据集:WMT 2014 英译德;以及问答数据集TriviaQA(Joshi等人,2017)。我们未在流行的分类基准测试(如GLUE(Wang等人,2019))上进行评估,因为自回归推理对此类任务的适用性较低。
在微调阶段,所有任务均采用恒定学习率0.001、批大小128和0.1的丢弃率。CNN/Daily Mail与WMT任务使用输入长度512和输出长度256。其他摘要数据集使用输入长度2048和输出长度512。TriviaQA则使用输入长度2048和输出长度32。我们训练至模型收敛,并选择开发集性能最佳的检查点。推理阶段采用贪婪解码策略。
计时
我们以xprof(Google, 2020)测得的每TPUv4芯片每样本时间为报告依据。在计时实验中,我们使用8个TPU,采用各TPU最高可容纳(至多32个)的最大批次大小,并针对每个模型单独优化并行化配置。
3.2 主要结果
图3展示了所有数据集上的平均性能,该性能是平均推理时间的函数,涉及MHA T5-Large和T5-XXL模型,以及上行训练比例为α = 0.05的、经过上行训练的MQA和GQA-8 XXL模型。我们看到,一个更大的、经过上行训练的MQA模型相对于MHA模型提供了更有利的权衡,其质量更高且推理速度比MHA-Large更快。此外,GQA取得了显著的质量提升,其性能接近MHA-XXL,而速度接近MQA。表1包含了所有数据集的完整结果。
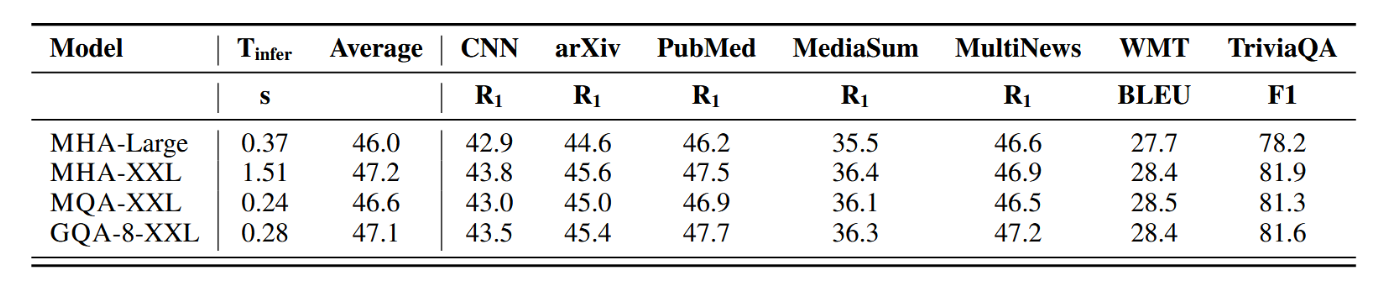
表1:T5 Large与XXL多注意力头部模型,以及经过5%增量训练、采用多查询和分组查询注意力的T5-XXL模型,在摘要数据集(CNN/Daily Mail、arXiv、PubMed、MediaSum、MultiNews)、翻译数据集(WMT)和问答数据集(TriviaQA)上的推理时间与平均开发集性能对比。
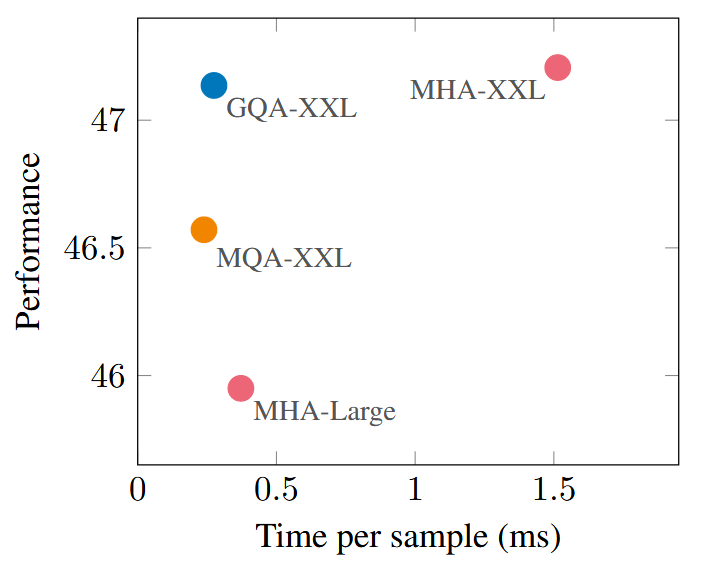
图3:经提升训练的多查询注意力(MQA)与多头注意力(MHA)相比实现了更优的权衡,其质量高于MHA-Large且速度更快;而分组查询注意力(GQA)取得了更佳性能,在获得相似速度提升的同时,其质量与MHA-XXL相当。该图展示了T5-Large与T5-XXL使用多头注意力、以及经5%提升训练的T5-XXL分别使用MQA和GQA-8注意力时,在所有任务上的平均性能随样本平均推理时间变化的函数关系。
3.3 消融实验
本节通过实验探究不同建模选择的影响。我们评估在代表性任务子集上的表现:CNN/Daily Mail(短文本摘要)、MultiNews(长文本摘要)以及TriviaQA(问答)。
检查点转换性能对比
图4比较了不同检查点转换方法的性能。平均池化方法表现最佳,其次是选择单头法,随机初始化法效果最弱。直观来看,性能排序与预训练模型信息保留程度呈正相关。
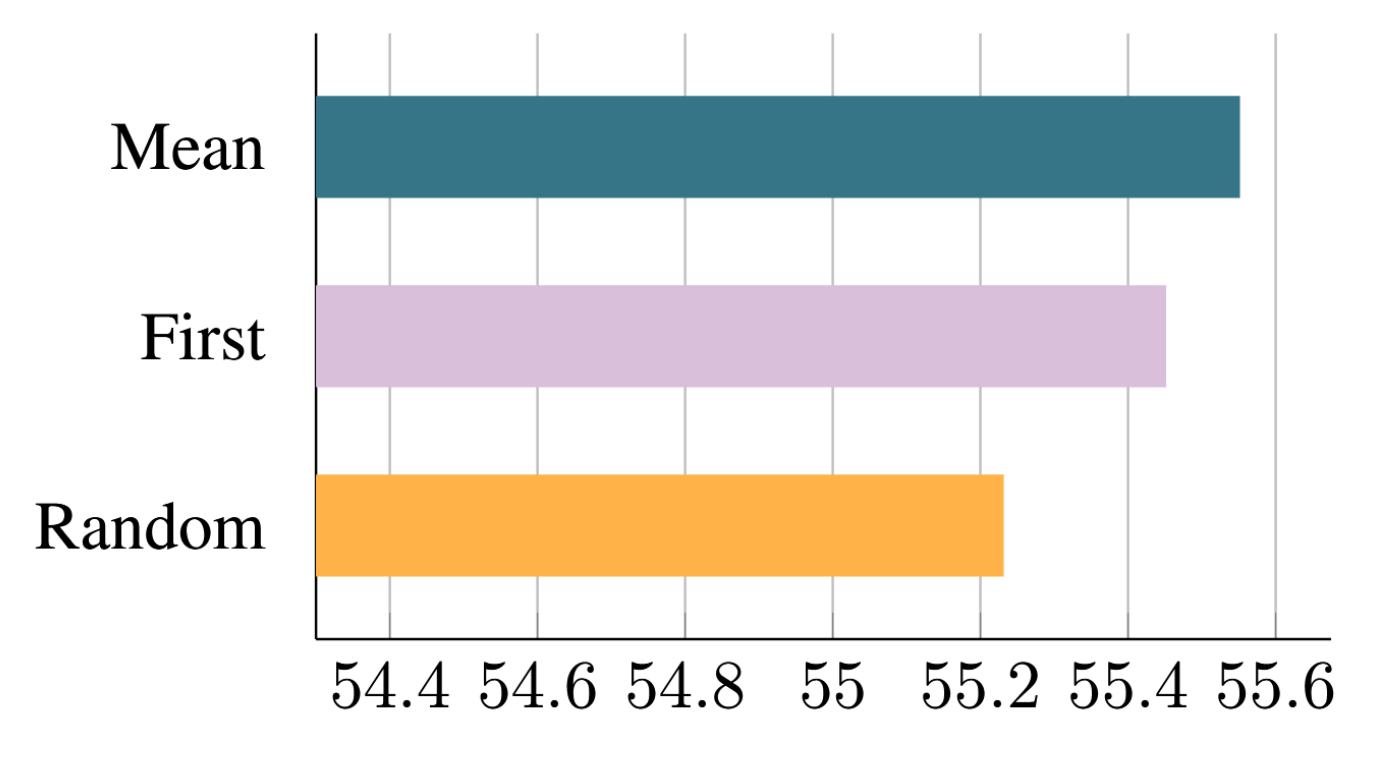
图4:采用不同检查点转换方法对T5-Large进行MQA增量训练(比例α=0.05)的性能对比。'Mean’表示对键和值头进行平均池化,'First’选取第一个头,'Random’则从头随机初始化。
上训练步骤图5展示了T5 XXL模型在采用MQA和GQA时,性能如何随上训练比例变化。首先,我们注意到GQA在转换后已能达到合理性能,而MQA则需要通过上训练来实现都有实用价值。MQA和GQA经5%增量训练即可获益,10%后收益呈边际递减。
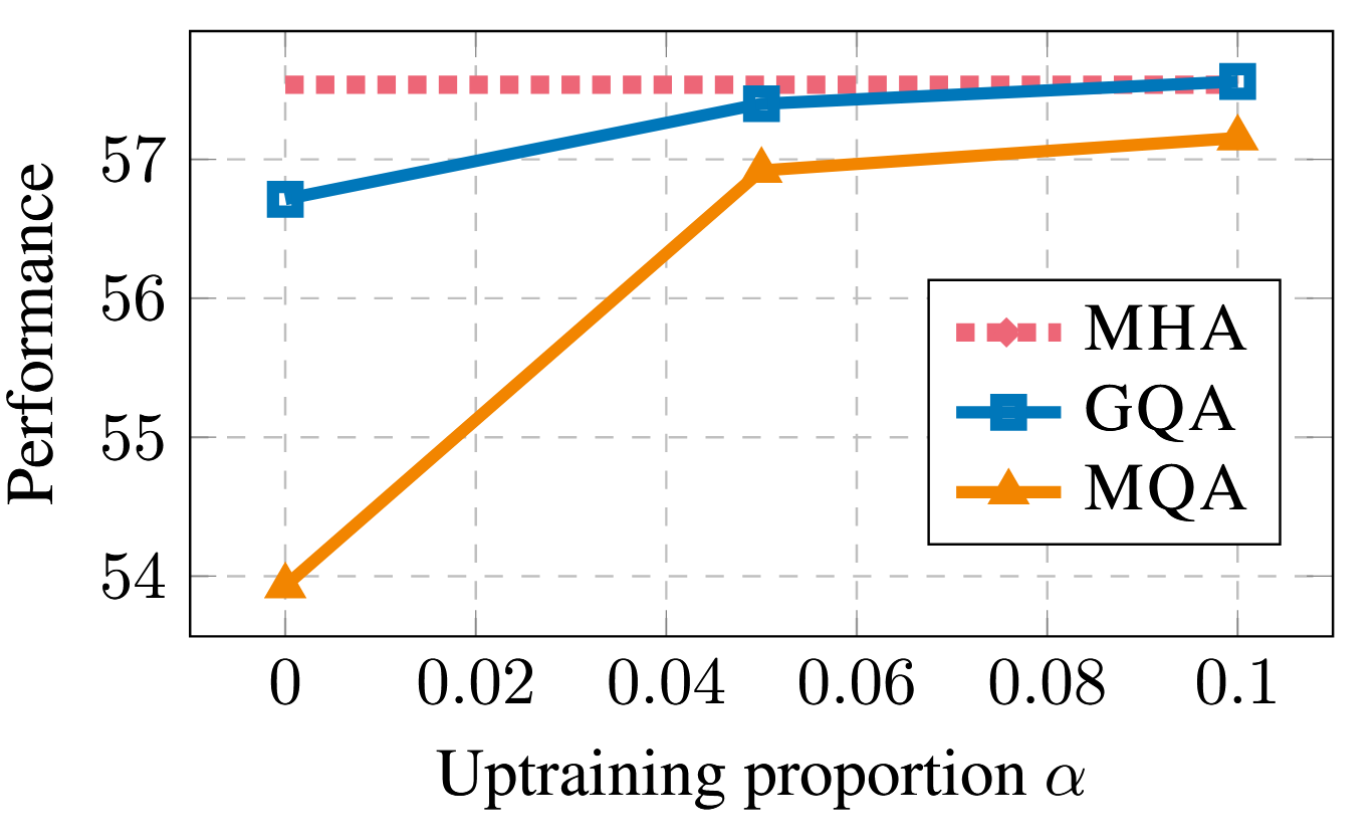
图5:采用MQA与GQA-8的T5 XXL模型性能随增量训练比例的变化关系。
分组数量
图6展示了GQA分组数量对推理速度的影响。对于较大模型而言,KV缓存的显存带宽开销限制较小(Shazeer, 2019),而由于注意力头数量的增加,键值大小的缩减更为显著。因此,从MQA开始增加分组数量时,初始仅导致轻微的速度下降,但随着分组趋近MHA,成本会逐步增加。我们选择8组作为理想的折中方案。
4 相关工作
本研究的核心目标是通过降低加载键值对的内存带宽开销(Williams et al., 2009),在解码器质量与推理时间之间实现更优的权衡。Shazeer(2019)率先提出了通过多头单查询注意力机制来降低此类开销。后续研究表明,多头单查询注意力在处理长输入时尤为有效(Pope et al., 2022; de Jong et al., 2022)。Rabe(2023)独立开发并公开了GQA的实现。其他研究为提升计算效率探索了注意力头的分组机制(Park et al., 2020; Luo et al., 2022; Ni et al., 2023),但并未专门关注决定内存带宽开销的键值头。
除上述方法外,学界还提出了多种其他技术以降低键值对及参数带来的内存带宽开销。Flash Attention(Dao 等人,2022)通过重构注意力计算流程,避免显式生成二次复杂度的注意力分数矩阵,从而减少内存占用并加速训练。量化技术(Dettmers 等人,2022;Frantar 等人,2022)通过降低权重和激活值(包括键值对)的数值精度来压缩模型体积。模型蒸馏(Hinton 等人,2015;Gou 等人,2021)则是在保持精度的前提下缩小模型规模,利用大模型生成的数据对小模型进行微调。层稀疏交叉注意力(de Jong 等人,2022)剔除了构成长序列输入主要计算开销的大部分交叉注意力层。推测性采样(Chen 等人,2023;Leviathan 等人,2022)通过小模型批量生成多个候选词元,再由大模型并行验证,从而缓解内存带宽瓶颈。
最后,我们提出的向上训练方法受Komatsuzaki等人(2022)的启发,该方法将标准的T5检查点向上训练为稀疏激活的专家混合模型。
5.结论
语言模型推理成本高昂的主要原因在于加载键值与查询值时的内存带宽开销。多头注意力机制会降低模型容量与质量以减轻这一开销。我们提出仅需少量原始预训练计算量即可将多头注意力模型转换为多查询模型。此外,我们提出了分组查询注意力机制——作为多头注意力与多查询注意力之间的插值方案,该机制能以接近多查询注意力的推理速度,达到与多头注意力相当的质量水平。
本文主要致力于缓解加载键值对所产生的内存带宽开销。该开销在生成长序列时尤为显著,而长序列生成的质量本身难以评估。在摘要任务中,我们采用Rouge评分,但我们深知这是一种存在缺陷的评估方式,无法反映全貌;因此,难以确定我们的权衡取舍是否完全正确。由于算力有限,我们亦未将我们的XXL GQA模型与从头训练的对比模型进行比较,故无法获知增量训练相较于从头训练的相对性能。最后,我们仅针对编码器-解码器模型评估了增量训练和GQA的影响。近年来,纯解码器模型极为盛行,由于此类模型不具备分离的自注意力与交叉注意力机制,我们预计GQA相较于MQA将展现出更强的优势。
6.引用文献
- James Bradbury, Roy Frostig, Peter Hawkins, Matthew James Johnson, Chris Leary, Dougal Maclaurin, George Necula, Adam Paszke, Jake VanderPlas, Skye Wanderman-Milne, and Qiao Zhang. 2018. JAX: composable transformations of Python+NumPy programs.
- Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre, and John Jumper. 2023. Accelerating large language model decoding with speculative sampling. CoRR, abs/2302.01318.
- Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, Parker Schuh, Kensen Shi, Sasha Tsvyashchenko, Joshua Maynez, Abhishek Rao, Parker Barnes, Yi Tay, Noam Shazeer, Vinodkumar Prabhakaran, Emily Reif, Nan Du, Ben Hutchinson, Reiner Pope, James Bradbury, Jacob Austin, Michael Isard, Guy Gur-Ari, Pengcheng Yin, Toju Duke, Anselm Levskaya, Sanjay Ghemawat, Sunipa Dev, Henryk Michalewski, Xavier Garcia, Vedant Misra, Kevin Robinson, Liam Fedus, Denny Zhou, Daphne Ippolito, David Luan, Hyeontaek Lim, Barret Zoph, Alexander Spiridonov, Ryan Sepassi, David Dohan, Shivani Agrawal, Mark Omernick, Andrew M. Dai, Thanumalayan Sankaranarayana Pillai, Marie Pellat, Aitor Lewkowycz, Erica Moreira, Rewon Child, Oleksandr Polozov, Katherine Lee, Zongwei Zhou, Xuezhi Wang, Brennan Saeta, Mark Diaz, Orhan Firat, Michele Catasta, Jason Wei, Kathy Meier-Hellstern, Douglas Eck, Jeff Dean, Slav Petrov, and Noah Fiedel. 2022. Palm: Scaling language modeling with pathways.
- Arman Cohan, Franck Dernoncourt, Doo Soon Kim, Trung Bui, Seokhwan Kim, Walter Chang, and Nazli Goharian. 2018. A discourse-aware attention model for abstractive summarization of long documents. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 615–621, New Orleans, Louisiana. Association for Computational Linguistics.
- Tri Dao, Daniel Y. Fu, Stefano Ermon, Atri Rudra, and Christopher Ré. 2022. Flashattention: Fast and memory-efficient exact attention with io-awareness. CoRR, abs/2205.14135.
- Michiel de Jong, Yury Zemlyanskiy, Joshua Ainslie, Nicholas FitzGerald, Sumit Sanghai, Fei Sha, and William Cohen. 2022. FiDO: Fusion-in-decoder optimized for stronger performance and faster inference. arXiv preprint arXiv:2212.08153.
- Tim Dettmers, Mike Lewis, Younes Belkada, and Luke Zettlemoyer. 2022. Llm.int8(): 8-bit matrix multiplication for transformers at scale. CoRR, abs/2208.07339.
- Alexander R. Fabbri, Irene Li, Tianwei She, Suyi Li, and Dragomir R. Radev. 2019. Multi-news: A large-scale multi-document summarization dataset and abstractive hierarchical model. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 1074–1084. Association for Computational Linguistics.
- Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. 2022. GPTQ: accurate post-training quantization for generative pre-trained transformers. CoRR, abs/2210.17323.
- Google. 2020. Profile your model with cloud tpu tools. https://cloud.google.com/tpu/docs/ cloud-tpu-tools. Accessed: 2022-11-11.
- Jianping Gou, Baosheng Yu, Stephen J. Maybank, and Dacheng Tao. 2021. Knowledge distillation: A survey. Int. J. Comput. Vis., 129(6):1789–1819.
- Jonathan Heek, Anselm Levskaya, Avital Oliver, Marvin Ritter, Bertrand Rondepierre, Andreas Steiner, and Marc van Zee. 2020. Flax: A neural network library and ecosystem for JAX. Geoffrey E. Hinton, Oriol Vinyals, and Jeffrey Dean. 2015. Distilling the knowledge in a neural network. CoRR, abs/1503.02531.
- Mandar Joshi, Eunsol Choi, Daniel S. Weld, and Luke Zettlemoyer. 2017. Triviaqa: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, Canada. Association for Computational Linguistics.
- Aran Komatsuzaki, Joan Puigcerver, James Lee-Thorp, Carlos Riquelme Ruiz, Basil Mustafa, Joshua Ainslie, Yi Tay, Mostafa Dehghani, and Neil Houlsby. 2022. Sparse upcycling: Training mixture-of-experts from dense checkpoints.
- Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2022. Fast inference from transformers via speculative decoding. CoRR, abs/2211.17192.
- Gen Luo, Yiyi Zhou, Xiaoshuai Sun, Yan Wang, Liujuan Cao, Yongjian Wu, Feiyue Huang, and Rongrong Ji. 2022. Towards lightweight transformer via groupwise transformation for vision-and-language tasks. IEEE Trans. Image Process., 31:3386–3398.
- Ramesh Nallapati, Bowen Zhou, Cícero Nogueira dos Santos, Çaglar Gülçehre, and Bing Xiang. 2016. Abstractive text summarization using sequence-tosequence rnns and beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, CoNLL 2016, Berlin, Germany, August 11-12, 2016, pages 280–290. ACL.
- Jinjie Ni, Rui Mao, Zonglin Yang, Han Lei, and Erik Cambria. 2023. Finding the pillars of strength for multi-head attention. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14, 2023, pages 1452614540. Association for Computational Linguistics.
- Sungrae Park, Geewook Kim, Junyeop Lee, Junbum Cha, Ji-Hoon Kim, and Hwalsuk Lee. 2020. Scale down transformer by grouping features for a lightweight character-level language model. In Proceedings of the 28th International Conference on Computational Linguistics, COLING 2020, Barcelona, Spain (Online), December 8-13, 2020, pages 6883–6893. International Committee on Computational Linguistics.
- Reiner Pope, Sholto Douglas, Aakanksha Chowdhery, Jacob Devlin, James Bradbury, Anselm Levskaya, Jonathan Heek, Kefan Xiao, Shivani Agrawal, and Jeff Dean. 2022. Efficiently scaling transformer inference. arXiv preprint arXiv:2211.05102.
- Markus Rabe. 2023. Memory-efficient attention. https://github.com/google/flaxformer/ blob/main/flaxformer/components/ attention/memory_efficient_attention.py. Accessed: 2023-05-23.
- Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J. Liu. 2020. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res., 21:140:1–140:67.
- Noam Shazeer. 2019. Fast transformer decoding: One write-head is all you need. arXiv preprint arXiv:1911.02150.
- Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timothée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurelien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. 2023. Llama: Open and efficient foundation language models.
- Alex Wang, Amanpreet Singh, Julian Michael, Felix Hill, Omer Levy, and Samuel R. Bowman. 2019. GLUE: A multi-task benchmark and analysis platform for natural language understanding. In 7th International Conference on Learning Representations, ICLR 2019, New Orleans, LA, USA, May 6-9, 2019. OpenReview.net.
- Samuel Williams, Andrew Waterman, and David A. Patterson. 2009. Roofline: an insightful visual performance model for multicore architectures. Commun. ACM, 52(4):65–76.
- Chenguang Zhu, Yang Liu, Jie Mei, and Michael Zeng. 2021. Mediasum: A large-scale media interview dataset for dialogue summarization. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2021, Online, June 6-11, 2021, pages 5927–5934. Association for Computational Linguistics.

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)