【量化RL】使用PPO来进行ETF动量轮动(v0.1)
还是习惯了用CSDN的编辑方式,因为旁边可以看到写了啥。DQN-ETF强化学习-滚动-经验保存反复学习版AI强化学习ETF策略-DQN智能体-滚动训练简单etf动量轮动策略simple_etf_1这里为simple_etf_2的初始版本实验。因为还是初始的一个成功,这里先记录下流程。和前言1的对比如下:两者的滑点,交易时间,佣金设置相同下,etf也相同下:收益上,现在比之前策略要好,但是持有体验上
前言
还是习惯了用CSDN的编辑方式,因为旁边可以看到写了啥。
参考1:DQN-ETF强化学习-滚动-经验保存反复学习版
参考2:AI强化学习ETF策略-DQN智能体-滚动训练
这里为simple_etf_2的初始版本实验。
因为还是初始的一个成功,这里先记录下流程。
聚宽online代码见:PPO轮动策略初始版 simple_etf_2(v0.1)
一、效果展示
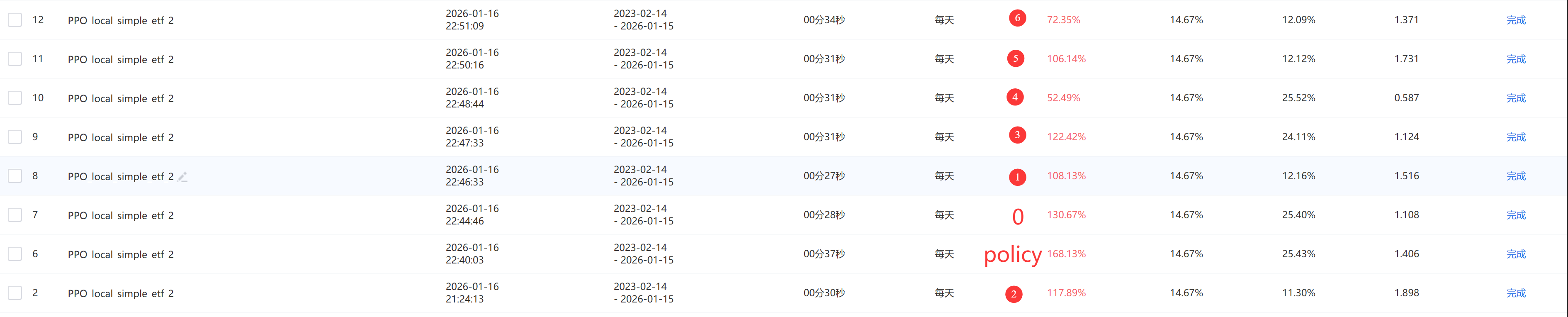
这里0-6 均为动作,7动作为平仓,即一直不买卖操作。
policy为PPO训出的模型
回测时间为训练模型时没见过达到数据。
训出的模型好于上述所有动作,可以说明模型学到了市场上的一些动作。
这里PPO为自己写的,代码库为:https://github.com/wild-firefox/FreeRL
二、状态,动作
由于是实验性质的from scratch,且是量化小白,这里状态动作基本参考2里的状态动作,
状态修改点:为了和simple_etf_1做比较,选取的etf为simple_etf_1的etf。
前5个状态:[参照基线的年化波动率,参考基线的累计年化收益,ETF池整体动量强度均值,动量离散度,两个最强动量ETF之间的差异]
聚宽online的代码
hs300 = '000300.XSHG'
hs300_data = get_price(hs300, count=g.state_window,
end_date=context.previous_date,
frequency='daily', fields=['close'])
hs300_returns = hs300_data['close'].pct_change().dropna() #相邻两天的百分比变化
## 年化波动率估计 公式:日波动率 * sqrt(252)
market_volatility = hs300_returns.std() * np.sqrt(252) if not hs300_returns.empty else 0
# 市场累计年化收益 公式:= (期末价/期初价 -1) * 252
market_momentum = (hs300_data['close'].iloc[-1] / hs300_data['close'].iloc[0] - 1) * 252 if len(hs300_data) > 0 else 0
# ETF池整体动量强度
avg_etf_momentum = np.mean(list(momentum_scores.values())) if momentum_scores else 0
# 动量离散度
momentum_dispersion = np.std(list(momentum_scores.values())) if len(momentum_scores) > 1 else 0
# 市场相关性代理 # 表示两个最强动量ETF之间的差异
top_etfs = sorted(momentum_scores, key=momentum_scores.get, reverse=True)[:2] if len(momentum_scores) >= 2 else []
correlation_proxy = abs(momentum_scores[top_etfs[0]] - momentum_scores[top_etfs[1]]) if len(top_etfs) == 2 else 0
后面状态:选取的etf动量,动量计算方式见前文。
动作修改点:(在参考1里)这里有三个动作的num=1,其实都是选取最大动量的etf,所以动作可以消减2个,现在为8个。
equal表示等权,momentum表示按动量权重,volatility表示按波动权重(新算一个波动值,和上述年化波动计算方式一样,波动越小,占比权重大)
g.action_space = [
{'type': 'equal', 'num': 1}, {'type': 'equal', 'num': 2}, {'type': 'equal', 'num': 3},
{'type': 'momentum', 'num': 1}, {'type': 'momentum', 'num': 2}, {'type': 'momentum', 'num': 3},
{'type': 'volatility', 'num': 1}, {'type': 'volatility', 'num': 2}, {'type': 'volatility', 'num': 3},
{'type': 'cash', 'num': 0} # 空仓动作
]
TODO
1.看代码上,可能还需要加上前言中计算到的量加入到状态,即右偏RSRS值和MA20均线值(2个,相差窗口3天)
2.这里参考1上对代码归一化的处理,感觉有点怪,不应该拿历史的数据来做归一吗,怎么直接拿当前状态来归一。
3.新写了一个连续的PPO,这里图方便,直接映射到离散动作上了,应该直接拿离散PPO会好一点。
环境搭建
数据上,使用开源库efinance来获取日线数据。
注意:为计算动量正确,要余出多的量来算第一天的动量值。
且回测时间和训练时间不能有交叉。
奖励上:修改了一下,当前,如下效果最好,step_return 为当日收益率。
reward = 0
if action == self.action_num-1 : # 空仓
reward -= 0
elif action != self.action_num-1 and step_return > 0:
reward += step_return
回合上:原来参考1是每月动作一次,这里改成每日动作一次。
其他:简单模仿真实环境,加上一个手续费的概念。
最后先在此环境上验证效果最好,再拿训出的模型部署到聚宽上比较真实的测试,最后效果发现差不多。
看了下动作也是差不多的,且验证过动量计算也是一致的。
验证图:当聚宽也不设置滑点,并均设置万2手续费,(一点区别:搭建的环境里没有设置最低的手续费,聚宽里设置最低5,)且均9点半交易。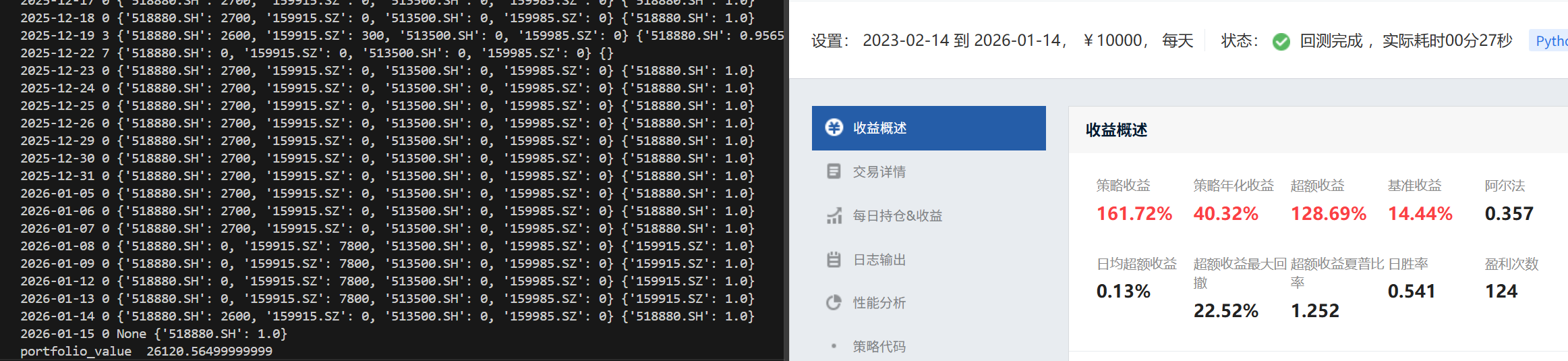
差距不超过0.2%。
交易细节图:4月14日的两者持仓相同,其余基本一致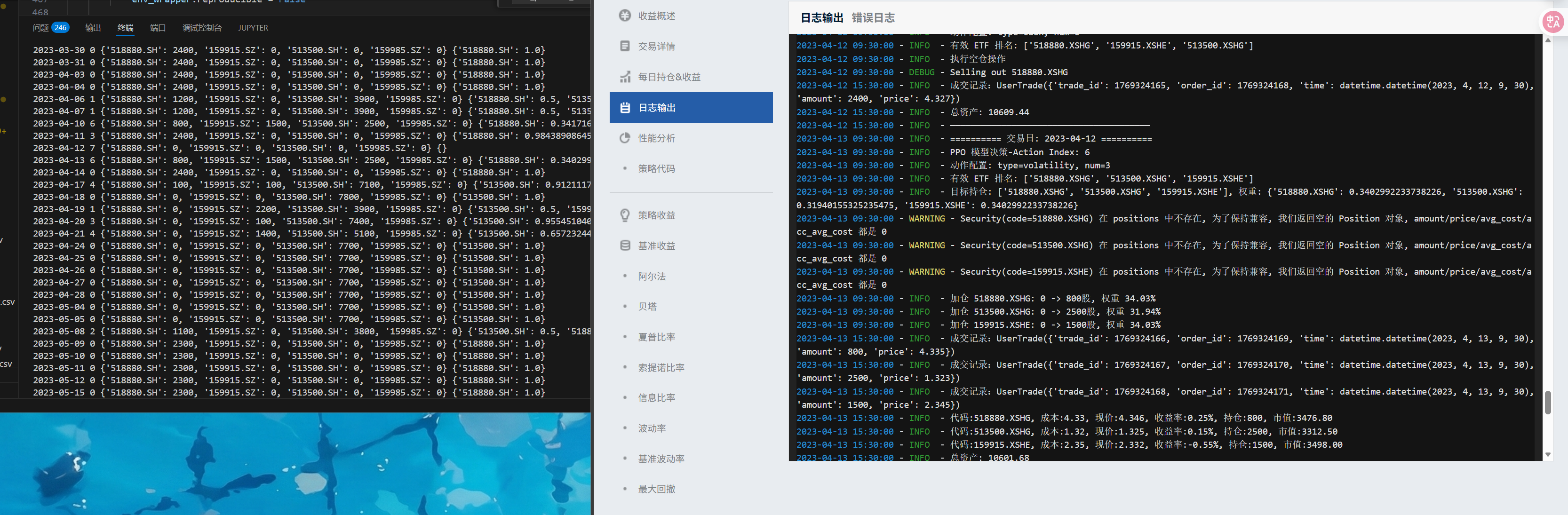
收益率曲线也基本一致。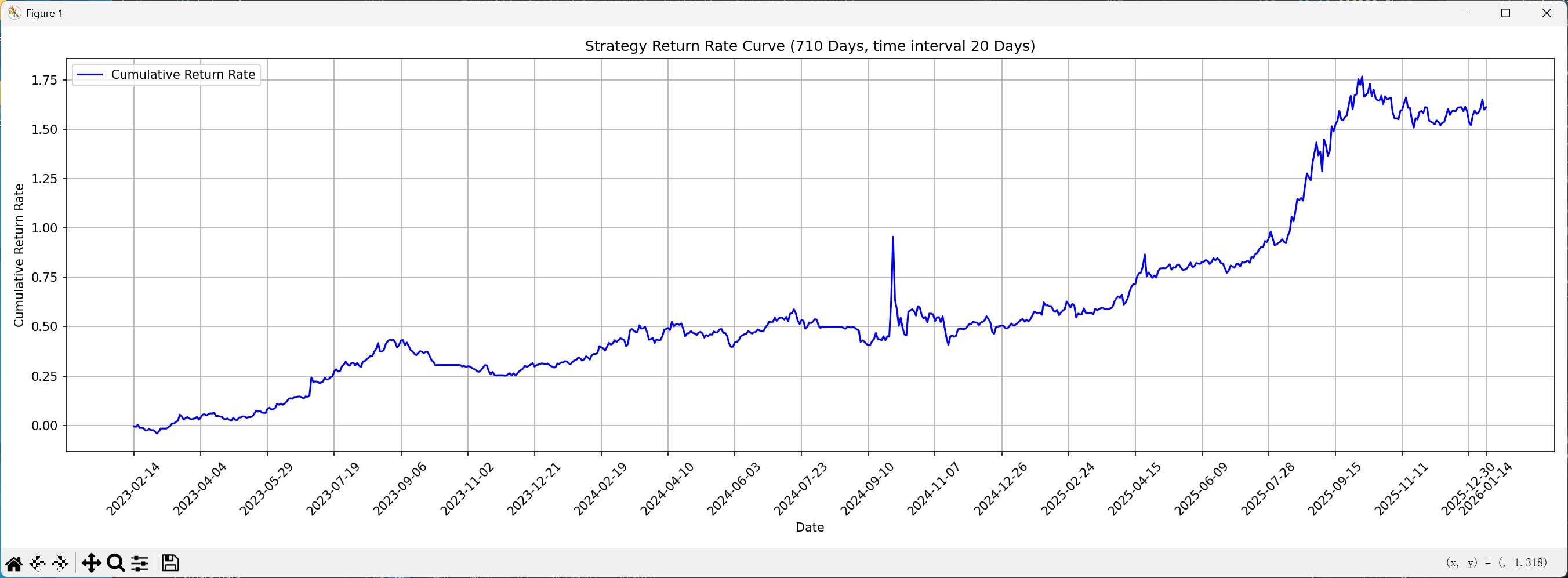
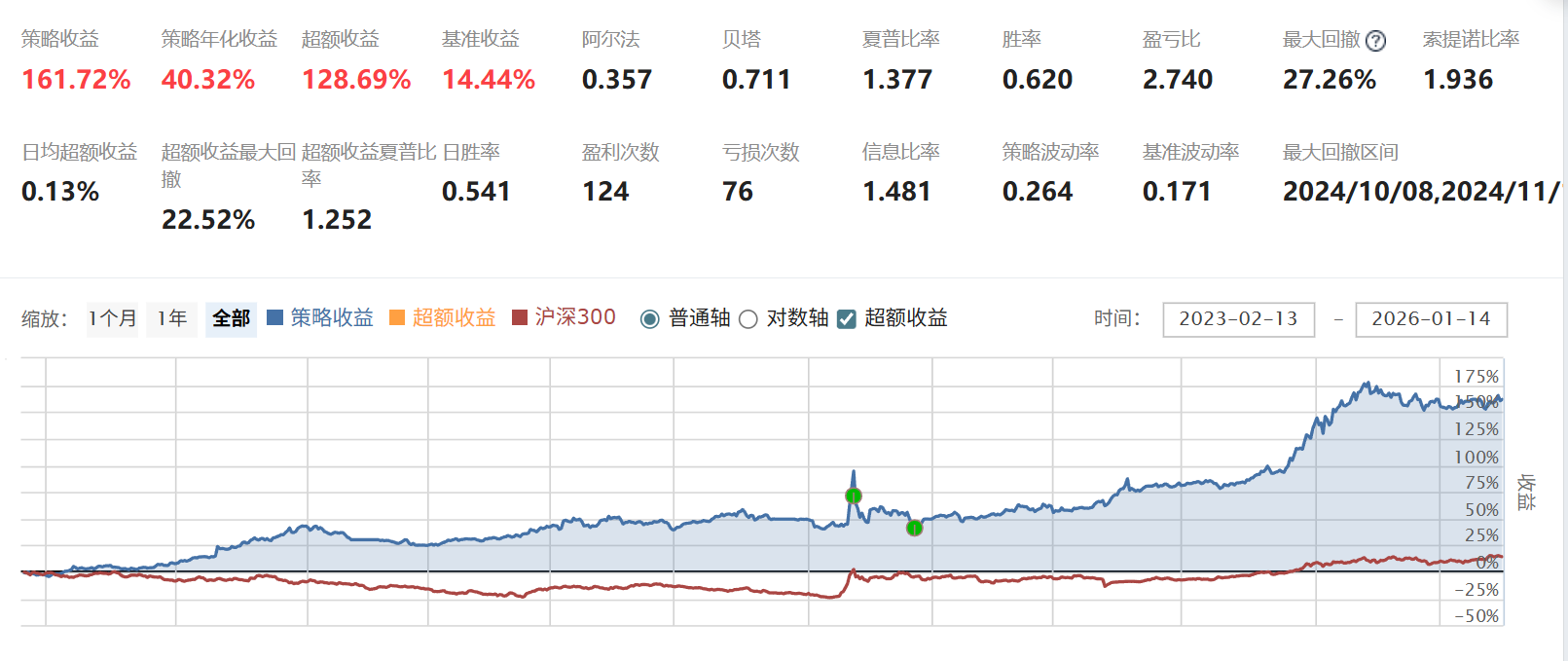
注意
在聚宽上逻辑一定要改成先卖再买,否则调仓会不一致。
最后,为符合逻辑,设置滑点为0.001,交易时间为10点半,万2,5起
效果如下:
TODO
之后试下,奖励直接改成step_return 。
策略
这里用了最熟悉的PPO策略,替换掉了参考中的DQN。
训练时间:2020-3-9~2023-2-13 (711个交易日)
回测时间:2023-2-14~2026-1-14 (710个交易日)
总结
和前言1的对比如下:两者的滑点,交易时间,佣金设置相同下,etf也相同下: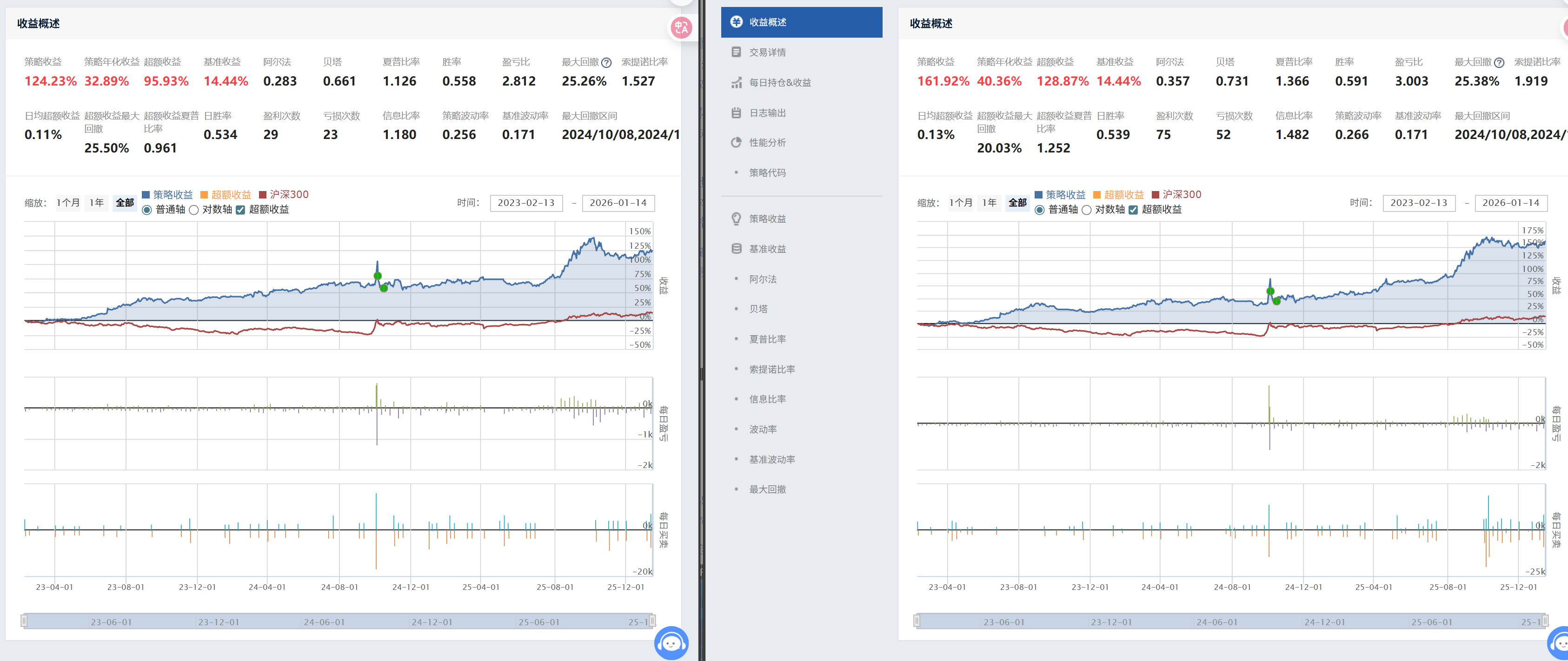
收益上,现在比之前策略要好,但是持有体验上效果应该不如之前的(在前面一部分的日期,还有优化空间),后面的体验倒是超过了。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 11
11 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)