4 倍速 + 不崩帧!RAE 框架颠覆 VAE,文本生成图像迎来技术拐点
纽约大学团队推出表征自编码器(RAE)框架,突破传统变分自编码器(VAE)在文本到图像生成中的局限。RAE直接在高维语义空间训练扩散模型,采用"冻结预训练编码器+轻量级解码器"架构,解决了VAE训练慢、易过拟合等问题,实现4倍收敛加速。研究发现数据组合比规模更重要,大规模模型设计更简化。相比VAE,RAE在训练效率、微调稳定性和语义一致性上具有显著优势,为统一多模态建模开辟新路
在文本到图像(T2I)生成领域,变分自编码器(VAE)主导的潜在扩散模型早已成为行业标配,但纽约大学团队推出的表征自编码器(RAE)框架,正以 “简单却更强” 的姿态打破这一格局。它通过直接在高维语义空间训练扩散模型,不仅解决了 VAE 长期存在的训练慢、易过拟合、语义割裂等痛点,更实现了 4 倍以上的收敛加速,为大规模 T2I 生成提供了全新技术路径。
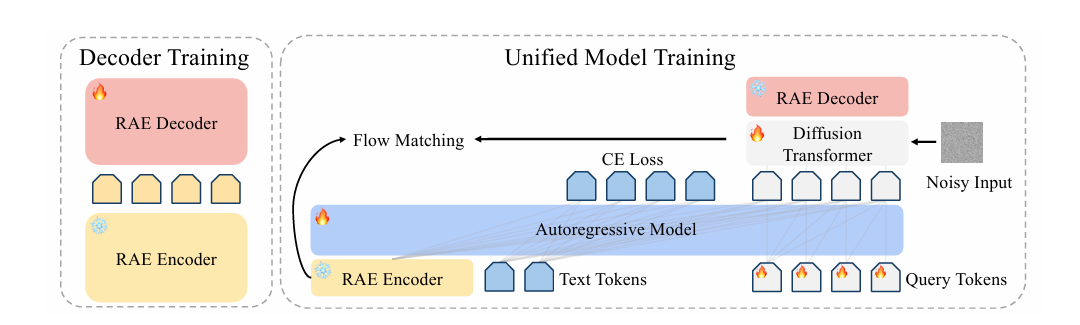
核心逻辑:RAE 如何跳出 VAE 的 “低维陷阱”?
VAE 的核心思路是将图像压缩到低维潜在空间以降低计算成本,但这种压缩不可避免地造成语义信息损耗,尤其在文本渲染等需要精细细节的场景表现拉胯。而 RAE 反其道而行之,采用 “冻结预训练编码器 + 轻量级解码器” 的极简架构:直接复用 SigLIP-2 这类成熟的视觉表征模型作为固定编码器,输出 1152 维的高维语义特征,无需重新训练编码器;仅通过优化轻量级解码器,就能实现从高维特征到像素的精准重建。
这种设计的妙处在于,高维语义空间天然包含更丰富的视觉细节和语义关联,让扩散模型可以直接在 “语义层面” 学习生成规律,而非像 VAE 那样在压缩后的低维空间中 “猜细节”。此前高维空间被认为难以用于生成建模,但 RAE 通过针对性的技术优化,成功将这一 “劣势” 转化为核心优势,彻底跳出了 VAE 的低维陷阱。
数据秘诀:不是越多越好,而是 “组合得巧”
要让 RAE 适配开放场景的 T2I 生成,数据训练是关键一步。研究团队整合了 7300 万条数据,涵盖网络图像、FLUX 生成的合成数据以及专门的文本渲染数据,却发现一个重要规律:数据组合比单纯的规模增长更能决定生成质量。
仅用 ImageNet 训练的 RAE 解码器,在自然图像重建上表现尚可,但面对文本渲染场景时完全 “抓瞎”,无法还原文字的精细笔画;而加入专门的文本渲染数据后,文本重建质量大幅提升,同时还能保持自然图像的生成效果。此外,无论是语言监督的 SigLIP-2 还是自监督的 WebSSL,都能作为 RAE 的有效编码器,这说明 RAE 框架对编码器选择并不挑剔,具备很强的适配性。
架构取舍:规模越大,设计越简单
在 RAE 框架的优化过程中,研究团队发现了一个有趣的现象:模型规模扩大后,反而能简化架构设计。其中,维度依赖的噪声调度是唯一不可或缺的核心组件 —— 通过根据潜在空间维度调整扩散时间步,能让生成对齐度和质量大幅提升,一旦移除,关键评估指标会直接断崖式下降。
而那些为小尺度模型设计的复杂结构,在大规模 T2I 训练中作用逐渐失效。比如宽扩散头(DiT^DH),在 0.5B 参数的小模型上能带来明显性能提升,但当模型参数超过 24 亿后,这种优势几乎可以忽略;再比如噪声增强解码,仅在训练初期有轻微帮助,后期则完全饱和。这一发现为模型瘦身和效率提升提供了重要依据:大规模模型无需复杂结构堆砌,做好核心设计即可发挥优势。
性能碾压:VAE 的三大痛点被 RAE 逐个击破
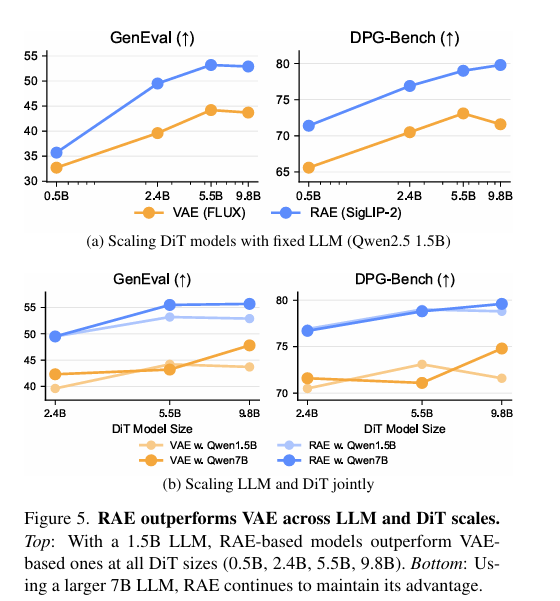
与当前最先进的 FLUX VAE 相比,RAE 在全尺度模型中都展现出压倒性优势,尤其在 VAE 的三大痛点上实现了精准突破。
首先是训练效率,RAE 实现了 4 倍以上的收敛加速。采用 15 亿参数 Qwen-2.5 语言模型搭配 24 亿参数 DiT 的 RAE 模型,在 GenEval 和 DPG-Bench 两个权威基准上,分别比 VAE 快 4.0 倍和 4.6 倍,意味着用更少的训练迭代就能达到更高性能。这种优势在从 5 亿到 98 亿参数的不同规模 DiT 模型中始终保持一致,即便是最小规模的 RAE 模型,也能轻松超越同配置的 VAE 基线。
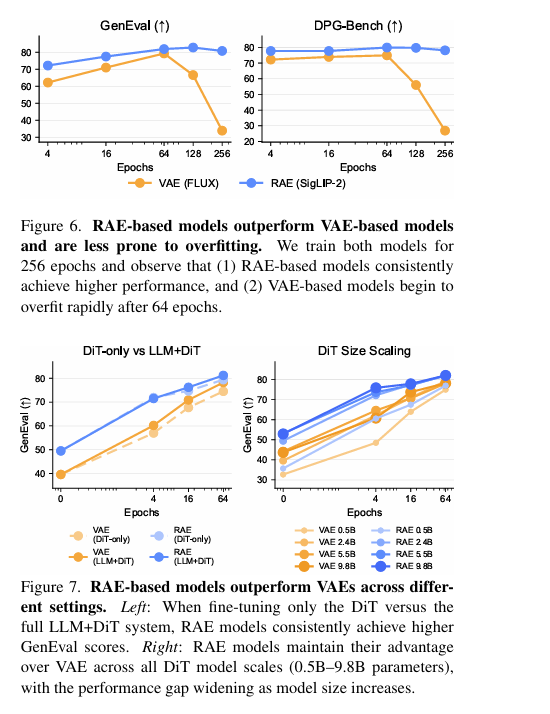
其次是微调稳定性,VAE 在 64 个 epoch 后就会出现灾难性过拟合,性能急剧下降,而 RAE 模型在 256 个 epoch 内始终保持稳定,甚至扩展到 512 个 epoch 仍仅有轻微性能衰减。这背后的核心原因是,RAE 的高维语义空间提供了天然的正则化效果,避免模型记忆训练样本,而是真正学习数据的底层分布规律。
最后是语义一致性,RAE 打破了视觉理解与生成的壁垒。传统 VAE 模型中,生成和理解依赖不同的潜在空间,模型无法直接解读自身生成的结果;而 RAE 让两者共享同一高维语义空间,生成的特征可被语言模型直接处理,无需先解码为像素再重新编码。研究团队基于这一特性提出潜在空间测试时缩放策略,通过语言模型对生成的潜在特征直接打分筛选,在不渲染像素的情况下就能提升生成质量,让 GenEval 分数获得显著提升。
未来方向:不止于图像,更是统一多模态的基石
RAE 的价值远不止于超越 VAE,更在于它为统一多模态建模开辟了新路径。生成任务的训练不会损害模型的理解能力,RAE 模型在 MME、TextVQA 等多个视觉语言基准上的表现,与纯理解模型相当,这意味着未来有望构建 “一个模型搞定理解 + 生成” 的多模态系统。
数据策略上的发现也极具指导意义:合成数据与 Web 数据的互补使用,比单纯增加数据量更有效。合成数据提供风格一致的视觉信号,加速模型收敛;Web 数据带来丰富的语义多样性,让模型能学习到更全面的视觉概念,两者结合实现了 1+1>2 的效果。
纽约大学团队已承诺开源所有代码、数据和模型权重,这意味着 RAE 很快将成为 T2I 领域的新基准。对于开发者而言,抛弃复杂的 VAE 调优,转向 RAE 框架可能是提升生成模型性能的最短路径;而其统一多模态建模的特性,也有望在图像编辑、视频生成等更多领域释放潜力,推动生成式 AI 技术进入更高效、更稳定的新阶段。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)