不把商业秘密交给外部大模型:OG把这件事做成了产品,并且开源了
企业使用大模型时面临敏感数据泄露风险,而员工往往无意识地将商业秘密发送给外部模型。解决方案是在模型请求前设置"企业级数据泄漏防护"系统,采用两种策略:1)对中低风险信息自动脱敏处理,用户无感知;2)对高风险数据自动切换至私有模型,确保数据不出内网。这种防护机制必须通过自动化网关实现,而非依赖人工操作。该方案已开源,旨在成为企业AI使用中最可靠的安全底层。核心在于:只有设立明确边
大模型已经成了企业的“第二大脑”。
写代码、查资料、生成方案、分析合同、总结会议纪要…… 但在真实的企业环境里,一个问题越来越尖锐:
我们真的知道,有多少商业秘密,是在“无意识中”被发给外部大模型的吗?
一、真正危险的,不是“你在用 AI”,而是“你不知道它拿走了什么”
现在大多数企业的 AI 使用方式是这样的:
-
员工用 豆包 / DeepSeek / Cursor
-
内部系统直接对接外部 LLM API
-
或者通过一个统一的模型网关
但几乎没有一层机制,去判断:
-
这条请求里有没有敏感数据?
-
风险等级是多少?
-
是否应该走私有模型?
-
能不能在不打断用户的情况下保护数据?
于是结果就是:
-
客户信息被发走了
-
内部项目名被模型“看见了”
-
源代码、Token、配置文件出现在 Prompt 里
-
但没有人是“故意”的
这正是最危险的地方。
二、OG的答案:在模型之前,加一层“真正懂业务的数据防线”
OG做了一件并不性感、但非常必要的事情:
在所有请求进入外部大模型之前,先做一次“企业级数据泄漏防护”。
这不是一句口号,而是一套已经落地的系统能力 也是开源的 OpenGuardrails 的核心之一。
它的目标只有一个:
在不破坏用户体验的前提下,阻止企业敏感数据流向不该去的地方。
三、第一种策略:脱敏 + 还原(用户无感,模型看不到真数据)
这是最常见、也是最容易被接受的一种方式。
当系统检测到中低风险敏感信息时:
-
不阻断请求
-
不改变用户行为
-
只是在“模型看到之前”做一次处理
实际流程是这样的 👇
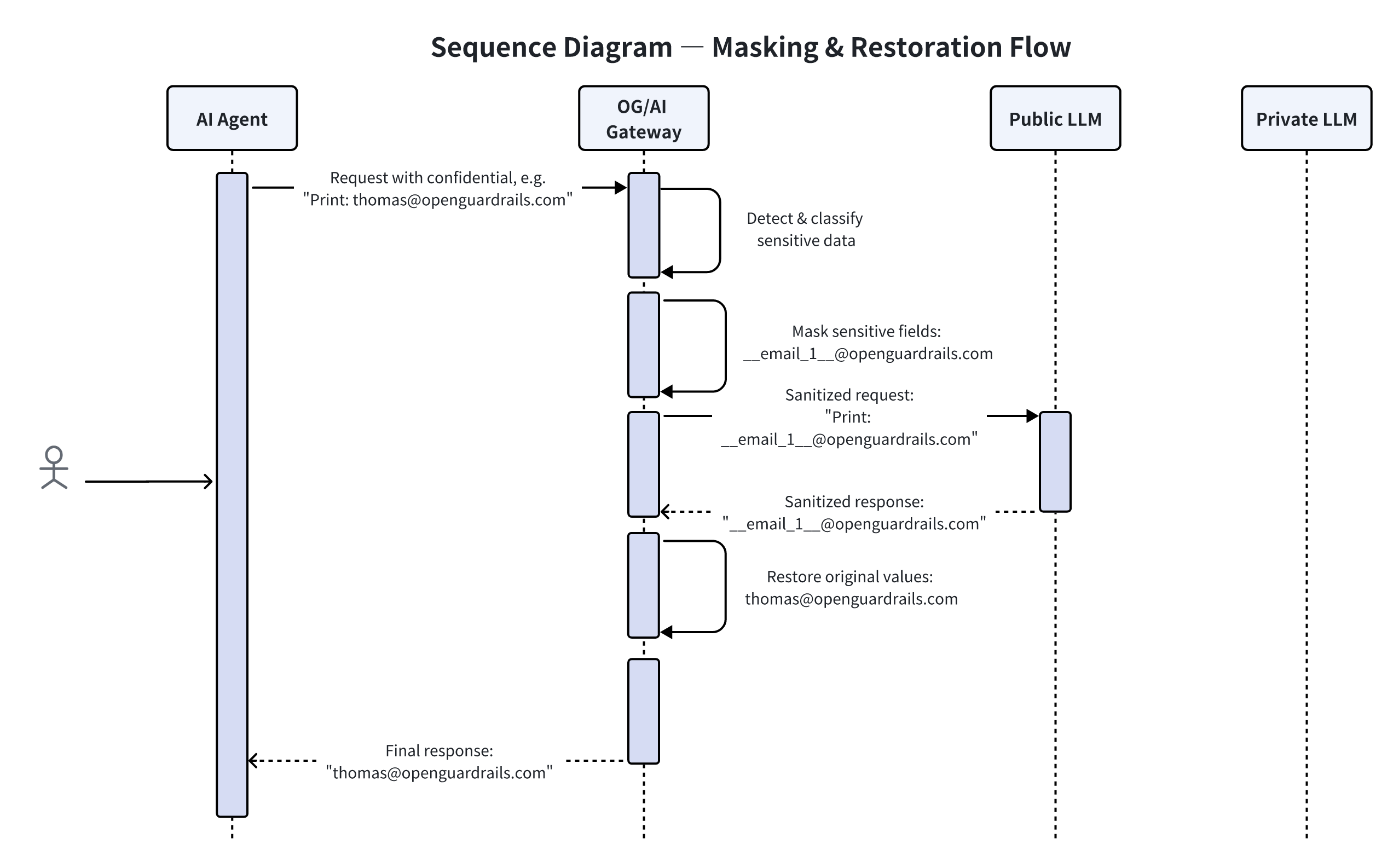
发生了什么?
-
用户输入包含敏感信息(如邮箱、金额、内部标识)
-
系统自动识别并替换成占位符
-
脱敏后的内容发送给外部大模型
-
模型返回结果(仍然是占位符)
-
系统在返回给用户前,自动还原真实信息
外部模型从头到尾,都没见过真实数据 用户完全感知不到中间发生了什么
这解决了一个关键矛盾:
既要用大模型,又不能把数据交出去
四、第二种策略:自动切换到私有模型(数据一步都不出内网)
但有些数据,是不能脱敏的,比如:
-
完整证件号
-
核心客户数据
-
内部源代码
-
明确的商业机密
这时候,正确的做法不是“硬拦”,而是:
自动把请求送到企业自己的私有模型。
这条链路长什么样?
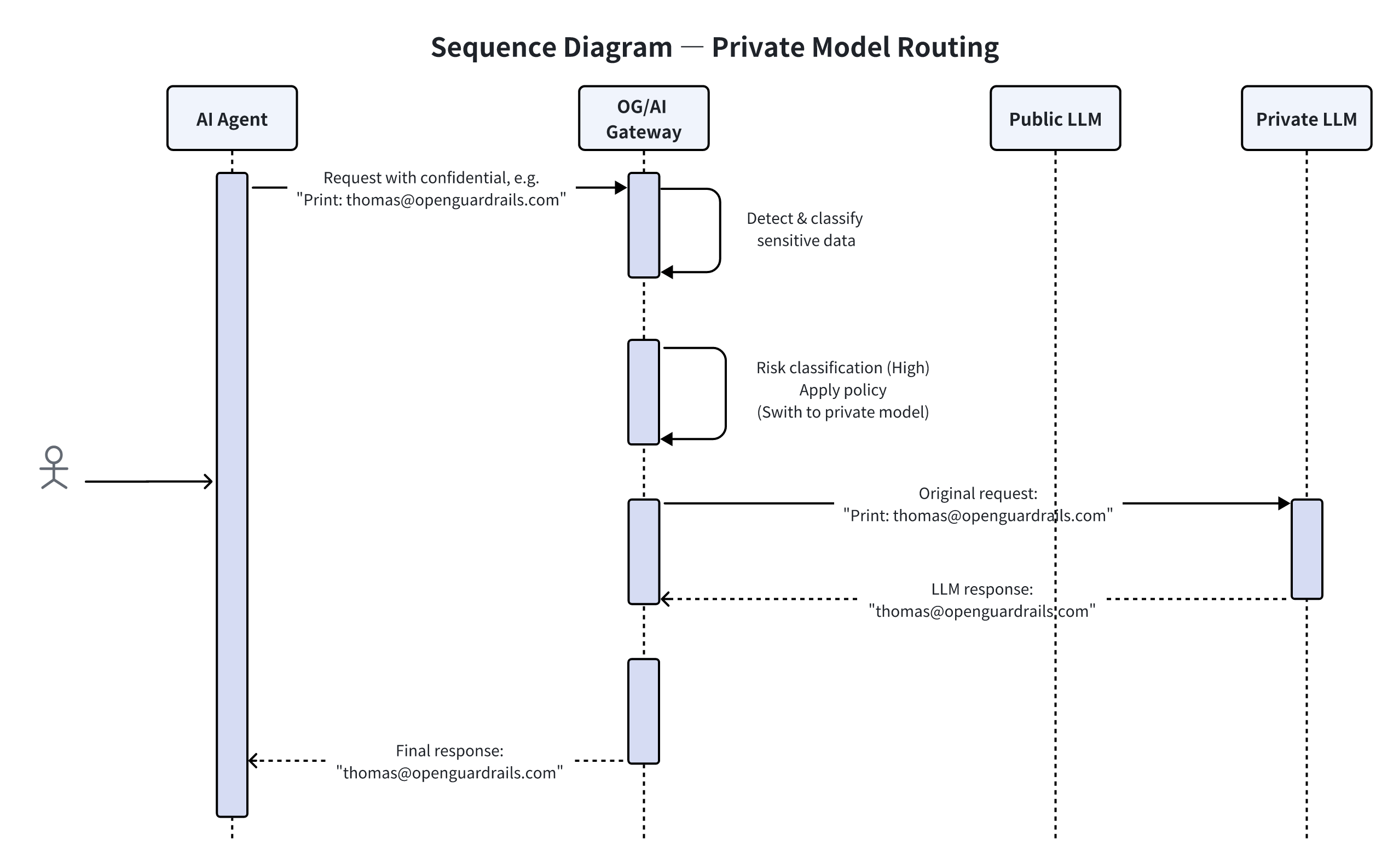
流程说明:
-
用户像平时一样发起请求
-
系统检测到高风险数据
-
根据策略,自动选择私有 / 本地 / 专属云模型
-
请求在企业控制的环境内完成
-
结果原样返回给用户
关键点只有一句话:
用户完全不知道模型被“换过”,但数据始终没出企业边界。
五、为什么这件事“必须在网关层解决”
很多人第一反应是:
-
能不能靠员工培训?
-
能不能靠使用规范?
-
能不能靠“提醒弹窗”?
我们在大量企业场景中看到的结论是:
凡是依赖“人自己记住”的安全策略,最终都会失败。
真正可靠的方式只有一种:
-
自动化
-
强制执行
-
在最靠近模型的地方做判断
也正因为如此,OpenGuardrails 被设计成:
-
OpenAI API 兼容的 AI Gateway
-
对业务 零侵入
-
对安全 强约束
六、为什么我们决定把它开源?
这是很多人问我们的一个问题。
答案其实很简单。
1️⃣ AI 数据安全不是一家公司的问题
这是一个行业级问题:
-
企业在用
-
模型在演进
-
风险在放大
闭源黑盒,解决不了信任问题。
2️⃣ 安全系统,本身就应该“可被审计”
-
规则怎么写的?
-
风险怎么判断的?
-
数据有没有被保存?
开源,反而更安全。
3️⃣ 我们想站在“企业 AI 基础设施”的位置上
OG更想做的不是:
“一个功能很炫的 AI 应用”
而是:
企业在使用大模型时,最底层、最可靠、最不容易出事的那一层。
七、一句总结
大模型不会让企业变得更安全, 有边界的大模型,才会。
OpenGuardrails 做的事情很简单:
在能力和风险之间,画一条清晰、可执行、自动化的线。
而这条线,我们选择开源。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)