揭秘大模型:从Transformer到ChatGPT的底层逻辑
核心模块关键技术点一句话解释表示层把文字变成计算机能算的数字向量。架构层理解上下文,知道“它”指代谁。训练层从“猜下一个词”进化到“听懂指令”。生成层根据概率逐个崩词,温度控制脑洞。扩展层决定了一次能读多少书,能不能外挂知识库。大语言模型并没有产生“意识”,它本质上是对人类语言统计规律的极致压缩。但正是这种极致的概率计算,涌现出了通过图灵测试的智能。理解了这些原理,作为开发者的你就不仅仅是在“调用
【硬核科普】拆解大模型(LLM)的“灵魂”:从 Transformer 到 ChatGPT 的底层原理
1. 前言:AI 并不是魔法
当 ChatGPT 写出一首诗,或者 Claude 帮你写好代码时,很多人会觉得这是一种“魔法”。但作为技术人员,我们需要透过魔法看本质。
大语言模型(Large Language Model, LLM)本质上是一个巨大的概率预测机器。它的所有智能,都建立在数学、统计学和算力之上。
本文将带你像剥洋葱一样,层层拆解 LLM 的技术内核:它是怎么“读”懂文字的?它是怎么“思考”的?它又是怎么“学会”说话的?
第一层:如何让机器“读懂”文字?(Tokenization & Embedding)
计算机不认识中文,也不认识英文,它只认识数字。所以,第一步是数字化。
1. 切分 (Tokenization)
我们将一句话拆解成一个个最小的语义单位,称为 Token。
-
对于英文,一个 Token 可能是一个单词(Apple)或词根(ing)。
-
对于中文,一个 Token 通常是一个字或词。
例子:
I love AI$\rightarrow$[I, love, AI]
2. 嵌入 (Embedding) —— 赋予语义
这是最关键的一步。我们不能简单地把“苹果”编码为 1,“香蕉”编码为 2,因为 1 和 2 没有任何逻辑关系。
我们需要把每个 Token 映射到一个高维向量空间中。
-
向量化:
苹果=[0.82, -0.55, 0.12, ...](假设是 1024 维向量) -
语义空间:在这个数学空间里,含义相近的词,距离会很近。
-
国王-男人+女人$\approx$女王 -
这就是机器理解“语义”的方式——通过计算向量之间的距离。
-
第二层:最强心脏 —— Transformer 架构
LLM 之所以能“大”,全靠 2017 年 Google 提出的 Transformer 架构。在此之前,RNN 和 LSTM 记不住长句子,而 Transformer 解决了这个问题。
1. 自注意力机制 (Self-Attention) —— LLM 的“眼睛”
这是 Transformer 的灵魂。当模型读到一句话时,它会计算每个词与其他所有词之间的关联度。
例子:“这只动物没过马路,因为它太累了。”
当人类读到“它”时,我们知道指代的是“动物”。
AI 怎么知道?通过 Self-Attention 计算,“它”这个词与“动物”的**注意力权重(Attention Weight)**最高,而与“马路”的权重较低。
通过这种机制,模型能够理解长文本中复杂的上下文依赖关系。
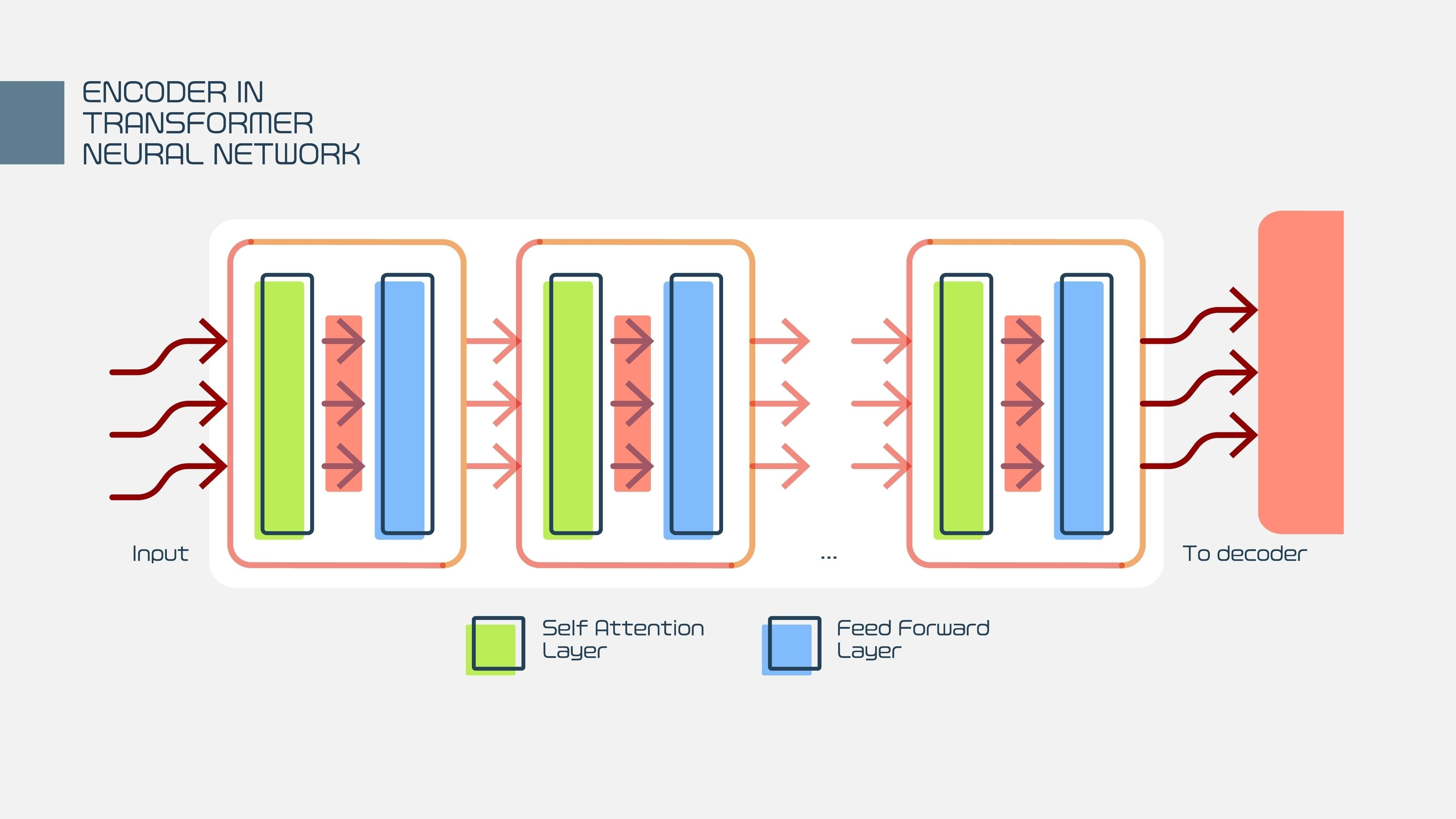
2. 前馈神经网络 (Feed-Forward Networks) —— LLM 的“记忆”
如果说 Attention 是在看上下文,那么 FFN 层就是在调用模型“背下来”的知识。这里存储了大量的参数(权重),模型从海量数据中学到的世界知识(如“巴黎是法国的首都”)主要存储在这里。
第三层:如何练就“大脑”?(训练三部曲)
一个单纯的 Transformer 架构只是一堆初始化的随机数字。要变成 ChatGPT,需要经历三个阶段的训练:
阶段一:预训练 (Pre-training) —— “博览群书”
-
目标:预测下一个词 (Next Token Prediction)。
-
数据:万亿级别的互联网文本(维基百科、书籍、代码、网页)。
-
过程:
-
输入:“床前明月光”
-
遮住最后一个字,让模型猜。
-
模型猜“水” -> 错了,调整参数。
-
模型猜“光” -> 对了,强化参数。
-
-
产出:基座模型 (Base Model)。
-
特点:它懂很多知识,能续写小说,但它不会聊天。你问它“你是谁”,它可能会续写成“你是谁的儿子...”。
-
阶段二:有监督微调 (SFT, Supervised Fine-Tuning) —— “学会规矩”
-
目标:学会听指令 (Instruction Following)。
-
数据:高质量的人工问答对(Prompt + Answer)。
-
过程:人类老师给它演示:“当用户问 A 时,你应该回答 B”。
-
产出:对话模型 (Chat Model)。
-
特点:它终于能像助手一样正常对话了,知道了问答的格式。
-
阶段三:人类反馈强化学习 (RLHF) —— “对齐价值观”
-
目标:让回答更符合人类偏好(有用、安全、无害)。
-
过程:
-
模型生成两个回答,人类标注员选出更好的那个(Reward Model)。
-
利用强化学习(PPO算法),让模型朝着“人类给高分”的方向进化。
-
-
产出:最终上线的 LLM(如 GPT-4, DeepSeek-V3)。
第四层:如何生成回复?(Inference & Probability)
当你问 AI 问题时,它并不是在数据库里“搜索”答案,而是在**“生成”**答案。
1. 逐词生成
LLM 每次只能生成一个 Token。
它根据你输入的所有上文,计算词表中几万个词出现的概率分布。
输入:“我爱吃”
模型预测概率:
苹果 (20%)
火锅 (15%)
石头 (0.001%)
2. 温度 (Temperature) —— 控制创造力
你是想要最稳妥的答案,还是有创意的答案?
-
Temperature = 0:总是选概率最大的词(苹果)。结果准确、死板。
-
Temperature > 0.8:有机会选中概率稍低但合理的词(火锅)。结果丰富、多样,但也更容易胡说八道(幻觉)。
5. 总结:LLM 的知识图谱
| 核心模块 | 关键技术点 | 一句话解释 |
| 表示层 | Tokenization, Embedding | 把文字变成计算机能算的数字向量。 |
| 架构层 | Transformer, Self-Attention | 理解上下文,知道“它”指代谁。 |
| 训练层 | Pre-training, SFT, RLHF | 从“猜下一个词”进化到“听懂指令”。 |
| 生成层 | Decoding, Temperature | 根据概率逐个崩词,温度控制脑洞。 |
| 扩展层 | Context Window, RAG | 决定了一次能读多少书,能不能外挂知识库。 |
6. 结语
大语言模型并没有产生“意识”,它本质上是对人类语言统计规律的极致压缩。但正是这种极致的概率计算,涌现出了通过图灵测试的智能。
理解了这些原理,作为开发者的你就不仅仅是在“调用 API”,而是在驾驭概率,构建未来。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)