1.2 大模型架构介绍
仅供参考
小节目标
- 掌握 Transformer 架构原理
- 理解多头注意力、掩码注意力机制
- 了解位置编码的作用与计算方式
一、Transformer架构
1. Transformer 的提出背景
- 2017 年 Google 论文**《Attention Is All You Need》**首次提出。
- 核心创新:完全基于 注意力机制(Attention),摒弃 RNN/CNN,解决长距离依赖和并行训练问题。
2. Transformer 整体架构
包含两大模块:
- Encoder(编码器):理解输入序列 → 生成上下文表示
- Decoder(解码器):基于编码结果 + 已生成内容 → 自回归生成输出
主流大模型均基于 Transformer 衍生,分为三类架构:
| 架构类型 | 特点 | 代表模型 |
|---|---|---|
| Encoder-only | 双向上下文理解,适合判别任务 | BERT |
| Decoder-only | 单向自回归生成,适合文本生成 | GPT 系列 |
| Encoder-Decoder | 编码-解码结构,适合翻译/摘要 | T5、BART |
3. Transformer 核心组件详解
① 输入部分
- 输入嵌入(Input Embedding)
将词元(token)映射为固定维度的可学习词向量。 - 位置编码(Positional Encoding, PE)
- 问题:Transformer 本身无序,无法感知词序。
- 解决:为每个位置添加位置向量,与词向量相加。
- 公式特点:
- 使用正弦/余弦函数,支持任意长度外推
- 不同频率编码不同位置
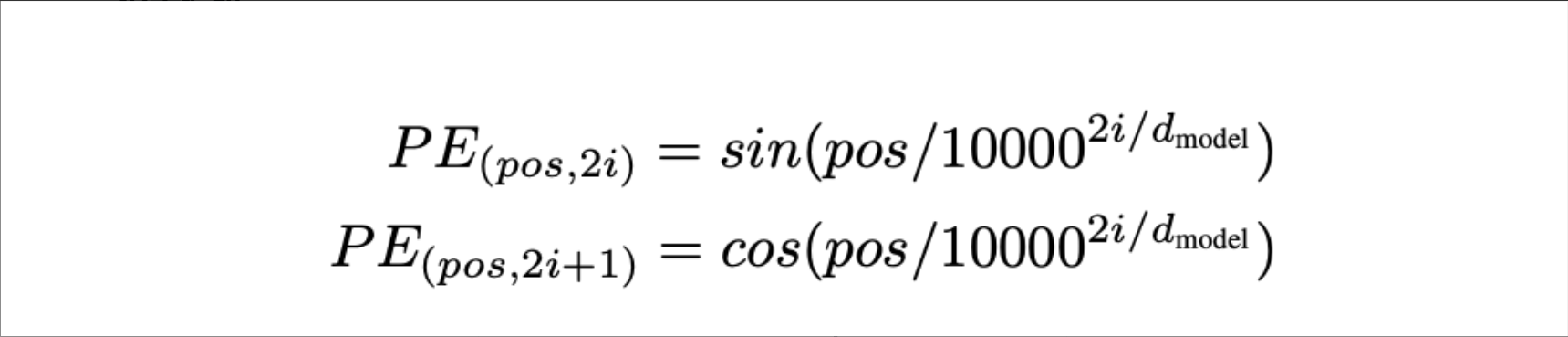
关键点:位置信息是加性融合,非拼接。
② 多头自注意力机制( MHA)
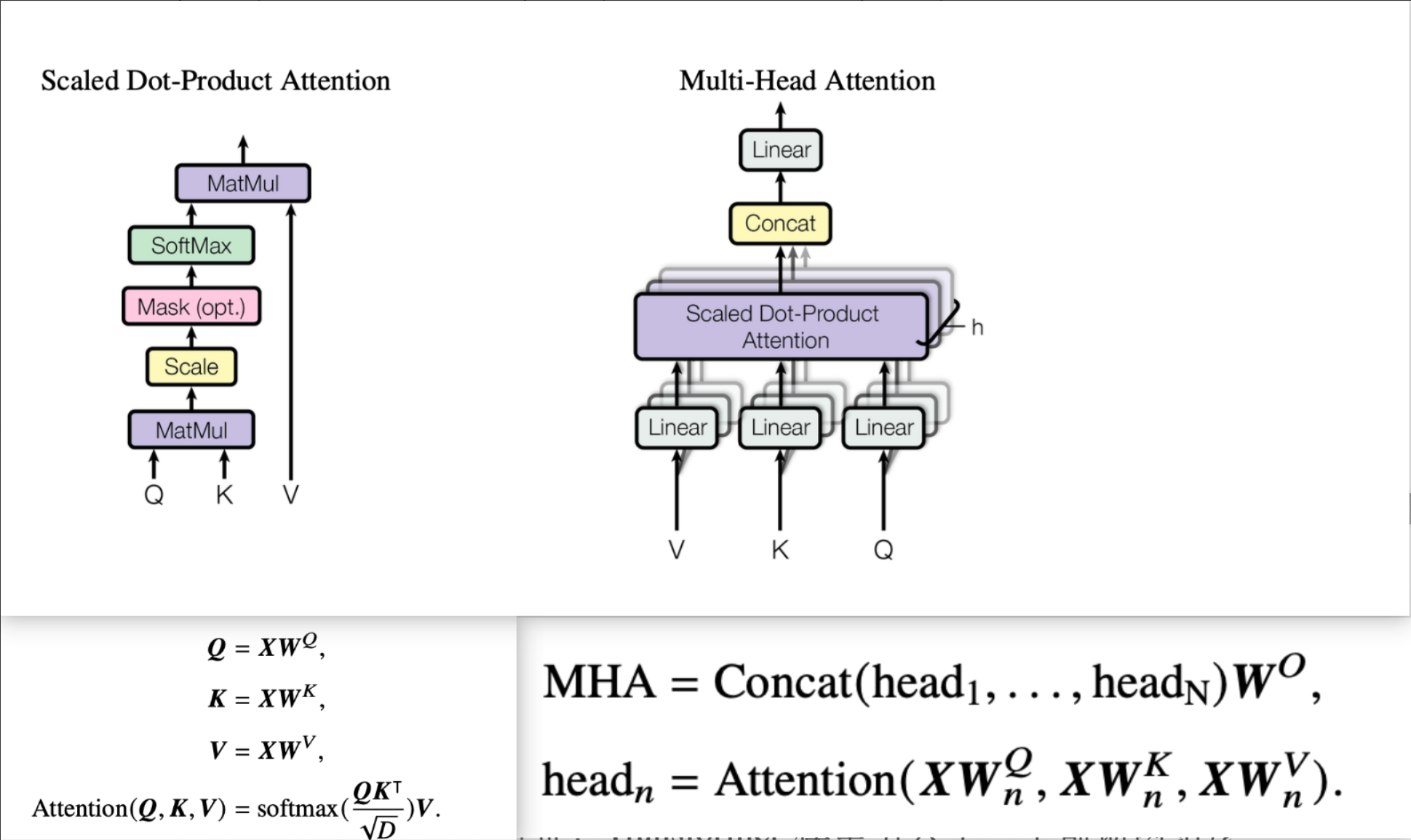
- 作用:让模型在不同子空间关注不同特征(如语法、语义、指代等)。
- 流程:
- 对输入线性变换得到 Q, K, V
- 基于公式计算注意力分数
- 多头拼接后线性投影
- 优势:
- 每个线性子空间分别计算注意力机制,每个子空间可以关注不同的特征,这样特征表能力更强。(核心优势)
- 支持并行计算
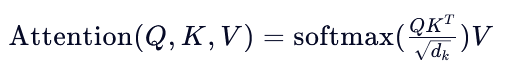
③ 前馈神经网络( FFN)
- 每个位置独立经过两层全连接 + ReLU(或 GELU)
- 公式: FFN(x)=W_2(ReLU(W_1x+b_1))+b_2
- 作用:引入非线性,增强特征提取能力
④ 残差连接 + 层归一化(Residual + LayerNorm)
- 每个子层(MHA / FFN)后接:
- 残差连接: x+Sublayer(x) → 缓解梯度消失
- Layer Normalization:对数据进行重新放缩,提升模型的训练稳定性。
注意: 一般优先进行层归一化,将输入的数据落到损失函数效果明显的范围内
⑤ 解码器特有机制
(1) 掩码多头自注意力(Masked MHA)
- 目的:防止模型在生成第 t 个词时“偷看”未来词( t+1,t+2,…t+1,t+2,… )
- 实现:在 Attention 的 softmax 前,对未来位置加 −∞−∞ (即 mask 掉)
(2) 交叉注意力(Cross-Attention)
- Query 来自 Decoder,Key/Value 来自 Encoder 最终输出
- 作用:让解码器动态关注输入序列的相关部分(类似“软对齐”)
二、大模型架构总结对比
| 模型 | 架构 | 预训练任务 | 典型用途 |
|---|---|---|---|
| BERT | Encoder-only | Masked LM + NSP | 文本分类、NER、问答 |
| GPT | Decoder-only | 自回归语言建模 | 文本生成、对话、代码 |
| T5 | Encoder-Decoder | Text-to-Text(统一输入输出格式) | 翻译、摘要、推理 |
💡 关键洞察:
- Encoder 强在“理解”,Decoder 强在“生成”
- 现代大模型(如 LLaMA、Qwen)多采用 Decoder-only,因其更适合规模化和生成任务
三、BERT(Encoder-only架构)
一句话定义
BERT(Bidirectional Encoder Representations from Transformers)是 Google 于 2018 年提出的基于 Transformer Encoder 的双向预训练语言模型,在 11 项 NLP 任务上刷新 SOTA,成为 NLP 里程碑。
- 在 SQuAD 1.1 阅读理解任务上超越人类表现
- GLUE 基准:80.4%(+7.6%)
- MultiNLI:86.7%(+5.6%)
- 关键突破:首次实现深度双向上下文建模(此前模型多为单向或浅层双向)
1. 整体架构
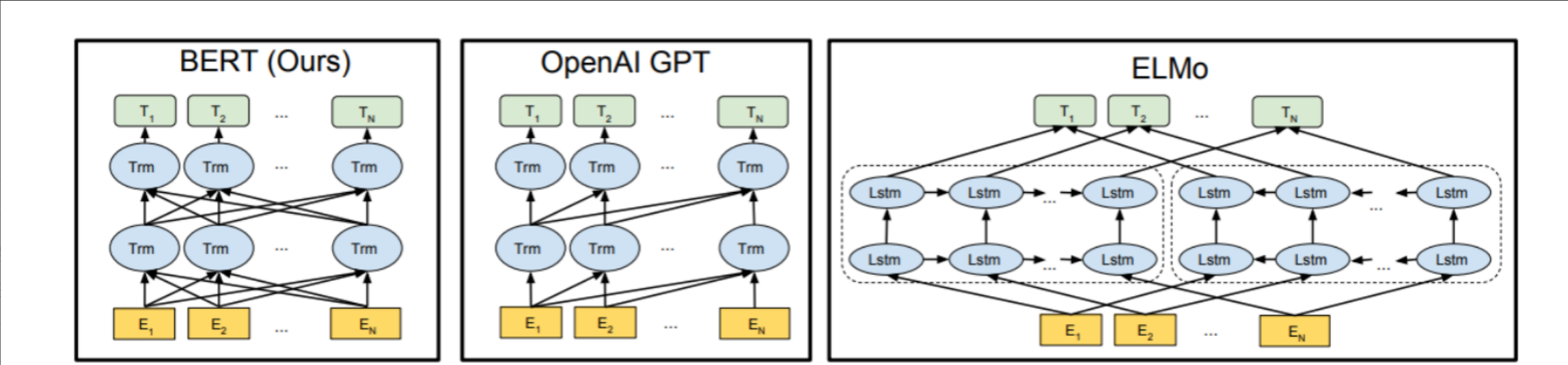
BERT = Embedding 层 + 多层 Transformer Encoder + 任务特定头
| 模块 | 作用 |
|---|---|
| Embedding | 词、句、位置三重嵌入融合 |
| Transformer Encoder | 多头注意力 + FFN + LayerNorm,堆叠 L 层 |
| Task Head(微调头) | 根据下游任务接不同输出层 |
BERT 是 Encoder-only 架构,无 Decoder,不用于文本生成。
2. 输入表示
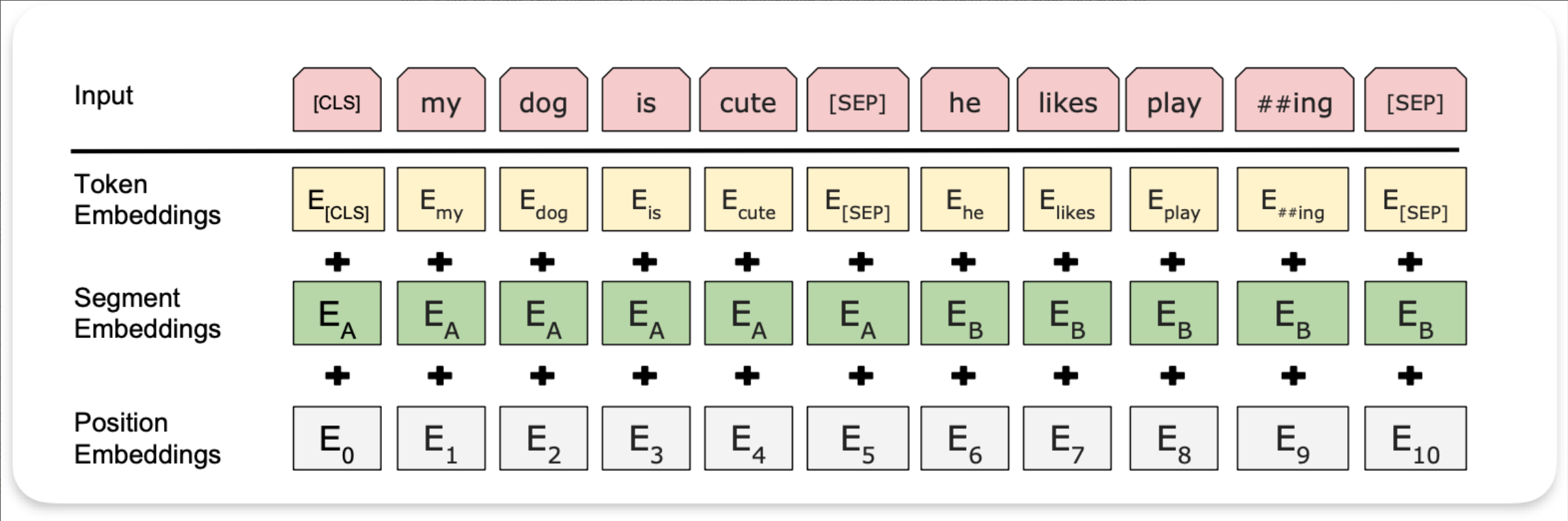
对输入序列(如 [CLS] 句子A [SEP] 句子B [SEP]),
每个 token 的最终输入为:Input=Token Emb + Segment Emb + Position Emb
| 嵌入类型 | 说明 |
|---|---|
| Token Embeddings(词嵌入张量) | 词表映射;第一个单词 为 [CLS],用于分类 |
| Segment Embeddings(句子分段嵌入张量) | 区分句子 A/B(0/1),支持句子对任务 |
| Position Embeddings(位置嵌入张量) | 可学习****的位置编码(非 Transformer 原版的三角函数) |
💡 所有 embedding 维度相同(如
bert-base为 768),直接相加。
3. Transformer Encoder 关键组件
(1) 多头自注意力(Multi-Head Self-Attention)
- 每个头独立计算 Q/K/V,捕获不同语义关系(如指代、修饰、主谓等)
- 多头拼接后线性投影
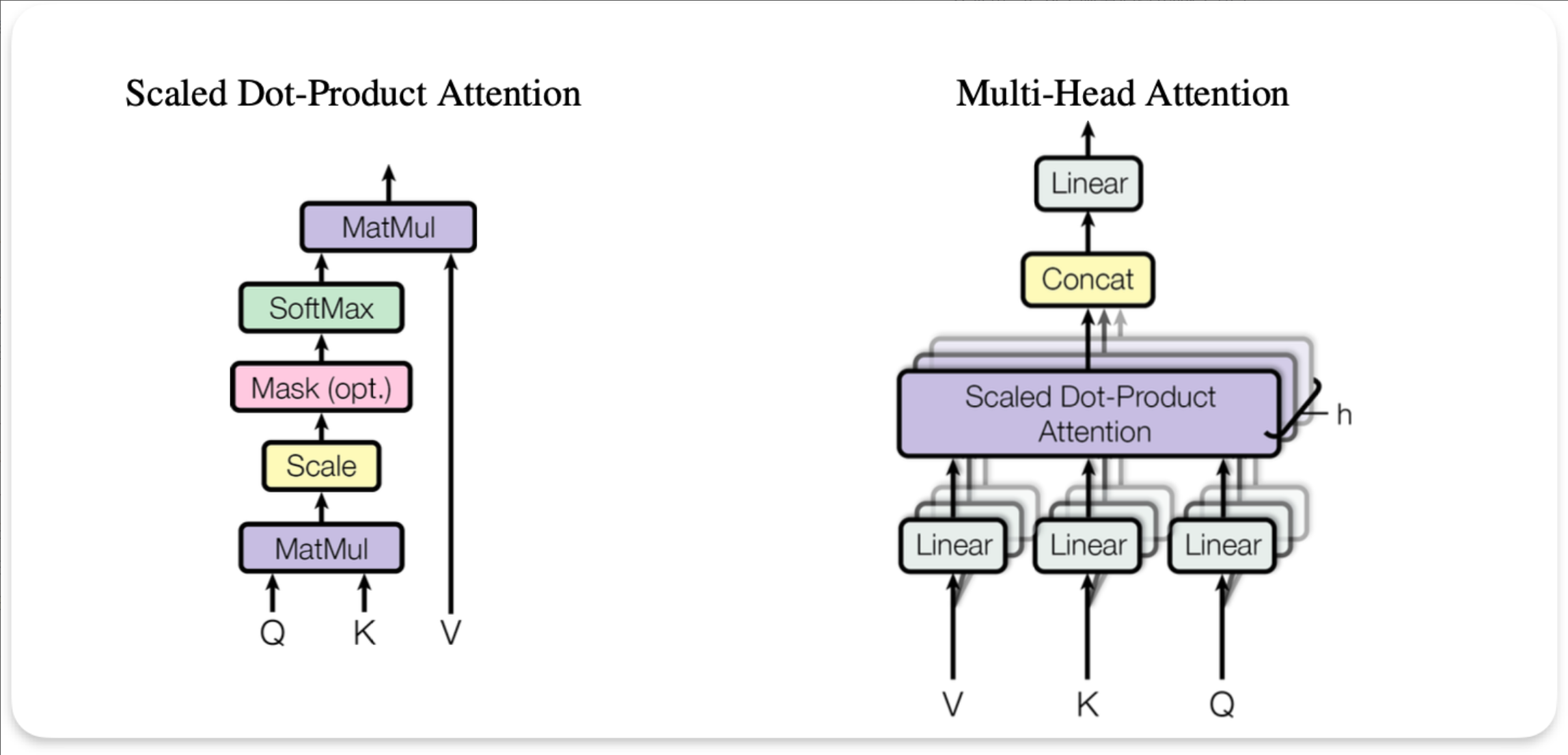
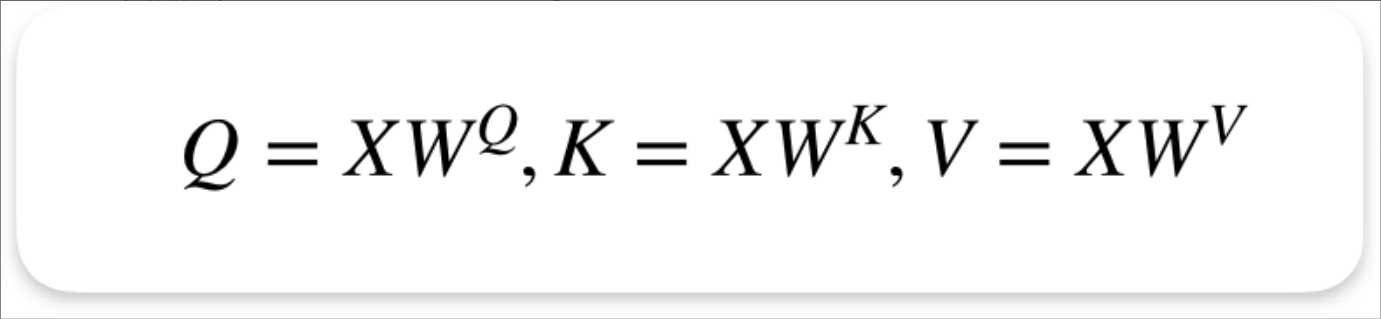
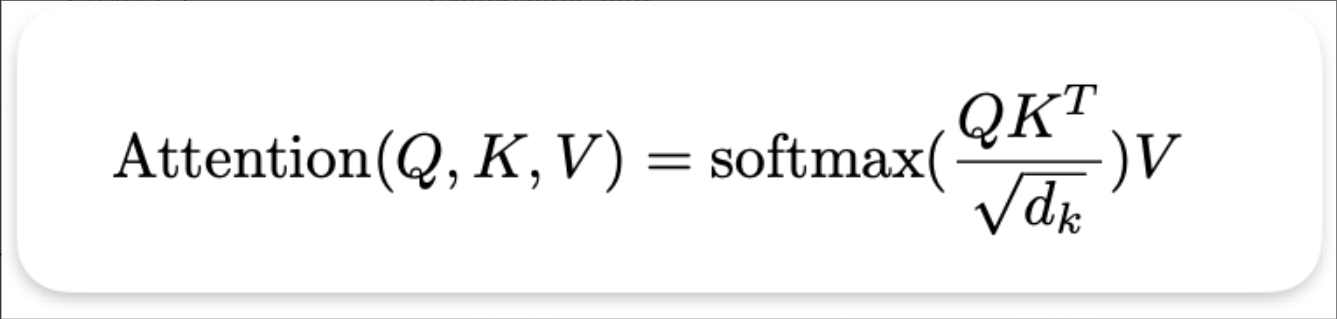

(2) 前馈网络(FFN)
- 结构:
Linear → GELU → Linear - 中间维度扩大(如 768 → 3072 → 768)
(3) 激活函数:GELU(非 ReLU)
“BERT 使用 GELU 而不是 ReLU,主要是因为 GELU 是一种更平滑的激活函数,在负值区域不会像 ReLU 那样直接截断为零,而是以概率方式保留部分信息。这有助于梯度流动,提升训练稳定性,尤其在深层 Transformer 结构中效果更好。而 ReLU 在负区梯度为零,容易导致神经元‘死亡’,影响模型表达能力。”
| 对比项 | ReLU | GELU |
|---|---|---|
| 负值处理 | 硬截断为 0 | 概率性保留(基于高斯 CDF) |
| 平滑性 | 不连续 | 光滑可导 |
| 表达能力 | 较弱 | 更强,训练更稳定 |
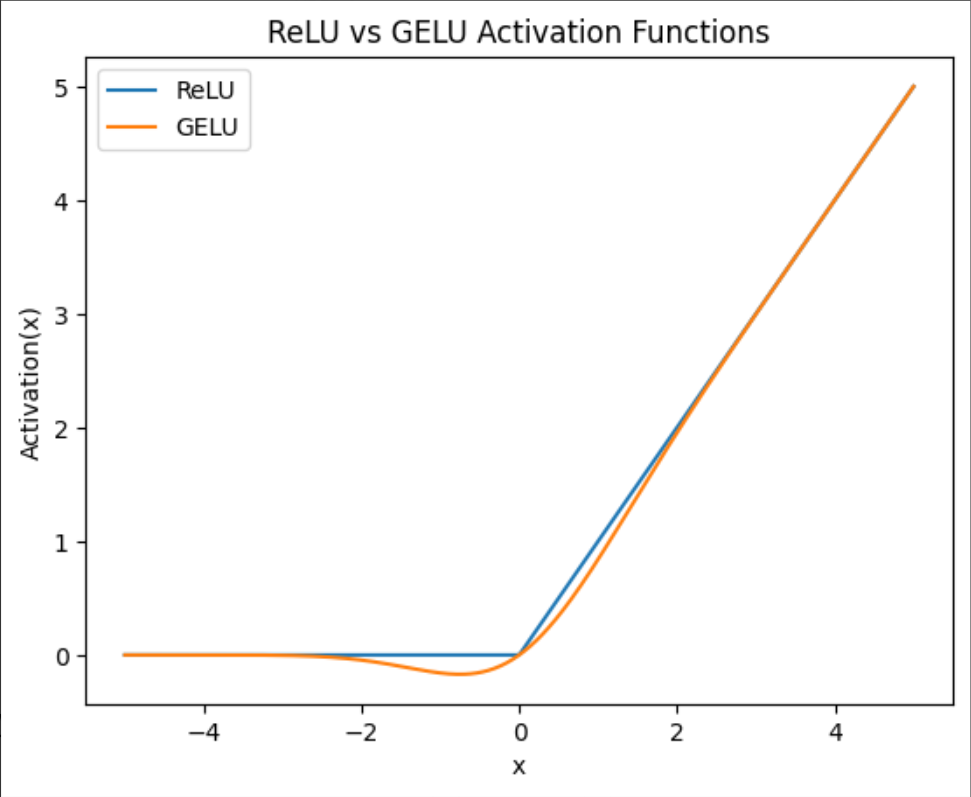
横坐标(X 轴):输入值(加权求和后的值) x
纵坐标(Y 轴):激活输出 Activation(x)
面试金句:
“BERT 使用 GELU 激活函数,它是一种平滑的概率门控机制,在负值区域保留部分信息,相比 ReLU 更有利于深层模型训练。”
(4) Layer Normalization + Dropout
- 每个子层后接 残差连接 + LayerNorm
- 默认 dropout = 0.1,提升泛化
4. 预训练任务(两大目标)
(1) Masked Language Model(MLM) —— “完形填空”
- 随机 选取 15% 的 token(80%→[MASK], 10%→随机词, 10%→原词)
- 训练目标:根据上下文预测被 mask 的原始词
- (核心) 实现双向上下文建模
2. Next Sentence Prediction(NSP) —— 句子关系判断
- 输入:
[CLS] 句子A [SEP] 句子B [SEP] - 标签:IsNext(正样本) / NotNext(负样本,随机采样)
- (核心) 提升模型对句子间逻辑的理解(如问答、推理)
后续研究(如 RoBERTa)发现 NSP 作用有限,常被弃用。
5. 下游任务微调(Fine-tuning)
什么是下游任务?
只要是基于一个已经预训练好的模型(如 BERT、GPT、Qwen 等)去完成某个具体目标,那么所做的工作通常就属于“下游任务”。
- 起点是预训练模型(不是从零训练)
- 目标是解决具体问题(如分类、生成、检测等)
- 通常涉及微调(fine-tuning)、提示(prompting)、适配器(adapter)或推理(inference)等操作
BERT 通过替换顶部任务头适配不同任务,所有参数端到端微调。
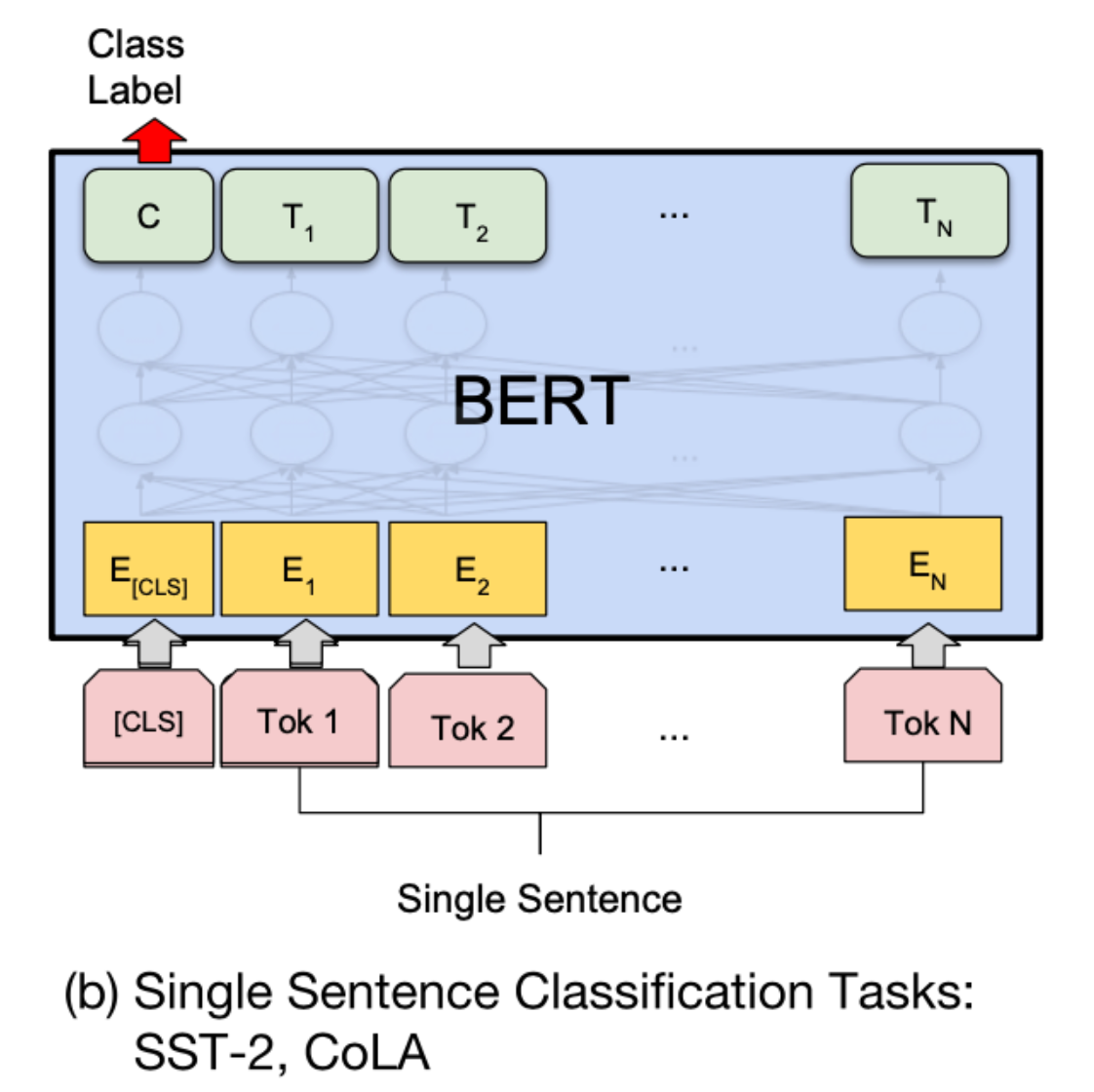
1. 单句分类任务
(1) 应用的任务包括
- 意图识别
- 新闻文本分类
- 情感分类
(2) 计算原理
- 取[CLS]向量,维度为[B, H]
- 接入分类层,本质上做线形变换W∈RH×CW\in \mathbb R ^{H\times C}W∈RH×C
- 最终激活函数使用softmax/sigmoid,得到归一化概率
- 概率最大的作为分类标签
(3) 微调方式:取 [CLS] 向量 → 分类层(Linear + Softmax)
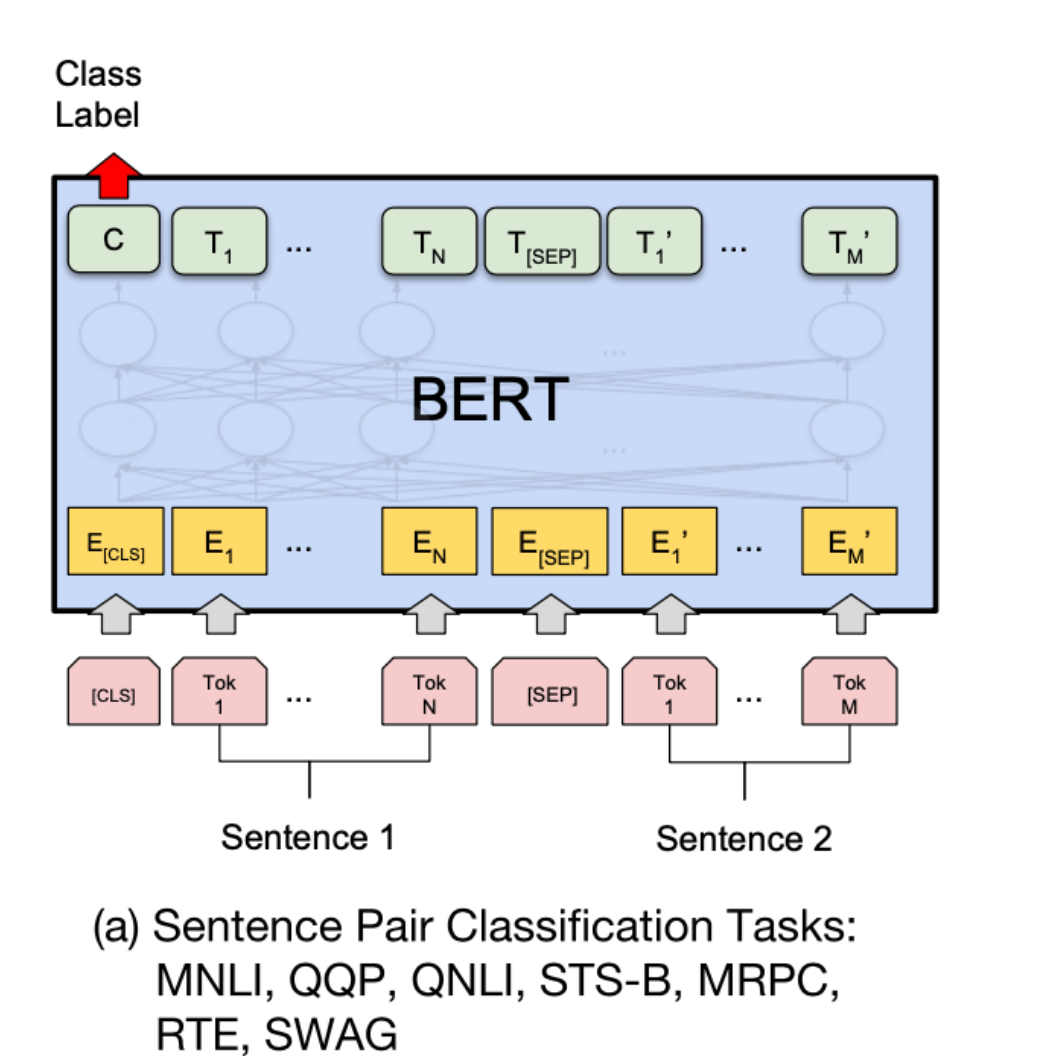
2. 句子对分类任务
(1) 应用的任务包括
- 句子对的相似度计算
- 文本是否匹配
(2) 计算原理
- 取[CLS]向量,维度为[B, H]
- 接入分类层,本质上做线形变换$ W\in \mathbb R ^{H\times C} $
- 最终激活函数使用softmax/sigmoid,得到归一化概率
- 概率最大的作为分类标签
(3) 微调方式:取 [CLS] 向量 → 分类层(Linear + Softmax),输入为 [CLS] A [SEP] B [SEP]
3. 序列标注任务
序列标注任务就是给一个序列,对序列中的每个位置预测一个标签
例如针对实体识别任务,需要抽取出一个句子中包含有哪些实体,实体通常指定义的一个特殊关键词,例如地点、人名、机构名称等,针对NER任务有多种标注方式,这里采用BIO进行标注进行说明,其中“B”表示实体开始,“I”表示实体内部,“O”表示其他不是实体的部分。
(1) 应用的任务包括
- 实体识别NER、分词、词性标注
(2)计算原理
- 取每个token向量,维度为[B, L, H]
- 接入分类层,本质上做线形变换$ W\in \mathbb R ^{H\times C} $
- 最终激活函数使用softmax/sigmoid,得到归一化概率
- 针对token分类,概率最大的作为分类标签
(3) 微调方式: 取每个 token 的输出向量 → 分类层
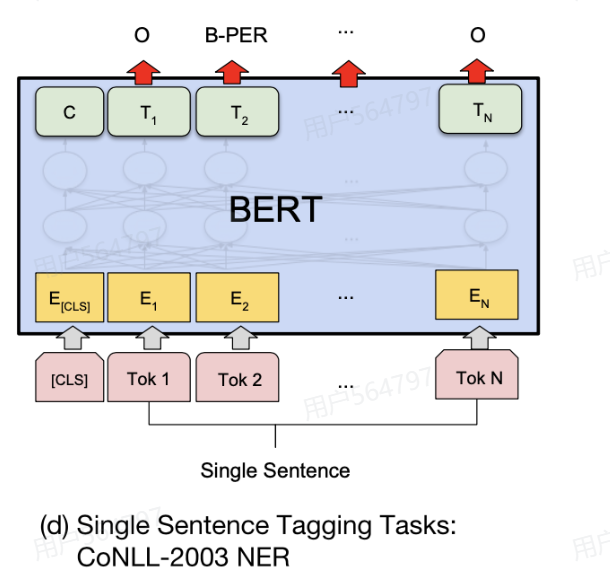
4. 基于原文的问答任务(BERT不常用,有更好的)
微调方式: 预测答案起止位置(两个全连接层分别预测 start/end)
所有任务只需微调 1~3 个 epoch,收敛快,效果好。
5. 代码示例
from transformers import BertTokenizer, BertForSequenceClassification
# 从hugging face上下载模型
model_path = "models/bert-base-chinese"
# 加载分词器
tokenizer = BertTokenizer.from_pretrained(model_path)
# 加载分类模型
model = BertForSequenceClassification.from_pretrained(model_path, num_labels=5)
print(model)
BertForSequenceClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSdpaSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, inplace=False)
(classifier): Linear(in_features=768, out_features=5, bias=True)
)
6. 分类任务
inputs = "hello world!"
inputs = tokenizer(inputs, return_tensors='pt')
output = model(**inputs) ## 前向传播
logits = output.logits # 未归一化的概率
# 取概率最大的标签,就是分类标签
logits.argmax()
7. MLM任务
from transformers import BertForMaskedLM
mlm = BertForMaskedLM.from_pretrained(model_path)
mlm_inputs = "[MASK]京是中国的首都"
mlm_inputs = tokenizer(mlm_inputs, return_tensors='pt')
output = mlm(**mlm_inputs)
logits = output.logits
index = 1 # [MASK] 位置在1索引
logits[:, index, :]
mlm_input_id = logits[:, index, :].argmax()
tokenizer.decode(mlm_input_id)
# [MASK] ===> 北
四、T5(Encoder-Decoder架构)
- 提出时间:2020年7月(Google)
- 核心思想:统一所有 NLP 任务为“文本到文本”(Text-to-Text)格式
- 例如:翻译任务输入为
"translate English to German: That is good.",输出为"Das ist gut." - 所有任务(分类、问答、相似度等)都用相同模型结构、损失函数和解码方式处理。
- 例如:翻译任务输入为
- 模型架构:
- 基于标准 Encoder-Decoder Transformer
- 主要改动:
- 使用简化版 LayerNorm(无 bias,放在残差连接外)
- 采用相对位置编码(标量形式,共享于各层,每头独立学习)
- 最多支持 128 的相对位置距离(共 32 个可学习位置 embedding)
- 训练方式:
- 自监督预训练:类似 BERT 的 MLM(掩码语言建模)
- 多任务联合微调:在多个有标注任务(如 SQuAD、翻译)上同时训练
- 优点:
- 任务统一,框架简洁
- 参数效率高,训练更快
- 可在较小数据集上有效微调
- 缺点:
- 依赖大量计算资源(因基于完整 Transformer)
五、GPT(Decoder-only架构)
- 提出时间:2018年6月(OpenAI)
- 核心思想:单向生成式语言模型 + 下游任务微调
- 模型架构:
- 仅使用 Transformer 的 Decoder 部分
- 采用 掩码自注意力(Masked Self-Attention),确保预测时只依赖左侧上下文(单向)
- 输入 = 词嵌入 + 位置编码
- 训练方式:
- 两阶段训练:
- 无监督预训练:最大化序列的自回归似然(预测下一个词)
- 有监督微调:针对具体任务(分类、问答等)添加任务特定的输入格式和分类头
- 两阶段训练:
- 任务适配示例:
- 分类:加
[START]和[END]token - 文本蕴含:用分隔符拼接前提与假设
- 多选题:将每个选项与题干分别拼接,取最高置信度
- 分类:加
- 优点:
- 在 12 项任务中 9 项超越当时 SOTA
- 利用 Transformer 捕捉长距离依赖,且易于并行训练
- 缺点:
- 单向建模,无法利用右侧上下文(相比 BERT 是劣势)
- 每个下游任务需单独设计输入格式和微调策略,不够统一.
一句话总结:
T5 把所有任务变成“填空题”,GPT 把所有任务变成“续写题”。
六、本小节面试可能会出现的问题
一、Transformer 架构
Q6:Transformer 的三大组件是什么?
A:多头自注意力(MHA)、前馈网络(FFN)、残差连接 + LayerNorm。
Q7:Decoder 为什么需要掩码注意力?
A:防止训练时“偷看”未来词,保证自回归生成的因果性。
Q8:位置编码的作用是什么?
A:为模型引入词序信息,因为 Transformer 本身对输入顺序不敏感。
Q9:Encoder-only、Decoder-only、Encoder-Decoder 各代表什么模型?
A:BERT(理解)、GPT(生成)、T5(翻译/摘要)。
二、BERT 相关
Q10:BERT 为什么能实现双向上下文?
A:通过 MLM(掩码语言模型)任务,同时利用左右上下文预测被 mask 的词。
Q11:BERT 的输入由哪三部分组成?
A:Token Embedding + Segment Embedding + Position Embedding(三者相加)。
Q12:[CLS] token 的作用是什么?
A:聚合整句语义,用于句子级分类任务。
Q13:BERT 为什么用 GELU 而不是 ReLU?
A:GELU 更平滑,在负区保留梯度,训练更稳定;ReLU 在负区梯度为零,易导致神经元死亡。
Q14:NSP 任务是什么?现在还重要吗?
A:判断两个句子是否连续。后续研究(如 RoBERTa)发现其作用有限,常被弃用。
Q15:BERT 能直接做文本生成吗?
A:不能,它是 Encoder-only 架构,无自回归生成能力。
三、大模型基础
Q16:大语言模型(LLM)相比传统 LM 有什么突破?
A:涌现能力(如上下文学习)、few-shot 推理、更强的泛化和生成能力。
Q17:预训练 + 微调范式的核心思想是什么?
A:先在海量无标签数据上学通用表示,再在下游任务上小样本适配。
Q18:HumanEval 评测什么?
A:评测模型根据描述生成可运行、正确代码的能力,通过单元测试验证。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 31
31 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)