李哥深度学习 第五节 图像分类实战
本次实战是一个食物分类任务,我们要让许多模型学习食物图片数据,然后进行分类。本次实战会采用模块化思想,通过data.py model.py train.py 和main.py四个python模块进行编写,其实思路基本就是第三节 回归实战的升级拓展,所以如果出现重复内容就不赘述了。这是监督学习模型的数据类,它包含基本三要素 init ,getitem , len,以及一个读文件方法readfilei
这节偷了个懒本来不想写了,但是不写又一直挂念着,所以还是补上吧╮(╯-╰)╭
一、任务概述
本次实战是一个食物分类任务,我们要让许多模型学习食物图片数据,然后进行分类。
本次实战会采用模块化思想,通过data.py model.py train.py 和main.py四个python模块进行编写,其实思路基本就是第三节 回归实战的升级拓展,所以如果出现重复内容就不赘述了。
二、数据准备
打开文件目录,我们可以发现数据集的训练集、验证集和测试集已经提前被放到不同的文件夹里了,而不是乱作一大坨,这样就不需要我们手动划分了。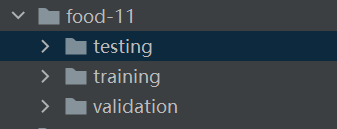
观察文件结构,发现标签可以从文件夹名称或者图片名中获取。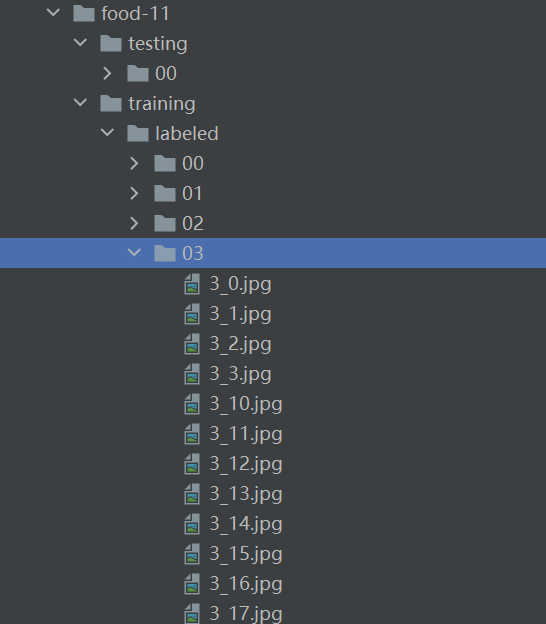
对了,我们还会发现training文件夹下有一个unlabeled文件夹,是给半监督模型用的。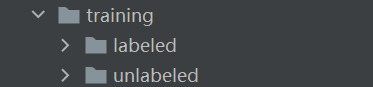
这样,数据我们就大致了解了,接下来开始编写代码。
三、data 模块
这个模块主要用于定义数据类和实现loader加载器
全部代码👇
import numpy as np
from torch.utils.data import Dataset,DataLoader
import torch
from sklearn.model_selection import train_test_split
import os
import cv2
from torchvision.transforms import transforms,autoaugment
from tqdm import tqdm
import random
from PIL import Image
import matplotlib.pyplot as plt
HW = 224
imagenet_norm = [[0.485, 0.456, 0.406],[0.229, 0.224, 0.225]]
test_transform = transforms.Compose([
transforms.ToTensor(),
]) # 测试集只需要转为张量
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(HW),
transforms.RandomHorizontalFlip(),
autoaugment.AutoAugment(),
transforms.ToTensor(),
# transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]) # 训练集需要做各种变换。 效果参见https://pytorch.org/vision/stable/transforms.html
class foodDataset(Dataset): #数据集三要素: init , getitem , len
def __init__(self, path, mode):
y = None
self.transform = None
self.mode = mode
pathDict = {'train':'training/labeled','train_unl':'training/unlabeled', 'val':'validation', 'test':'testing'}
imgPaths = path +'/'+ pathDict[mode] # 定义路径
if mode == 'test':
x = self._readfile(imgPaths,label=False)
self.transform = test_transform #从文件读数据,测试机和无标签数据没有标签, trans方式也不一样
elif mode == 'train':
x, y =self._readfile(imgPaths,label=True)
self.transform = train_transform
elif mode == 'val':
x, y =self._readfile(imgPaths,label=True)
self.transform = test_transform
elif mode == 'train_unl':
x = self._readfile(imgPaths,label=False)
self.transform = train_transform
if y is not None: # 注意, 分类的标签必须转换为长整型: int64.
y = torch.LongTensor(y)
self.x, self.y = x, y
def __getitem__(self, index): # getitem 用于根据标签取数据
orix = self.x[index] # 取index的图片
if self.transform == None:
xT = torch.tensor(orix).float()
else:
xT = self.transform(orix) # 如果规定了transformer, 则需要transf
if self.y is not None: # 有标签, 则需要返回标签。 这里额外返回了原图, 方便后面画图。
y = self.y[index]
return xT, y, orix
else:
return xT, orix
def _readfile(self,path, label=True): # 定义一个读文件的函数
if label: # 有无标签, 文件结构是不一样的。
x, y = [], []
for i in tqdm(range(11)): # 有11类
label = '/%02d/'%i # %02必须为两位。 符合文件夹名字
imgDirpath = path+label
imglist = os.listdir(imgDirpath) # listdir 可以列出文件夹下所有文件。
xi = np.zeros((len(imglist), HW, HW, 3), dtype=np.uint8)
yi = np.zeros((len(imglist)), dtype=np.uint8) # 先把放数据的格子打好。 x的维度是 照片数量*H*W*3
for j, each in enumerate(imglist):
imgpath = imgDirpath + each
img = Image.open(imgpath) # 用image函数读入照片, 并且resize。
img = img.resize((HW, HW))
xi[j,...] = img #在第j个位置放上数据和标签。
yi[j] = i
if i == 0:
x = xi
y = yi
else:
x = np.concatenate((x, xi), axis=0) # 将11个文件夹的数据合在一起。
y = np.concatenate((y, yi), axis=0)
print('读入有标签数据%d个 '%len(x))
return x, y
else:
imgDirpath = path + '/00/'
imgList = os.listdir(imgDirpath)
x = np.zeros((len(imgList), HW, HW ,3),dtype=np.uint8)
for i, each in enumerate(imgList):
imgpath = imgDirpath + each
img = Image.open(imgpath)
img = img.resize((HW, HW))
x[i,...] = img
return x
def __len__(self): # len函数 负责返回长度。
return len(self.x)
class noLabDataset(Dataset):
def __init__(self,dataloader, model, device, thres=0.85):
super(noLabDataset, self).__init__()
self.model = model #模型也要传入进来
self.device = device
self.thres = thres #这里置信度阈值 我设置的 0.99
x, y = self._model_pred(dataloader) #核心, 获得新的训练数据
if x == []: # 如果没有, 就不启用这个数据集
self.flag = False
else:
self.flag = True
self.x = np.array(x)
self.y = torch.LongTensor(y)
# self.x = np.concatenate((np.array(x), train_dataset.x),axis=0)
# self.y = torch.cat(((torch.LongTensor(y),train_dataset.y)),dim=0)
self.transformers = train_transform
def _model_pred(self, dataloader):
model = self.model
device = self.device
thres = self.thres
pred_probs = []
labels = []
x = []
y = []
with torch.no_grad(): # 不训练, 要关掉梯度
for data in dataloader: # 取数据
imgs = data[0].to(device)
pred = model(imgs) #预测
soft = torch.nn.Softmax(dim=1) #softmax 可以返回一个概率分布
pred_p = soft(pred)
pred_max, preds = pred_p.max(1) #得到最大值 ,和最大值的位置 。 就是置信度和标签。
pred_probs.extend(pred_max.cpu().numpy().tolist())
labels.extend(preds.cpu().numpy().tolist()) #把置信度和标签装起来
for index, prob in enumerate(pred_probs):
if prob > thres: #如果置信度超过阈值, 就转化为可信的训练数据
x.append(dataloader.dataset[index][1])
y.append(labels[index])
return x, y
def __getitem__(self, index): # getitem 和len
x = self.x[index]
x= self.transformers(x)
y = self.y[index]
return x, y
def __len__(self):
return len(self.x)
def get_semi_loader(dataloader,model, device, thres):
semi_set = noLabDataset(dataloader, model, device, thres)
if semi_set.flag: #不可用时返回空
dataloader = DataLoader(semi_set, batch_size=dataloader.batch_size,shuffle=True)
return dataloader
else:
return None
def getDataLoader(path, mode, batchSize):
assert mode in ['train', 'train_unl', 'val', 'test']
dataset = foodDataset(path, mode)
if mode in ['test','train_unl']:
shuffle = False
else:
shuffle = True
loader = DataLoader(dataset,batchSize,shuffle=shuffle) #装入loader
return loader
def samplePlot(dataset, isloader=True, isbat=False,ori=None): #画图, 此函数不需要掌握。
if isloader:
dataset = dataset.dataset
rows = 3
cols = 3
num = rows*cols
# if isbat:
# dataset = dataset * 225
datalen = len(dataset)
randomNum = []
while len(randomNum) < num:
temp = random.randint(0,datalen-1)
if temp not in randomNum:
randomNum.append(temp)
fig, axs = plt.subplots(nrows=rows,ncols=cols,squeeze=False)
index = 0
for i in range(rows):
for j in range(cols):
ax = axs[i, j]
if isbat:
ax.imshow(np.array(dataset[randomNum[index]].cpu().permute(1,2,0)))
else:
ax.imshow(np.array(dataset[randomNum[index]][0].cpu().permute(1,2,0)))
index += 1
ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
plt.show()
plt.tight_layout()
if ori != None:
fig2, axs2 = plt.subplots(nrows=rows,ncols=cols,squeeze=False)
index = 0
for i in range(rows):
for j in range(cols):
ax = axs2[i, j]
if isbat:
ax.imshow(np.array(dataset[randomNum[index]][-1]))
else:
ax.imshow(np.array(dataset[randomNum[index]][-1]))
index += 1
ax.set(xticklabels=[], yticklabels=[], xticks=[], yticks=[])
plt.show()
plt.tight_layout()
if __name__ == '__main__': #运行的模块, 如果你运行的模块是当前模块
print("你运行的是data.py文件")
filepath = '../food-11_sample'
train_loader = getDataLoader(filepath, 'train', 8)
for i in range(3):
samplePlot(train_loader,True,isbat=False,ori=True)
val_loader = getDataLoader(filepath, 'val', 8)
for i in range(100):
samplePlot(val_loader,True,isbat=False,ori=True)
##########################
3.1 foodDataset 类
class foodDataset(Dataset): #数据集三要素: init , getitem , len
def __init__(self, path, mode):
def __getitem__(self, index): # getitem 用于根据标签取数据
def _readfile(self,path, label=True): # 定义一个读文件的函数
def __len__(self): # len函数 负责返回长度。
3.1.1 foodDataset 概述
这是监督学习模型的数据类,它包含基本三要素 init ,getitem , len,以及一个读文件方法readfile
- init 用于接收参数,它主要被设计用来读取你在不同情况下所需要的不同数据文件
- getitem 实现容器协议,使对象支持索引操作 obj[key])
- len 实现长度协议,使对象支持 len() 函数
- readfile 方法用于协助init读文件,不是必须的方法
其实这个类封装完毕后,从“外界”调用视角来看,我们能做的就是:
- 传参,这个是init 的功劳;
- 按索引随机选取,比如下面的samplePlot画图函数里有这么一句:
ax.imshow(np.array(dataset[randomNum[index]].cpu().permute(1,2,0)))
当你看到dataset[xxxxxx]的时候就会发现,这不是列表嘛!是的,这就是魔术方法getitem
- 获取长度,还是samplePlot画图函数里有这么一句:
datalen = len(dataset)
就是让dataset可以通过len函数获取长度
你不觉得定义了上面的魔术方法后,操作被非常优雅地简化了吗?这就是我们的目的之一
3.1.2 init 方法
def __init__(self, path, mode):
y = None
self.transform = None
self.mode = mode
pathDict = {'train':'training/labeled','train_unl':'training/unlabeled', 'val':'validation', 'test':'testing'}
imgPaths = path +'/'+ pathDict[mode] # 定义路径
if mode == 'test':
x = self._readfile(imgPaths,label=False)
self.transform = test_transform #从文件读数据,测试机和无标签数据没有标签, trans方式也不一样
elif mode == 'train':
x, y =self._readfile(imgPaths,label=True)
self.transform = train_transform
elif mode == 'val':
x, y =self._readfile(imgPaths,label=True)
self.transform = test_transform
elif mode == 'train_unl':
x = self._readfile(imgPaths,label=False)
self.transform = train_transform
if y is not None: # 注意, 分类的标签必须转换为长整型: int64.
y = torch.LongTensor(y)
self.x, self.y = x, y
初始化属性
init 初始化了foodDataset的四个属性,分别是self.x self.y self.transform self.mode,self.mode直接等于参数mode即可,self.x self.y self.transform使用了分支结构来赋值
- self.x和self.y就是数据和数据标签,我们使用_readfile函数读取x和y(后面会解释_readfile),'test’和’train_unl’没有标签y,而’train’和’val’有,因此产生分支
- self.transform存储了数据增强处理的流程,在’train’和’train_unl’下,赋为train_transform,在’test’和’val’下,赋为test_transform。其实也很好理解,在训练时数据可以通过各种各样的变换来扩充模型,而验证和测试时就不需要,没意义。下面是增强管道的设置,在非训练时只转换为tensor型数据。
test_transform = transforms.Compose([
transforms.ToTensor(),
]) # 测试集只需要转为张量
train_transform = transforms.Compose([
transforms.ToPILImage(),
transforms.RandomResizedCrop(HW),
transforms.RandomHorizontalFlip(),
autoaugment.AutoAugment(),
transforms.ToTensor(),
# transforms.Normalize([0.485,0.456,0.406],[0.229,0.224,0.225])
]) # 训练集需要做各种变换。 效果参见https://pytorch.org/vision/stable/transforms.html
讨论几个问题:
-
可以看到self.y在初始化时就被设置为tensor型数据,可是self.x一直到被切片训练时才被转换为tensor,为什么不早转换?
-
这样就是只在训练时把数据转换为tensor,作为临时变量用完即销毁,存储的一直是ndarry,所以节省了内存,tensor占用的内存是巨大的,x全部存为tensor可能会把内存爆掉
-
self.x是被强化后进行了训练,那原图有被训练到吗?
-
并没有,在train.py中,x, target = data[0].to(device), dadta[1].to(device),我们取了data的第一个0和1维度的数据作为x和target,data是由train_loader提供的打包数据,而train_loader通过dataset的__getitem__魔术方法获取数据,在有标签时返回 xT, y, orix,批次数据是 (batch_xT, batch_y, batch_orix),无标签时返回 xT, orix ,批次数据是 (batch_xT, batch_orix),所以orix没有参与训练。这里保留下来可能是对于写模型时打印测试数据有帮助?
-
而且,强化后的数据比原图好用,所以替换了
路径头准备
读数据时,可以发现数据路径由[共同部分]+[训练模式]组成,所以做了个字典映射一下训练模式,然后拼接成具体路径传入_readfile
3.2 getDataLoader 方法
def getDataLoader(path, mode, batchSize):
assert mode in ['train', 'train_unl', 'val', 'test']
dataset = foodDataset(path, mode)
if mode in ['test','train_unl']:
shuffle = False
else:
shuffle = True
loader = DataLoader(dataset,batchSize,shuffle=shuffle) #装入loader
return loader
一个DataLoader 方法,返回一个loader,用于提供batchsize,它将数据集封装成可迭代对象,支持批量加载、随机打乱等功能,以前介绍过这里不再赘述。
3.3 noLabDataset类和get_semi_loader类
这是半监督的数据类和loader,后面做大模型好像用不到这个,李哥说了解即可,那这里就略过了。
3.4 samplePlot画图函数
略
四、 model 模块
model模块会定义好模型框架,这里有一个李哥自己写的模型,还有一堆预训练好的模型。
模型本身不区分监督和半监督,它们的差别仅体现在数据的预处理上,当然无监督还是区分的。
import torch
import torch.nn as nn
import numpy as np
from timm.models.vision_transformer import PatchEmbed, Block
import torchvision.models as models
def set_parameter_requires_grad(model, linear_probing):
if linear_probing:
for param in model.parameters():
param.requires_grad = False # 一个参数的requires_grad设为false, 则训练时就会不更新
class MyModel(nn.Module): #自己的模型
def __init__(self,numclass = 2):
super(MyModel, self).__init__()
self.layer0 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #112*112
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #56*56
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #28*28
self.layer3 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #14*14
self.pool1 = nn.MaxPool2d(2)#7*7
self.fc = nn.Linear(25088, 512)
# self.drop = nn.Dropout(0.5)
self.relu1 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(512, numclass)
def forward(self,x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool1(x)
x = x.view(x.size()[0],-1) #view 类似于reshape 这里指定了第一维度为batch大小,第二维度为适应的,即剩多少, 就是多少维。
# 这里就是将特征展平。 展为 B*N ,N为特征维度。
x = self.fc(x)
# x = self.drop(x)
x = self.relu1(x)
x = self.fc2(x)
return x
# def model_Datapara(model, device, pre_path=None):
# model = torch.nn.DataParallel(model).to(device)
#
# model_dict = torch.load(pre_path).module.state_dict()
# model.module.load_state_dict(model_dict)
# return model
#传入模型名字,和分类数, 返回你想要的模型
def initialize_model(model_name, num_classes, linear_prob=False, use_pretrained=True):
# 初始化将在此if语句中设置的这些变量。
# 每个变量都是模型特定的。
model_ft = None
input_size = 0
if model_name =="MyModel":
if use_pretrained == True:
model_ft = torch.load('model_save/MyModel')
else:
model_ft = MyModel(num_classes)
input_size = 224
elif model_name == "resnet18":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained) # 从网络下载模型 pretrain true 使用参数和架构, false 仅使用架构。
set_parameter_requires_grad(model_ft, linear_prob) # 是否为线性探测,线性探测: 固定特征提取器不训练。
num_ftrs = model_ft.fc.in_features #分类头的输入维度
model_ft.fc = nn.Linear(num_ftrs, num_classes) # 删掉原来分类头, 更改最后一层为想要的分类数的分类头。
input_size = 224
elif model_name == "resnet50":
""" Resnet50
"""
model_ft = models.resnet50(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "googlenet":
""" googlenet
"""
model_ft = models.googlenet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
# 处理辅助网络
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# 处理主要网络
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model_utils name, exiting...")
exit()
return model_ft, input_size
def prilearn_para(model_ft,linear_prob):
# 将模型发送到GPU
device = torch.device("cuda:0")
model_ft = model_ft.to(device)
# 在此运行中收集要优化/更新的参数。
# 如果我们正在进行微调,我们将更新所有参数。
# 但如果我们正在进行特征提取方法,我们只会更新刚刚初始化的参数,即`requires_grad`的参数为True。
params_to_update = model_ft.parameters()
print("Params to learn:")
if linear_prob:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
#
# # 观察所有参数都在优化
# optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
def init_para(model):
def weights_init(model):
classname = model.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
model.apply(weights_init)
return model
4.1 MyModel 类
class MyModel(nn.Module): #自己的模型
def __init__(self,numclass = 2):
super(MyModel, self).__init__()
self.layer0 = nn.Sequential(
nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #112*112
self.layer1 = nn.Sequential(
nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #56*56
self.layer2 = nn.Sequential(
nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #28*28
self.layer3 = nn.Sequential(
nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1,bias=True),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.MaxPool2d(2)
) #14*14
self.pool1 = nn.MaxPool2d(2)#7*7
self.fc = nn.Linear(25088, 512)
# self.drop = nn.Dropout(0.5)
self.relu1 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(512, numclass)
def forward(self,x):
x = self.layer0(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.pool1(x)
x = x.view(x.size()[0],-1) #view 类似于reshape 这里指定了第一维度为batch大小,第二维度为适应的,即剩多少, 就是多少维。
# 这里就是将特征展平。 展为 B*N ,N为特征维度。
x = self.fc(x)
# x = self.drop(x)
x = self.relu1(x)
x = self.fc2(x)
return x
这是一个自定义模型类,init 定义了四个layer进行卷积,最后输出numclass个分类,forward完成了前向传播。
4.2 其他类
如何选取合适的模型不是目前的重点,重点在于了解调用这些大佬预训练好的模型我们都需要做什么。
def set_parameter_requires_grad(model, linear_probing):
if linear_probing:
for param in model.parameters():
param.requires_grad = False # 一个参数的requires_grad设为false, 则训练时就会不更新
def initialize_model(model_name, num_classes, linear_prob=False, use_pretrained=True):
# 初始化将在此if语句中设置的这些变量。
# 每个变量都是模型特定的。
model_ft = None
input_size = 0
if model_name =="MyModel":
if use_pretrained == True:
model_ft = torch.load('model_save/MyModel')
else:
model_ft = MyModel(num_classes)
input_size = 224
elif model_name == "resnet18":
""" Resnet18
"""
model_ft = models.resnet18(pretrained=use_pretrained) # 从网络下载模型 pretrain true 使用参数和架构, false 仅使用架构。
set_parameter_requires_grad(model_ft, linear_prob) # 是否为线性探测,线性探测: 固定特征提取器不训练。
num_ftrs = model_ft.fc.in_features #分类头的输入维度
model_ft.fc = nn.Linear(num_ftrs, num_classes) # 删掉原来分类头, 更改最后一层为想要的分类数的分类头。
input_size = 224
elif model_name == "resnet50":
""" Resnet50
"""
model_ft = models.resnet50(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "googlenet":
""" googlenet
"""
model_ft = models.googlenet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "alexnet":
""" Alexnet
"""
model_ft = models.alexnet(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "vgg":
""" VGG11_bn
"""
model_ft = models.vgg11_bn(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier[6].in_features
model_ft.classifier[6] = nn.Linear(num_ftrs,num_classes)
input_size = 224
elif model_name == "squeezenet":
""" Squeezenet
"""
model_ft = models.squeezenet1_0(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
model_ft.classifier[1] = nn.Conv2d(512, num_classes, kernel_size=(1,1), stride=(1,1))
model_ft.num_classes = num_classes
input_size = 224
elif model_name == "densenet":
""" Densenet
"""
model_ft = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
num_ftrs = model_ft.classifier.in_features
model_ft.classifier = nn.Linear(num_ftrs, num_classes)
input_size = 224
elif model_name == "inception":
""" Inception v3
Be careful, expects (299,299) sized images and has auxiliary output
"""
model_ft = models.inception_v3(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, linear_prob)
# 处理辅助网络
num_ftrs = model_ft.AuxLogits.fc.in_features
model_ft.AuxLogits.fc = nn.Linear(num_ftrs, num_classes)
# 处理主要网络
num_ftrs = model_ft.fc.in_features
model_ft.fc = nn.Linear(num_ftrs,num_classes)
input_size = 299
else:
print("Invalid model_utils name, exiting...")
exit()
return model_ft, input_size
可以看到思路大致就是要明确:
- **要不要使用大佬的参数:**就是调用models里的参数pretrained是否为use_pretrained
- 要不要微调:set_parameter_requires_grad是否为的参数linear_prob是否为False(这里linear_prob同时承担了微调和线性探测的开关,如果linear_prob=True,则set_parameter_requires_grad会冻上所有参数,这时候只剩后来我们自己换上的的分类头可以训练,这称为线性探测;而linear_prob=False时,所有参数均可参与训练,这称为微调)
- 调整最终分类头,就是先获取原分类头的的输入维度,然后做一个linear,输入为刚获取的输入维度不变,输出为我们自己的分类数
- 确定一下原数据集的输入维度input_size
4.3 参数筛选函数 prilearn_para
def prilearn_para(model_ft,linear_prob):
# 将模型发送到GPU
device = torch.device("cuda:0")
model_ft = model_ft.to(device)
# 在此运行中收集要优化/更新的参数。
# 如果我们正在进行微调,我们将更新所有参数。
# 但如果我们正在进行特征提取方法,我们只会更新刚刚初始化的参数,即`requires_grad`的参数为True。
params_to_update = model_ft.parameters()
print("Params to learn:")
if linear_prob:
params_to_update = []
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
params_to_update.append(param)
print("\t",name)
else:
for name,param in model_ft.named_parameters():
if param.requires_grad == True:
print("\t",name)
#
# # 观察所有参数都在优化
# optimizer_ft = optim.SGD(params_to_update, lr=0.001, momentum=0.9)
这个函数用于在训练之前调用,如果你打算微调,那么要事先保存一份需要更新的参数的副本(李哥这好像忘了return params_to_update了),然后传给优化器。这主要是因为大模型的参数量实在太大了,事先筛选掉没梯度的参数可以节省算力
4.4 参数初始化函数 init_para
def init_para(model):
def weights_init(model):
classname = model.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(model.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(model.weight.data, 1.0, 0.02)
nn.init.constant_(model.bias.data, 0)
model.apply(weights_init)
return model
这个函数一般是自己从头到尾做一个模型时用,它会把模型所有的卷积层和归一化层的参数初始化为特定值,这是因为经验规律告诉我们这么做初始化的效果会比较好
五、 train 模块
train模块定义了兼顾监督和半监督训练流程的函数train_val,同时调用模块自动绘制损失图和准确率图
from tqdm import tqdm
import torch
import time
import matplotlib.pyplot as plt
import numpy as np
from data import samplePlot, get_semi_loader
def train_val(para):
########################################################
model = para['model'] # 我的模型
semi_loader = para['no_label_Loader'] # 无标签数据集的加载器(半监督核心)
train_loader =para['train_loader'] # 带标签的训练集加载器
val_loader = para['val_loader'] # 验证集加载器
optimizer = para['optimizer'] # 优化器(AdamW/SGD)
loss = para['loss'] # 损失函数(交叉熵loss)
epoch = para['epoch'] # 总训练轮次
device = para['device'] # 训练设备(cuda:0 / cpu)
save_path = para['save_path'] # 最优模型保存路径
save_acc = para['save_acc'] # 保存精度阈值
pre_path = para['pre_path'] # 预训练模型加载路径(断点续训)
max_acc = para['max_acc'] # 记录验证集最高精度
val_epoch = para['val_epoch'] # 隔多少轮做一次验证(比如每1轮验证1次)
acc_thres = para['acc_thres'] # 开启半监督的精度阈值(比如acc>0.8才开)
conf_thres = para['conf_thres'] # 伪标签置信度阈值(比如预测概率>0.9才用)
do_semi= para['do_semi'] # 是否开启半监督训练(开关:True/False)
semi_epoch = 10 # 半监督训练的执行间隔:每10轮执行一次半监督
###################################################
no_label_Loader = None
if pre_path != None:
model = torch.load(pre_path)
model = model.to(device)
# model = torch.nn.DataParallel(model).to(device)
# model.device_ids = [0,1]
plt_train_loss = [] # 每轮训练损失
plt_train_acc = [] # 每轮训练精度
plt_val_loss = [] # 每轮验证损失
plt_val_acc = [] # 每轮验证精度
plt_semi_acc = [] # 每轮半监督训练精度
val_rel = [] # 验证集的预测结果(可选,可删)
max_acc = 0 # 初始化:验证集最高精度为0(用来保存最优模型)
for i in range(epoch):
start_time = time.time()
model.train()
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
semi_acc = 0.0
for data in tqdm(train_loader): #取数据
optimizer.zero_grad() # 梯度置0
x, target = data[0].to(device), data[1].to(device)
pred = model(x) #模型前向
bat_loss = loss(pred, target) # 算交叉熵loss
bat_loss.backward() # 回传梯度
optimizer.step() # 根据梯度更新
train_loss += bat_loss.item() #.detach 表示去掉梯度
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(),axis=1) == data[1].numpy())
# 预测值和标签相等,正确数就加1. 相等多个, 就加几。
if no_label_Loader != None:
for data in tqdm(no_label_Loader):
optimizer.zero_grad()
x , target = data[0].to(device), data[1].to(device)
pred = model(x)
bat_loss = loss(pred, target)
bat_loss.backward()
optimizer.step()
semi_acc += np.sum(np.argmax(pred.cpu().data.numpy(),axis=1)== data[1].numpy())
plt_semi_acc .append(semi_acc/no_label_Loader.dataset.__len__())
print('semi_acc:', plt_semi_acc[-1])
plt_train_loss.append(train_loss/train_loader.dataset.__len__())
plt_train_acc.append(train_acc/train_loader.dataset.__len__())
if i % val_epoch == 0:
model.eval()
with torch.no_grad():
for valdata in val_loader:
val_x , val_target = valdata[0].to(device), valdata[1].to(device)
val_pred = model(val_x)
val_bat_loss = loss(val_pred, val_target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == valdata[1].numpy())
val_rel.append(val_pred)
val_acc = val_acc/val_loader.dataset.__len__()
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_acc
plt_val_loss.append(val_loss/val_loader.dataset.__len__())
plt_val_acc.append(val_acc)
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f | valAcc: %3.6f valLoss: %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1])
)
else:
plt_val_loss.append(plt_val_loss[-1])
plt_val_acc.append(plt_val_acc[-1])
if do_semi and plt_val_acc[-1] > acc_thres and i % semi_epoch==0: # 如果启用半监督, 且精确度超过阈值, 则开始。
no_label_Loader = get_semi_loader(semi_loader, semi_loader, model, device, conf_thres)
plt.plot(plt_train_loss) # 画图。
plt.plot(plt_val_loss)
plt.title('loss')
plt.legend(['train', 'val'])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
plt.savefig('acc.png')
plt.show()
5.1 train_val 函数
这个函数看起来很长,但实际上跟我们之前的学习基本一下,我来大致梳理一下:
5.1.1 参数和变量
参数para是在main函数里会打包好的一个字典,接受字典后会在函数内解包并赋给函数内变量
########################################################
model = para['model'] # 我的模型
semi_loader = para['no_label_Loader'] # 无标签数据集的加载器(半监督核心)
train_loader =para['train_loader'] # 带标签的训练集加载器
val_loader = para['val_loader'] # 验证集加载器
optimizer = para['optimizer'] # 优化器(AdamW/SGD)
loss = para['loss'] # 损失函数(交叉熵loss)
epoch = para['epoch'] # 总训练轮次
device = para['device'] # 训练设备(cuda:0 / cpu)
save_path = para['save_path'] # 最优模型保存路径
save_acc = para['save_acc'] # 保存精度阈值
pre_path = para['pre_path'] # 预训练模型加载路径(断点续训)
max_acc = para['max_acc'] # 记录验证集最高精度
val_epoch = para['val_epoch'] # 隔多少轮做一次验证(比如每1轮验证1次)
acc_thres = para['acc_thres'] # 开启半监督的精度阈值(比如acc>0.8才开)
conf_thres = para['conf_thres'] # 伪标签置信度阈值(比如预测概率>0.9才用)
do_semi= para['do_semi'] # 是否开启半监督训练(开关:True/False)
semi_epoch = 10 # 半监督训练的执行间隔:每10轮执行一次半监督
###################################################
no_label_Loader = None # 无标签数据集加载器初始化为空
if pre_path != None: # 如果有预训练模型
model = torch.load(pre_path) # 加载预训练模型
model = model.to(device) # 将模型移动到训练设备
# model = torch.nn.DataParallel(model).to(device)
# model.device_ids = [0,1]
plt_train_loss = [] # 每轮训练损失
plt_train_acc = [] # 每轮训练精度
plt_val_loss = [] # 每轮验证损失
plt_val_acc = [] # 每轮验证精度
plt_semi_acc = [] # 每轮半监督训练精度
val_rel = [] # 验证集的预测结果(可选,可删)
max_acc = 0 # 初始化:验证集最高精度为0(用来保存最优模型)
这里有一个问题,参数传进来后,如果model是一个预训练好的模型,那model = torch.load(pre_path)不久又重复加载一遍了吗?这里可能存在冗余
5.1.2 开始训练
for i in range(epoch): # 训练epoch轮
start_time = time.time()
model.train() # 训练模式
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
semi_acc = 0.0
for data in tqdm(train_loader): # 取数据
optimizer.zero_grad() # 梯度置0
x, target = data[0].to(device), data[1].to(device)
pred = model(x) # 模型前向
bat_loss = loss(pred, target) # 算交叉熵loss
bat_loss.backward() # 回传梯度
optimizer.step() # 根据梯度更新
train_loss += bat_loss.item() #.detach 表示去掉梯度
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(),axis=1) == data[1].numpy())
# 预测值和标签相等,正确数就加1. 相等多个, 就加几。
if no_label_Loader != None: # 半监督训练
for data in tqdm(no_label_Loader):
optimizer.zero_grad()
x , target = data[0].to(device), data[1].to(device)
pred = model(x)
bat_loss = loss(pred, target)
bat_loss.backward()
optimizer.step()
semi_acc += np.sum(np.argmax(pred.cpu().data.numpy(),axis=1)== data[1].numpy())
plt_semi_acc .append(semi_acc/no_label_Loader.dataset.__len__())
print('semi_acc:', plt_semi_acc[-1])
plt_train_loss.append(train_loss/train_loader.dataset.__len__()) # 记录训练损失
plt_train_acc.append(train_acc/train_loader.dataset.__len__()) # 记录训练准确率
if i % val_epoch == 0:
model.eval()
with torch.no_grad():
for valdata in val_loader:
val_x , val_target = valdata[0].to(device), valdata[1].to(device)
val_pred = model(val_x)
val_bat_loss = loss(val_pred, val_target)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == valdata[1].numpy())
val_rel.append(val_pred)
val_acc = val_acc/val_loader.dataset.__len__() # 通过准确率更新最优模型
if val_acc > max_acc:
torch.save(model, save_path)
max_acc = val_acc
plt_val_loss.append(val_loss/val_loader.dataset.__len__())
plt_val_acc.append(val_acc)
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f | valAcc: %3.6f valLoss: %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1])
)
else:
plt_val_loss.append(plt_val_loss[-1]) # 让train和val对齐,方便画图
plt_val_acc.append(plt_val_acc[-1])
if do_semi and plt_val_acc[-1] > acc_thres and i % semi_epoch==0: # 如果启用半监督, 且精确度超过阈值, 则开始。
no_label_Loader = get_semi_loader(semi_loader, semi_loader, model, device, conf_thres)
注释写的挺明白的了,这里补充几点:
- 我们之前在回归实战里用的是SGD随机梯度下降方法,那是一种小批次梯度下降的方法,所以每一个epoch只训练batch_size的数据;而本次用的是AdamW方法,所以这里其实每个epoch都用所有数据完整地训练了一次模型
- 半监督训练部分不去细究了,
绝对不是因为我想偷懒 - 模型和数据,必须放在同一个设备上,否则会程序崩溃
- MyModel 继承了 torch.nn.Module 这个父类,nn.Module 这个父类内部,已经帮我们重写了 Python 的魔术方法__call__,nn.Module 的 call 方法内部,会自动调用写好的 forward方法,所以才可以直接model(x)完成前向
六、main 模块
main函数的工作就是做好类的实例化,设置好超参数,然后传参就行
import random
import torch
import torch.nn as nn
import numpy as np
import os
from model_utils.model import initialize_model
from model_utils.train import train_val
from model_utils.data import getDataLoader
# os.environ['CUDA_VISIBLE_DEVICES']='0,1'
# 固定随机种子,确保实验结果可复现
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
#################################################################
seed_everything(0)
###############################################
# 配置超参数
model_name = 'resnet18'
##########################################
num_class = 11
batchSize = 32
learning_rate = 1e-4
loss = nn.CrossEntropyLoss() # 指定损失函数:交叉熵损失,适用于多分类任务
epoch = 10
device = 'cuda' if torch.cuda.is_available() else 'cpu'
##########################################
filepath = 'food-11_sample'
# filepath = 'food-11'
##########################
#读数据
train_loader = getDataLoader(filepath, 'train', batchSize)
val_loader = getDataLoader(filepath, 'val', batchSize)
no_label_Loader = getDataLoader(filepath,'train_unl', batchSize)
#模型
model, input_size = initialize_model(model_name, 11, use_pretrained=False)
print(input_size)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate,weight_decay=1e-4)
save_path = 'model_save/model.pth'
# 打包参数
trainpara = {
"model" : model,
'train_loader': train_loader,
'val_loader': val_loader,
'no_label_Loader': no_label_Loader,
'optimizer': optimizer,
'batchSize': batchSize,
'loss': loss,
'epoch': epoch,
'device': device,
'save_path': save_path,
'save_acc': True,
'max_acc': 0.5,
'val_epoch' : 1,
'acc_thres' : 0.7,
'conf_thres' : 0.99,
'do_semi' : True,
"pre_path" : None
}
if __name__ == '__main__':
train_val(trainpara)
至此训练完毕,可喜可贺可喜可贺

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)