李哥深度学习 第八节 自然语言处理下 Bert实战
本次任务是一个情感二分类的任务,即使给一段评论,模型要能识别出好评还是差评,我们会使用预训练好的Bert模型,不会进行微调,仅进行线性探测。这次的结构和上次一样,还是data.py model.py train.py 和main.py四个模块。
这一节和李哥深度学习 第五节 图像分类实战挺像的,所以我基本会对比着这篇文章的结构来写
任务概述
本次任务是一个情感二分类的任务,即使给一段评论,模型要能识别出好评还是差评,我们会使用预训练好的Bert模型,不会进行微调,仅进行线性探测。
这次的结构和上次一样,还是data.py model.py train.py 和main.py四个模块。
工程结构
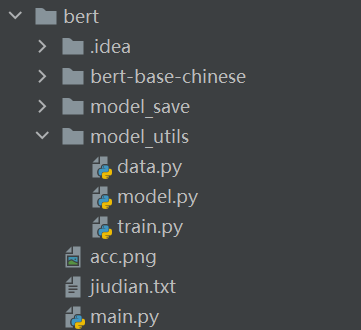
- idea是我们用pychram打开工程后自动生成的文件夹,不用管
- bert-base-chinese是bert中文预训练模型,从hugging face上下载的
- model_save是用来保存历史最佳模型的文件夹
- model_utils里面都是老朋友
- jiudian.txt是本次要用的数据集
- main函数也不陌生了,是工程最终的入口
预训练模型下载
Hugging Face,有四个model,选择pytorch_model.bin下载,然后下载其他配置文件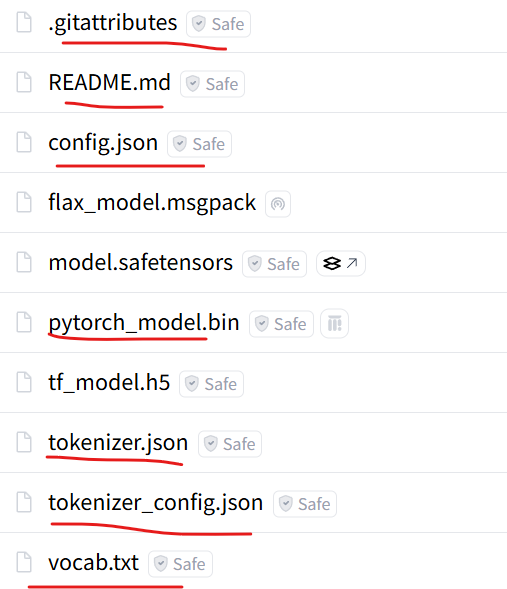
观察数据
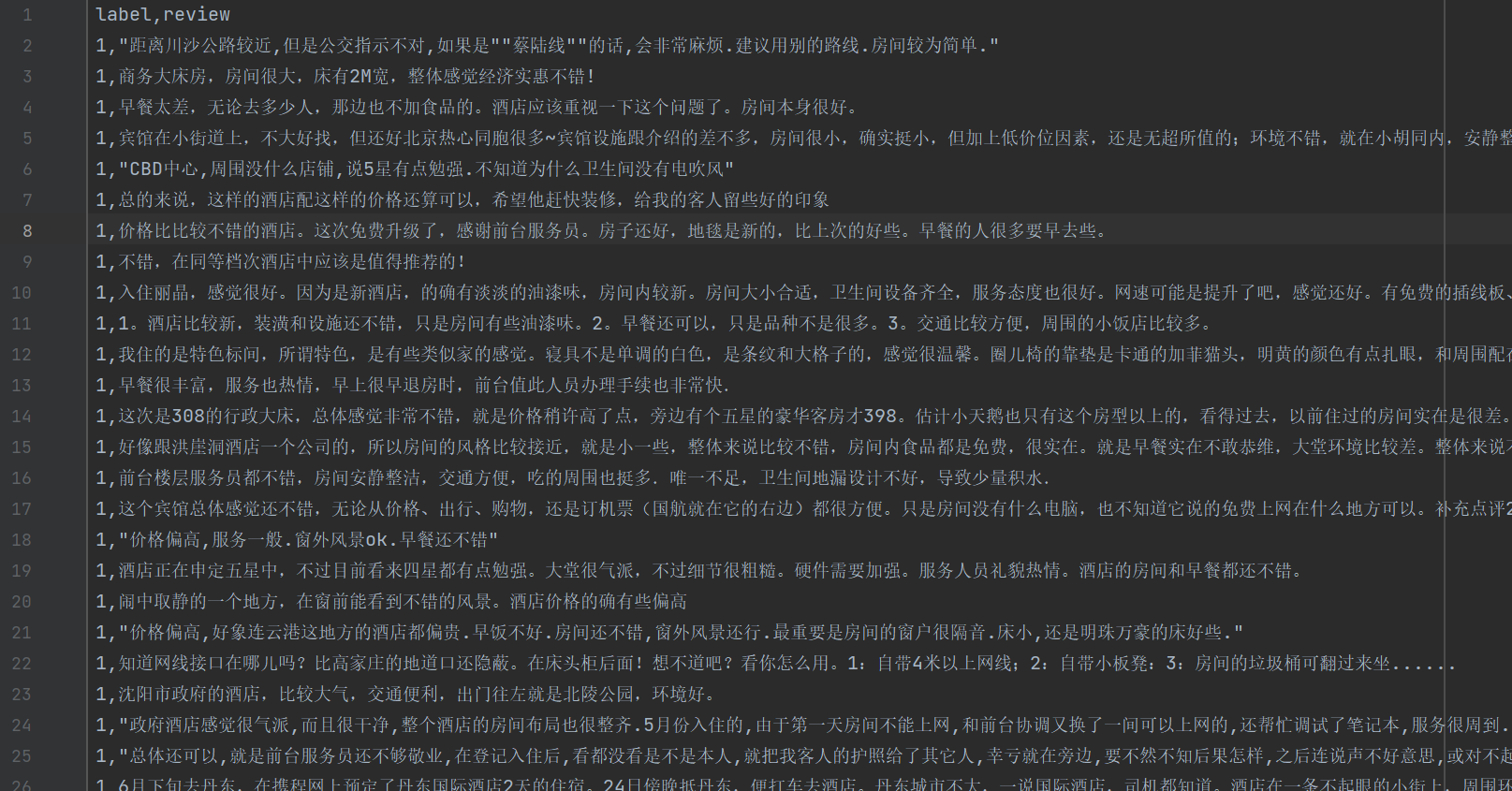

- 第一行为表头,要删除
- 每一条数据的第一个字符为分类,1代表好评,0代表差评
- 数据之间用换行符 \n 分隔
这次的数据集就不是那么贴心地提前划分好训练验证测试了,所以要自己划分
data模块
观察好数据后,我们来动手编写data模块
- data模块最基本的任务就是定义数据类、实现读文件功能、实现获取loader功能。
- 然后本次和上次的区别是,读文件只读一个文件即可,但是要自己划分训练集和验证集来训练分类头
- 然后这次地loader会直接同时返回 train_loader,和val_loader,不用mode来控制,当然这种变化是无关紧要的
读文件
def read_txt_data(path):
label = []
data = []
with open(path, "r", encoding="utf-8") as f:
for i, line in tqdm(enumerate(f)):
if i == 0:
continue # continue 表示立即执行下一次循环
if i > 200 and i < 7500:
continue
line = line.strip('\n') # 去掉换行符
line = line.split(",", 1) # 1表示分割次数,可以分割出标签和数据
label.append(line[0])
data.append(line[1])
return data, label
- f是一个文件指针,enumerate(f)会自动按照换行符 \n 进行分割,来变成可迭代对象。如果希望自定义分割,可以这么做:
with open(path, "r", encoding="utf-8") as f:
all_content = f.read() # 读取整个文件为一个字符串
lines = all_content.split("自定义分隔符") # 按自定义符号拆分
for i, line in enumerate(lines):
# 处理每一行
数据类
class JdDataset(Dataset):
def __init__(self, x, label):
self.X = x
label = [int(i) for i in label] # 将字符类型label变为int类型label
self.Y = torch.LongTensor(label)
def __getitem__(self, item):
return self.X[item], self.Y[item] # 数据集一般不让返回str, 要写在字典中,或者转为矩阵。
def __len__(self):
return len(self.Y)
loader
def get_dataloader(path, batchsize=1, valSize=0.2):
x, label = read_txt_data(path)
train_x, val_x, train_y, val_y = train_test_split(x, label,test_size=valSize,shuffle=True, stratify=label)
train_set = JdDataset(train_x, train_y)
val_set = JdDataset(val_x, val_y)
train_loader = DataLoader(train_set, batch_size=batchsize)
val_loader = DataLoader(val_set, batch_size=batchsize)
return train_loader, val_loader
- train_test_split是一个非常非常常用的划分数据的函数,写法也很固定
- 参数stratify的作用是保证划分的train和val中,1和0的比例均与原数据集一样
model 模块
在model模块里放好需要的模型类,上一次的模型都是直接加载torch里的模型,而这次的Bert因为要用中文Bert,所以是我们从网上下载的,加载方式会麻烦一些
myBertModel 类
class myBertModel(nn.Module):
def __init__(self, bert_path, num_class, device):
def build_bert_input(self, text):
def forward(self, text):
最开始我看代码时觉得很奇怪,怎么这么长?不是加载一下预训练模型,然后接一个分类头就行了吗?然后我仔细看了看,发现主要是要处理输入。
就是说,我们知道Bert的预训练模型,训练好的是嵌入层embedding和自注意力Self-attention,这其实是不完整的。就embedding来说,我们需要对输入进行一系列格式化的处理,让embedding能够成功接收数据,这就是build_bert_input的作用,也是myBertModel额外多出来的一个核心功能
初始化函数 init
class myBertModel(nn.Module):
def __init__(self, bert_path, num_class, device):
super(myBertModel, self).__init__()
self.device = device
self.num_class = num_class # 分类数
# bert_config = BertConfig.from_pretrained(bert_path)
# self.bert = BertModel(bert_config)
self.bert = BertModel.from_pretrained(bert_path) # 加载预训练模型
self.tokenizer = BertTokenizer.from_pretrained(bert_path) # 加载分词器
self.out = nn.Sequential( # 添加分类头
nn.Linear(768,num_class)
)
- 加载预训练模型,其实就是说BertModel本身的架构就是一个embedding和一个selfattention,我们要把下载下来的模型参数导入进去
- 加载分词器,就是把你下载好的中文分词器导入到BertModel的分词器BertTokenizer,让他拥有对中文进行分词的能力
- 分类头就是,BertModel的输出维度固定为768,而我们是一个情感二分类,所以需要添加一个全连接层把768映射到2
格式化输入 build_bert_input
def build_bert_input(self, text):
Input = self.tokenizer(text,return_tensors='pt', padding='max_length', truncation=True, max_length=128)
input_ids = Input["input_ids"].to(self.device)
attention_mask = Input["attention_mask"].to(self.device)
token_type_ids = Input["token_type_ids"].to(self.device)
return input_ids, attention_mask, token_type_ids
解释一下tokenizer:
- 输入text是评论,可以是一条也可以是多条,bert是看不懂文字的,所以使用tokenizer转换为编码;**return_tensors=‘pt’**表示返回tensor类型变量,因为我们是在pytorch环境下做的模型; padding=‘max_length’, truncation=True, max_length=128 三者共同出现,max_length将句子长度固定为128,padding允许句子长度不足128时完成填充,truncation允许句子长度超过128时直接截断。
- max_length一般取64/128/256/512,512是Bert设计范围内的最大极限,这里128是根据对数据的观察选出的比较合适的长度,既不会浪费大量空间,又不会造成大量的截断。
- 分词器tokenizer会返回一个字典,包含"input_ids",“attention_mask”,“token_type_ids”,"input_ids"给出了字到id的映射,"attention_mask"给出了填充信息,"token_type_ids"给出了句子信息
- 举个例子 :
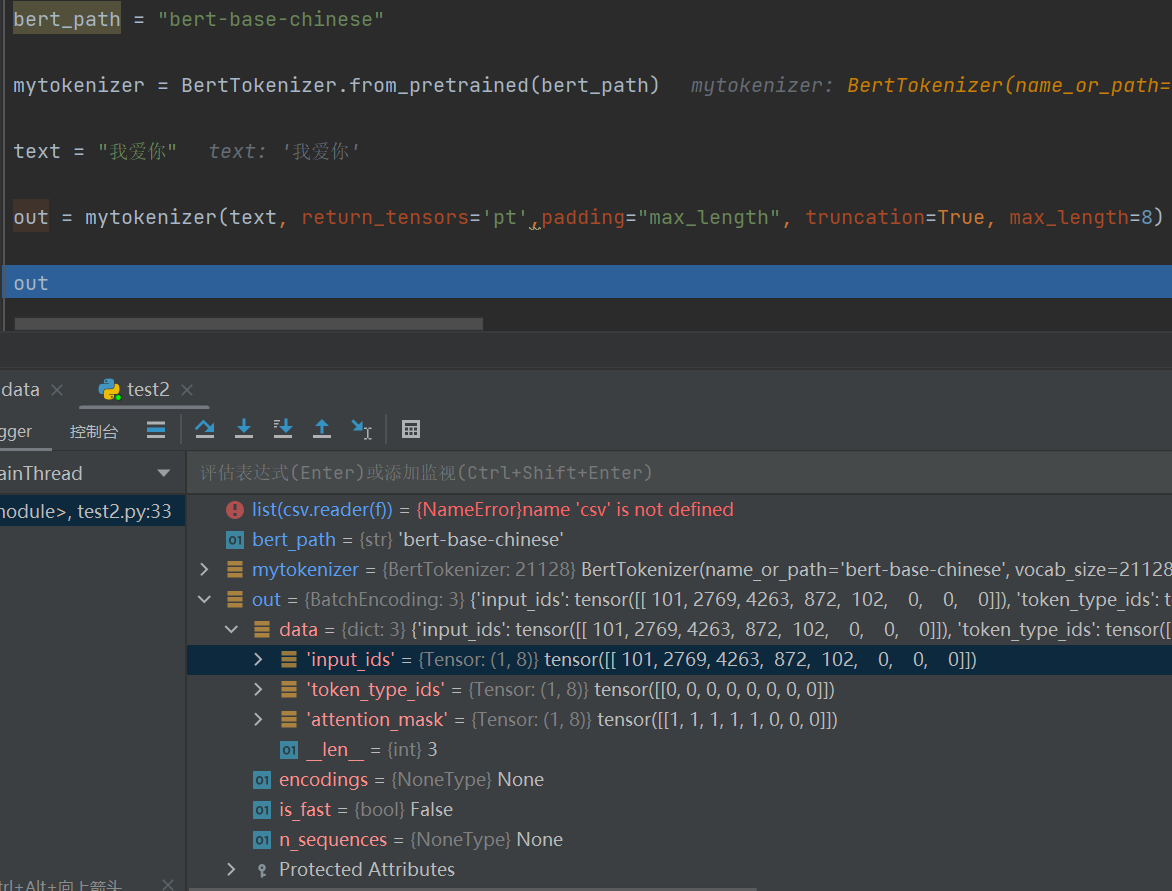
input_ids中,[CLS]->101,我->2769,爱->4263,你->872,剩下的填充0
token_type_ids中,全部为零,因为就这么一个句子
attention_mask中,前5位为零
前向传播 forward
def forward(self, text):
input_ids, attention_mask, token_type_ids = self.build_bert_input(text)
sequence_out, pooled_output = self.bert(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
return_dict=False)
out = self.out(pooled_output)
return out
所以说,build_bert_input的返回才是Bert可以接受的输入。
train 模块
import torch
import time
import matplotlib.pyplot as plt
import numpy as np
from tqdm import tqdm
def train_val(para):
########################################################
model = para['model']
train_loader =para['train_loader']
val_loader = para['val_loader']
scheduler = para['scheduler']
optimizer = para['optimizer']
loss = para['loss']
epoch = para['epoch']
device = para['device']
save_path = para['save_path']
max_acc = para['max_acc']
val_epoch = para['val_epoch']
#################################################
plt_train_loss = []
plt_train_acc = []
plt_val_loss = []
plt_val_acc = []
val_rel = []
for i in range(epoch):
start_time = time.time()
model.train()
train_loss = 0.0
train_acc = 0.0
val_acc = 0.0
val_loss = 0.0
for batch in tqdm(train_loader):
model.zero_grad()
text, labels = batch[0], batch[1].to(device)
pred = model(text)
bat_loss = loss(pred, labels)
bat_loss.backward()
optimizer.step()
scheduler.step() # 学习率更新
optimizer.zero_grad()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0) # 梯度裁剪
train_loss += bat_loss.item() #.detach 表示去掉梯度
train_acc += np.sum(np.argmax(pred.cpu().data.numpy(),axis=1)== labels.cpu().numpy())
plt_train_loss . append(train_loss/train_loader.dataset.__len__())
plt_train_acc.append(train_acc/train_loader.dataset.__len__())
if i % val_epoch == 0:
model.eval()
with torch.no_grad():
for batch in tqdm(val_loader):
val_text, val_labels = batch[0], batch[1].to(device)
val_pred = model(val_text)
val_bat_loss = loss(val_pred, val_labels)
val_loss += val_bat_loss.cpu().item()
val_acc += np.sum(np.argmax(val_pred.cpu().data.numpy(), axis=1) == val_labels.cpu().numpy())
val_rel.append(val_pred)
if val_acc > max_acc:
torch.save(model, save_path+str(epoch)+"ckpt")
max_acc = val_acc
plt_val_loss.append(val_loss/val_loader.dataset.__len__())
plt_val_acc.append(val_acc/val_loader.dataset.__len__())
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f | valAcc: %3.6f valLoss: %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1], plt_val_acc[-1], plt_val_loss[-1])
)
if i % 50 == 0:
torch.save(model, save_path+'-epoch:'+str(i)+ '-%.2f'%plt_val_acc[-1])
else:
plt_val_loss.append(plt_val_loss[-1])
plt_val_acc.append(plt_val_acc[-1])
print('[%03d/%03d] %2.2f sec(s) TrainAcc : %3.6f TrainLoss : %3.6f ' % \
(i, epoch, time.time()-start_time, plt_train_acc[-1], plt_train_loss[-1])
)
plt.plot(plt_train_loss)
plt.plot(plt_val_loss)
plt.title('loss')
plt.legend(['train', 'val'])
plt.show()
plt.plot(plt_train_acc)
plt.plot(plt_val_acc)
plt.title('Accuracy')
plt.legend(['train', 'val'])
plt.savefig('acc.png')
plt.show()
几乎跟上次写的一模一样,就多了个学习率更新和梯度裁剪
main 模块
import torch.nn as nn
import torch
import random
import numpy as np
import os
from model_utils.data import get_dataloader
from model_utils.model import myBertModel
from model_utils.train import train_val
def seed_everything(seed):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
random.seed(seed)
np.random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
model_name = 'MyModel'
num_class = 2
batchSize = 4
learning_rate = 0.0001
loss = nn.CrossEntropyLoss()
epoch = 3
device = 'cuda' if torch.cuda.is_available() else 'cpu'
data_path = "jiudian.txt"
bert_path = 'bert-base-chinese'
save_path = 'model_save/'
seed_everything(1)
##########################################
train_loader, val_loader = get_dataloader(data_path, batchsize=batchSize)
model = myBertModel(bert_path, num_class, device).to(device)
# tokenizer, model = build_model_and_tokenizer(bert_path)
param_optimizer = list(model.parameters())
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate,weight_decay=0.0001)
scheduler = torch.optim.lr_scheduler.CosineAnnealingWarmRestarts(optimizer,T_0=20,eta_min=1e-9)
trainpara = {'model': model,
'train_loader': train_loader,
'val_loader': val_loader,
'scheduler': scheduler,
'optimizer': optimizer,
'learning_rate': learning_rate,
'warmup_ratio' : 0.1,
'weight_decay' : 0.0001,
'use_lookahead' : True,
'loss': loss,
'epoch': epoch,
'device': device,
'save_path': save_path,
'max_acc': 0.85,
'val_epoch' : 1
}
train_val(trainpara)
这里用到的AdamW 和CosineAnnealingWarmRestarts 是Bert模型的黄金搭档,用上就行,然后参数基本也都是经验性质的最优参数,基本不用动

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)