AI模型调参指南:核心参数全解析
文章摘要:本文系统介绍了大语言模型生成文本时的核心调参方法。首先详细解析了控制随机性的关键参数:温度(temperature)影响输出保守程度,top_p和top_k控制候选词范围,min_p过滤低概率词。其次介绍了减少重复的参数:频率惩罚、存在惩罚和重复惩罚等。此外还涵盖了输出长度控制、多样性策略、结构化输出等参数设置。文章提供了针对不同场景的调参建议:严谨任务应降低温度、增大top_p;创意写
一、控制“随机性 / 创造力”的核心参数
这些参数直接控制模型在每一步选下一个 token 时的随机性,是你最常调的几类。
1. temperature(温度)
作用本质:
对 logits(未归一化的对数概率)做缩放:
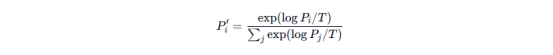
T = 1:不变,更接近“原始模型”习性。
T < 1:放大高概率与低概率 token 差距 → 分布更尖锐 → 输出更保守、更确定。
T > 1:压缩差距 → 分布更平 → 输出更随机、更有脑洞。
常见取值与含义:
0 或接近 0:近似“贪心解码”(几乎每步都选当前最高概率 token)。
0.1–0.3:严谨问答、数学推理、代码。
0.4–0.7:日常对话,既不死板也不疯。
0.8–1.2:创意写作、故事、广告文案。
1.2:高脑洞,容忍“跑偏”。
实战建议:
只要你觉得回答“太飘”,第一反应就是先降温度。
只要你觉得回答“像机器/太一致”,先升温度。
2. top_p(核采样 / Nucleus Sampling)
机制:
按概率从大到小排序所有 token;
从最高开始累加概率,直到累计和 ≥ top_p;
只在这部分 token 内随机选下一个。
所以:
top_p 小:满足累计概率很快 → 候选更少 → 输出更保守。
top_p 大:需要更多 token 才凑够累计概率 → 候选多 → 输出更发散。
常用区间:
0.7–0.9:严谨问答。
0.8–0.95:一般对话、写作。
0.9–0.98:高度创意。
与 temperature 关系:
两者都影响“随机性”,常配合使用。
实践中常见策略:固定一个、微调另一个,例如:
固定 top_p = 0.9,调 temperature;
或固定 temperature = 0.7,调 top_p。
3. top_k
机制:
每次只保留概率最高的 k 个 token,剩下全砍掉,再在这 k 个里按概率采样。
特点:
k 小:非常确定,容易重复、机械。
k 大:多样性更高,但也更容易跑题。
典型设置:
精准问答:5–20。
日常对话/文章:20–50。
小说、脑洞:50–100+。
与 top_p 对比:
top_k:固定数量,不管累计概率。
top_p:动态数量,只看累计概率到没到阈值。
很多云服务端(尤其是 OpenAI 原生接口)不直接暴露 top_k,但本地引擎(vLLM、llama.cpp 等)普遍支持。
4. min_p(Minimum Probability Sampling)
机制:
只允许概率 ≥「当前最高概率 × min_p」的 token 参加采样。
min_p 越大 → 相对阈值越高 → 候选更少 → 输出更保守、减少极低概率“噪点”。
min_p 越小 → 接受更多长尾 token → 输出更发散。
典型用法:
0.03–0.1:在已经设定 temperature、top_p 的基础上,再防止模型“捡破烂”式选极端低概率 token。
5. typical_p(典型采样)
直观理解:
仅保留“比随机噪声高出一截”的那些 token,用于过滤掉极其不典型的 token。
典型值多在 0.05–0.2 之间,0 或 1 通常表示关闭。
适合:
想让文本既自然又有点变化时,搭配中等温度使用。
6. tfs_z(Tail-Free Sampling)
原理:
Tail-Free Sampling 通过削掉概率分布的“长尾”部分来减少非常罕见的 token。[2]
直观效果:
z 越小 → 越“无尾” → 输出更稳。
z 越接近 1 → 效果接近“不开”。
常用场景:
本地 LLaMA 模型,经常出奇怪字串时,可适当调低 tfs_z(如 0.8–0.9)。
7. Mirostat(mirostat_mode、mirostat_tau、mirostat_eta)
目的:
动态控制文本生成过程中的困惑度(perplexity),让输出既不无聊也不过度随机。
mirostat_mode
0:关闭;
1 / 2:不同版本的 Mirostat 算法。
mirostat_tau
目标“惊讶度”/交叉熵,越大越随机。
mirostat_eta
每步调节步长,控制收敛速度。
一般不建议新手一上来折腾 Mirostat,除非你做的是研究级调参。
二、减少重复与控制话题的惩罚参数
1. frequency_penalty(频率惩罚)
作用:
根据 token 在已生成文本中出现的次数来惩罚:出现越多,惩罚越重。
值越大 → 对高频词抑制越强 → 更会“换个说法”。
常见区间:
0:完全按原始概率(无惩罚)。
0.1–0.3:轻微防复读,适合普遍写作。
0.3–0.8:明显减少重复。
强行不让重复某些词,可能导致语言不自然。
推荐使用:
长文生成 / FAQ 机器人老爱重复某些词时,加到 0.2–0.4 是很常见做法。
2. presence_penalty(存在惩罚)
作用:
只要某个 token 出现过,就给它减分,不考虑出现多少次。
值越大:模型越倾向于引入新词 / 新话题。
典型区间:
0:关闭;
0.1–0.4:鼓励适度引入新词;
0.8:有很强“别再说这玩意”的意味。
对比 frequency_penalty:
frequency_penalty 关心“出现了几次”;
presence_penalty 只关心“出现没出现过”。
3. repetition_penalty(重复惩罚)
多见于 transformers、本地 LLaMA 推理框架。
作用:
对所有已经生成过的 token 或 n‑gram 统一施加一个惩罚系数(通常 >1)。
1.0:关闭;
1.05–1.2:轻中度防止重复短语;
1.3:几乎杜绝连续重复,但也可能影响正常用词。
与 frequency / presence 的关系:
repetition_penalty 粗暴“一刀切”;
frequency / presence 较为细腻,可以单独调节“常用词复用”和“话题扩展”。
4. no_repeat_ngram_size
作用:
模型保证不会重复出现指定长度的 n‑gram。
0:关闭;
2–4:防止短语级别的复读;
5–8:强烈限制结构重复,适合需要句式多变的创作。
典型场景:
生成故事、小说时重复句式明显,可尝试 no_repeat_ngram_size = 3 或 4。
5. length_penalty(长度惩罚)
多在 beam search 中使用。
1:惩罚长文本 → 输出更短、更凝练;
<1:鼓励长文本 → 摘要、报告场景适当调低。
6. logit_bias
作用:
直接调整特定 token 的 logit 值,从而影响其出现概率。
值为正:大幅提高某 token 出现概率;
值为负:大幅降低该 token 出现概率;
数值范围通常在 [-100, 100]。
典型用途:
强制输出某个词,如指定回答必须包含“是”或“否”;
避免某些敏感词出现。
三、输出长度与资源控制类参数
1. max_tokens / max_completion_tokens
被新版本统一为 max_completion_tokens:
含义:“本次最多生成多少个输出 token”,不会影响输入长度。
作用:控制响应的最大篇幅和成本上限(token = 计费单位)。
典型设置:
短问答:128–256。
普通对话:256–512。
长文 / 报告:1024–2048 甚至更多(受模型上下文长度限制)。
2. max_new_tokens(本地/Transformers 常用)
含义:
与 max_completion_tokens 等效,限制输出 token 上限,不含输入 token。
使用 HuggingFace 的 .generate 时最常见参数。
3. max_prompt_tokens(Assistants API)
作用:
限制**“单次推理所用的提示 tokens 总数”**,包括上下文对话历史、文件检索等内容。[5]
用法:
在复杂助手(多轮对话、检索、多工具)里,防止上下文无限增长、成本失控。
若设得过小,模型可能频繁“遗忘”早期上下文。
4. min_new_tokens / min_length
约束最小输出长度,防止模型“一句话就完事了”。
摘要、剧本、分点回答等任务常用。
四、生成数量、多样性与搜索策略
1. n(number of outputs)
含义:
一次请求生成多少条不同候选回答。
1:默认,性能/成本最优。
1:增加多样性,但 token 消耗近似乘以 n。
常用:
想要多个方案对比时,设置 3–5,配合较高 temperature。
2. best_of
(主要在旧 completions API、本地推理框架如 vLLM 中)
机制:
实际在后端生成 best_of 条候选,按 token 概率选出最优的那几条,再返回其中的 n 条。
要点:
要求 best_of >= n;
成本约等于 best_of × max_tokens,非常耗资源;
适合对质量极度敏感的场合(比如自动出题、生成考试内容)。
3. num_beams(束搜索宽度)
在 HuggingFace Transformers 等框架中使用。
num_beams = 1:相当于贪心或随机采样。
num_beams > 1:进行 beam search,尽量找到 log 概率最高的完整序列。
特点:
beam 越宽 → 找到的序列越“全局最优” → 输出更稳定、条理更清晰;
但创造力会下降,而且计算量上升明显。
常用于:摘要、翻译这类有“标准答案”的任务。
4. early_stopping
配合 beam search 使用:
true:当所有 beam 都生成了 EOS 或达到阈值就停;
false:继续搜索到 max_tokens 或其它条件。
五、调试与分析用参数
1. logprobs & top_logprobs
logprobs:
要求接口返回每一个生成 token 的 log 概率序列。
可用于:
调试 prompt;
构建置信度指标;
探索模型“本来想说啥”。
top_logprobs:
指定返回每个位置上概率最高的前 k 个 token 及其 logprob;
常用范围 1–5。
在需要“解释性”或构建复杂后处理逻辑时很有用。
2. seed(随机种子)
作用:
给采样过程设一个固定种子,使带随机性的生成在同一模型版本下尽可能可复现。[7]
注意:
不是所有接口都完全保证 100% 重复,但在固定 model + prompt + seed + 参数时,结果高度稳定。
六、结构化输出与工具调用相关参数
1. response_format
用途:
强制模型返回符合特定 JSON 结构的文本(Structured Outputs)。
常见写法(伪代码):
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "Answer",
"schema": {
"type": "object",
"properties": {
"summary": { "type": "string" },
"tags": { "type": "array", "items": { "type": "string" } }
},
"required": ["summary"]
}
}
}适用场景:
需要机器安全解析的输出,如表单、配置、结构化数据。
2. tools / tool_choice / function_call
tools:
定义模型可以调用的函数列表(包括名称、参数模式、用途说明)。
tool_choice:
"auto":模型自己决定是否、调用哪个工具;
"required":必须调用至少一个工具;
也可以指定具体函数名。
function_call(旧接口中的参数名):
与 now 的 tools + tool_choice 思路类似,主要用于强制或允许函数调用。
用途:
构建“具备读写数据库、调用外部 API 能力”的智能体;
将 LLM 从“纯文本生成器”升级为“带工具的决策引擎”。
七、停止条件相关参数
1. stop(stop sequences)
作用:
一旦生成的文本中出现指定的序列,模型就停止继续生成。
典型用法:
"stop": ["\n\nHuman:", "\n\nUser:"]或指定 JSON 结束符、特殊标记,确保输出在合适的位置“收住”。
注意:
stop 通常是字符串,而非 token ID;
可传单个字符串,也可传字符串数组。
八、流式输出(Streaming)
1. stream
stream = true:服务器会以 Server-Sent Events 的形式一块一块地推送生成内容。
优点:首 token 延迟低,前端可以立刻显示“正在回答……”;
缺点:代码实现稍复杂。
九、缓存与用户标识相关参数
1. prompt_cache_key(Prompt Caching)
作用:
配合 OpenAI 的 Prompt Caching 功能,将长提示前缀缓存起来,大幅降低延迟和成本。[12]
典型场景:
系统提示(System Prompt)很长,但用户每轮只在后面加一点点补充;
多用户共用统一的前缀结构。
2. user
作用:
提供一个最终用户 ID(并非 API Key 所属账号),方便平台做风控与统计。[13]
有助于:
分用户计费;
异常行为检测;
A/B 测试。
十、综合调参建议(实战顺序)
先定任务类型:严谨(代码/数学/检索)还是创意(写作/脑暴)?
先只调 temperature,找一个你满意的稳定度。
如果仍有明显“离谱 token”,再收紧 top_p 或增加 top_k/min_p 限制。
出现明显啰嗦、复读:
frequency_penalty 从 0.2 试起;
或设 no_repeat_ngram_size = 3;
如仍严重再加少量 presence_penalty 或 repetition_penalty。
输出总是偏短 / 偏长:
调整 max_completion_tokens / max_new_tokens;
使用 length_penalty(beam search 时);
必要时设 min_new_tokens 要求最小输出。
需要结构化输出或对接后端:
使用 response_format + JSON Schema;
或用 tools / tool_choice 做函数调用。
需要可重复实验:
固定 seed,同时锁定 model 版本与所有参数。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 10
10 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)