大模型参数揭秘:从7B到70B的关键解析
大模型参数是深度学习的核心知识载体,包括权重和偏置,决定了模型的能力上限。关键参数包括总量、隐藏维度、层数、注意力头数、FFN维度等,这些因素共同影响模型性能和计算成本。实际应用中,7B-13B规模的模型通常能平衡效果与资源消耗,而更大的70B模型收益有限但成本剧增。选择模型时应综合考虑任务需求、硬件配置和成本效益,避免盲目追求参数量。优化架构、训练策略和微调方法往往比单纯增加参数更能提升实际效果
一、「参数」在大模型里到底指什么?
在深度学习里,参数(Parameters)= 权重(weights)+ 偏置(bias),是训练过程中被更新的所有数值。
训练阶段:通过反向传播不断更新参数,使模型在大量数据上拟合「输入 → 输出」的映射。
推理阶段:加载这些已经训练好的参数,接收新输入,按既定算子(矩阵乘法、注意力等)算出结果。
所以:
参数 = 模型的「知识存储单元」;
参数量越大,理论上表达能力越强,但算力 / 显存 / 成本也会急剧上升。
二、大模型中最关键的几类参数
可以把「大模型参数」拆成以下几块来看:
1. 参数总量(#Params)
常见说法:7B、13B、34B、70B 中的「B」就是 Billion(十亿参数)。
比如:
7B 模型 ≈ 7 × 10⁹ 个参数
13B 模型 ≈ 13 × 10⁹ 个参数
这是衡量「模型大小」最直观的指标。
影响:
优点:参数多 → 理论容量更大 → 能拟合更复杂的规律。
缺点:
训练成本呈指数级增长(数据量、时间、显卡数);
推理显存、延迟、能耗都显著增加。
对绝大多数实际业务:7B–13B 档的模型已经能覆盖大量应用场景,70B 通常只在资源很富裕、对效果要求极高时才会用。
2. 隐藏维度 / 模型维度(Hidden Size, d_model)
这是 Transformer 里每层中间表示的向量维度,通常记为 d_model。
举例:d_model = 4096 表示每一个 token 在模型内部被表示为 4096 维向量。
常见取值:1024、2048、3072、4096 等。
影响:
容量:维度越大,单层能表达的信息越多;
计算量:矩阵乘法复杂度与 d_model² 成正比,放大一倍维度,计算量可以接近翻 4 倍。
3. 层数(Layers)
也就是 Transformer Block 的数量(堆了多少层)。
小模型:12、16 层
中等:24–32 层
大模型:48–80 层
影响:
层数决定了「深度」,越深的网络能学习更复杂的组合特征。
但深度越大:
前向/反向传播越慢;
内存和显存占用增加;
如果训练不足,容易过拟合或梯度不稳定。
粗略理解:参数量 ≈ 层数 × 维度² × 常数因子,层数和维度是参数量的两个主旋律。
4. 注意力头数(Attention Heads)
在多头自注意力(Multi-Head Attention)中,每个 head 学习不同的「关注模式」。
num_heads:头的数量,常见值:8、16、32、64……
每个 head 的维度:d_head = d_model / num_heads
影响:
头多:可以从更多角度去建模 token 间的关系(语法、语义、位置等)。
头太多但维度太小:单个 head 可能表达力不够,反而浪费计算。
5. 前馈层维度(FFN Dimension, ffn_dim)
每个 Transformer Block 里,除了注意力部分,还有一个前馈网络(Feed Forward Network, FFN),典型结构是:
Linear(d_model → ffn_dim) → 激活 → Linear(ffn_dim → d_model)
一般 ffn_dim ≈ 4 × d_model。
所以:
如果 d_model = 4096,则 ffn_dim ≈ 16384。
这一块的参数量和计算量也非常大,是算力消耗的主力之一。
6. 词表大小(Vocab Size)
tokenizer 把文字拆成 token,每个 token 都有一个唯一的 ID,所有可用的 token 构成词表:
常见:32k、50k、100k、200k token。
Embedding 表大小 ≈ vocab_size × embedding_dim,也是一块不小的参数量。
影响:
词表越大:
表达更精细(特别是多语言、代码、特殊符号时);
但 embedding 参数量变大,训练更难,数据稀疏问题更明显。
词表越小:
token 序列会变长(如把一个复杂汉字拆成多个 token),影响速度和效果。
7. 上下文长度(Context Length, seq_len)
指单次推理能处理的最大 token 数(包含系统提示、历史对话、当前输入和预期输出)。
典型档位:
2k、4k、8k、16k、32k、100k、128k……
注意:上下文长度不是「参数」,但直接影响显存和吞吐量:
自注意力复杂度约为 O(seq_len² × d_model),序列加倍,计算量近似 ×4;
KV Cache(注意力缓存)显存占用也随 seq_len × 并发数 线性增长。
三、「参数量」如何换算到显存和推理资源?
1. 纯参数显存估算
假设使用 FP16(16 位浮点,2 字节)存储:
显存(GB) ≈ 参数量(个) × 2字节 ÷ (1024³) ≈ 参数量(B) × 2 / 1e9
粗略表:
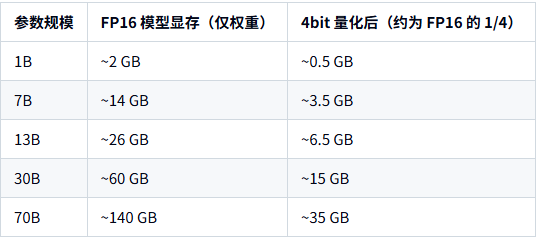
实际部署时,还要加:
KV Cache:与 seq_len × d_model × 层数 × 并发数 成正比;
模型框架的开销、激活缓存等。
因此常见经验是:
7B + 4bit + 8K 上下文:需要 8–12GB 显存 比较稳;
13B + 4bit + 8K 上下文:建议 16–24GB 显存;
30B 以上:基本要 高端卡或多卡 才舒服。
2. CPU vs GPU:同样参数,体验差多少?
CPU-only:
优点:没显卡也能跑(小模型 + 量化);
缺点:比同价位显卡推理慢一个数量级,适合体验或离线任务。
GPU 推理:
利用并行矩阵运算,速度远快于 CPU;
对于 7B 级别,在家用 8–12GB 显卡上就能做到接近在线大模型的体验。
四、参数规模与「效果 / 成本 / 并发」的平衡
可以用下面这个角度理解:
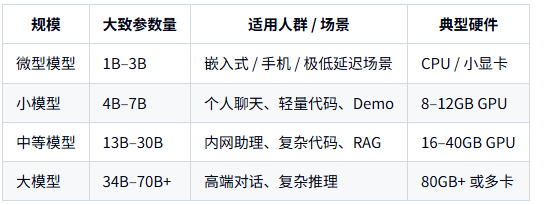
常用经验:
个人 / 学习 / 开发:
→ 直接上 7B 4bit,在 8–12GB 显卡上就能很好用。
小团队内部系统:
→ 以 13B 4bit 为主,配 16–24GB 显卡。
大规模商业化:
→ 自建 7B/13B 集群做主力,必要时再调云端 GPT‑4o/5 等顶级闭源模型兜底。
五、为什么「参数越多并不一定越好」?
架构优化:
MoE(Mixture of Experts):例如 Mixtral‑8x7B,总参数 40 多 B,但每次只激活一小部分专家 → 在推理时类似 9B 模型的成本,却能接近更大模型效果。
新的注意力机制、RoPE 变体、归一化等改进,能显著提升「每个参数的利用效率」。
训练数据与策略:
高质量、多样化、干净的数据,往往比「再翻一倍参数」更关键。
RLHF、控制生成、工具调用等工程优化,对实用效果影响非常大。
任务特化与微调:
一个通用 7B + 高质量指令微调(或 LoRA),在特定业务上往往可以干趴「未微调的 13B」。
所以:不要只盯着参数量选模型。
更务实的做法是:
先确定「效果够不够」→ 再算「硬件/费用顶不顶」→ 再选具体大小。
六、参数选型思路
1. 先回答三个问题
你是 个人 还是 团队 / 公司?
主要干什么?(聊天、写代码、总结文档、RAG、Agent……)
有多少显存?(8GB / 12GB / 24GB / 40GB+?)
2. 对应决策
只有 CPU 或核显:
只建议跑 ≤3B 量化模型 做体验;
正事还是用云端 API(DeepSeek/Qwen/GLM/GPT 等)。
8–12GB 显存(常见家用独显):
模型:7B 4bit(Llama3‑8B、Qwen‑7B、Mistral‑7B 等)
任务:个人聊天、写代码、文档总结都够用。
16–24GB 显存:
可跑 13B 4bit 做主力模型;
并发 3–5 个人同时用问题不大,适合小团队内部助手。
40GB+ 或多卡集群:
根据预算再考虑 30B/70B 或 MoE 大模型;
这时更多是系统工程问题,而不是「参数怎么选」。
七、小结
参数 = 权重 + 偏置,是大模型的知识载体;
关键参数包括:总参数量、隐藏维度、层数、注意力头数、FFN维度、词表大小、上下文长度;
参数量决定上限,架构和训练决定能否接近上限;
对大多数实际应用来说:
7B–13B 的模型 + 4bit 量化 + 合理硬件配置,已经是性价比极高的选择;
一味堆到 70B 往往是「成本翻倍,收益有限」。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 39
39 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)