AI Agent系列:从零开始掌握RAG检索增强生成技术!
本文是AI Agent系列第15篇,详细介绍RAG检索增强生成技术,包括其核心步骤、应用场景及与搜索引擎的区别。文章解释了向量、向量化模型概念,演示如何使用阿里通义Embedding模型进行文本向量化编码,并提供完整代码示例。通过学习,开发者可构建企业级智能问答系统,让AI更好地理解和回答专业领域问题。
AI Agent 系列文章15, 后续会更新 RAG、MCP、向量数据库等内容,最后全栈开发一个 Agent 智能体并部署上线。
本篇介绍内容:
1)RAG 简单介绍
2)介绍下向量(Vector)
3)向量化模型(Embedding Model)
4)文本向量化(text embedding)编码
- RAG 简单介绍
rag, Retrieval-Augmented Generation 检索增强生成,是辅助AI生成专业领域答案的有效方案。
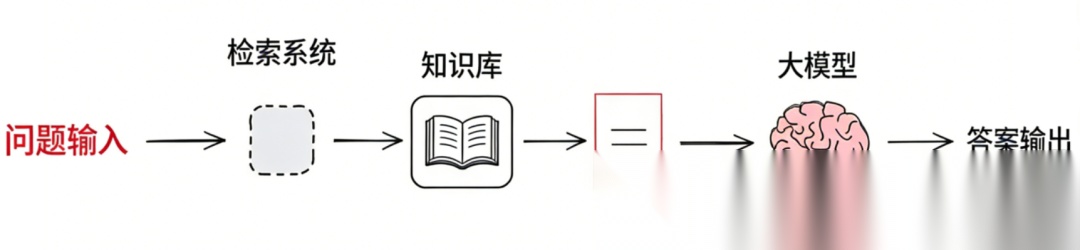
核心步骤:
-
将文本向量化并存储到向量数据库;
-
用户提问时,检索数据库;
-
把检索结果发送给LLM配合生成最终结果;
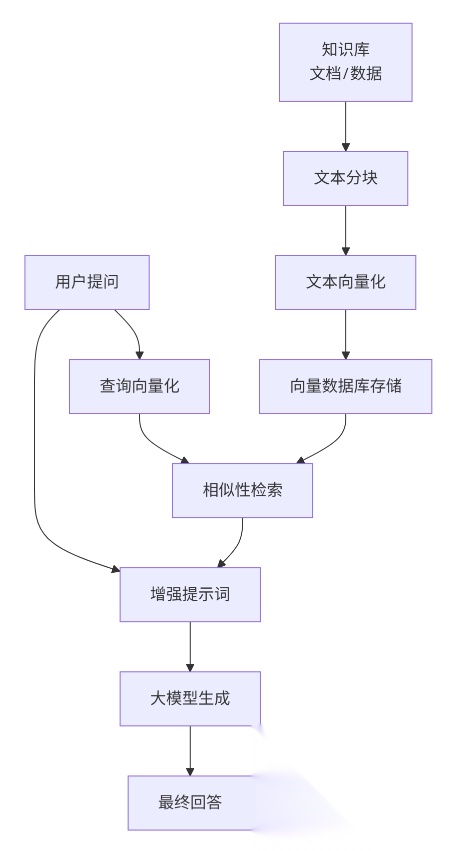
最经典的落地场景就是 智能客服
llm虽然有大量的数据,但是一些企业内部的知识库,它是不知道的,比如一家指定的网店有什么款式的衣服,有什么促销活动等等。
疑问:可以把这些信息作为预置的 prompt 交给 llm ?
这是不现实的,大量的知识库,可能会突破 llm 的输入 token 的长度, 即使没突破,也会消耗大量的token,这是不现实的,token 也得花钱。
这时,就得用上 RAG 了,它的作用就来了。
拆分知识库 —> 文本向量化 —> 存入向量数据库
PS: Langchain 的官方文档:
https://docs.langchain.com/langsmith/evaluation-approaches
- 什么是向量
向量可以用坐标表示,常见的有二维坐标,三维坐标,这个都知道。
简单回顾下数学概念

欧式距离公式:

这其实也是勾股定理 的直接应用。
三维空间 --》 多维空间,也是同样的道理:
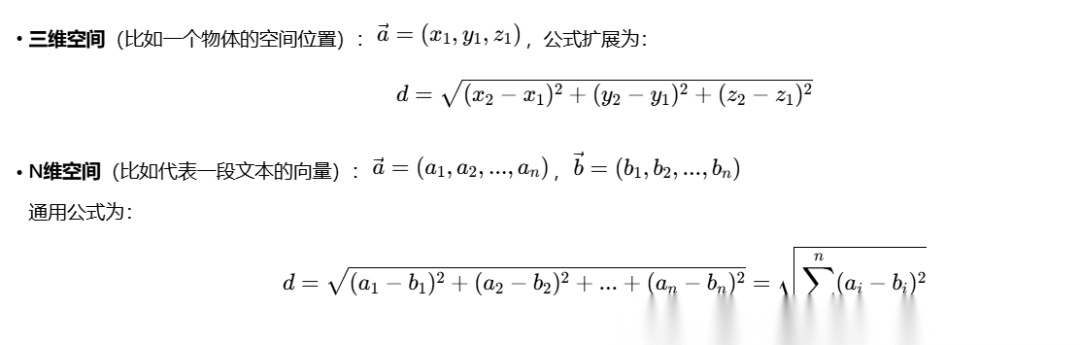
能计算两点之间的距离,那能否计算 两段文字 甚至 两张图片 的距离呢?
这听起来有点抽象,这其实就是 多维向量 之间的距离。
传统的搜索引擎 和 rag的区别:
传统的 ElasticSearch (搜索引擎) ,比如搜索“课程”,只能匹配到一样的关键字才能搜索出来,
而rag,可以理解语义,搜索语义相近的关键词,例如搜索“课程”,也可以匹配到“教学”这个关键词相关的资料,因为两个关键词语义相近;
简单来说,Elasticsearch是“引擎”,负责高效查找信息;RAG是“智能汽车”,利用引擎提供的燃料(信息),将用户送达目的地(获得答案)。
它们不是二选一的关系,而是底层基础设施与上层智能应用的关系。一个优秀的RAG系统,往往离不开一个像ElasticSearch这样强大的搜索引擎作为其核心组件。
具体文本怎么向量化的底层原理,我想我也头大,反正简单理解就是 大规模语料库上训练 得到。
计算向量间的余弦相似度,可以找到语义相近的文档。
将每个词映射为一个低维、稠密的向量(例如128维或300维)。这些向量的神奇之处在于,语义相近的词(如“国王”和“王后”),其向量在空间中的距离或方向也会相近。
欧氏距离、余弦相似度。这个距离就是两段文字、两个图片的相似度。
简单原理了解到这,太抽象的数学原理就不深究了。
主要是体会 自然语言 —> 计算机的数学世界
- 向量化模型(Embedding Model)
Langchain 文档地址:
https://docs.langchain.com/oss/javascript/integrations/text_embedding/index
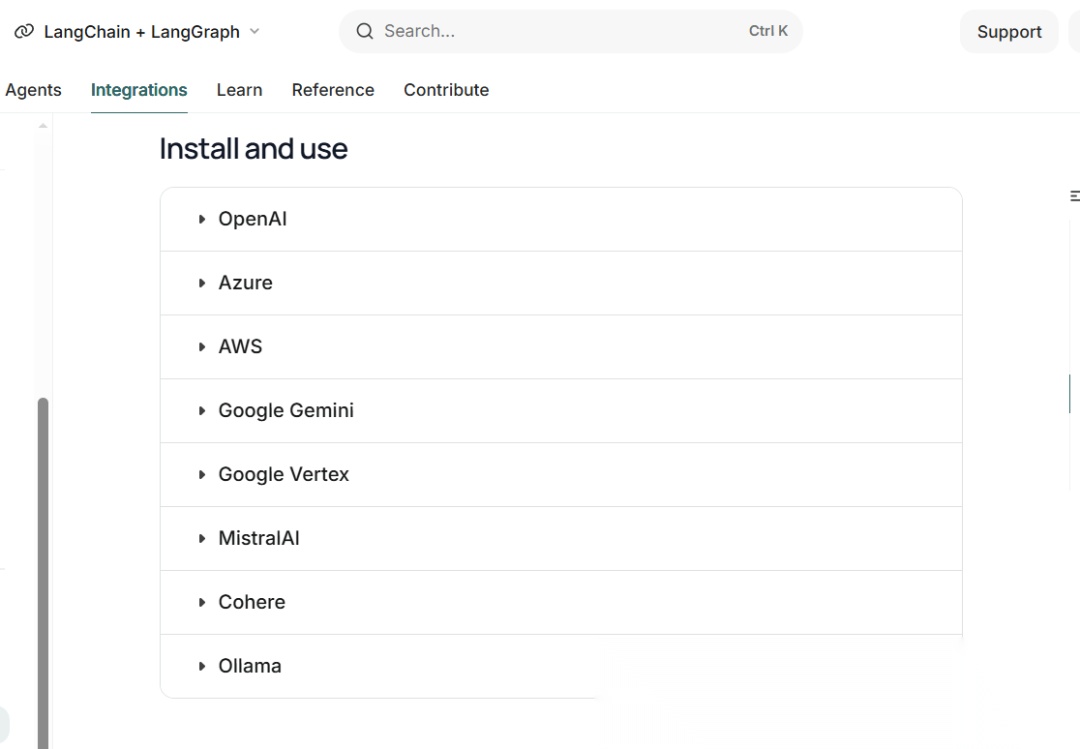
官方提供的向量化模型,都是国外的。这些国内要么不能用,要么不好用
那咋办呢?
还好找到了 langchain 支持阿里的通义
https://docs.langchain.com/oss/javascript/integrations/text_embedding/alibaba_tongyi
还得去 阿里云百炼 平台申请个api key
https://bailian.console.aliyun.com/cn-beijing/?tab=model&spm=0.0.0.i5#/api-key
- 文本向量化 - 编码
npm install @langchain/community @langchain/core
遇到 npm 底层依赖冲突,直接加 --force 安装。
import { AlibabaTongyiEmbeddings } from "@langchain/community/embeddings/alibaba_tongyi";
import 'dotenv/config';
const model = new AlibabaTongyiEmbeddings({
apiKey: process.env.ALIBABA_API_KEY,
});
const res = await model.embedQuery(
"疯狂动物城是一部怎样的电影?"
);
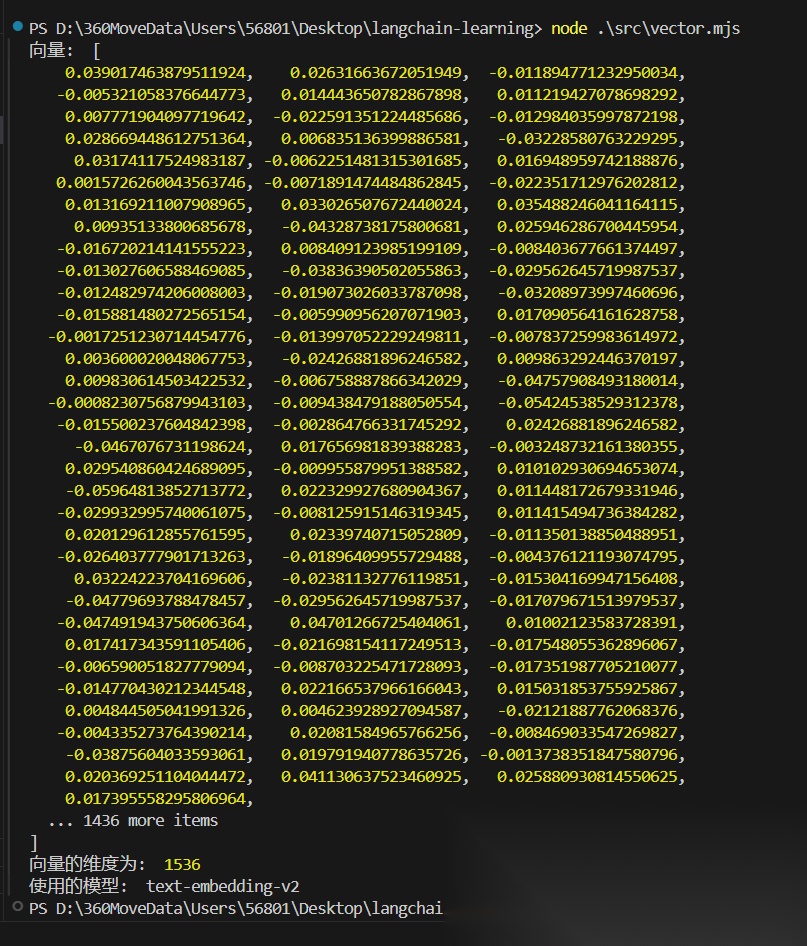
console.log('向量: ', res);
console.log('向量的维度为: ', res.length);
console.log('使用的模型: ', model.modelName);
执行结果:
最后唠两句
为什么AI大模型成为越来越多程序员转行就业、升职加薪的首选
很简单,这些岗位缺人且高薪
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
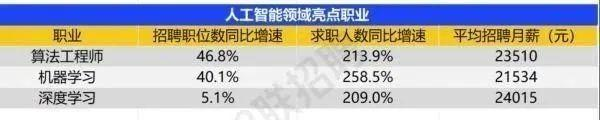
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。
那0基础普通人如何学习大模型 ?
深耕科技一线十二载,亲历技术浪潮变迁。我见证那些率先拥抱AI的同行,如何建立起效率与薪资的代际优势。如今,我将积累的大模型面试真题、独家资料、技术报告与实战路线系统整理,分享于此,为你扫清学习困惑,共赴AI时代新程。
我整理出这套 AI 大模型突围资料包【允许白嫖】:
-
✅从入门到精通的全套视频教程
-
✅AI大模型学习路线图(0基础到项目实战仅需90天)
-
✅大模型书籍与技术文档PDF
-
✅各大厂大模型面试题目详解
-
✅640套AI大模型报告合集
-
✅大模型入门实战训练
这份完整版的大模型 AI 学习和面试资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

①从入门到精通的全套视频教程
包含提示词工程、RAG、Agent等技术点

② AI大模型学习路线图(0基础到项目实战仅需90天)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤640套AI大模型报告合集

⑥大模型入门实战训练

如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献495条内容
已为社区贡献495条内容

所有评论(0)