【Datawhale】大模型基础与量化微调-t4
的左奇异向量和右奇异向量,它们构成了矩阵作用空间的正交基。在几何上,右奇异向量是矩阵的输入空间的特征方向,它们描述了矩阵在这些方向上对输入向量的作用。左奇异向量是输出空间的特征方向,表示矩阵在输出空间中将输入向量映射到的结果方向.它们确保了 SVD 分解在高维空间中依然能够精确地描述矩阵的行为。尤其是在维度压缩、特征提取等问题中,右奇异向量对应于数据的主方向,而左奇异向量则对应于数据在新空间中的主
PEFT LoRA
Parameter-Efficient Fine-Tuning,PEFT
Low-Rank Adaptation of Large Language Models,LoRA
PEFT方法通过策略性地添加或修改少量参数(通常少于总参数的1%),同时保持预训练模型的大部分冻结状态来实现这一点
其基本假设,尤其与LoRA等流星方法相关,是特定任务所需的调整通常存在于一个低维子空间中;这意味着模型权重中所需的变化,即更新矩阵 Δ W \Delta W ΔW,通常可以通过一个低秩矩阵有效近似,这比完整的 Δ W ΔW ΔW需要少得多的参数来表示。首先看奇异值分解:
1. 奇异值分解(SVD)
SVD是实数或复数矩阵的一种分解,它将方阵的特征分解推广到任意 m × n m\times n m×n 矩阵。对于任意给定矩阵 W ∈ R m × n W\in\mathbb{R}^{m\times n} W∈Rm×n其SVD如下所示 W = U Σ V T W=U\Sigma V^{T} W=UΣVT
其中:
-
U U U是一个 m × n m\times n m×n的正交矩阵 ( U U T = U T U = I m ) (UU^T=U^TU=I_m) (UUT=UTU=Im), U U U的列是 W W W的左奇异向量,这些向量构成了 W W W的列空间的正交基
-
Σ \Sigma Σ是一个 m × n m\times n m×n的矩形对角矩阵,对相交线上的元素 σ i = Σ i i \sigma_i=\Sigma_{ii} σi=Σii是 W W W的奇异值,非负,表示矩阵在不同方向上的伸缩比例
通常按降序排列: σ 1 ≥ σ 2 ≥ ⋯ ≥ σ r > 0 \sigma_1\geq\sigma_2\geq\cdots\geq\sigma_r>0 σ1≥σ2≥⋯≥σr>0,其中 r = r a n k ( W ) r=rank(W) r=rank(W)。\sigma的所有其他元素均为零
奇异值是 SVD 分解中的核心元素,它们揭示了矩阵在不同方向上的缩放强度
-
V T V^T VT是一个 n × n n\times n n×n的正交矩阵, V T V^T VT的行是 W W W的右奇异向量,这些向量构成了 W W W的行空间的正交基
实际上SVD将 W W W表示的线型变换分解为三个更简单的操作:旋转输入向量到右奇异向量基下的空间 V T V^T VT、沿着每个奇异值的方向进行缩放 Σ \Sigma Σ、将缩放后的向量再次旋转到左奇异向量基下的空间 U U U
SVD 中的 U U U和 v v v分别是矩阵 W W W的左奇异向量和右奇异向量,它们构成了矩阵作用空间的正交基。在几何上,右奇异向量是矩阵的输入空间的特征方向,它们描述了矩阵在这些方向上对输入向量的作用。左奇异向量是输出空间的特征方向,表示矩阵在输出空间中将输入向量映射到的结果方向.它们确保了 SVD 分解在高维空间中依然能够精确地描述矩阵的行为。尤其是在维度压缩、特征提取等问题中,右奇异向量对应于数据的主方向,而左奇异向量则对应于数据在新空间中的主成分
通过截断SVD进行低秩近似
SVD 在我们此处的价值在于它能提供矩阵的最佳低秩近似。Eckart-Young-Mirsky 定理指出,根据 Frobenius 范数(或谱范数),矩阵W的最佳秩K近似通过保留其前k(远小于m和n)个最大奇异值及其对应的奇异向量而获得的,表示:
W k = U k Σ k V k T W_k=U_k\Sigma_kV_k^T Wk=UkΣkVkT,其中 k < < m i n ( m , n ) k<<min(m,n) k<<min(m,n),那么参数量: k ( m + 1 + n ) k(m+1+n) k(m+1+n)就会 < < m × n <<m\times n <<m×n
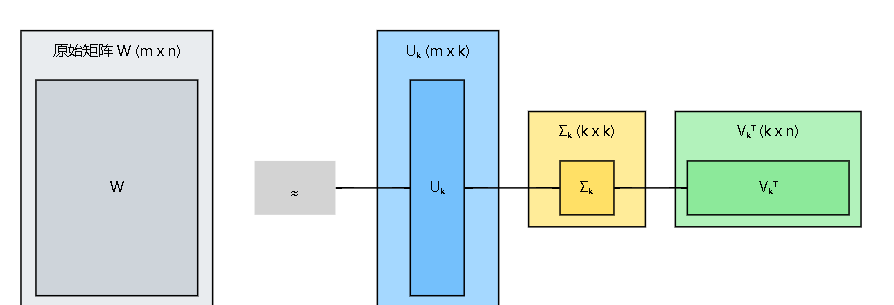
较大的奇异值对应于向量空间中 W W W变换影响最大(捕获大部分方差)的方向。通过丢弃与小奇异值相关的分量,我们通常可以大幅减少表示矩阵所需的参数数量,同时保留其大部分主要信息
LoRA的做法
LoRA实际上不以更新矩阵 Δ W \Delta W ΔW的svd作为低秩矩阵,它会把 Δ W \Delta W ΔW表示为两个较小矩阵 B ∈ R m × k B\in\mathbb{R}^{m\times k} B∈Rm×k A ∈ R k × n A\in\mathbb{R}^{k\times n} A∈Rk×n的乘积,即 Δ W = B A \Delta W=BA ΔW=BA,其中 k < < m i n ( m , n ) k<<min(m,n) k<<min(m,n),实际上类似于 ( U k Σ k ) V k T X (U_k\Sigma_k)V_k^TX (UkΣk)VkTX或 U k ( Σ k V k T ) U_k(\Sigma_kV_k^T) Uk(ΣkVkT)。通过在微调的反向传播李学习这两个参数,而W保持不变
2. 微调方法的分类
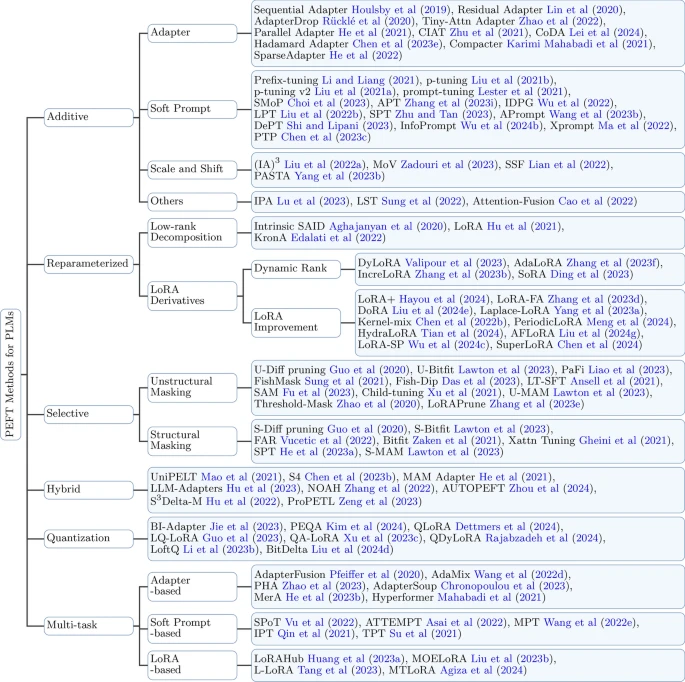
PEFT的分类有很多种,以加性方法举例:
- adapter适配器微调:Parameter-Efficient Transfer Learning for NLP,提出了适配器微调,一种基础的加性微调方法,adapter模块被插入到预训练模型的现有层之间(例,Transformer 块中的多头注意力子层和前馈子层之后),只有这些适配器内部的参数会被训练。基础模型保持不变,这允许将不同的适配器(为不同任务训练的)插入到同一个基础模型中使用,会引入额外的推理延迟
- soft prompt:
- prefix 前缀微调 https://aclanthology.org/2021.acl-long.353.pdf,将一系列可训练的连续向量(即“前缀”)添加到每个注意力层的输入之前。这些前缀在微调过程中作为任务特定的指令被学习
- prompt 微淘 https://arxiv.org/abs/2104.08691,是一种简化方法,其中可训练向量添加到初始输入embedding中,像 P-Tuning 这样的变体进一步完善了这一思路
- scale and shift
- Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learninghttps://arxiv.org/abs/2205.05638
I A ) 3 IA)^3 IA)3通过缩放内部激活的注入adapter,用于通过学习到的向量缩放模型的内部激活。对于具有层的解码器,添加缩放向量和(初始化为 1),分别用于缩放键、值和前馈激活。这使得模型能够在更新模型参数的极小部分()的同时,实现特定任务的自适应,从而支持混合任务批次。如果模型专用于单个任务,则可以将该方法永久应用于权重矩阵,避免额外的计算
- Few-Shot Parameter-Efficient Fine-Tuning is Better and Cheaper than In-Context Learninghttps://arxiv.org/abs/2205.05638
选择性方法:微调W的部分参数
选择性方法采取更直接的方法,即仅解冻并微调原始预训练模型参数中经过仔细选择的一小部分。其余参数保持冻结。
例如:
- 仅微调网络中的偏置项。
- 选择性地更新最后一层或对适应任务很重要的特定层。
- FishMask 或 Diff Pruning 这样更复杂的技术尝试识别并训练对目标任务很重要的子网络。
尽管直观,选择性方法的有效性在很大程度上取决于识别出要微调的正确参数子集。虽然在训练过程中可能比完全微调的内存消耗少,但它们可能需要比附加方法或重参数化方法微调更多的参数才能达到相似的性能。此外,管理不同的任务需要存储修改后参数的单独副本或复杂的修补机制
重参数化方法:修改权重更新
重参数化方法修改了权重更新的表示或应用方式,而不是直接添加参数或选择子集
- lora:lora假设将模型微调具体任务时有效的更新矩阵具有较低的内秩,通过学习规模比更新矩阵小得多的低秩矩阵B和A来近似,也不改变原始的权重,前向传播表示为: h = ( W m , n + B A ) ⋅ x h=(W_{m,n}+BA)\cdot x h=(Wm,n+BA)⋅x,反向传播的过程中只更新B·A,参数量也下降为 r ( m , n ) r(m,n) r(m,n),而低秩 r r r小很多(如 8, 16, 64)即微调参数量也很小仅为全量微调的千分之一甚至万分之一(相较于gpt3175b with Adam)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 19
19 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)